首个开源MoE大模型Mixtral 8x7B的全面解析:从原理分析到代码解读
前言
23年12月8日,Mistral AI 在 X 平台甩出一条磁力链接(当然,后来很多人打开一看,发现是接近 87 GB 的种子)
看上去,Mixtral 8x7B的架构此前传闻的GPT-4架构非常相似(很像传闻中GPT-4的同款方案),但是「缩小版」:
- 8 个专家总数,而不是 16 名(减少一半)
- 每个专家为 7B 参数,而不是 166B(减少 24 倍)
- 42B 总参数(估计)而不是 1.8T(减少 42 倍)
- 与原始 GPT-4 相同的 32K 上下文
在发布后 24 小时内,已经有开发者做出了在线体验网站:https://replicate.com/nateraw/mixtral-8x7b-32kseqlen
OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。早些时候,有人爆料 GPT-4 是采用了由 8 个专家模型组成的集成系统。后来又有传闻称,ChatGPT 也只是百亿参数级的模型(大概在 200 亿左右)
传闻无从证明,但 Mixtral 8x7B 可能提供了一种「非常接近 GPT-4」的开源选项,特此,本文全面解析下:从原理解析到代码解读(在此文之前,尚没有资料扒得像本文这样如此之细)
第一部分 首个开源MoE大模型Mixtral 8x7B
1.1 Mixtral 8x7B的整体架构与模型细节
两天后的23年12.11日,Mistral AI团队对外正式发布 Mixtral 8x7B,其在大多数基准测试中都优于 Llama 2 70B,推理速度提高了 6 倍,且它在大多数标准基准测试中匹配或优于 GPT3.5
为免歧义,补充说明下,Mistral AI团队目前总共发布了两个模型
- 今年10月发布的Mistral 7B
- 今年12月则发布的混合专家模型,称之为Mixtral 8x7B
一个mis 一个mix,本质不同
而这个Mistral AI团队什么来头呢?
据此文《七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到Mistral、LongLora Llama》第4部分的介绍
- 这个Mistral AI团队是今年5月,由DeepMind和Meta的三位前员工在巴黎共同创立的(其CEO Arthur Mensch此前在DeepMind巴黎工作,CTO Timothée Lacroix和首席科学家Guillaume Lample则在Meta共同参与过LLaMA一代的研发,很像当年OpenAI的部分员工出走成立Anthropic啊)
- 今年10月,他们还发布了第一个基座大模型,即Mistral 7B,一度被称为最好的7B模型,因为其在所有评估基准中均胜过了目前最好的13B参数模型(Llama 2,对标的第二代),并在推理、数学和代码生成方面超越了Llama 34B(对,这里其对标Llama第一代的34B)
1.1.1 Mixtral 8x7B是一个稀疏的专家混合网络
Mixtral 8x7B是一个纯解码器模型
- 其中前馈块从一组 8 个不同的参数组中进行选择(It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters)
- 在每一层,对于每个token,路由器网络选择其中的两个组(“专家”)来处理token并通过组合相加得到它们的输出(At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively)
这点可能很多朋友不会特别在意,但你仔细品味下,你会发现大有天地,即:每个token 都由某两个专家负责完成,最后整个序列 则是由一系列「不同的两两专家」组合完成,下文还会详述该点
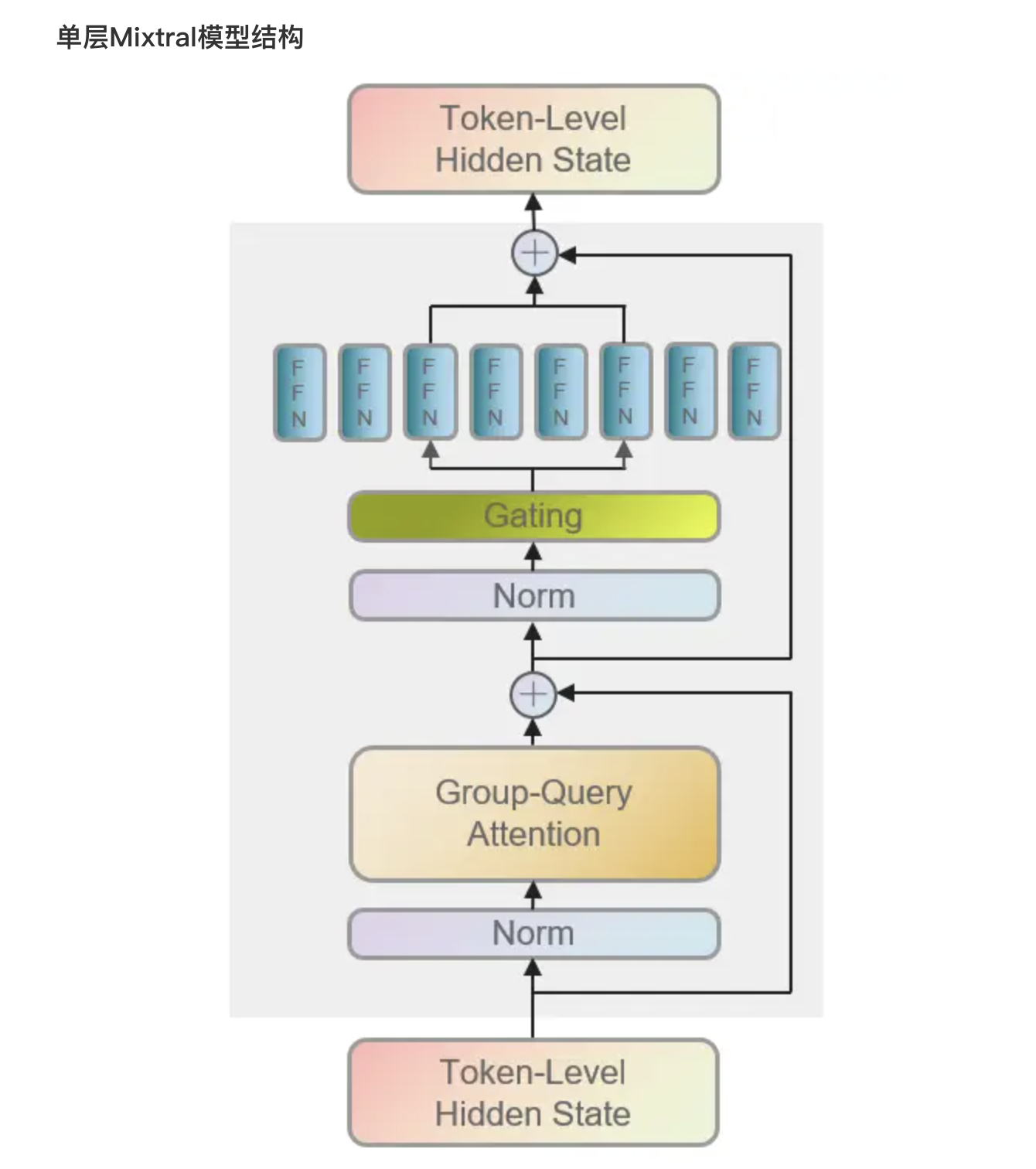
如下图所示,传入模型的各个token在经过Attention层及残差连接后,进一步将由路由(Gating/Router)导向2个expert(FFN)中,之后对expert的输出进行加权聚合,再经过残差连接得到当前层的输出
1.1.2 Mixtral的参数总量为何是46.7B而非56B
Mixtral 共有 46.7B 个参数,但每个token仅使用 12.9B 个参数。因此,它以与 12.9B 模型相同的速度和相同的成本处理输入并生成输出(Mixtral has 46.7B total parameters but only uses 12.9B parameters per token. It, therefore, processes input and generates output at the same speed and for the same cost as a 12.9B model)
- 即,虽然Mixtral模型的完整名称为“Mixtral-8x7B-v0.1”,看似有“8x7B=56B”的参数量,但实际的参数量应当是约47B而非56B,因为在各个层中仅有experts部分(FFN)是独立存在的,其余的部分(Attention等)则是各个expert均有共享的
- 可以想象成一个“纺锤状”的样式,数据由共享模块传输至expert模块对应于纺锤中部发散的部分,对expert的输出进行加权聚合则对应纺锤末端收束的部分
1.1.3 Mixtral中所采取的GQA机制
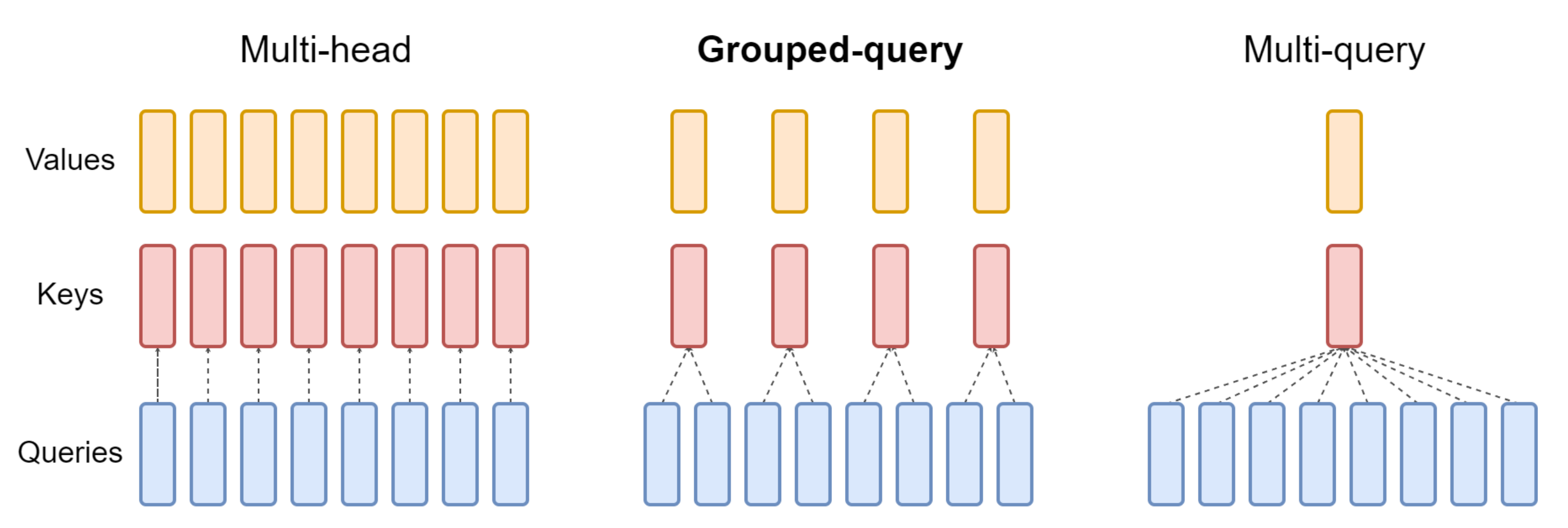
Mixtral沿用了Mistral 7B中所采取的GQA机制,与传统的MHA(Multi-Head Attention)相比,主要是对Attention机制中的K、V表征维度进行控制,从而降低K、V对应的参数量,除GQA外相应地还有MQA(Multi-Query Attention),MQA可以认为是GQA的特例。相关维度如下表所示:
| Q | K | V | |
| MHA | hidden_dim | hidden_dim | hidden_dim |
| GQA | hidden_dim | hidden_dim/n | hidden_dim/n |
| MQA | hidden_dim | 1 | 1 |
其中n为K和V相对MHA参数量降低的比例,具体地,在Mixtral中n为4
关于GQA的更多细节详见此文《一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA》
1.1.4 Mixtral中的路由(Gating/Router)
路由(Gating/Router)本质是一个线性层,输入维度为隐层维度hidden_dim、输出维度为expert数num_experts。正向传播过程中将被用作预测给定token对应输入各个expert的分值
self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)至于路由处理的对象可以是Sentence-Level、Token-Level或者Task-Level
- Sentence-Level是对各个样本分别进行路由
- Token-Level是对样本中的各个token分别进行路由
- Task-Level要求不同的expert明确负责不同任务
因此同样也是对各个样本分别进行路由,但其所路由的目标expert是有明确导向的,例如某样本的数据还提供有“所属任务”信息,通过该信息可明确将该样本导向某个专职负责对应任务的expert中
Mixtral采取了Token-Level的处理单位
- 至于首次在NLP任务中使用Token-Level的MOE可以追溯至2017年的《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》

- 该论文展示了Token-Level的一些有趣现象,通过观察各个expert所负责token的统计特征,不同的expert确实掌握了一些语法层面理解, 当需要不定冠词“a”在重要的动词短语中引入直接宾语时,则会有专门的752号expert来负责输出这个“a”
1.2 模型表现:匹配或超越Llama 2 70B 以及 GPT3.5
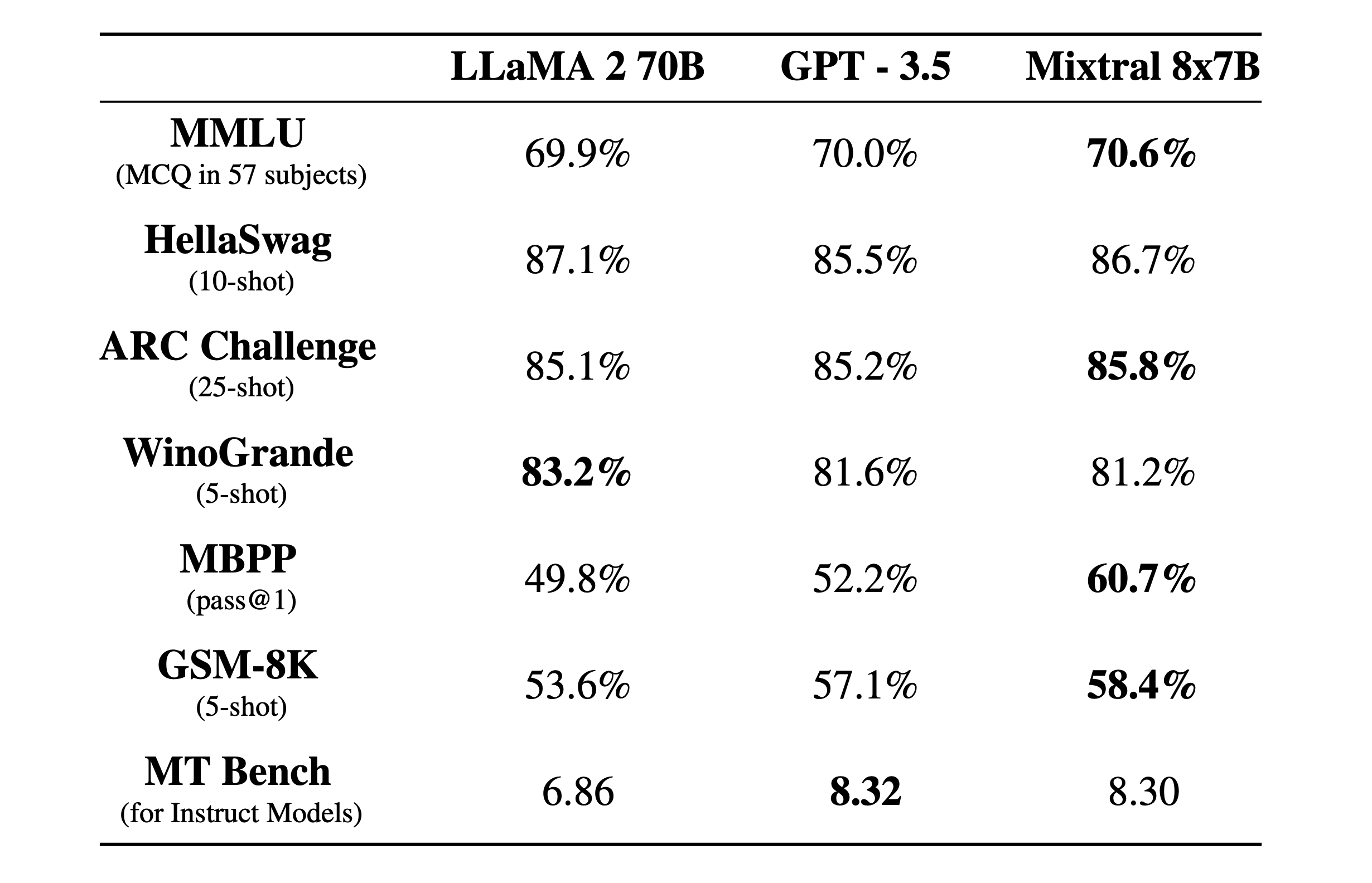
我们将 Mixtral 与 Llama 2 系列和 GPT3.5 基础模型进行比较。Mixtral 在大多数基准测试中均匹配或优于 Llama 2 70B 以及 GPT3.5
在下图中的测试,衡量了质量与推理预算的权衡。与 Llama 2 相比,Mistral 7B 和 Mixtral 8x7B 更高效
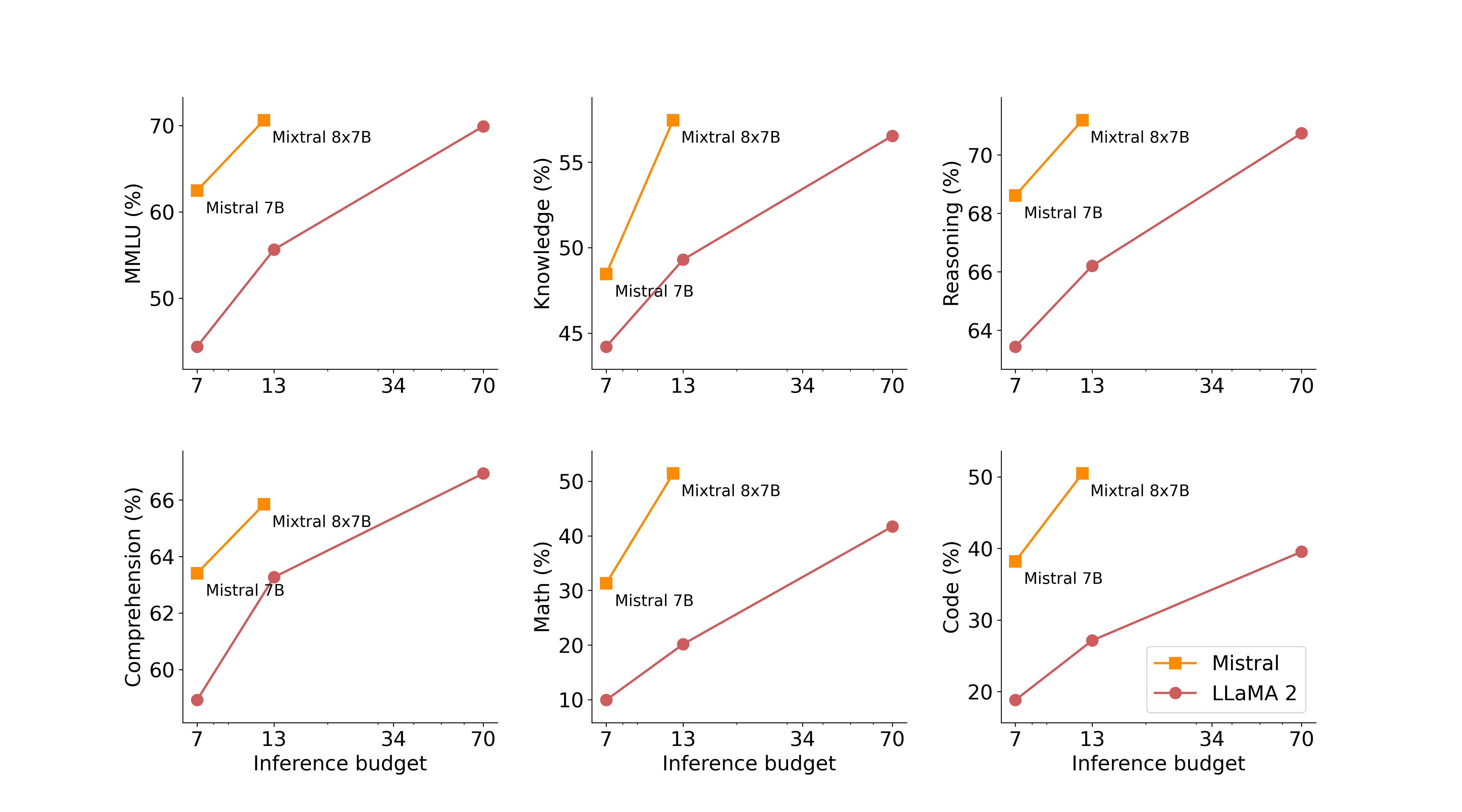
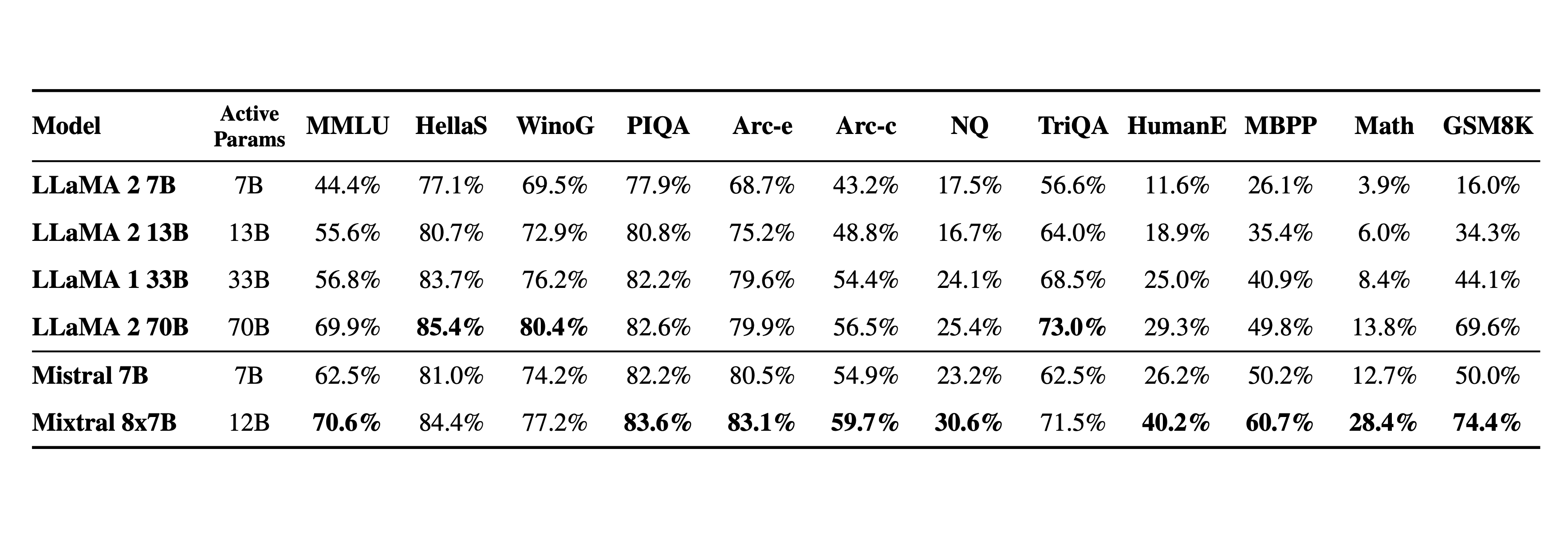
下表给出了上图的详细结果
为了识别可能的缺陷,通过微调/偏好建模来纠正,测量了其在BBQ/BOLD 上的性能
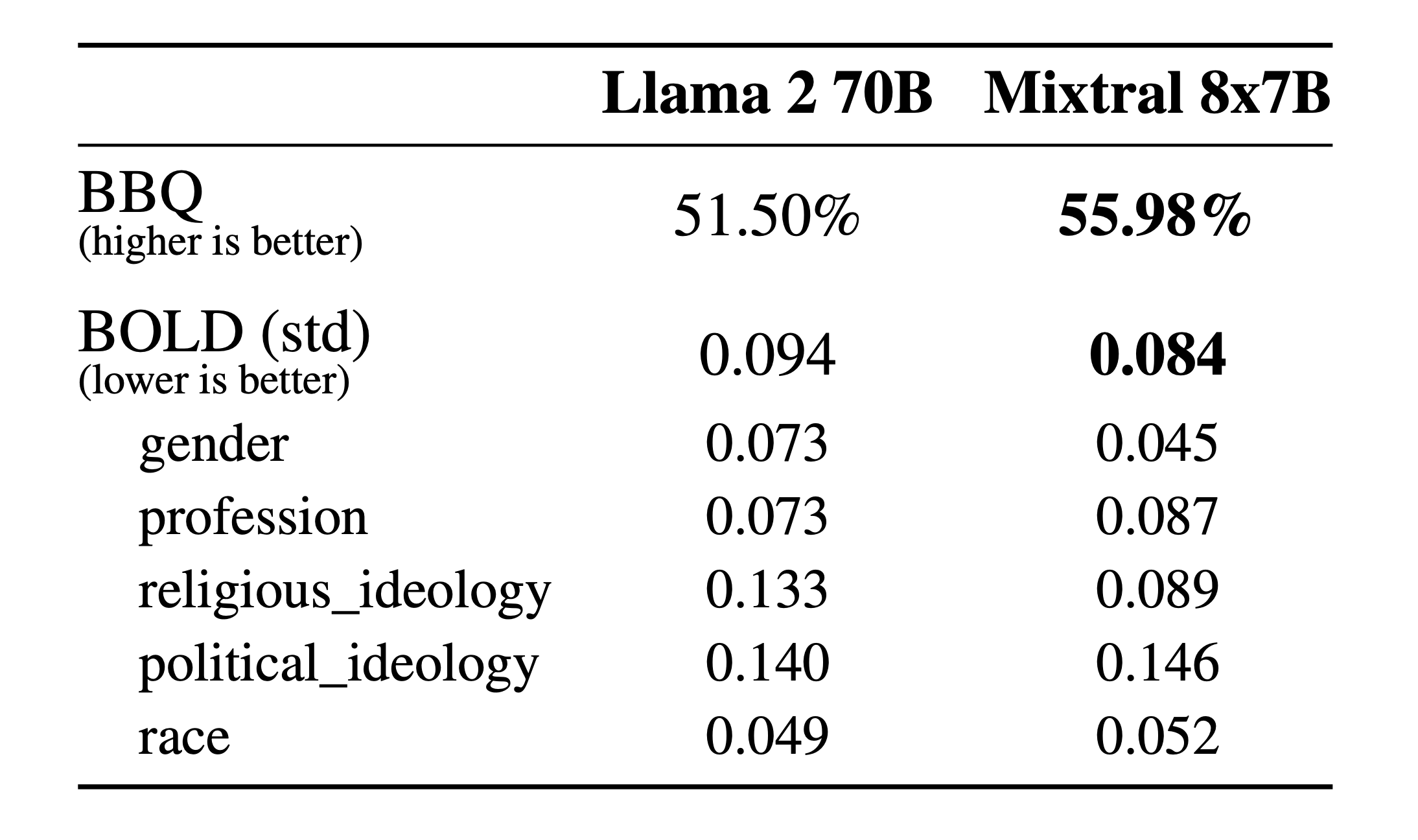
与 Llama 2 相比,Mixtral 对 BBQ 基准的偏差较小。总体而言,Mixtral 在 BOLD 上比 Llama 2 显示出更积极的情绪
1.3 指令遵循模型Mixtral 8x7B Instruct
与 Mixtral 8x7B 一起发布还有 Mixtral 8x7B Instruct,其在Mixtral 8x7B的基础上通过监督微调和直接偏好优化(DPO)进行优化,以让之严格的遵循指令
关于什么是DPO及其原理细节,请参见此文《RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr》
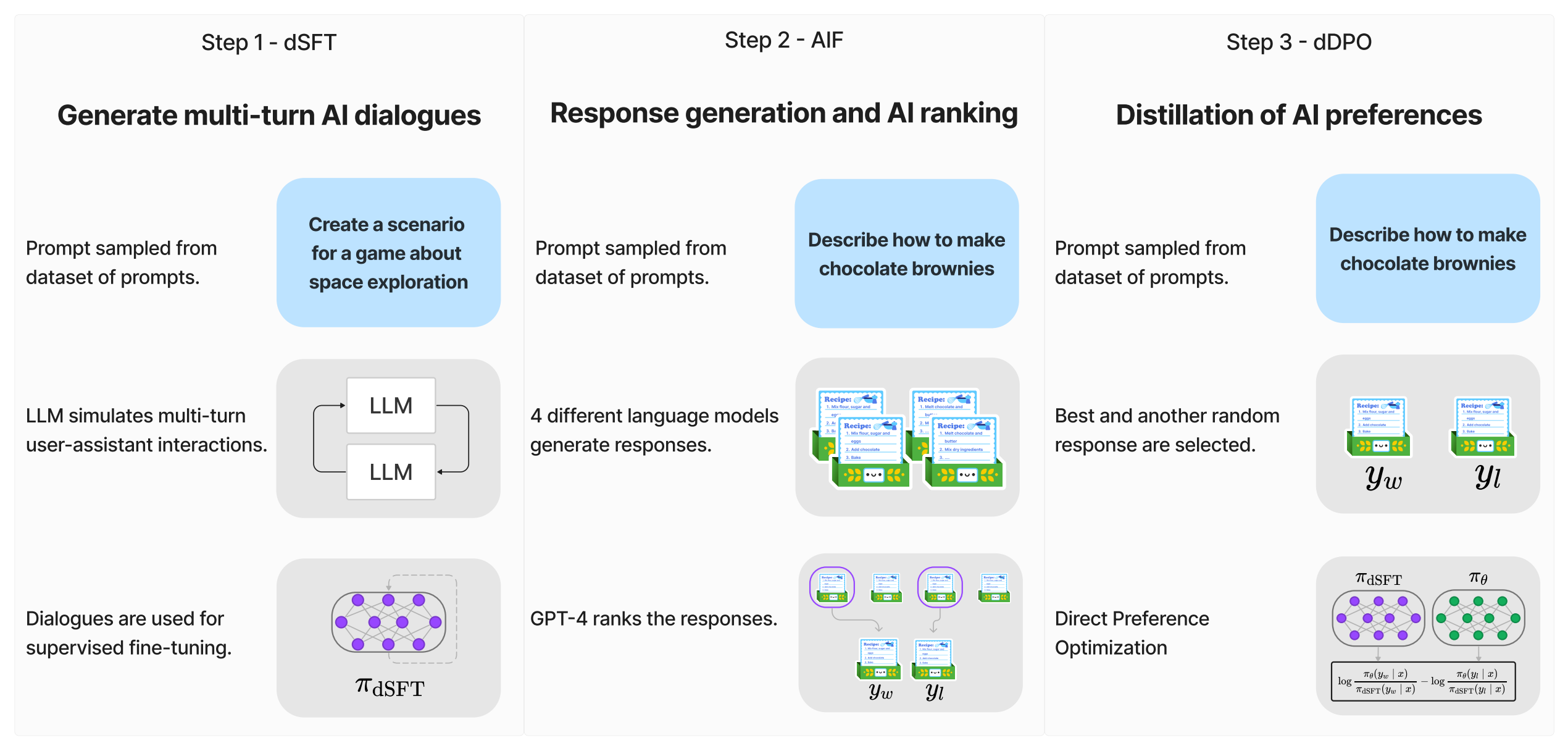
在MT-Bench上,它达到了8.30的分数,使其成为最好的开源模型,性能可与GPT3.5相媲美
第二部分 Mixtral(MOE架构)的实现细节:代码解读
如阿荀所说(本部分的base版本由我司大模型项目团队第二项目组的阿荀提供,我在其基础上陆陆续续做了大量的补充、说明 ),上文中关于mixtral一个比较反直觉的点是:
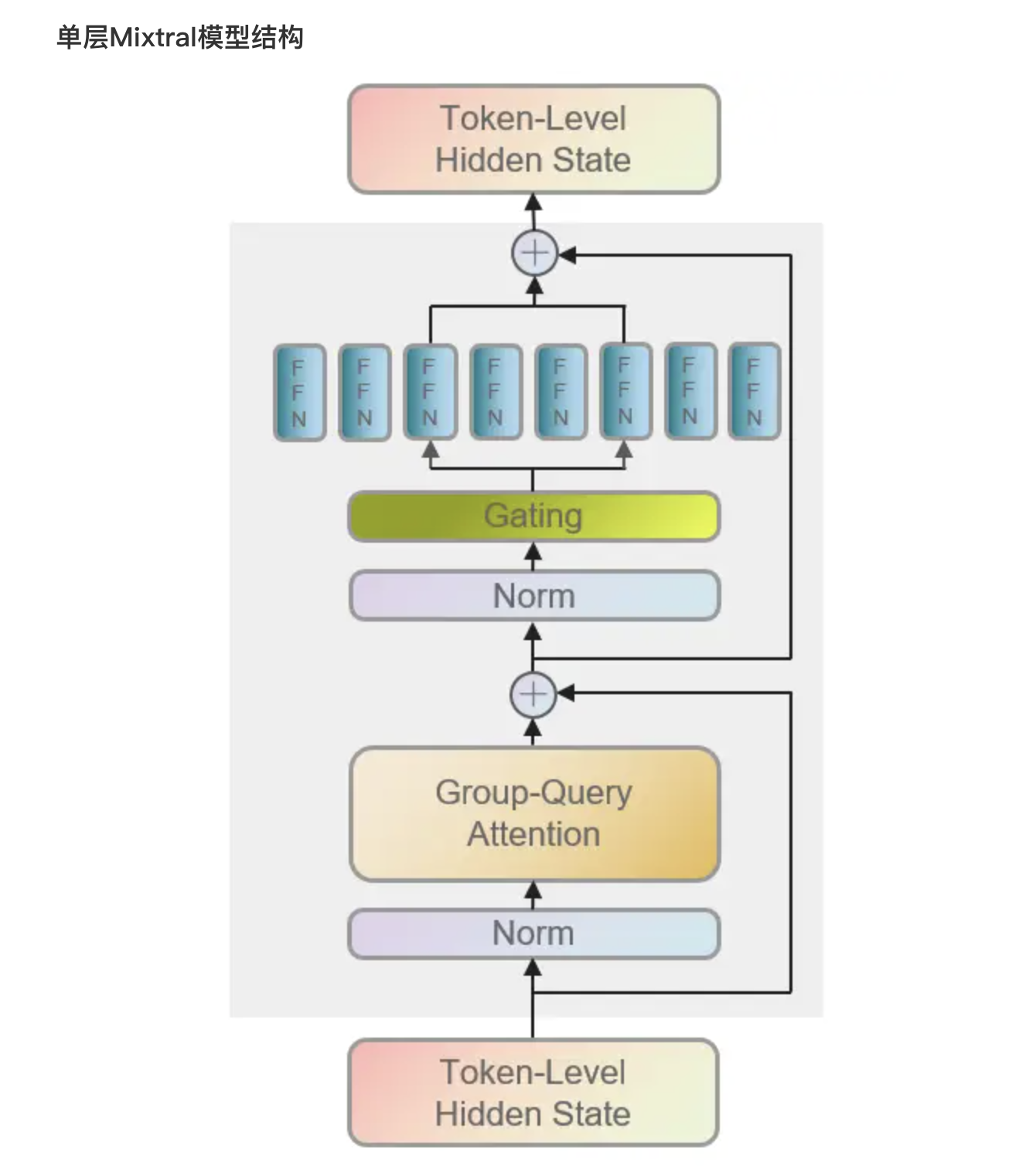
- 对于每个token,路由器网络选择其中的两个组(“专家”)来处理token并通过组合相加得到它们的输出「At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively」
- 啥意思,就是如果不仔细了解的话,很容易误以为是“输入的一整个序列”分给TOP 2专家,结果事实是每个token都各自分配TOP 2专家,而且当你仔细抠完mixtral的代码之后,你会发现还真是如此..
2.1 MOE模块的前向传播:整体流程
单个Mixtral层可以大体划分为Attention模块和MOE模块,以下重点关注MOE模块的前向传播过程
2.1.1 获取各token对应的top2 expert及其权重
为确保大家可以以最快的速度理解各行代码的含义,我在阿荀分析的基础上拆成了以下六个步骤,且对每个步骤都加了额外的解释说明
- 由于hidden_states的维度,通常包括批大小(batch_size)、序列长度(sequence_length)和隐藏层维度(hidden_dim),故有
# 由Attention模块输出的hidden_states作为本部分的输入 batch_size, sequence_length, hidden_dim = hidden_states.shape - 将hidden_states的形状重构为一个二维张量,用于将其处理为每个token的表示
# 转换成(bs*seq_len, hidden_dim),即token-level hidden_states = hidden_states.view(-1, hidden_dim) - 通过一个门控(gate)机制来生成路由逻辑(router_logits),用于后续决定每个token应由哪些专家(experts)处理
# router_logits: (batch * sequence_length, n_experts) # (bs * seq_len, n_experts) router_logits = self.gate(hidden_states) - 对每个token的路由逻辑应用softmax函数,计算每个专家对每个token的处理权重
# 在token-level(dim=1)进行softmax,即每个token都各自进行n_experts分类的输出 routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float) - 选取每个token的前top_k个最重要的专家及其权重
# routing_weights: (bs * seq_len, topk),是选取的experts对应的原始权重 # selected_experts: (bs * seq_len, topk),是选取的experts的编号/索引号 routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1) - 对选出的每个token的专家权重进行归一化处理,确保每个token的专家权重之和为1
# 对原始权重重新归一化,使得所取出的experts权重加和等于1 # routing_weights的具体样例见下文的【代码块A】 routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
2.1.2 将各token传入对应的expert模型中进行前向传播得到输出
- 首先
# final_hidden_states: (bs * seq_len, hidden_dim) # 由全0张量初始化 # final_hidden_states将用于存储各token对应expert的聚合结果 final_hidden_states = torch.zeros( (batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device ) - 根据给定的selected_experts作为元素1所在位置的索引,构建向量长度为num_experts的one-hot编码
好比24个token,需要由8个expert两两组合处理,那我针对每一个token都构建长度为8的0 1编码,这个编码分别代表8个expert
故,每个token选择了哪两个expert,则对应的编码位上变为1,否则为0
比如July这个token选择3 7两个expert,则July对应的0 1编码位:0 0 1 0 0 0 1 0
再比如Edu这个token如果选择了2 4两个expert,则其01编码为:0 1 0 1 0 0 0 0
依此类推..# selected_experts.shape: (bs*seq_len, topk) # torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).shape: (bs*seq_len, topk, num_experts) - 使用相对取巧方法来进行前向传播
具体而言,下面这个张量expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0).shape: (num_experts, topk, bs*seq_len)
的物理含义是由“每个token分别选取了哪topk个expert”变成了“每个expert分别作为各个排位存在的时候,对应需要处理哪些token”
这样做的好处在于:后续循环的时候只需要进行num_experts次前向传播就能得到结果,而无需进行bs*seq_len次前向传播
为方便大家更好的理解上面那行代码的含义,我特地画了个示意图以加快理解 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z,是需要处理的token
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z,是需要处理的token 1 2 3 4 5 6 7 8,代表8个expert
1 2 3 4 5 6 7 8,代表8个expert
(如阿荀所说,如此,便把关注视角从“各个token”变成了“各个专家”,当然,大部分情况下 token数远远不止下图这5个,而是比专家数多很多。总之,这么一转换,最终可以省掉很多循环 )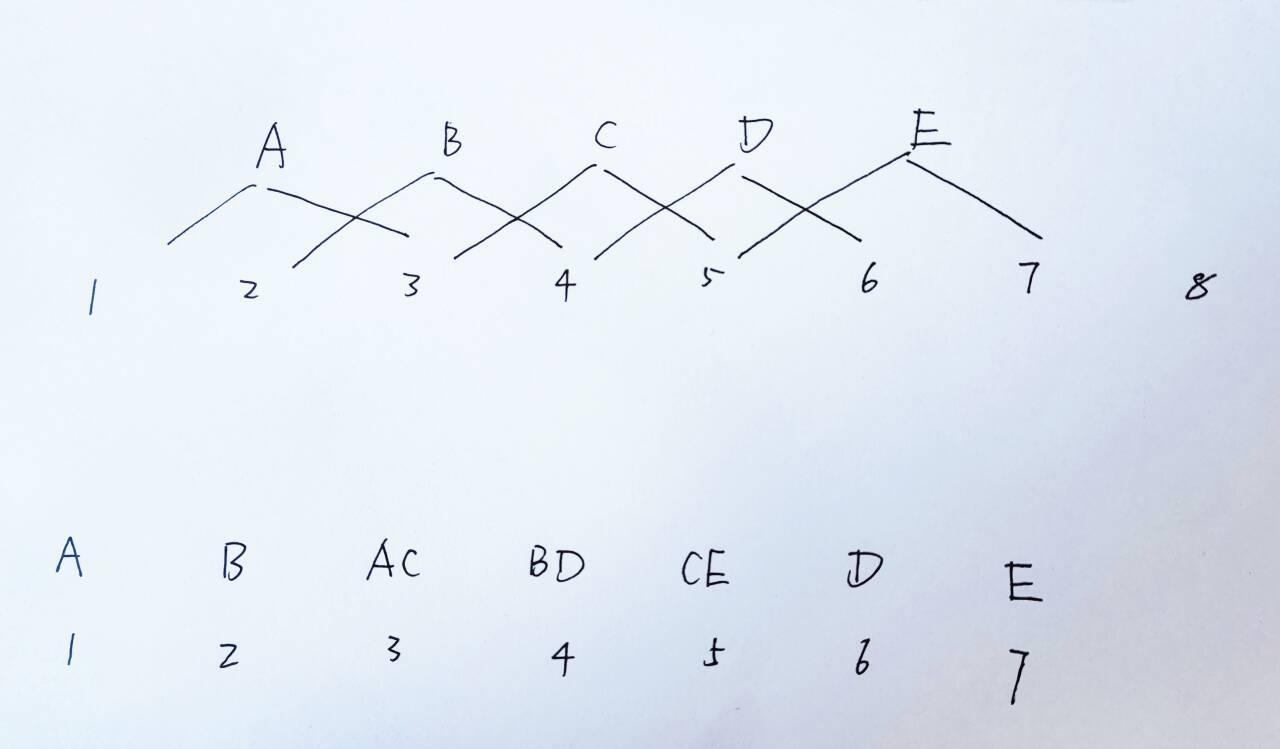
- 所以接下来只需要进行num_experts次循环
上面这几行代码得好好解释下# 根据次序逐个取出expert模型 for expert_idx in range(self.num_experts): expert_layer = self.experts[expert_idx] idx, top_x = torch.where(expert_mask[expert_idx])
由于expert_mask记录有各个expert分别作为各个排位存在的时候,对应需要处理哪些token,故expert_mask[expert_idx].shape: (topk, bs*seq_len),便是从expert_mask中取出其对应的,详见下文的【代码块B】
故上面三行的最后一行中等式中的右边项:torch.where(expert_mask[expert_idx]),则是辨析出expert_mask[expert_idx]值为1的位置索引,详见下文的【代码块C】
至于:idx.shape: (bs * seq_len, ),则代表expert_mask[expert_idx]中(每列)元素值为1的索引位置
以及:top_x.shape: (bs * seq_len, ),则代表expert_mask[expert_idx]中(每行)元素值为1的索引位置
继续分析该for循环之后的代码,如下# 如果exert_mask[expert_idx]不存在元素为1的值则跳过 if top_x.shape[0] == 0: continue # 全部token的隐向量hidden_states中取出当前expert对应token的隐向量 # current_state.shape: (top_x_length, hidden_dim) current_state = hidden_states[None, top_x_list].reshape(-1, hidden_dim) # 将取出的token隐向量传入expert模型进行前向传播得到返回 # current_hidden_states.shape: (top_x_length, hidden_dim) # expert_layer的正向过程详见下文的【代码块D】 current_hidden_states = expert_layer(current_state, routing_weights[top_x_list, idx_list, None]) # 将当前expert的输出以加和的形式写入预先定义好的final_hidden_states张量中 final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype)) - for循环结束后,相当于所有expert均处理完毕后,将维护好的final_hidden_states由(bs * seq_len, hidden_dim)转为(bs, seq_len, hidden_dim),并将作为本批次运行的返回
更多详见下文的【代码块E】final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
2.2 MOE前向传播中五个代码块的细致分析:鞭辟入里
2.2.1 代码块A:routing_weights的具体样例
# 【代码块A】routing_weights
# 每行对应1个token,第0列为其对应排位第1的expert、第1列为其对应排位第2的expert,元素值为相应权重
[[0.5310, 0.4690],
[0.5087, 0.4913],
[0.5775, 0.4225],
[0.5014, 0.4986],
[0.5030, 0.4970],
[0.5479, 0.4521],
[0.5794, 0.4206],
[0.5545, 0.4455],
[0.5310, 0.4690],
[0.5294, 0.4706],
[0.5375, 0.4625],
[0.5417, 0.4583],
[0.5014, 0.4986],
[0.5239, 0.4761],
[0.5817, 0.4183],
[0.5126, 0.4874]]2.2.2 代码块B:expert_mask[expert_idx]
因为有:expert_mask记录有各个expert分别作为各个排位存在的时候,对应需要处理哪些token
故而有:expert_mask[expert_idx]从expert_mask中取出第expert_idx个expert将处理哪些token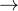 第0行为该expert作为排位第1存在的时候处理的token
第0行为该expert作为排位第1存在的时候处理的token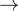 第1行为该expert作为排位第2存在的时候处理的token
第1行为该expert作为排位第2存在的时候处理的token
# 【代码块B】expert_mask[expert_idx]
# 下述两行例子的物理含义为:
# 第一行是“该expert作为排位1的exert存在时,需要处理第9个token;
# 第二行是“该expert作为排位2的expert存在时,需要处理第10、11个token”
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0]]2.2.3 代码块C:idx, top_x = torch.where(expert_mask[expert_idx])
# 【代码块C】idx, top_x = torch.where(expert_mask[expert_idx])
# 以上述expert_mask[expert_idx]样例为例,对应的torch.where(expert_mask[expert_idx])结果如下
idx: [0, 1, 1]
top_x: [9, 10, 11]idx对应行索引,top_x对应列索引,例如张量expert_mask[expert_idx]中,出现元素1的索引为(0, 9)、(1, 10)、(1, 11)
从物理含义来理解,top_x实际上就对应着“关乎当前expert的token索引”,第9、第10、第11个token被“路由”导向了当前所关注的expert,通过top_x可以取到“需要传入该expert的输入”,也即第9、第10、第11个token对应的隐向量
- 因此top_x将作为索引用于从全部token的隐向量hidden_states中取出对应token的隐向量
- 而idx和top_x也会组合起来被用于从expert权重张量routing_weights中取出对应的权重
并且通过行索引、列索引的组合routing_weights
2.2.4 代码块D:expert内部的前向传播
# 【代码块D】expert内部的前向传播
def forward(self, hidden_states, routing_weights):
current_hidden_states = self.act_fn(self.w1(hidden_states)) * self.w3(hidden_states)
current_hidden_states = self.w2(current_hidden_states)
return routing_weights * current_hidden_states其入参不仅有expert相应token的隐向量,还有对应expert的权重,整体是一个基于swiGLU激活的FFN
最后对FFN的输出进行加权得到该expert的实际输出,因此加权处理是在expert的内部就已经进行了
2.2.5 代码块E:final_hidden_states
- 最初final_hidden_states是全0张量
# 查看与当前expert有关的final_hidden_states部分,即final_hidden_states[top_x] [[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]] - 使用.index_add_函数后在指定位置(top_x)加上了指定值(current_hidden_states)
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype)) - 再次查看与当前expert有关的final_hidden_states部分,即
[[ 0.0938, 0.0509, -0.0689, ..., -0.0182, -0.0246, 0.0468], [ 0.1246, 0.0642, 0.0015, ..., 0.0100, -0.0110, 0.0219], [ 0.0478, -0.0192, 0.0139, ..., -0.0039, -0.0197, 0.0475]]
第三部分 混合专家模型MOE的发展史与更多实践细节
// 待更
参考文献与推荐阅读
- 一条磁力链接席卷AI圈,87GB种子直接开源8x7B MoE模型
- Mistral AI对Mixtral of experts的介绍:Mixtral of experts | Mistral AI | Open source models
- 开源大模型超越GPT-3.5!爆火MoE实测结果出炉
- https://github.com/nateraw/replicate-examples/tree/main/mixtral
- 预训练大模型:百度UFO(Unified Feature Optimization)
- 集4学员且友人wstart推荐的三篇论文
LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision - ..