RabbitMQ 脑裂丢数据
什么是脑裂?
所谓的脑裂问题,就是在多机集群中节点与节点之间失联,都认为对方出现故障,而自身裂变为独立的个体,各自为政,那么就出现了抢夺对方的资源,争抢启动,至此就发生了事故。rabbitmq 脑裂问题,实质上是个网络分区问题,rabbitmq集群的网络分区容错性不好,在网络比较差的情况下容易出错,最明显的就是脑裂问题了。
举个栗子:
A和B是集群上的两个节点,分别拥有一部分集群的数据a,b, 如果这时发生分区问题,两个节点无法通信,A以为B宕机,B以为A宕机,于是就出现了:
(1)如果A存在B的备份,那就以完整数据运行,B存在A的数据备份,也是同样, 那这里就造成共享数据损坏。
(2)如果 A,B 各自仅拥有a,b 的数据,那要么都无法恢复/启动,要么就瓜分数据运行。
分析
从RabbitMQ启动,数据加裁逻辑过程中,可以看出
在从节点队列启动的时候,你是会先把当前队列所在文件夹下的索引 进行清空,同时清空当前节点上当前队列的内存数据。
然后再从队列主节点上同步数据回来。
如果在脑裂出现的情况下,又连接到队列的从节点所在服务器上,并写了数据,那数据就在从节点上,并没有同步到原本的主节点上,假如这个时候把当前这个RabbitMQ节点进行重启,那RabbitMQ上的数据就会丢失,重新从主节点上进行数据同步。

按上面图逻辑顺序,理论上在 第四步(写入2)中 写入的数据,在重启RabbitMQ_B节点后,数据是会丢失的
出现脑裂的现象
1、通过rabbitmqctl工具查看
即采用rabbitmqctl cluster_status命令.未发生分区的情况,如下图:
[root@rmq-node3 ~]# rabbitmqctl cluster_status
Cluster status of node 'rabbit@rmq-node3'
[{nodes,[{disc,['rabbit@rmq-node2','rabbit@rmq-node1']},
{ram,['rabbit@rmq-node3']}]},
{running_nodes,['rabbit@rmq-node1','rabbit@rmq-node2','rabbit@rmq-node3']},
{cluster_name,<<"rabbit@rmq-node1">>},
{partitions,[]}, #注意,这里为空数组,表明没有发生网络分区
{alarms,[{'rabbit@rmq-node1',[]},
{'rabbit@rmq-node2',[]},
{'rabbit@rmq-node3',[]}]}]
发生分区的情况:
[root@rmq-node3 ~]# rabbitmqctl cluster_status
Cluster status of node 'rabbit@rmq-node3'
[{nodes,[{disc,['rabbit@rmq-node2','rabbit@rmq-node1']},
{ram,['rabbit@rmq-node3']}]},
{running_nodes,['rabbit@rmq-node1','rabbit@rmq-node2','rabbit@rmq-node3']},
{cluster_name,<<"rabbit@rmq-node1">>},
{partitions,[{'rabbit@rmq-node1',['rabbit@rmq-node2','rabbit@rmq-node3']}]}, #这里是发生了network partitions
{alarms,[{'rabbit@rmq-node1',[]},
{'rabbit@rmq-node2',[]},
{'rabbit@rmq-node3',[]}]}]
2、通过RabbitMQ管理控制台查看
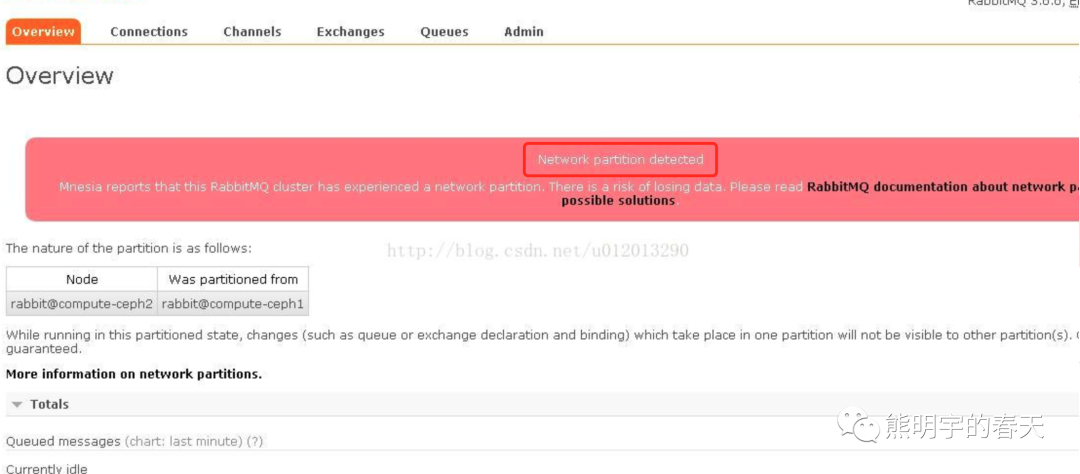
恢复方式
1.人工方式
(1)部分重启。选择受信分区即网络环境好的分区,重启其他分区,让他们重新加入受信分区中,之后再重启受信分区,消除警告⚠️
(2)全部重启。停掉整个集群,然后启动,不过要保证第一个启动的是受信分区。不然还没等所有节点加入,自己就挂了。
2.自动处理
(1)ignore 默认配置,即分区不做任何处理。发生网络分区时,需要人工介入。要使用这种,就要保证网络高可用,例如,节点都在一个机架上,用的同一个交换机,这个交换机连上一个WAN,保证网络稳定。
(2)pause_minority,优先暂停‘少数派’。就是节点判断自己在不在‘少数派’(少于或者等于集群中一半的节点数),在就自动关闭,保证稳定区的大部分节点可以继续运行。一般情况下,可应用于非跨机架、奇数节点的集群中。
(3)pause-if-all-down,对于受信节点的选择尤为考究,尤其是在集群中所有节点硬件配置相同的情况下。此种模式可以处理对等分区的情形。
(4)autoheal, 关闭客户端连接数最多的节点。 这里比较有意思,rabbitmq 会自动挑选一个‘获胜’分区,即连接数最小的,重启其他分区。(如果平手,就选节点多的,如果节点也一致,那就以未知方式挑选‘获胜者’)。这个更关心服务的连续性而不是数据的完整性。但是如果集群中有节点处于非运行状态,则此种模式会失效。
ignore:适用于网络很可靠或者只有两个节点的集群;
pause_minority:适用于三机房,每个机房有一个节点或一个以上的集群;
pause_if_all_down:适用于三机房,每个机房节点数不一样的集群(比如四个节点);
autoheal:适用于网络不可靠,只关心服务的连续性而不是数据的完整性。适合有两个节点的集群;
修改/etc/rabbitmq/rabbitmq.config配置文件,添加pause_minority策略
[
{rabbit,
[{tcp_listeners,[5672]},
{cluster_partition_handling, pause_minority}]
}
]
模拟测试
1、未加策略前,集群状态正常;
2、添加iptables策略,模拟网络中断;
网络中断后RabbitMQ服务端口还存在(同机房还可以进行读写);
3、关闭iptables策略,检查集群状态,发现集群已经分成两个分区;
重启节点rabbit@sz-145-centos178后集群状态恢复正常。
4、修改/etc/rabbitmq/rabbitmq.config配置文件,添加pause_minority策略;
5、逐一重启所有节点,重启过程中集群状态正常;
重启完成后再次添加iptables策略,模拟网络中断;可以发现添加策略后网络中断时MQ节点检测到自身属于少数节点,所以关闭自身节点,不提供服务;
6、关闭iptables策略,可以看到该节点RabbitMQ服务自动启动,集群状态也正常;