IA-GCN: Interactive Graph Convolutional Network for Recommendation阅读笔记
IA-GCN: Interactive Graph Convolutional Network for Recommendation
0.论文信息
- paper地址:https://arxiv.org/pdf/2204.03827v1.pdf
- code:未公开
1. 摘要
-
问题: 在之前的研究工作中,在embedding过程中没有考虑user-item之间的交互特征
-
方法: 提出了IA-GCN模型,在user-item之间建立双边交互指导。
- 在学习用户(user)表示的时候,注重在 item 树中给跟目标用户相似的邻居分配更多的权重。
- 在学习项目(item)表示时,更关注在 user 树中与目标 item 相似的邻居。
注:这篇文章是基于何向南老师的 Light-GCN 改的
2. 引言
问题: 有的基于gcn的CF算法虽然已经被广泛研究,但大多存在一个关键的限制:在CF层中,用户树和项目树直到最终融合时才进行交互。这是因为它们的聚合大多继承自传统的GCNs,,最初是为了对每个节点进行分类而提出的。然而,推荐任务与分类任务有着根本的不同: 不仅关注user和item的一般特征、用户的购买力、对项目的评分,还需要关注user和item之间的交互信息。比如: user 在选择 item 时的 consideration,item 吸引 user 的 characteristic,这些都决定着用户的 preference。
3. 模型概述
3.1 问题定义
- user: U = { u 1 , u 2 , . . . , u n } U=\{u_1,u_2,...,u_n\} U={u1,u2,...,un}
- item: I = { i 1 , i 2 , . . . , i m } I=\{i_1,i_2,...,i_m\} I={i1,i2,...,im}
- 目标是学得一个函数:
f
:
U
×
I
−
>
R
f:U\times I ->R
f:U×I−>R 来预测的user-item pair
(
u
,
i
)
(u,i)
(u,i) 偏好分数 (preference score)
y
^
u
,
i
\hat y_{u,i}
y^u,i
- 一个准确的predictor f f f 应该给positive user-item pair ( u , i + ) (u,i_+) (u,i+) 分配相比于negative user-item pair ( u , i − ) (u,i_-) (u,i−) 更高的分数
- positive 交互:点击、购买等等
- 根据 Bayesian Personalized Ranking (BPR)[1205.2618.pdf (arxiv.org)] , 将目标函数定义为:
l ( D ) = − 1 ∣ D ∣ ∑ ( u , i + , i − ) ∈ D l n σ ( y ^ u , i + − y ^ u , i − + λ R ) l(D)=- \frac 1{|D|}\sum_{(u,i_+,i_-)\in D}ln \sigma(\hat y_{u,i_+}- \hat y_{u,i_-}+\lambda R ) l(D)=−∣D∣1(u,i+,i−)∈D∑lnσ(y^u,i+−y^u,i−+λR)
D D D 是数据集, σ \sigma σ 是 s i g m o i d sigmoid sigmoid 函数, λ R \lambda R λR 表示对所有模型参数的正则化。
- 偏好得分 y ^ u , i \hat y_{u,i} y^u,i 的计算,即目标用户和目标项目的内积:
y ^ u , i = f ( u . i ) = < e u 0 , e i 0 > \hat y_{u,i} =f(u.i)=<e^0_u,e^0_i> y^u,i=f(u.i)=<eu0,ei0>
e u 0 , e i 0 ∈ R d e_u^0 ,e_i^0\in R^d eu0,ei0∈Rd 是 u u u 和 i i i 的 embeddings,总的来说,我们有 𝑚 + 𝑛 𝑚 + 𝑛 m+n 嵌入向量,它们将与其他模型参数一起随机初始化和端到端训练。
3.2 图卷积框架
-
将用户-项目交互被表述为无向二分图 G = ( V , E ) G=(V,E) G=(V,E), 其中用户和项目都充当图节点,即 V = U ∪ I V = U ∪ I V=U∪I 。 𝑢 − 𝑖 𝑢 - 𝑖 u−i 交互作为边,即 E ⊆ U × I E ⊆ U × I E⊆U×I。
-
高阶特征表示为 e 𝑢 𝑘 , e 𝑖 𝑘 , 𝑘 ∈ { 1 , . . . , 𝐾 } e^𝑘_𝑢, e^𝑘_𝑖, 𝑘 ∈ \{1, ..., 𝐾\} euk,eik,k∈{1,...,K},其中 𝑘 阶特征 e 𝑢 𝑘 / e 𝑖 𝑘 e^𝑘_𝑢 /e^𝑘_𝑖 euk/eik 总结了 𝑢 / 𝑖 𝑢/𝑖 u/i 的 𝑘 − h o p 𝑘-hop k−hop 邻域内的信息。 在图 G 上,预测分数计算如下:
y ^ u , i = f ( u , i ) = < e u ∗ , e i ∗ > \hat y_{u,i}=f(u,i)=<e_u^*,e_i^*> y^u,i=f(u,i)=<eu∗,ei∗> -
其中 𝑒 𝑢 ∗ 𝑒^∗_𝑢 eu∗ 和 𝑒 𝑖 ∗ 𝑒^∗_𝑖 ei∗ 表示 𝐾 𝐾 K 卷积层之后的高阶特征。 受 ResNet的启发,许多研究表明,使用跳跃连接来组合 GCN 层可以有效地解决过度平滑问题。 在一个常见的范式中,组合运算符用于从历史表示 [ 𝑒 𝑢 0 、 𝑒 𝑢 1 、 ⋅ ⋅ ⋅ 、 𝑒 𝑢 𝐾 ] 、 [ 𝑒 𝑖 0 、 𝑒 𝑖 1 、 ⋅ ⋅ ⋅ 、 𝑒 𝑖 𝐾 ] [𝑒^0_𝑢、𝑒^1_𝑢、···、𝑒^𝐾_𝑢 ]、[𝑒^0_𝑖、𝑒^1_ 𝑖、···、𝑒^𝐾_𝑖 ] [eu0、eu1、⋅⋅⋅、euK]、[ei0、ei1、⋅⋅⋅、eiK] 和 Eq.( 3) 可扩展为:
e 𝑢 ∗ = 𝐶 𝑜 𝑚 𝑏 ( e 𝑢 0 , e 𝑢 1 , . . . , e 𝑢 𝐾 ) , e 𝑖 ∗ = 𝐶 𝑜 𝑚 𝑏 ( e 𝑖 0 , e 𝑖 1 , . . . , e 6 𝐾 𝑖 ) ∈ R ( 𝐾 + 1 ) d e^∗_𝑢 = 𝐶𝑜𝑚𝑏 (e^0_𝑢, e^1_𝑢, ..., e^𝐾_𝑢 ), e^∗_𝑖 = 𝐶𝑜𝑚𝑏 (e^0_𝑖 , e^1_𝑖 , ..., e6𝐾_𝑖 ) ∈ R^{(𝐾+1)d} eu∗=Comb(eu0,eu1,...,euK),ei∗=Comb(ei0,ei1,...,e6Ki)∈R(K+1)d
其中 𝐶 𝑜 𝑚 𝑏 𝐶𝑜𝑚𝑏 Comb 是 𝑢 𝑢 u 和 𝑖 𝑖 i 的 0 0 0 到 𝐾 𝐾 K 顺序特征的任意组合。 -
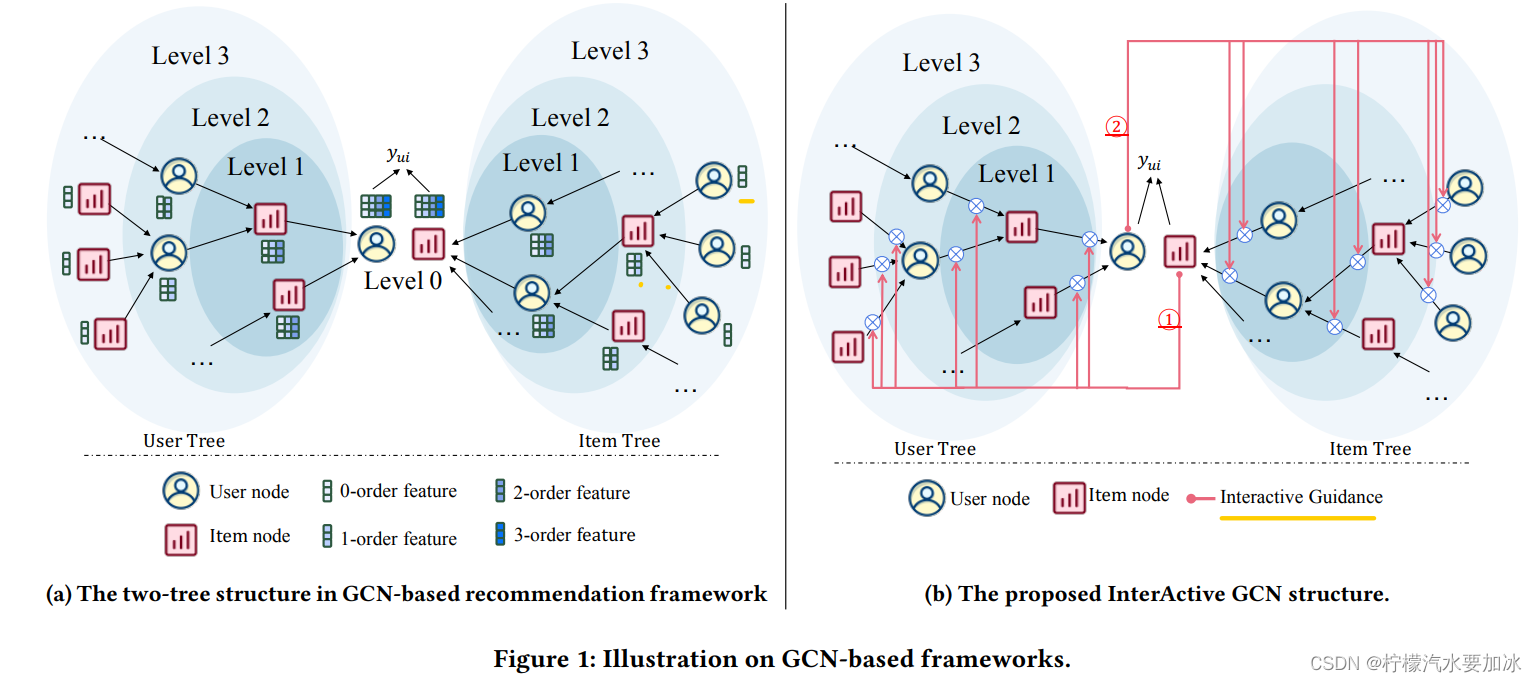
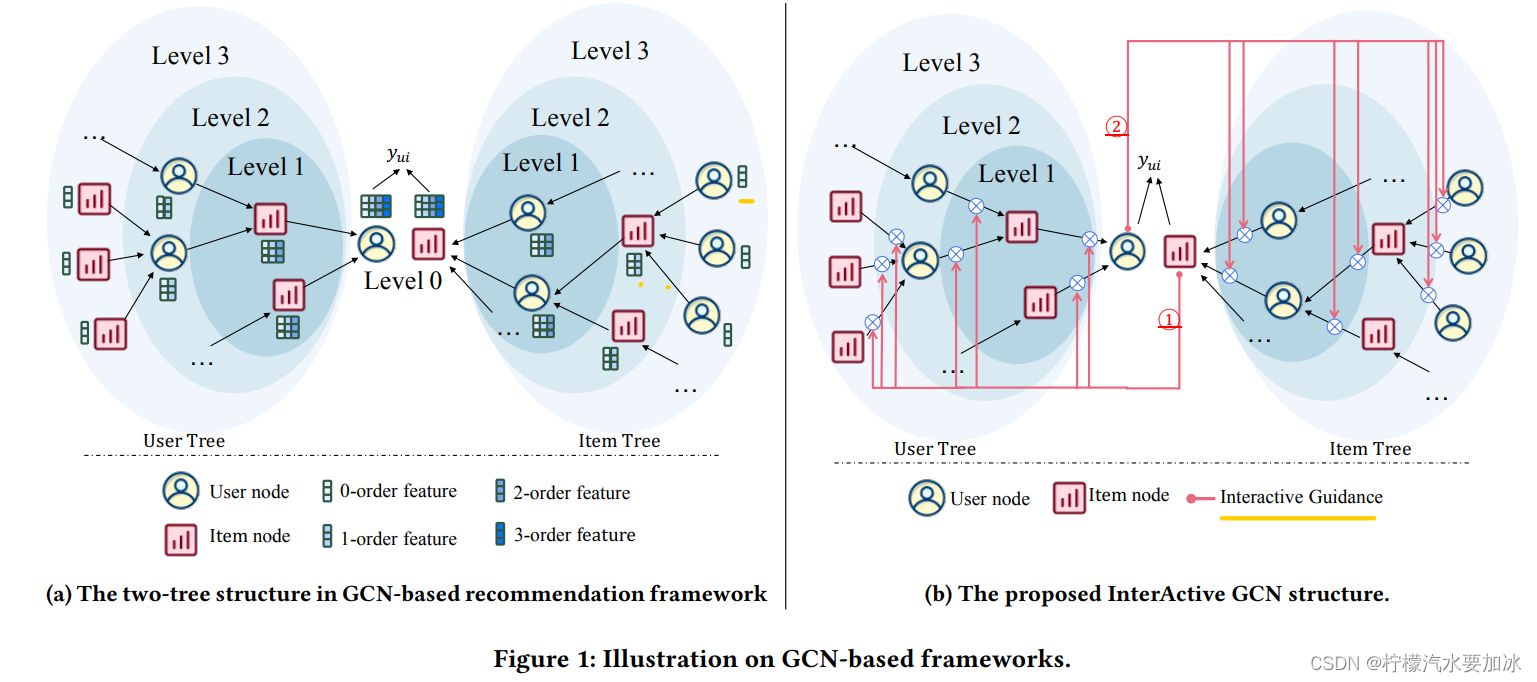
在文献中, 𝑢 / 𝑖 𝑢/𝑖 u/i 的高阶特征通常由两个树状结构计算,它们以 𝑢 / 𝑖 𝑢/𝑖 u/i 为根,由 𝐾 𝐾 K 堆叠图卷积层组成,如图1a所示。 具体来说,对于两棵树中的任何父节点 𝑝,其子集 N 𝑝 N_𝑝 Np 是从 𝑝 𝑝 p 在 G 中的直接邻居采样来的,并且父节点 𝑝 的 𝑘+1 阶特征是从他的子节点的 k k k 阶特征聚合过来的。
e 𝑝 𝑘 + 1 = 𝐴 𝑔 𝑔 ( e 𝑐 𝑘 : 𝑐 ∈ N 𝑝 ) , 𝑘 ∈ { 0 , . . . , 𝐾 − 1 } e^{𝑘 +1}_𝑝 = 𝐴𝑔𝑔(e^𝑘_𝑐 : 𝑐 ∈ N𝑝 ), 𝑘 ∈ \{0, ..., 𝐾 - 1\} epk+1=Agg(eck:c∈Np),k∈{0,...,K−1}
其中 𝐴 𝑔 𝑔 𝐴𝑔𝑔 Agg 是一个聚合器函数,它结合了孩子的特征。 该卷积操作沿树从下到上迭代使用,产生 e 𝑢 ∗ e^∗_𝑢 eu∗ 和 e 𝑖 ∗ e^∗_𝑖 ei∗ 用于最终偏好预测。
3.3 IA-GCN模型
3.3.1 什么是交互?
- 对于任意两个不同的 item i ≠ j i \not = j i=j , 用于预测 y ^ u , i \hat y_{u,i} y^u,i 和 y ^ u , j \hat y_{u,j} y^u,j 的嵌入表示 e u ∗ e_u^* eu∗ 是一样的;
- 对于任意两个不同的 user u ≠ v u \not = v u=v , 用于预测 y ^ u , i \hat y_{u,i} y^u,i 和 y ^ v , i \hat y_{v,i} y^v,i 的嵌入表示 e i ∗ e_i^* ei∗ 是一样的;
意思是:对于不同的 item,按照原来的方法,用于预测 y ^ u , i \hat y_{u,i} y^u,i 和 y ^ u , j \hat y_{u,j} y^u,j 的嵌入表示 e u ∗ e_u^* eu∗ 是一样的,现在想让 e u ∗ e_u^* eu∗ 是不一样的,对 i 更喜欢就会在预测 y ^ u , i \hat y_{u,i} y^u,i 的时候把 e u ∗ e_u^* eu∗ 权重赋高。
为了解决这个限制,IA-GCN 在两棵树之间构建了显式交互:
- 目标用户 𝑢 指导项目(item)树中的聚合,即强调类似于 𝑢 的子项;
- 目标项目 𝑖 指导用户(user)树中的聚合,即为类似于 𝑖 的子项分配更高重要性。
这种交互式指南使 IA-GCN 能够通过每个图卷积关注特定于目标的信息。 因此,得到的目标 𝑢/𝑖 的高阶特征不是固定的,而是以目标用户-项目对中对应的 𝑖/𝑢 为条件: 𝑒 𝑢 ∗ ∣ 𝑖 𝑒^∗_𝑢 |𝑖 eu∗∣i 和 𝑒 𝑖 ∗ ∣ 𝑢 𝑒^∗_𝑖 |𝑢 ei∗∣u。(即用于预测 y ^ u , i \hat y_{u,i} y^u,i 和 y ^ u , j \hat y_{u,j} y^u,j 的嵌入表示 e u ∗ e_u^* eu∗ 现在是不一样的了,用 𝑒 𝑢 ∗ ∣ 𝑖 𝑒^∗_𝑢 |𝑖 eu∗∣i 来预测 y ^ u , i \hat y_{u,i} y^u,i,用 𝑒 𝑢 ∗ ∣ j 𝑒^∗_𝑢|j eu∗∣j 来预测 y ^ u , j \hat y_{u,j} y^u,j)
那么如何衡量要聚合的子节点与其向导(即另一棵树的根)之间的相似性?
3.3.2 交互指导
考虑一个图卷积运算,它在节点 𝑔 的指导下,通过聚合其子节点 ∀ 𝑐 ∈ N 𝑝 ∀𝑐 ∈ N𝑝 ∀c∈Np 的特征来计算父节点 𝑝 的高阶特征。
使用交互式引导策略,有以下两种情况:
- 𝑔 = 𝑖 𝑔 = 𝑖 g=i,并且 𝑐 ∈ N u 𝑐 ∈ N_u c∈Nu ,即目标 i t e m item item指导 u s e r user user树中的邻域聚合。 如图1b①所示。
- 𝑔 = 𝑢 𝑔 = 𝑢 g=u,且 𝑐 ∈ N 𝑖 𝑐 ∈ N_𝑖 c∈Ni,即目标 u s e r user user 引导 i t e m item item树中的邻域聚合。 如图1b②所示。
具体来说,当聚合到 𝑝 (父节点) 时,𝑐 的重要性是根据 𝑐 与引导 𝑔 的相似性/相关性来分配的。
该策略的有如下几个注意事项:
-
首先,𝑐 和 𝑔 的高阶特征虽然可用,但可能由于邻域传播而产生噪声。 所以只从 𝑐 和 𝑔 的 0 阶特征计算重要性分数。
-
其次,𝑐 和 𝑔 的嵌入向量的简单内积对于计算注意力系数应该是可行的。 当 𝑐 和 𝑔 是同构节点时,它用作相似度度量。 当它们是异质的时,它量化了用户-项目对之间的相关性。
-
第三,更多的孩子,即更大的 ∣ N 𝑝 ∣ |N𝑝| ∣Np∣,并不一定表明 𝑝 𝑝 p 更重要。 所以 𝑝 𝑝 p 聚合的高阶特征的规模不应该随着 ∣ N 𝑝 ∣ |N𝑝| ∣Np∣的增加而增加。 因此,我们将控制 ∀ 𝑐 ∈ N 𝑝 ∀𝑐 ∈ N𝑝 ∀c∈Np 上所有相似性的总规模。
-
最后,我们将由 𝑔 引导的孩子 𝑐 对 𝑝 的重要性公式化为:
α 𝑝 , 𝑐 ∣ 𝑔 = e x p ( < e g 0 , e c > / τ ) ∑ 𝑐 ′ ∈ N p e x p ( < e g 0 , e c ′ > / τ ) \alpha_{𝑝, 𝑐}| 𝑔 =\frac {exp (<e^0_g, e_c> / \tau) }{\sum_{𝑐'∈N_p} exp(<e^0_g, e_{c′}> / \tau)} αp,c∣g=∑c′∈Npexp(<eg0,ec′>/τ)exp(<eg0,ec>/τ)
其中 τ \tau τ 是温度参数。等式(6)中的 softmax 层为确保 ∑ 𝑐 ∈ N p α 𝑝 , 𝑐 ∣ 𝑔 = 1 \sum_{𝑐 ∈N_p}\alpha_{𝑝,𝑐} |𝑔 = 1 ∑c∈Npαp,c∣g=1。
请注意,IA-GCN 中的这种聚合重要性与 GCN 中现有的注意机制(例如 GAT 根本不同。 我们的 α 𝑝 , 𝑐 ∣ 𝑔 \alpha_{𝑝,𝑐}|𝑔 αp,c∣g 取决于𝑐 与𝑔 的相似性,即来自另一棵树的交互式引导。 而在现有的注意力中, α 𝑝 , 𝑐 \alpha_{𝑝,𝑐} αp,c 取决于 𝑐 与 𝑝 的相似性。 由于使用的知识仍然仅限于𝑐自己的单棵树,现有算法无法提取交互特征。
3.3.3 交互卷积
在前面的部分中,关注如何在聚合器中分配重要性,现在我们深入研究式(5)中聚合器的设计。
在文献中,早期的 GCN 工作大多属于繁重的流程:线性变换、加权和池化和非线性激活 。 虽然最近的研究强调了这样一个事实,即轻型聚合器(例如加权和池)通常可以实现最先进的性能。 以何向南老师的 LightGCN 模型为例。
当聚合
𝑐
∈
N
𝑝
𝑐 ∈ N_𝑝
c∈Np到
𝑝
𝑝
p 时,他们使用:
e
𝑝
𝑘
+
1
=
∑
𝑐
∈
N
𝑝
1
∣
N
𝑝
∣
∣
N
𝑐
∣
e
𝑐
𝑘
e^{𝑘 +1}_𝑝= \sum_{𝑐 ∈N_𝑝} \frac 1 { \sqrt{{|N_𝑝|}{|N_𝑐|}}}e^𝑘_𝑐
epk+1=c∈Np∑∣Np∣∣Nc∣1eck
其中它们的聚合权重是基于𝑐和𝑝自己的树中的信息的简单归一化。
由于 IA-GCN 的重点是在两棵树之间引入交互式指导,本文遵循简单且经过验证的有效加权和池聚合器。 使用建议的交互式指导,我们的卷积操作被表述为:
e
𝑝
𝑘
+
1
∣
g
=
∑
𝑐
∈
N
𝑝
α
p
,
c
∣
g
e
𝑐
𝑘
e^{𝑘 +1}_𝑝|g= \sum_{𝑐 ∈N_𝑝} \alpha_{p,c}|g \space e^𝑘_𝑐
epk+1∣g=c∈Np∑αp,c∣g eck
其中 α 𝑝 , 𝑐 ∣ 𝑔 \alpha_{𝑝,𝑐} | 𝑔 αp,c∣g是交互权重,在等式(6)中定义
请注意,IA-GCN 是一个易于插入的模块,理论上可以应用于任何基于 GCN 的推荐方法。 通过将我们的交互权重相乘,许多现有算法将受益于学习到的用户-项目交互知识。
3.3.4 层组合和模型预测
在介绍了消息传递的方式之后,我们通过公式(8)中定义的 𝐴𝑔𝑔 运算符从原始嵌入 𝑒0 开始聚合 𝑘 + 1 阶特征。 然后应用等式(4)中提到的组合算子从顺序层收集有影响的信息。 这样的𝐶𝑜𝑚𝑏操作可以重新表述如下:
e
𝑝
∗
∣
𝑔
=
𝐶
𝑜
𝑚
𝑏
(
𝑒
𝑝
0
∣
𝑔
,
𝑒
𝑝
1
∣
𝑔
,
⋅
⋅
⋅
,
𝑒
𝑝
𝐾
∣
𝑔
)
e^∗_𝑝|𝑔 = 𝐶𝑜𝑚𝑏 (𝑒^0_𝑝|𝑔,\space 𝑒^1_𝑝|𝑔, · · · ,\space 𝑒^𝐾_𝑝|𝑔)
ep∗∣g=Comb(ep0∣g, ep1∣g,⋅⋅⋅, epK∣g)
具体来说,我们工作中的𝐶𝑜𝑚𝑏可以概括为:
e
p
∗
∣
g
=
∑
k
=
0
K
β
𝑘
𝑒
𝑝
𝑘
∣
𝑔
s
.
t
.
β
𝑘
≥
0
&
∑
k
=
0
K
β
𝑘
=
1
e^∗_p|g =\sum_{k=0}^K \space \beta _𝑘 \space 𝑒^𝑘_𝑝|𝑔 \\ s.t. \beta_𝑘 ≥ 0\quad \& \space \sum_{k=0}^K \beta_𝑘 = 1
ep∗∣g=k=0∑K βk epk∣gs.t.βk≥0& k=0∑Kβk=1
β
𝑘
\beta_𝑘
βk 表示从k 阶特征收集信息的比率/重要性。
β
𝑘
\beta_𝑘
βk不仅可以基于专家知识调整超参数,还可以与图卷积层共同学习变量。 与等式(2)一样,我们考虑到交互式引导的预测如下:
y
^
𝑢
,
𝑖
=
𝑓
(
𝑢
,
𝑖
)
=
<
e
𝑢
∗
∣
𝑖
,
e
𝑖
∗
∣
𝑢
>
\hat y_{𝑢, 𝑖} = 𝑓 (𝑢, 𝑖) = <e^*_𝑢 | 𝑖, e^*_𝑖 | 𝑢>
y^u,i=f(u,i)=<eu∗∣i,ei∗∣u>
它从早期阶段对目标用户和目标项目之间的交互进行建模,通过每个卷积操作保留宝贵的目标特定信息,并在最后对交互概率进行预测。
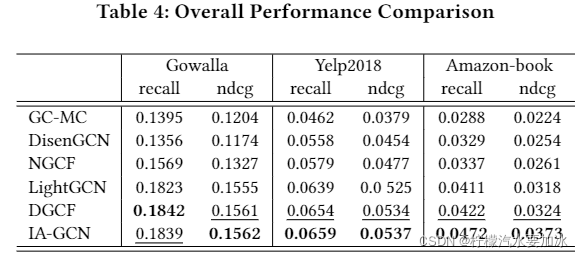
4. 实验结果