李宏毅机器学习第十一周self-attention
文章目录
- week 11 Self-attention
- 摘要
- Abstract
week 11 Self-attention
摘要
之前学习的网络,例如传统CNN仅能考虑感受野范围内的信息,且输入通常是以向量的形式。本周学习的self-attention机制赋予了网络考虑全局信息的能力。这种网络的输出是多种多样的,本文中以“每个向量对应一个标签”这一输出的类型为例说明网络结构。self-attention层主要依赖注意力机制计算各个向量之间的相关性,有两种计算方法dot-product与additive,在本文的3.1部分着重对dot-product方法的计算流程进行了介绍。在CNN中有多个卷积核从而针对多种模式进行匹配的经验,self-attention中同样可以通过Multi-head Self-attention计算向量间多种标准下的相关性。self-attention还引入了position encoding,从而使得网络可以考虑向量的位置信息。最后在该部分末尾给出了self-attention在多个领域的应用,并将其与CNN、RNN进行了比较。实现并训练了LSTM模型。本周阅读的文献构建了一种FAM-LSTM模型,用于日光温室温度和湿度的多步预测,并获得了较高精度。
Abstract
Previously learned networks, such as traditional CNNs, can only consider information in the range of receptive fields, and the input is usually in the form of vector. The self-attention mechanism learned this week gives the network the ability to consider the global information. The output of such a network is varied, and the type of output “one label per vector” is used as an example to illustrate the network structure. The self-attention layer mainly relies on the attention mechanism to calculate the correlation between each vector, and there are two calculation methods, dot-product and additive, and the calculation process of the dot-product method is introduced in Part 3.1 of this article. In the experience of having multiple convolution kernels in CNNs to match multiple patterns, self-attention can also calculate the correlation between vectors under multiple criteria through multi-head self-attention. Self-attention also introduces position encoding, which allows the network to consider the location information of vectors. Finally, at the end of the section, the application of self-attention in multiple fields is given, and self-attention was compared to CNNs and RNNs. The LSTM model is implemented and trained. The literature read this week constructs a FAM-LSTM model for multi-step prediction of solar greenhouse temperature and humidity, and obtains high accuracy.
一、李宏毅机器学习self-attention
1. vector set as input
在之前学习的网络结构中,输入通常是一个向量,输出为值或者类。那么是否有一种网络,其输入为一组长度各异的向量,而输出为多个值或者类
例如文字处理,其输入为一个文字组成的序列。但文字并不能使用one-hot encoding的方式进行编码,因为one-hot encoding的前提假设是各元素是不相关的,而文字并不具有这种特性。因此使用文字作为序列的组成元素。
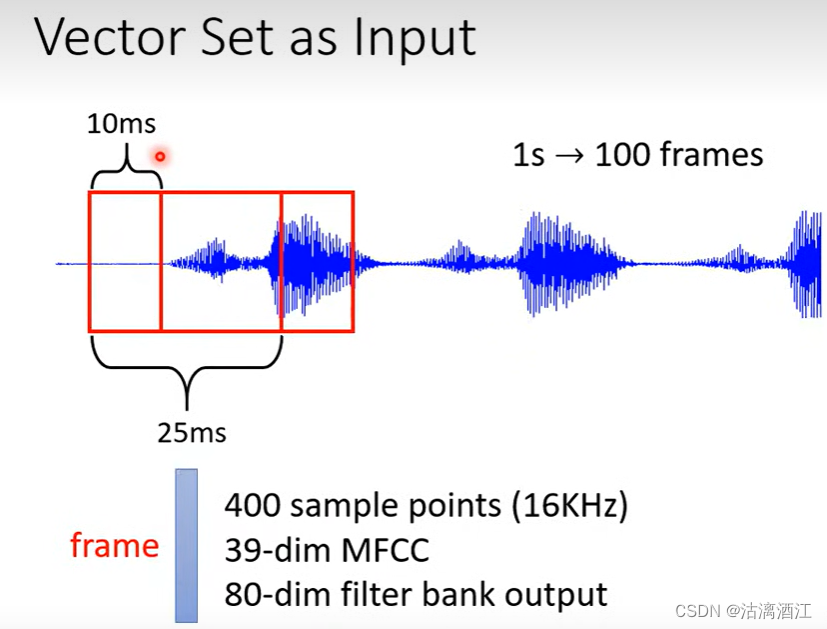
例如语音处理,其输入为一段声音讯号的序列,将其转换为一组向量序列,具体方法见下图。通常将1s分割为100frames。
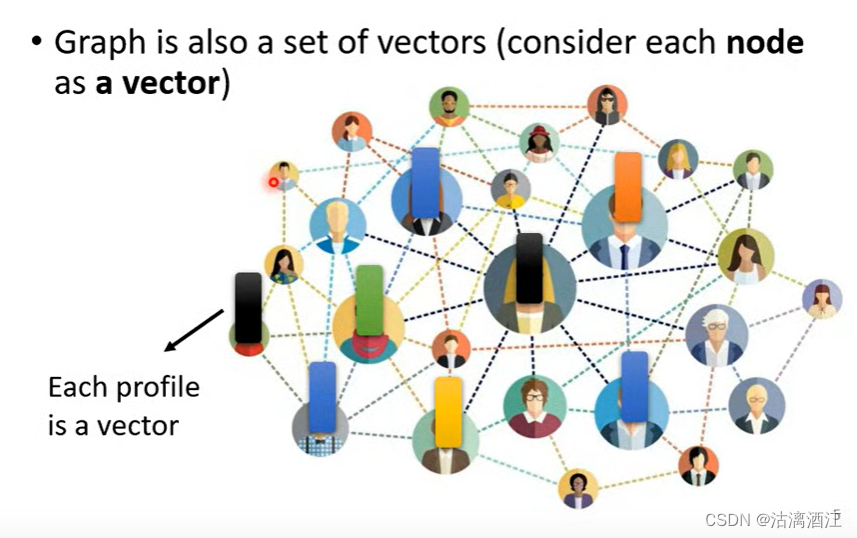
一个图可以看作一组向量,例如下图中人物关系图,可以将节点中一个人的详细信息作为一个向量,而这个图则由多个这样的向量组成。
在分子式中,可以将各个原子使用one-hot vector表示,从而以一组向量表示分子
2. what is the output?
- 每个向量对应一个标签,例如字符标记、HW2、social network……
- 整个序列对应一个标签,例如评论标记、HW4、分子标记……
- 由模型决定输出的标签个数,seq2seq,例如翻译(HW5)
3. Eg.sequence labeling
每个向量对应一个标签
下面以词语标记为例讲解该网络的大致结构
对于全连接网络,若逐个输入词语,则网络无法考虑整个序列从而确定该词语的属性。例如"I saw a saw.",尽管两个"saw"是不同词性的,但是对于全连接网络,两者是相同的。
对于上述问题,HW2中给出的解决方案是将一个窗口内的多个词语同时作为网络的输入,从而减小无法看到整个序列所带来的影响。
但上述方法是有极限的,其对于长度各异的输入序列是不奏效的,因为长度不确定从而window无法适配。更严重的是在week8中已经遇到了concat_nframe过大导致内存溢出的问题,这表明一味的增大window size从实际角度来讲是不现实的。
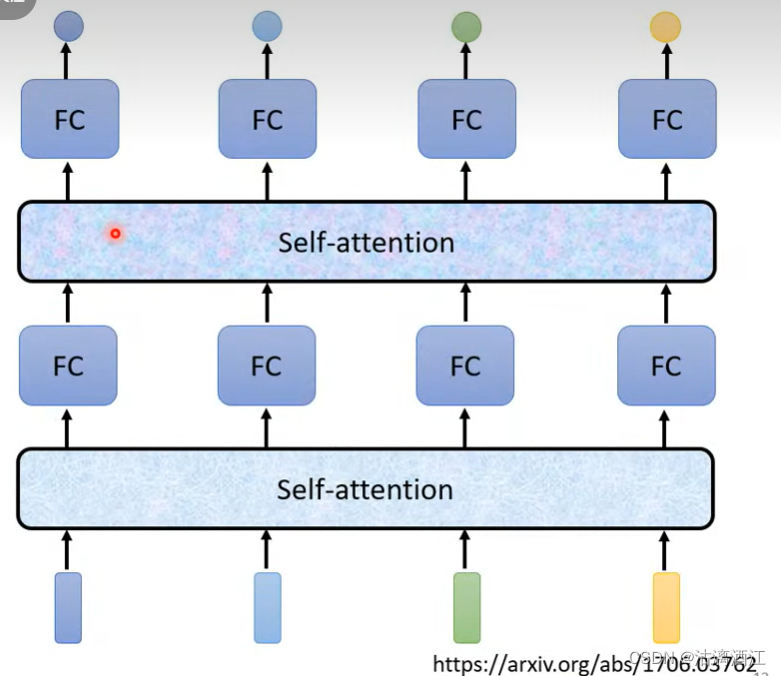
self-attention的网络可以实现上述要求,可以将整个序列输入self-attention network,其会对应每个向量给出一个向量,随后将经过self-attention处理的向量序列输入全连接网络进行处理。
self-attention可以考虑整个序列,全连接可以针对单个向量处理。二者可以以类似CNN中卷积层与池化层的组织方式,按照需求交替的设置self-attention layer与全连接层。
在arxiv的一篇论文Attention is all you need.中提出了transformer模型,文中实现了基于self-attention的网络结构。下面介绍self-attention大致的机制
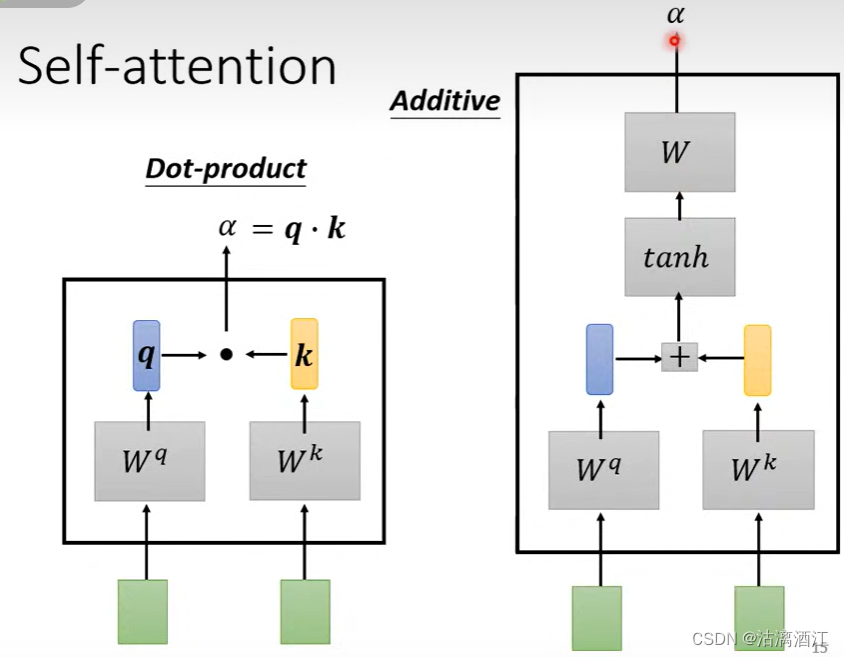
以下解释如何根据对应向量考虑整个序列,首先,考虑对应向量与其他各个向量的相关性,有dot-product, additive等算法可以实现该需求,下面为提到的两种算法的大致流程。
- 假设对应向量
x
x
x,现考虑其与向量
x
′
x'
x′的相关性,则有
- dot-product
- 两个向量乘以对应矩阵,再点乘即为输出值
- q = W q x , k = W k x ′ , α = q ⋅ k q=W^qx,\ k=W^kx', \alpha=q\cdot k q=Wqx, k=Wkx′,α=q⋅k
- additive
- 两个向量乘以对应矩阵,再相加,经过 t a n h tanh tanh函数,最后transform之后输出
- dot-product
3.1 framework of self-attention
本文中主要用到的方法是dot-product
在网络中使用dot-product计算相关性的流程如下,假设要查询 a 1 a^1 a1与其他向量的相关性
- 首先,计算 q u e r y query query向量 q 1 = W q a 1 q^1=W^qa^1 q1=Wqa1,之后计算 k e y key key向量 k i = W k a i k^i=W^ka^i ki=Wkai, a i a^i ai为输入序列中的所有向量。
- 其次,计算
a
t
t
e
n
t
i
o
n
s
c
o
r
e
attention\ score
attention score,若查询向量对应
a
1
a^1
a1、关键词向量对应
a
2
a^2
a2,则有
α
1
,
2
=
q
1
⋅
k
2
\alpha_{1,2}=q^1\cdot k^2
α1,2=q1⋅k2
- 以此类推计算所有向量的attention score
- 之后,将所有的 a t t e n t i o n s c o r e attention score attentionscore输入soft-max中,将其映射为一个分布, α 1 , 2 \alpha_{1,2} α1,2对应的输出为 α 1 , 2 ′ \alpha'_{1,2} α1,2′
- 最后,将 a i a^i ai乘上矩阵 W v W^v Wv,得到 v i v^i vi,用 α 1 , i ′ \alpha'_{1,i} α1,i′乘上 v i v^i vi,将所有的按照该流程的得到的结果累加 b 1 = ∑ i α 1 , i ′ v i b^1=\sum_i{\alpha'_{1,i}v^i} b1=∑iα1,i′vi, a i a^i ai为输入序列中的所有向量。若其他向量 b i b^i bi与 b 1 b^1 b1越相近,则 a i a^i ai与 a 1 a^1 a1越相近
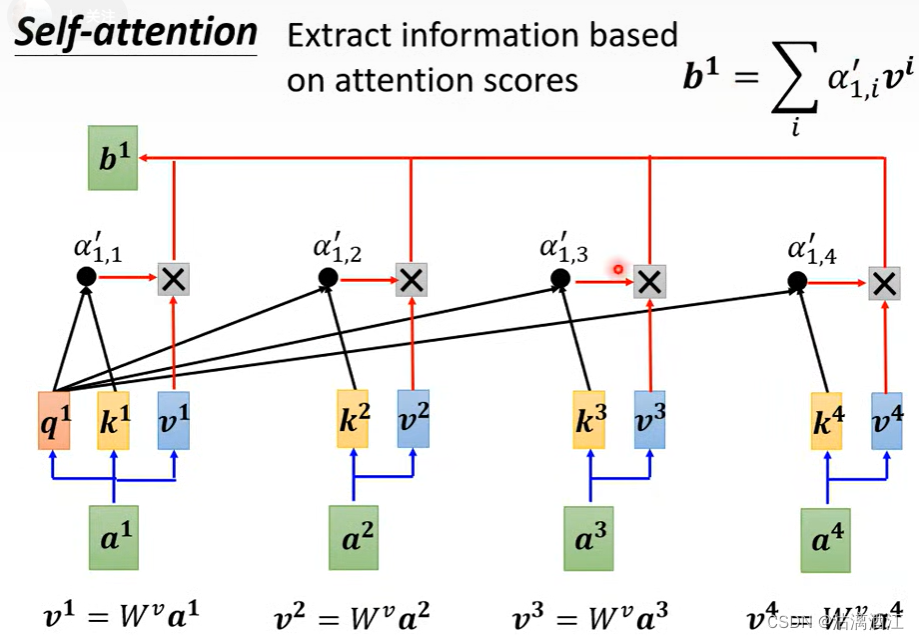
大致计算过程如下

其中 A ′ A' A′称作 a t t e n t i o n m a t r i x attention\ matrix attention matrix, W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv三个矩阵中是需要训练的参数
3.2 Multi-head Self-attention
对于多种相关性的任务,可以使用更多的参数矩阵得到更多的矩阵来计算多种相关性,这样的网络就是 M u l t i − h e a d S e l f − a t t e n t i o n Multi-head\ Self-attention Multi−head Self−attention
翻译、语音辨识等任务适用比较多head,这是一个需要程序员调整的超参
以下以两个head为例,计算过程如下
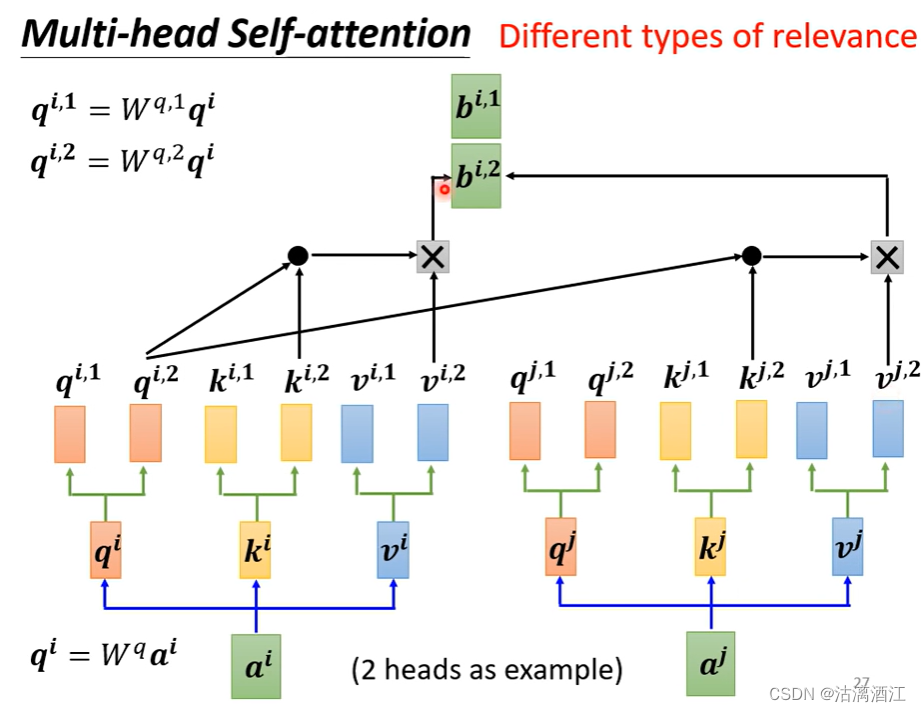
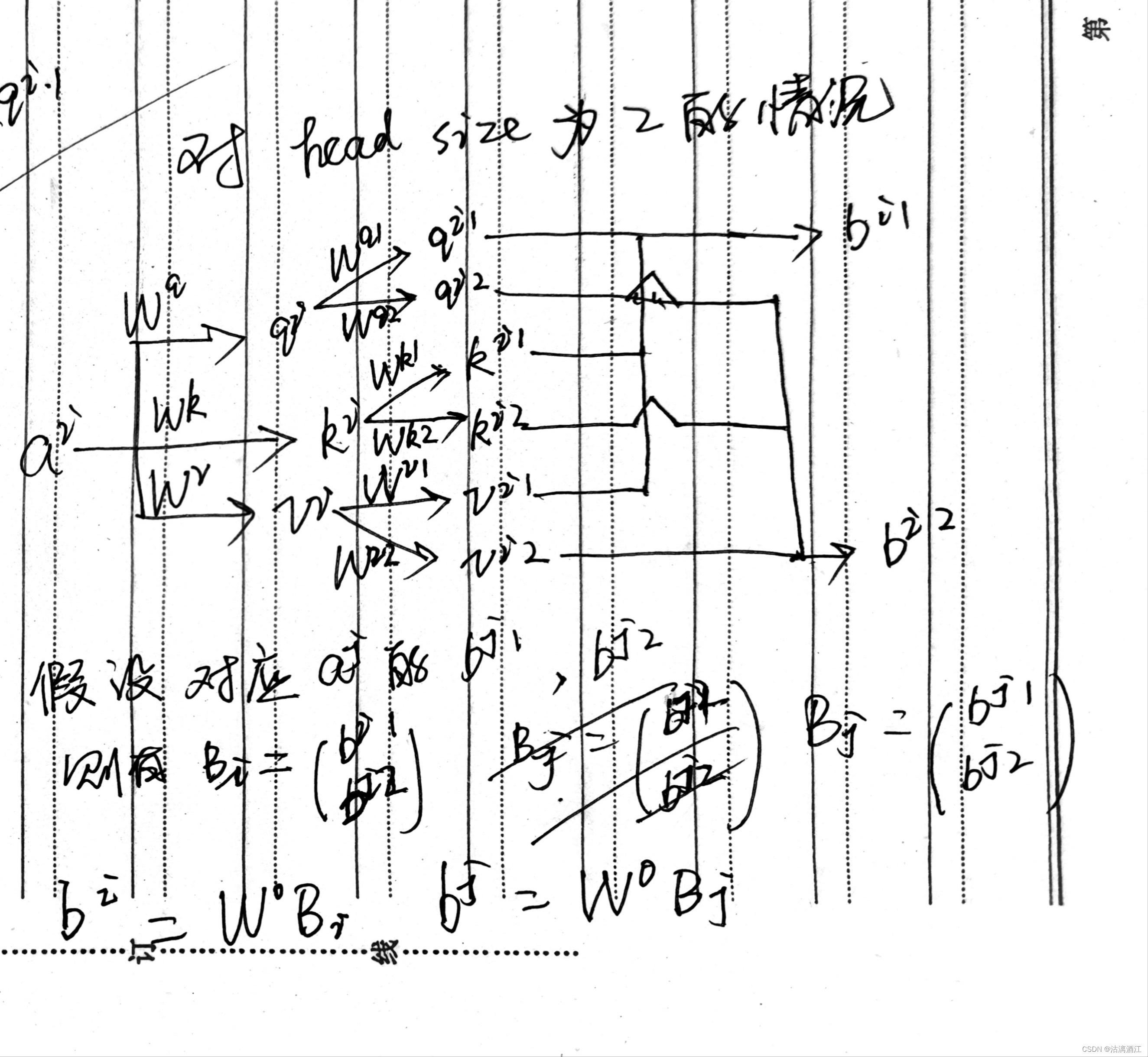
3.3 Positional Encoding
在上述的各种self-attention网络结构中没有体现位置信息,而位置信息在例如语义辨识等任务中是较为重要的。为了解决该问题,可以对每个位置设定一个特定的向量 e i e^i ei,这个矩阵可以是根据特定规则直接产生的,也可以设置为参数让网络自行训练产生
下图右侧是矩阵E,其中的每一列都代表了对应位置的向量
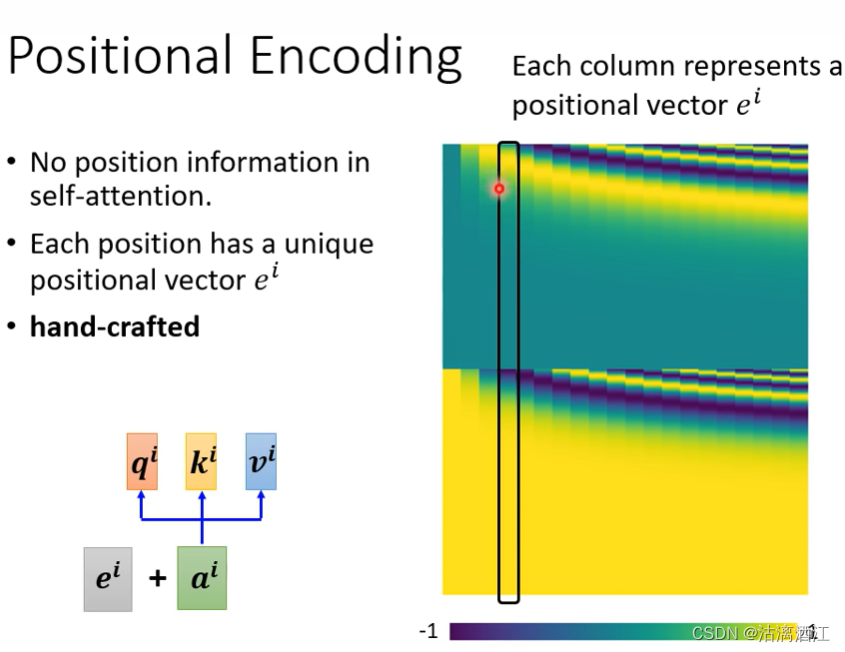
这是一个尚待开发的课题,可以尝试自行确定一种用于产生位置矩阵的方法
关于Positional Encoding,可以参考该论文,文中研究了多种方法并进行了分析,部分效果如下图
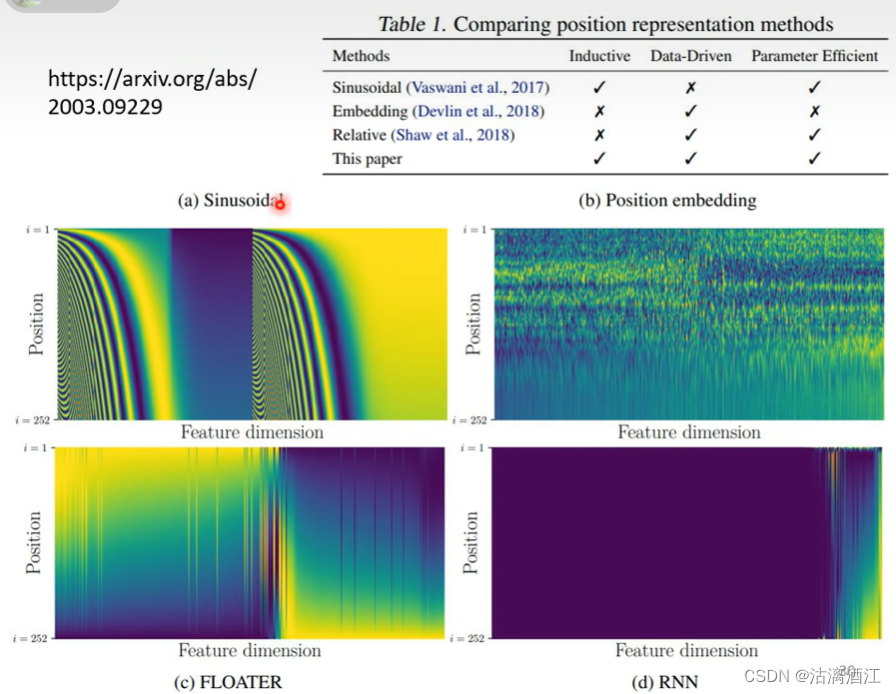
4. More application
4.1 NLP

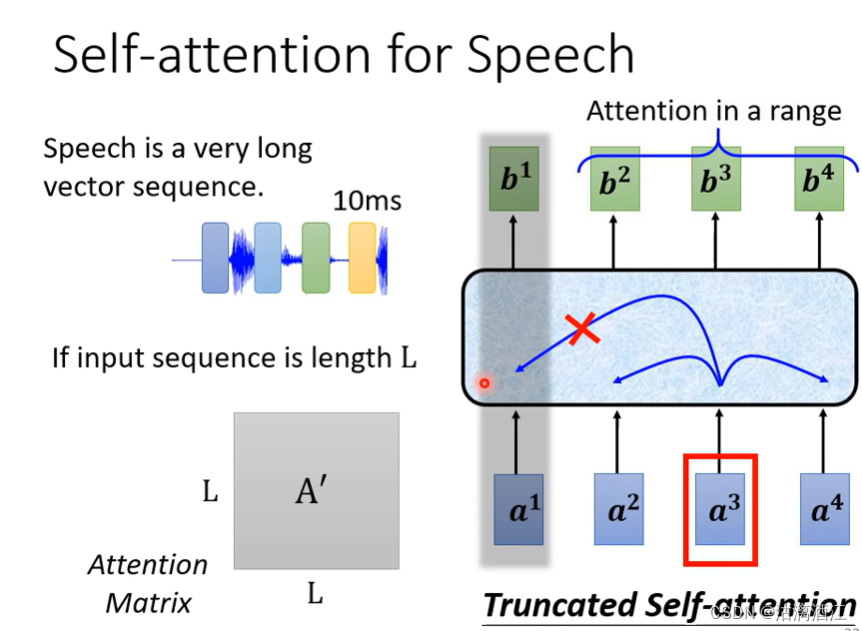
4.2 self-attention for speech
在语音辨识领域,可以将10ms的语音表示为一个向量,从而将语音讯号转换为一组向量。以这种方法表示声音讯号所需的数据量较大,因此让网络可以仅考虑一部分的向量,类似HW2中做的那样,这种网络称作Truncated Self-attention。
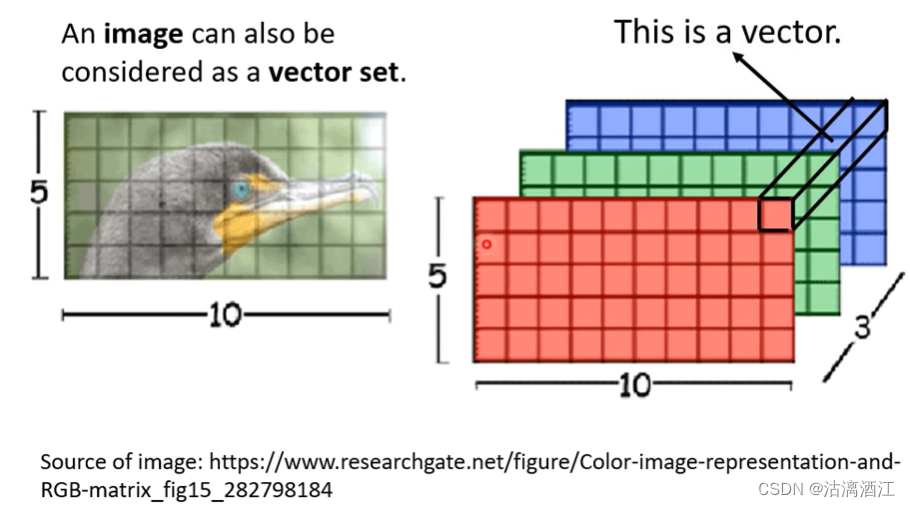
4.3 self-attention for image
使用该网络处理图片需要将图片转换为一个向量组。对于3个频道的图片,如下图,可以将每个pixel看作一个向量。
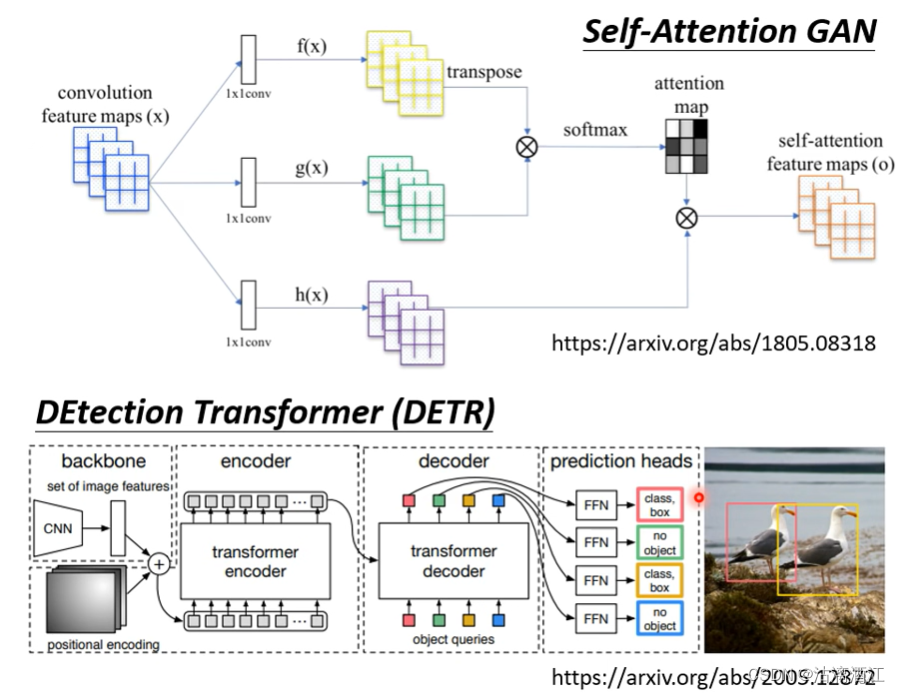
以下是使用该网络处理影响的两个例子
4.4 Self-attention for Graph
图中节点相连表明了两个节点是具有相关性的,因此计算attention matrix时,仅需考虑相连节点的相关性,可以看作一种GNN。

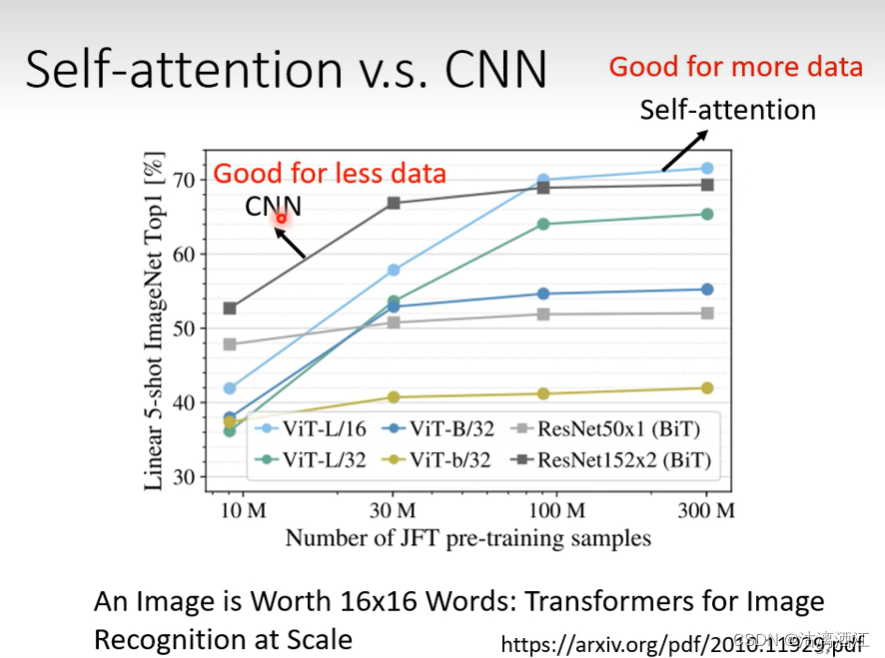
5. self-attention v.s. CNN
CNN仅能考虑一个感受野范围内的数据,相当于一个简化的self-attention。self-attention相当于一个具有可学习感受野的CNN。相应的self-attention的模型复杂度较高,当数据量不足时,容易过拟合。而CNN模型的限制较大,当数据量不足时,不那么容易过拟合。效果如下图
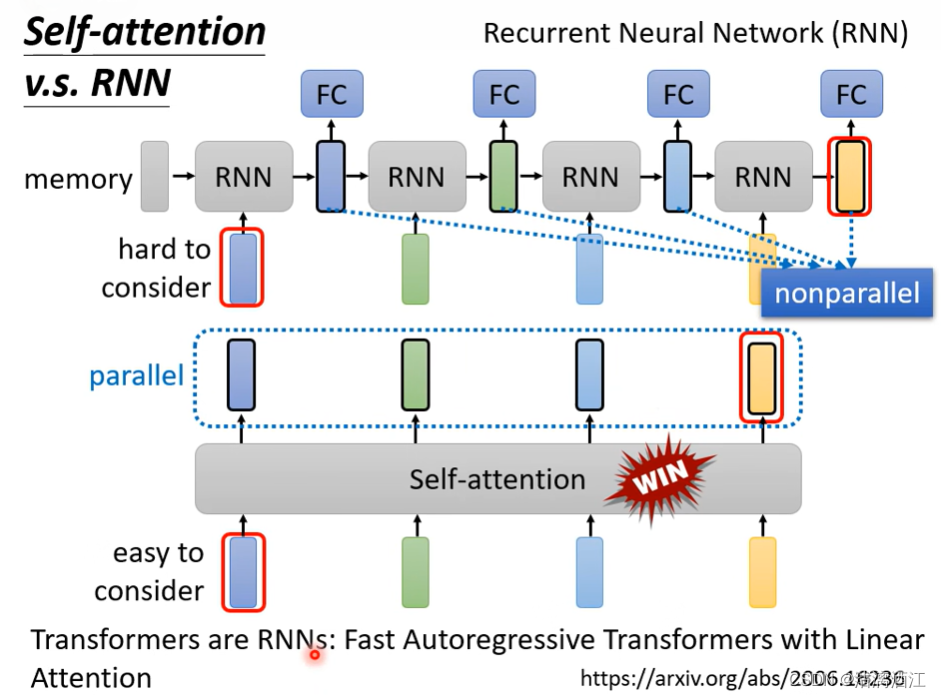
6. self-attention v.s. RNN
二者的输入均为一个序列。但RNN不可以进行平行运算,且单向RNN不能考虑未输入向量。
二、基于Pytorch的LSTM实现
1. 数据集和问题的定义
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
使用seaborn库内置所有数据集列表sns.get_dataset_names()
使用航班数据集
flight_data = sns.load_dataset("flights")
数据集中有144行3列,任务是基于132个月预测最近12个旅行的乘客人数
以下设定默认图形大小
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 15
fig_size[1] = 5
plt.rcParams["figure.figsize"] = fig_size
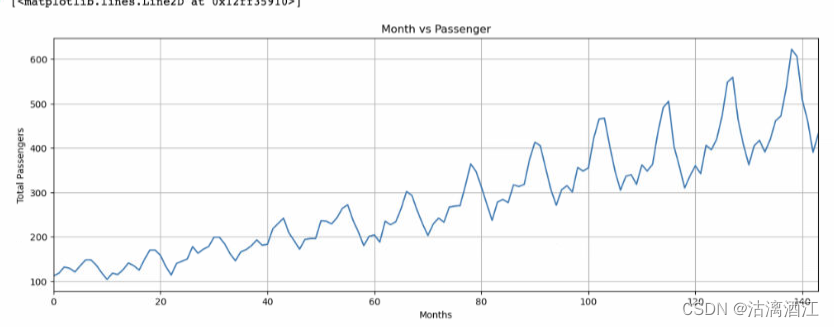
绘制乘客数量每月出现的频率
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.xlabel('Months')
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(flight_data['passengers'])
2. 数据预处理
将乘客列的类型修改为浮点数
all_data = flight_data['passengers'].values.astype(float)
分割数据集为训练集和测试集。划分前132条记录为训练信息,最后12条信息为测试集
test_data_size = 12
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
数据归一化,使用sklearn.preprocessing模块中的MinMaxScaler缩放数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data .reshape(-1, 1))
用FloatTensor将数据转换为张量
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
设置序列输入长度
train_window = 12
分割输入序列为元组列表,每个元组中首个元素包含12个项目的列表,对应于12个月内旅行乘客数量,第二个元素仅包含后续一个月的乘客数量
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]
inout_seq.append((train_seq ,train_label))
return inout_seq
创建训练序列以及标签
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
3. 创建LSTM模型
定义训练模型
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.linear=nn.Linear(100,1)
self.lstm = nn.LSTM(input_size, hidden_layer_size)
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq) ,1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
4. 训练模型
创建模型对象、损失函数以及优化器
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
训练过程
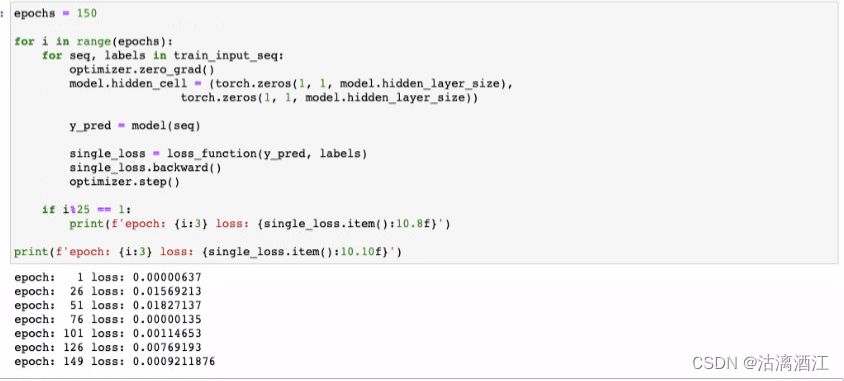
epochs = 150
for i in range(epochs):
for seq, labels in train_inout_seq:
optimizer.zero_grad()
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
if i%25 == 1:
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
训练结果如下
4. 预测
筛选最后12个月的数据
fut_pred = 12
test_inputs = train_data_normalized[-train_window:].tolist()
print(test_inputs)
预测并打印结果
model.eval()
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append(model(seq).item())
test_inputs[fut_pred:]
将归一化后的预测结果还原
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
print(actual_predictions)

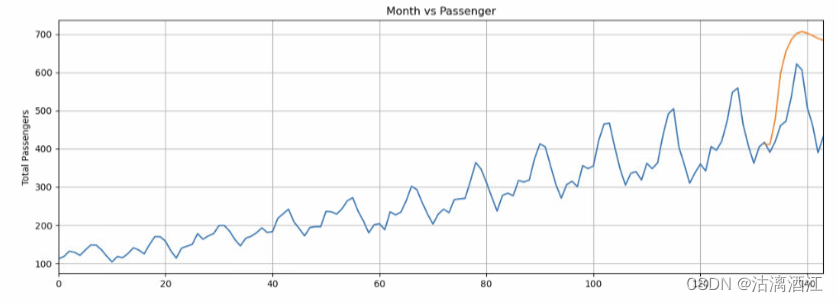
绘制预测图
x = np.arange(132, 144, 1)
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'])
plt.plot(x,actual_predictions)
plt.show()
三、文献阅读
1. 题目
题目:Multistep ahead prediction of temperature and humidity in solar greenhouse based on FAM-LSTM model
作者:Yongxia Yang1,2; Pan Gao1,3; Zhangtong Sun1,2; Haoyu Wang1,2; Miao Lu1,3; Yingying Liu1,2,3CA1; Jin Hu1,2,3CA2
期刊:Computers and Electronics in Agriculture
2. abstract
This paper constructs a FAM-LSTM model for multi-step prediction of temperature and humidity in solar greenhouses. Compared to other models, the FAM-LSTM model stands out for its high precision.
该论文构建了一种前馈注意力机制-长期短期记忆(FAM-LSTM)模型,用于日光温室温度和湿度的多步预测。与其他模型相比,FAM-LSTM模型因其高精度而脱颖而出。
3. 网络架构
向量组首先经过lstm与dropout处理,然后输入注意力机制,随后输入全连接层后输出。
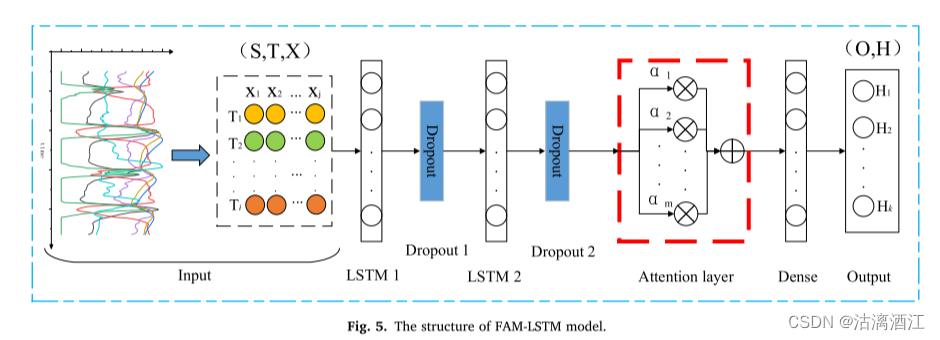
输入层:模型的输入是多维时间序列特征。输入层将输入数据转换为适合LSTM模型结构的三维数组形状(输入样本、时间步长、特征)(S,T,X),其中,S为输入样本的数量, T = T 1 , T 2 ⋯ T i T = {T_1,T_2⋯T_i} T=T1,T2⋯Ti(i为输入序列的时间步, T i T_i Ti表示第i个时间步), X = X 1 , X 2 ⋯ X j X = {X_1,X_2⋯X_j} X=X1,X2⋯Xj(j为输入序列的特征维度, X j X_j Xj表示表示第j维特征)
输出层:输出层用于实现预测结果的输出,输出维度为(输出样本,时间步)(O,H)。其中,O是输入样本的数量, H = H 1 , H 2 ⋯ H k H = {H_1,H_2⋯H_k} H=H1,H2⋯Hk(k是当前时间的向后预测时间步,Hk表示当前时间之后第k个时间步的预测温度)
下面对文中使用的LSTM与FAM框架进行解释
3.1 LSTM
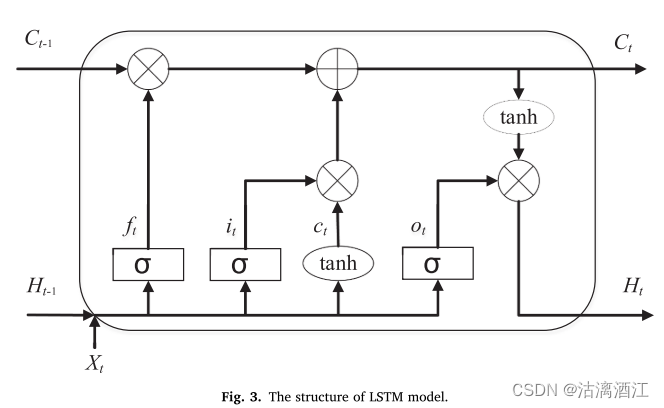
LSTM神经网络在t时刻的工作原理如下:
i t = σ ( W i [ H t − 1 , X t ] + b i ) i_t=\sigma(W_i[H_{t-1},X_t]+b_i) it=σ(Wi[Ht−1,Xt]+bi)
f t = σ ( W f [ H t − 1 , X t ] + b f ) f_t=\sigma(W_f[H_{t-1},X_t]+b_f) ft=σ(Wf[Ht−1,Xt]+bf)
C ~ t = tanh ( W C [ H t − 1 , X t ] + b C ) \tilde C_t=\tanh(W_C[H_{t-1},X_t]+b_C) C~t=tanh(WC[Ht−1,Xt]+bC)
C t = f t C t − 1 + i t C ~ t C_t=f_tC_{t-1}+i_t\tilde C_t Ct=ftCt−1+itC~t
o t = σ ( W o [ H t − 1 , X t ) + b o o_t=\sigma(W_o[H_{t-1},X_t)+b_o ot=σ(Wo[Ht−1,Xt)+bo
H t = o t tanh ( C t ) H_t=o_t\tanh(C_t) Ht=ottanh(Ct)
i t , f t , C ~ t , o t , H t i_t, f_t, \tilde C_t, o_t,H_t it,ft,C~t,ot,Ht分别表示t时刻的输入门、遗忘门、候选单元状态、输出门、当前单元状态和隐藏层状态。 X t X_t Xt为时间t的输入向量。
3.2 feed-forward attention mechanism
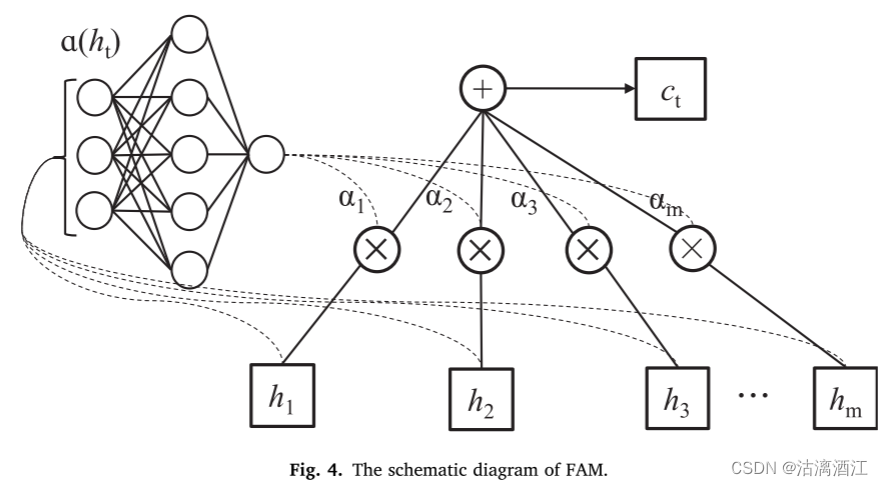
计算每个输入序列的重要性 h t = h 1 , h 2 , h 3 , … , h m h_t = {h_1, h_2, h_3,\dots,h_m} ht=h1,h2,h3,…,hm(其中m表示t时刻的输入序列的数量, h m h_m hm表示第m个输入序列),如式(9)所示。注意力计算过程生成输入 h t h_t ht在各个时间步的概率向量 α t = α 1 , α 2 , α 3 , … , α m \alpha_t={\alpha_1,\alpha_2,\alpha_3,\dots,\alpha_m} αt=α1,α2,α3,…,αm,如式(10)。此时的输出向量 c t c_t ct是由式(11)中定义的 α t \alpha_t αt为权重对输入进行自适应加权平均得到的。
FAM神经网络在t时刻的工作原理如下:
(9) e t = a ( h t ) e_t=a(h_t) et=a(ht)
(10) α m = exp ( e m ) ∑ n = 1 m α l h l \alpha_m=\frac{\exp(e_m)}{\sum_{n=1}^m\alpha_lh_l} αm=∑n=1mαlhlexp(em)
(11) c t = ∑ l = 1 m α l h l c_t=\sum_{l=1}^m\alpha_lh_l ct=∑l=1mαlhl
其中,a是可学习的函数; m是t时刻输入序列的数量; α m \alpha_m αm为t时刻第m个输入序列的概率向量; c t c_t ct 是t时刻输入序列的加权平均值。
4. 文献解读
4.1 Introduction
有一些机械模型,包括三维模拟模型(Saberian和Sajadiye,2019)和热力学模型(Ali et al.,2020),可以实现温室环境的动态预测。然而,机械模型容易受到边界条件和物理参数的定义的影响。在此研究中,利用 FAM 在不同时间步长为输入特征生成不同的注意力权重来预测温室温度和湿度。将FAM-LSTM模型与多个模型的准确性和误差进行了对比。结果表明,FAM-LSTM模型可以实现温室温湿度的精确多步预测。
4.2 创新点
通过物联网技术获取实验数据
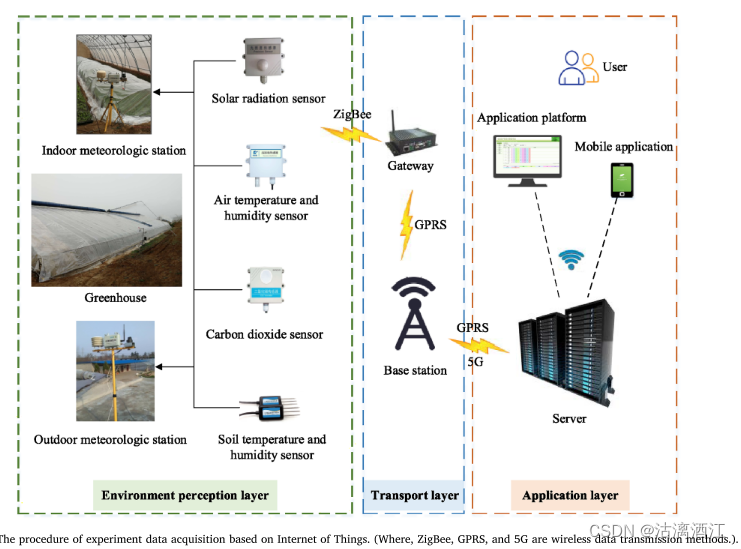
下图说明了通过物联网技术获取实验数据的流程。首先,传感器采集的数据通过ZigBee技术发送到网关,并通过GPRS技术传输到基站。随后,服务器与基站进行通信,并将获取的数据保存到数据库中。最后,用户可以从应用平台或移动应用程序下载数据。
Feed-forward attention mechanism - Long-Short term memory
该论文将LSTM与FAM相结合,提出了一种基于FAM-LSTM模型的温室温湿度时间序列预测模型
首先,利用LSTM模型来处理多元时间序列数据特征。随后,将FAM用于描述未来时间步长与每个时间步长的历史数据之间的关系。然后,通过向每个时间步长输入不同权重并加权求和来提取主要影响。
4.3 实验过程
Data acquisition
试验于2021年11月1日至2022年1月31日在中国陕西省西北农林科技大学泾阳蔬菜试验示范站温室(N108°48′,E34°36′)进行,获得环境有关日光温室生产过程的数据。为了在线获取温室内外的环境参数,实验采用了实验室开发的农业物联网监测平台(https://ems.nwsuaf.edu.cn)。
Data preprocessing
Missing values为了降低传感器采集或传输问题引起的数据丢失和异常对模型性能的影响,采用箱线图来检查数据的整体分布情况并剔除异常数据,以保证数据集的连续性和准确性。低于和高于第 25 个和第 75 个百分位数减去或加上 1.5 倍四分位数范围的数据(Ritter, 2023)将被试作异常值并删除。对于缺失数量低于5的,使用线性插值填充;填充数据为最接近缺失值且具有相同天气条件的数据。
Selection of input variables为了增强模型的有效性,使用PCC计算IAT、IAH和其他环境因素之间的相关系数,计算公式如下:
R = ∑ i = 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) ∑ i = 1 n ( X i − X ‾ ) 2 ∑ i = 1 n ( Y i − Y ‾ ) 2 \displaystyle R=\frac{\sum_{i=1}^n(X_i-\overline X)(Y_i-\overline Y)}{\sqrt{\sum_{i=1}^n(X_i-\overline X)^2}\sqrt{\sum_{i=1}^n(Y_i-\overline Y)^2}} R=∑i=1n(Xi−X)2∑i=1n(Yi−Y)2∑i=1n(Xi−X)(Yi−Y)
Normalization采用线性归一化方法使数据保持同一维数,计算公式如下:
y = 0.6 ( x − x m i n ) x m a x − x m i n + 2 {\displaystyle y=\frac{0.6(x-x_{min})}{x_{max}-x_{min}}+2} y=xmax−xmin0.6(x−xmin)+2
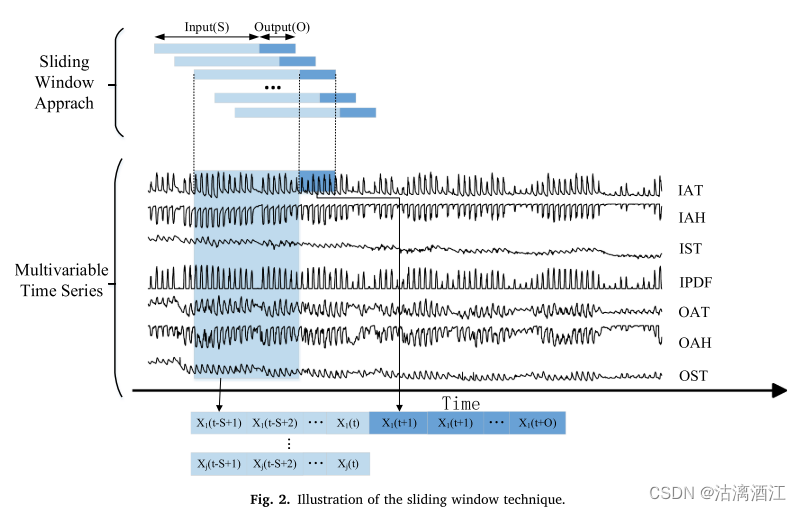
Data preparation使用滑动窗口技术对归一化数据进行划分。
Algorithm parameter settings
参数设置如下:学习率为0.01,优化器为Adam,batch size为32,epoch设置为200。输入窗口为48。模型在 t+24(12h)、t+48(24h)、t+72(36h)和t+96(48h)的不同预测窗口进行训练。将原始数据集分为训练集和测试集,划分比例分别为6:4、7:3和8:2。输入和输出窗口在整个时间序列中同时滑动,步长为30 min。
Models evaluation
平均绝对误差 (MAE) 和均方根误差 (RMSE)
R M S E = 1 N ∑ i = 1 N ( x i − y i ) RMSE=\sqrt{\frac1N\sum_{i=1}^N(x_i-y_i)} RMSE=N1∑i=1N(xi−yi)
M A E = 1 N ∑ i = 1 N ∣ x i − y i ∣ MAE=\frac1N\sum_{i=1}^N|x_i-y_i| MAE=N1∑i=1N∣xi−yi∣
y i , x i y_i,x_i yi,xi分别为日光温室室内温度的实际值和预测值; N 是样本数
区间温度预测误差 ϵ T \epsilon_T ϵT、区间湿度预测误差 ϵ H \epsilon_H ϵH,二者均表示为预测值与i时刻实际值的差值,计算公式如下:
ϵ T ( i , h ) = X p ( i , h ) − X a ( i , h ) \epsilon_T(i,h)=X_p(i,h)-X_a(i,h) ϵT(i,h)=Xp(i,h)−Xa(i,h)
ϵ H ( i , h ) = Y p ( i , h ) − Y a ( i , h ) \epsilon_H(i,h)=Y_p(i,h)-Y_a(i,h) ϵH(i,h)=Yp(i,h)−Ya(i,h)
其中,h为预测时间步长
Correlation analysis of impact factors
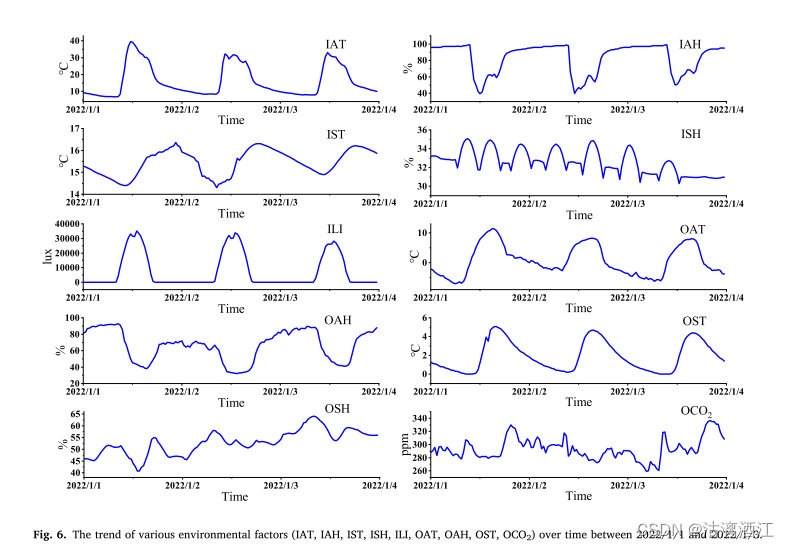
利用重采样功能对原始数据进行下采样,以减少数据冗余并满足建模要求。将时间频率转换为30分
钟并与平均值聚合。下图展示了各种环境因素随时间变化的趋势和周期性。
Performances of different models in indoor air temperature prediction
在相同的原始数据集上进行,并与RNN、LSTM、GRU、FAM-RNN和FAM-GRU模型进行对比,以验证FAM-LSTM模型的性能。下表显示了6个模型在输出标准t+24、t+48、t+72和t+96时温室IAT预测的性能。
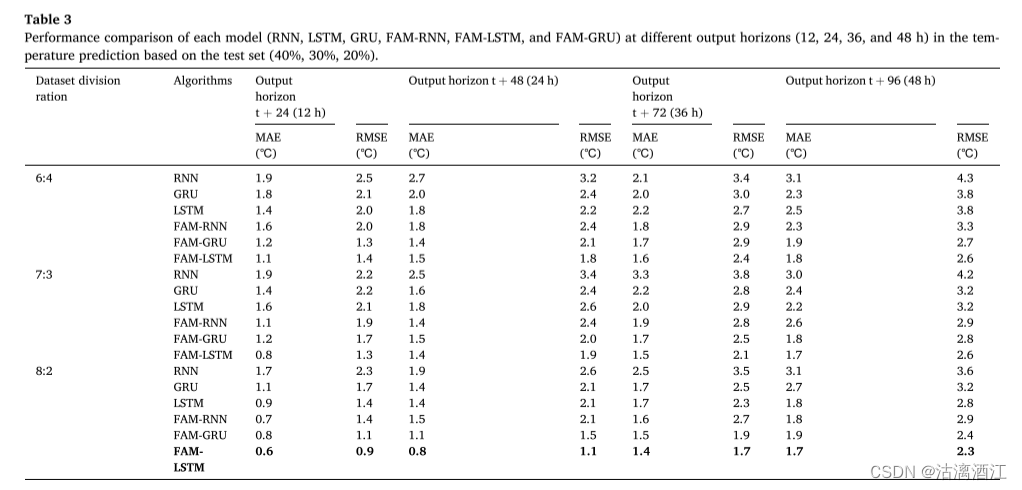
由表可知,对于6:4、7:3和8:2的不同数据集划分比例
- LSTM 和 GRU 模型比 RNN 模型表现出更高的预测精度。
- 添加FAM后,FAM-RNN、FAM-LSTM和FAM-GRU模型的预测精度优于RNN、LSTM和GRU模型。
- 当数据集划分比例为8:2时,FAM-LSTM模型的MAE和RMSE最低。
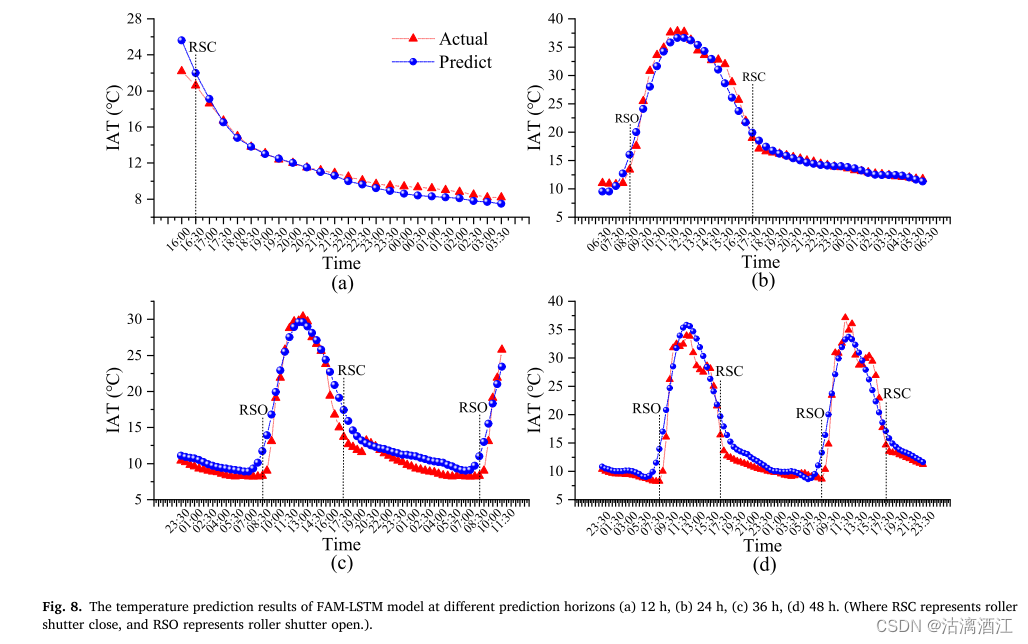
FAM-LSTM 模型在不同的预测范围内独立训练。12、24、36、48h不同预测层位下的实际值与预测值的比较结果如图 8所示。FAM-LSTM模型预测在不同预测层位下均准确地拟合了真实数据,但由于卷帘的影响,在8:30和17:00的预测误差相对较高,未来可引入光强度以改进模型。
Performances of different models in indoor air humidity prediction
下表显示了RNN、LSTM、GRU、FAM-LSTM、FAM-RNN和FAM-GRU模型在12、24、36、48h输出范围内预测IAH的性能。
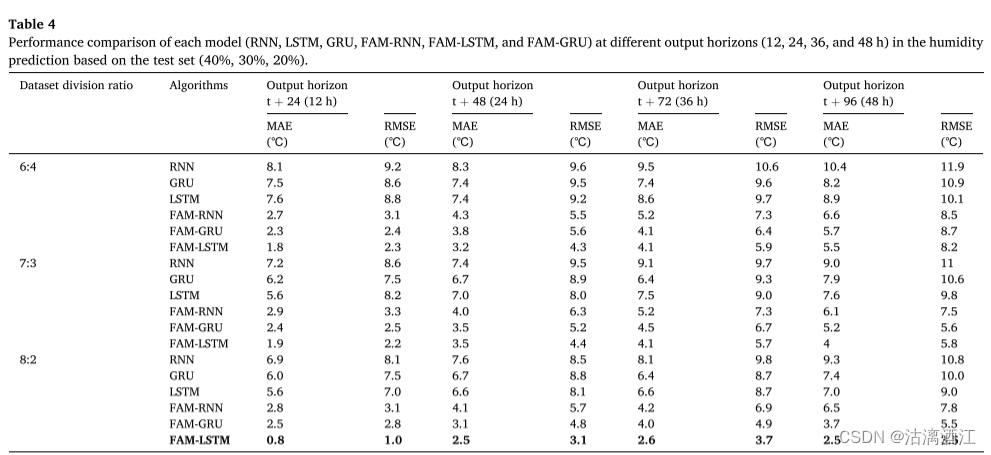
添加FAM后效果相对于原模型均有一定程度的提升,且在实验的模型中FAM-LSTM模型具有最好的预测性能。
下图显示了FAM-LSTM模型在不同预测范围内的实际湿度和预测湿度之间的比较结果。基于FAM-LSTM模型,预测湿度与实际湿度非常吻合。
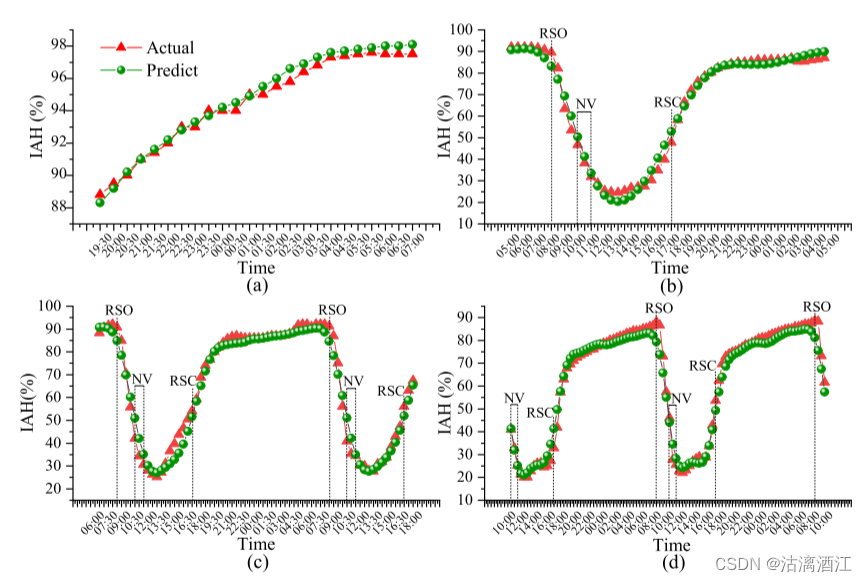
- 当光强度变化时,有一定程度误差,未来可引入光强度以改进模型。
- 自然通风(NV)会降低实际空气湿度(Hou et al., 2021)。该操作会增加预测湿度和测量湿度之间的差异。上图(d)显示了从NV开始的48h湿度预测结果。
- 考虑了通风后环境因素的变化,得到了比NV期间其他预测结果更准确的预测结果(上图(b),©)
Analysis of model error
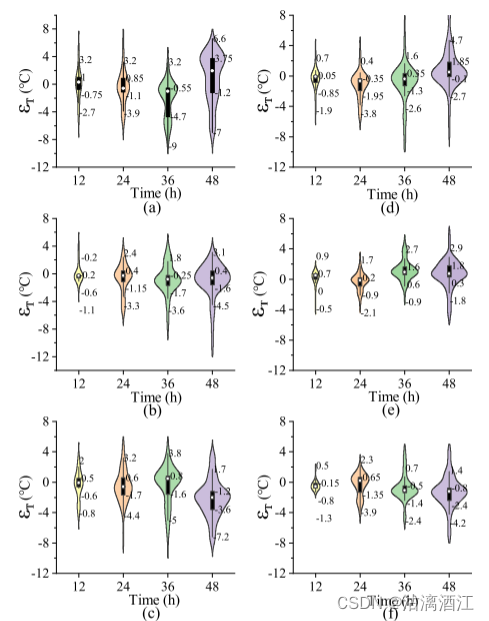
为了分析和评估不同模型的性能,通过 ϵ T , ϵ H \epsilon_T, \epsilon_H ϵT,ϵH评估误差,得出了RNN、LSTM、GRU、FAM-RNN、FAM-LSTM和FAM-GRU模型在各种预测水平上的误差分布。
模型与图的对应关系:(a)RNN, (b)LSTM, ©GRU, (d)FAM-RNN, (e)FAM-LSTM, (f)FAM-GRU
图中白点是平均值,方框代表25%和75%(Q1和Q3)的数据,实线部分包含 99.3% 的数据。
下图为各模型以 ϵ T \epsilon_T ϵT为准的误差分布。
下图为各模型以 ϵ H \epsilon_H ϵH为准的误差分布
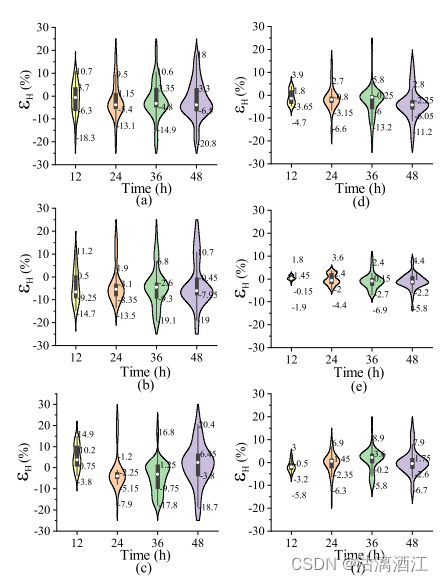
该结果证明了FAM-LSTM模型在多元时间序列预测中的可行性,满足了日光温室多步温湿度预测的需求。
4.4 结论
该论文基于FAM-LSTM模型,提出了一种日光温室温湿度预测方法。该模型可以实现对温室不同时期温湿度的多步提前预测。
四、绘图软件的基本使用
1. tensorboard
详见第九周hw2部分
2. latex
首先,下载mac版本的latex,使用homebrew安装brew install mactex --cask
其次,下载vscode,并下载插件,搜索latex,下载如下插件

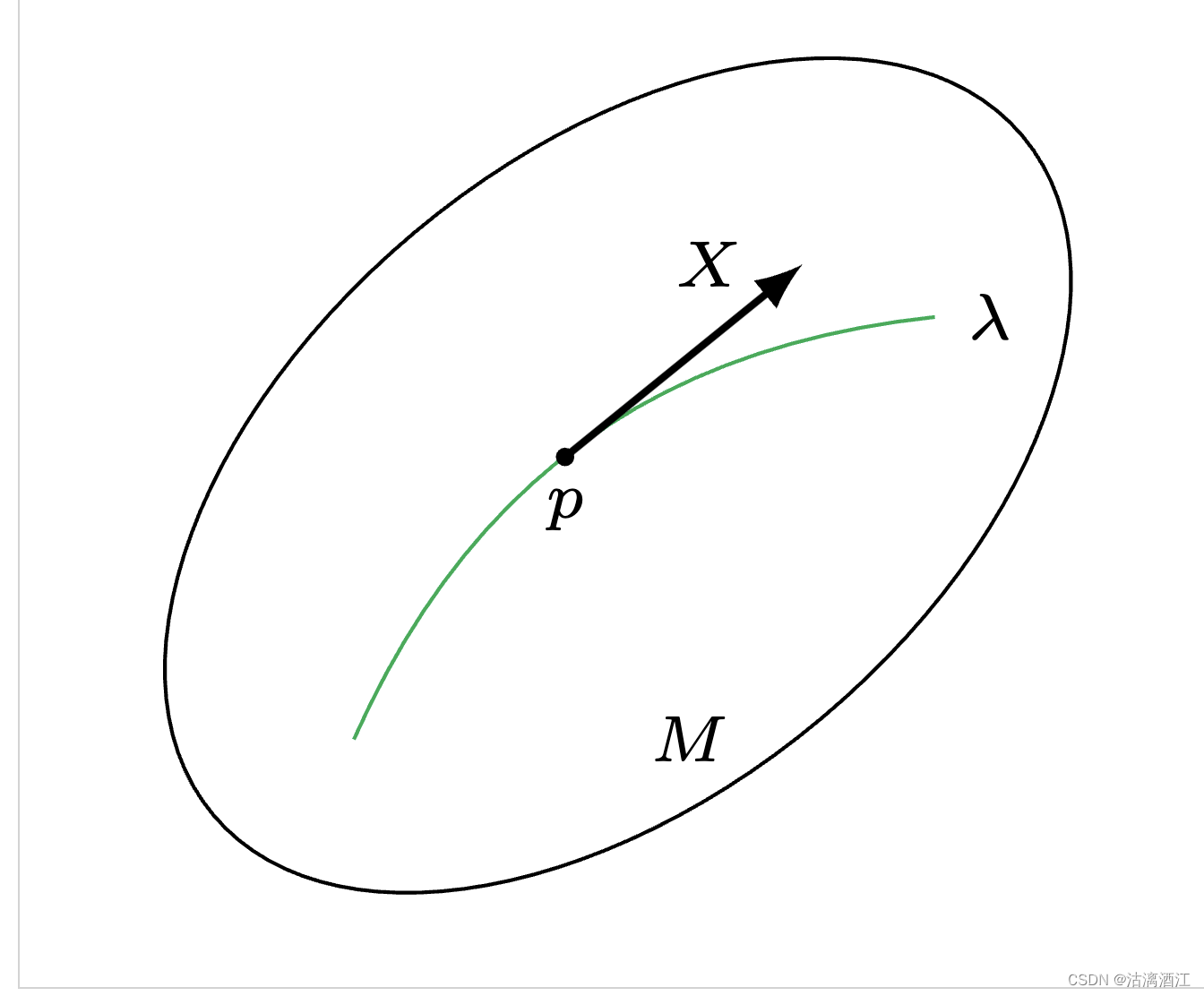
然后,创建.tex后缀文件,代码如下
\documentclass[border=0.3cm]{standalone}
\usepackage{amsmath}
\usepackage{tikz}
\usepackage{xcolor}
\definecolor{deepgreen}{cmyk}{0.99998,0,1,0}
\begin{document}
\begin{tikzpicture}
\draw[rotate=40](0,0)ellipse(2 and 1.2);
\path[deepgreen] (-1, -1) edge [bend left] (1.2,0.6);
\node at(1.2,0.6)[right]{\scriptsize\( \lambda \)};
\fill(-0.2,0.07)circle(1pt)node[below]{\scriptsize\( p \)};
\draw[-latex,thick](-0.2,0.07)--(0.7,0.8)node[left,xshift=-0.1cm]{\scriptsize\( X \)};
\node at(0,-1)[right]{\scriptsize\( M \)};
\end{tikzpicture}
\end{document}
最后,可以自行配置编辑中预览,之前下载的插件中提供了持久化功能,点击右上角绿色三角执行按钮,生成多个相关文件,其中pdf文件效果如下
3. matplotlib
见本篇lstm实现部分末尾
小结
之前学习的网络,例如传统CNN仅能考虑感受野范围内的信息,且输入通常是以向量的形式,这导致网络一般只能对部分范围内的信息进行处理并在此基础上产生结果。但使用覆盖全图的卷积核或者超大规模的全连接网络同样是不合理的,二者均需要训练大量的参数,从而所需算量也是大难以承受的。而且以这种形式构建的网络规模较大,这通常意味着需要较大量的数据用于训练以避免模型过拟合。基于本周学习的self-attention机制构建网络可以产生一种能输入向量组、考虑全局信息的网络,例如transformer。这种网络的输出是多种多样的,本文中以“每个向量对应一个标签”这一输出的类型为例说明网络结构。self-attention层是本网络中的主要创新点,该层可以考虑输入序列中的所有信息。由于全连接层一般用于处理单个向量,在本网络结构中通常将经过self-attention层处理的向量组分别接入全连接层。self-attention层主要依赖注意力机制计算各个向量之间的相关性,有两种计算方法dot-product与additive,本文主要介绍dot-product方法。dot-product主要围绕价值value、关键词key、权重weight展开,在本文的3.1部分着重对计算流程进行了介绍。在CNN中有多个卷积核从而针对多种模式进行匹配的经验,self-attention中同样可以通过Multi-head Self-attention计算向量间多种标准下的相关性。self-attention还引入了position-encoding,从而使得网络可以考虑向量的位置信息。最后在文末给出了self-attention在多个领域的应用,并将其与CNN、RNN进行了比较。实现并训练了LSTM模型。本周阅读的文献构建了一种FAM-LSTM模型,用于日光温室温度和湿度的多步预测,并获得了较高精度。简略了解了多种未来可能用到的绘图工具。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin:Attention Is All You Need.[J].CoRR abs/1706.03762
[2] Xuanqing Liu, Hsiang-Fu Yu, Inderjit Dhillon, Cho-Jui Hsieh:Learning to Encode Position for Transformer with Continuous Dynamical Model.[J].CoRR abs/2003.09229
[3] Yongxia Yang1,2; Pan Gao1,3; Zhangtong Sun1,2; Haoyu Wang1,2; Miao Lu1,3; Yingying Liu1,2,3CA1; Jin Hu1,2,3CA2:Multistep ahead prediction of temperature and humidity in solar greenhouse based on FAM-LSTM model.[J].Computers and Electronics in Agriculture,Volume 213,2023,108261