搭建简单的GPT聊天机器人
目录
进行模型参数设置、加载词典和数据、数据准备、GPU设置、构建优化器和损失函数,进行模型的训练和测试,完成execute.py。
通过给出的前端代码,调用flask前端进行测试,完成app.py文件,使用网页端聊天机器人聊天对话。
有问题后台私信
第一步
进行语料库读取、文本预处理,完成data_utls.py
data_utls.py
'''
数据处理器
'''
import os
import jieba
from tkinter import _flatten
import json
# 读取语料库文件
def read_corpus(corpus_path='../data/dialog/'):
'''
corpus_path:读取文件的路径
'''
corpus_files = os.listdir(corpus_path) # 列出文件路径下所有文件
corpus = []
for corpus_file in corpus_files: # 循环读取各个文件内容
with open(os.path.join(corpus_path, corpus_file), 'r', encoding='utf-8') as f:
corpus.extend(f.readlines())
corpus = [i.replace('\n', '') for i in corpus]
return corpus # 返回语料库的列表数据
print('语料库读取完成!'.center(30, '='))
corpus = read_corpus(corpus_path='../data/dialog/')
print('语料库展示: \n', corpus[:6])
# 分词
def word_cut(corpus, userdict='../data/ids/mydict.txt'):
'''
corpus:语料
userdict:自定义词典
'''
jieba.load_userdict(userdict) # 加载自定义词典
corpus_cut = [jieba.lcut(i) for i in corpus] # 分词
print('分词完成'.center(30, '='))
return corpus_cut
# 构建词典
def get_dict(corpus_cut):
'''
corpus_cut:分词后的语料文件
'''
tmp = _flatten(corpus_cut) # 将分词结果列表拉直
all_dict = list(set(tmp)) # 去除重复词,保留所有出现的唯一的词
id2words = {i: j for i, j in enumerate(all_dict)}
words2id = dict(zip(id2words.values(), id2words.keys())) # 构建词典
print('词典构建完成'.center(30, '='))
return all_dict, id2words, words2id
# 执行分词
corpus_cut = word_cut(corpus, userdict='../data/ids/mydict.txt')
print('分词结果展示: \n', corpus_cut[:2])
# 获取字典
all_dict, id2words, words2id = get_dict(corpus_cut)
print('词典展示: \n', all_dict[:6])
# 文件保存
def save(all_dict, corpus_cut, file_path='../tmp'):
'''
all_dict: 获取的词典
file_path: 文件保存路径
corpus_cut: 分词后的语料文件
'''
if not os.path.exists(file_path):
os.makedirs(file_path) # 如果文件夹不存在则新建
source = corpus_cut[::2] # 问
target = corpus_cut[1::2] # 答
# 构建文件的对应字典
file = {'all_dict.txt': all_dict, 'source.txt': source, 'target.txt': target}
# 分别进行文件处理并保存
for i in file.keys():
if i in ['all_dict.txt']:
with open(os.path.join(file_path, i), 'w', encoding='utf-8') as f:
f.writelines(['\n'.join(file[i])])
else:
with open(os.path.join(file_path, i), 'w', encoding='utf-8') as f:
f.writelines([' '.join(i) + '\n' for i in file[i]])
print('文件已保存'.center(30, '='))
# 执行保存
save(all_dict, corpus_cut, file_path='../tmp')
第二步
进行Seq2Seq模型的构建,完成Seq2Seq.py
import tensorflow as tf
import typing
# 编码
class Encoder(tf.keras.Model):
# 设置参数
def __init__(self, vocab_size: int, embedding_dim: int, enc_units: int) -> None:
'''
vocab_size: 词库大小
embedding_dim: 词向量维度
enc_units: LSTM层的神经元数量
'''
super(Encoder, self).__init__()
self.enc_units = enc_units
# 词嵌入层
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
# LSTM层,GRU是简单的LSTM层
self.gru = tf.keras.layers.GRU(self.enc_units, return_sequences=True, return_state=True)
# 定义神经网络的传输顺序
def call(self, x: tf.Tensor, **kwargs) -> typing.Tuple[tf.Tensor, tf.Tensor]:
'''
x: 输入的文本
'''
x = self.embedding(x)
output, state = self.gru(x)
return output, state # 输出预测结果和当前状态
# 注意力机制
class BahdanauAttention(tf.keras.Model):
# 设置参数
def __init__(self, units: int) -> None:
'''
units: 神经元数据量
'''
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units) # 全连接层
self.W2 = tf.keras.layers.Dense(units) # 全连接层
self.V = tf.keras.layers.Dense(1) # 输出层
# 设置注意力的计算方式
def call(self, query: tf.Tensor, values: tf.Tensor, **kwargs) -> typing.Tuple[tf.Tensor, tf.Tensor]:
'''
query: 上一层输出的特征值
values: 上一层输出的计算结果
'''
# 维度增加一维
hidden_with_time_axis = tf.expand_dims(query, 1)
# 构造计算方法
score = self.V(tf.nn.tanh(self.W1(values) + self.W2(hidden_with_time_axis)))
# 计算权重
attention_weights = tf.nn.softmax(score, axis=1)
# 计算输出
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights # 输出特征向量和权重
# 解码
class Decoder(tf.keras.Model):
# 设置参数
def __init__(self, vocab_size: int, embedding_dim: int, dec_units: int):
'''
vocab_size: 词库大小
embedding_dim: 词向量维度
dec_units: LSTM层的神经元数量
'''
super(Decoder, self).__init__()
self.dec_units = dec_units
# 词嵌入层
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
# 添加LSTM层
self.gru = tf.keras.layers.GRU(self.dec_units, return_sequences=True, return_state=True)
# 全连接层
self.fc = tf.keras.layers.Dense(vocab_size)
# 添加注意力机制
self.attention = BahdanauAttention(self.dec_units)
# 设置神经网络传输顺序
def call(self, x: tf.Tensor, hidden: tf.Tensor, enc_output: tf.Tensor) \
-> typing.Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
'''
x: 输入的文本
hidden: 上一层输出的特征值
enc_output: 上一层输出的计算结果
'''
# 计算注意力机制层的结果
context_vector, attention_weights = self.attention(hidden, enc_output)
# 次嵌入层
x = self.embedding(x)
# 词嵌入结果和注意力机制的结果合并
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# 添加注意力机制
output, state = self.gru(x)
# 输出结果更新维度
output = tf.reshape(output, (-1, output.shape[2]))
# 输出层
x = self.fc(output)
return x, state, attention_weights # 输出预测结果,当前状态和权重
第三步
进行模型参数设置、加载词典和数据、数据准备、GPU设置、构建优化器和损失函数,进行模型的训练和测试,完成execute.py。
import os
import datetime
from Seq2Seq import Encoder, Decoder
import tensorflow as tf
# 设置参数
data_path = '../data/ids' # 文件路径
epoch = 100 # 迭代训练次数
batch_size = 15 # 每批次样本数
embedding_dim = 256 # 词嵌入维度
hidden_dim = 512 # 隐层神经元个数
shuffle_buffer_size = 4 # 清洗数据集时将缓冲的实例数
device = -1 # 使用的设备ID,-1即不使用GPU
checkpoint_path = '../tmp/model' # 模型参数保存的路径
MAX_LENGTH = 50 # 句子的最大词长
CONST = {'_BOS': 0, '_EOS': 1, '_PAD': 2, '_UNK': 3}# 最大输出句子的长度
# 加载词典
print(f'[{datetime.datetime.now()}] 加载词典...')
data_path = '../data/ids'
CONST = {'_BOS': 0, '_EOS': 1, '_PAD': 2, '_UNK': 3}
table = tf.lookup.StaticHashTable( # 初始化后即不可变的通用哈希表。
initializer=tf.lookup.TextFileInitializer(
os.path.join(data_path, 'all_dict.txt'),
tf.string,
tf.lookup.TextFileIndex.WHOLE_LINE,
tf.int64,
tf.lookup.TextFileIndex.LINE_NUMBER
), # 要使用的表初始化程序。有关支持的键和值类型,请参见HashTable内核。
default_value=CONST['_UNK'] - len(CONST) # 表中缺少键时使用的值。
)
# 加载数据
print(f'[{datetime.datetime.now()}] 加载预处理后的数据...')
# 构造序列化的键值对字典
def to_tmp(text):
'''
text: 文本
'''
tokenized = tf.strings.split(tf.reshape(text, [1]), sep=' ')
tmp = table.lookup(tokenized.values) + len(CONST)
return tmp
# 增加开始和结束标记
def add_start_end_tokens(tokens):
'''
tokens: 列化的键值对字典
'''
tmp = tf.concat([[CONST['_BOS']], tf.cast(tokens, tf.int32), [CONST['_EOS']]], axis=0)
return tmp
# 获取数据
def get_dataset(src_path: str, table: tf.lookup.StaticHashTable) -> tf.data.Dataset:
'''
src_path: 文件路径
table:初始化后不可变的通用哈希表。
'''
dataset = tf.data.TextLineDataset(src_path)
dataset = dataset.map(to_tmp)
dataset = dataset.map(add_start_end_tokens)
return dataset
# 获取数据
src_train = get_dataset(os.path.join(data_path, 'source.txt'), table)
tgt_train = get_dataset(os.path.join(data_path, 'target.txt'), table)
# 把数据和特征构造为tf数据集
train_dataset = tf.data.Dataset.zip((src_train, tgt_train))
# 过滤数据实例数
def filter_instance_by_max_length(src: tf.Tensor, tgt: tf.Tensor) -> tf.Tensor:
'''
src: 特征
tgt: 标签
'''
return tf.logical_and(tf.size(src) <= MAX_LENGTH, tf.size(tgt) <= MAX_LENGTH)
train_dataset = train_dataset.filter(filter_instance_by_max_length) # 过滤数据
train_dataset = train_dataset.shuffle(shuffle_buffer_size) # 打乱数据
train_dataset = train_dataset.padded_batch( # 将数据长度变为一致,长度不足用_PAD补齐
batch_size,
padded_shapes=([MAX_LENGTH + 2], [MAX_LENGTH + 2]),
padding_values=(CONST['_PAD'], CONST['_PAD']),
drop_remainder=True,
)
# 提升产生下一个批次数据的效率
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
# 模型参数保存的路径如果不存在则新建
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
# 获得当前主机上GPU运算设备的列表
gpus = tf.config.experimental.list_physical_devices('GPU')
if 0 <= device and 0 < len(gpus):
# 限制TensorFlow仅使用指定的GPU
tf.config.experimental.set_visible_devices(gpus[device], 'GPU')
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
# 建模
print(f'[{datetime.datetime.now()}] 创建一个seq2seq模型...')
encoder = Encoder(table.size().numpy() + len(CONST), embedding_dim, hidden_dim)
decoder = Decoder(table.size().numpy() + len(CONST), embedding_dim, hidden_dim)
# 设置优化器
print(f'[{datetime.datetime.now()}] 准备优化器...')
optimizer = tf.keras.optimizers.Adam()
# 设置损失函数
print(f'[{datetime.datetime.now()}] 设置损失函数...')
# 损失值计算方式
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
# 损失函数
def loss_function(loss_object, real: tf.Tensor, pred: tf.Tensor) -> tf.Tensor:
'''
loss_object: 损失值计算方式
real: 真实值
pred: 预测值
'''
# 计算真实值和预测值的误差
loss_ = loss_object(real, pred)
# 返回输出并不相等的值,并用_PAD填充
mask = tf.math.logical_not(tf.math.equal(real, CONST['_PAD']))
# 数据格式转换为跟损失值一致
mask = tf.cast(mask, dtype=loss_.dtype)
return tf.reduce_mean(loss_ * mask) # 返回平均误差
# 设置模型保存
checkpoint = tf.train.Checkpoint(optimizer=optimizer, encoder=encoder, decoder=decoder)
# 训练
def train_step(src: tf.Tensor, tgt: tf.Tensor):
'''
src: 输入的文本
tgt: 标签
'''
# 获取标签维度
tgt_width, tgt_length = tgt.shape
loss = 0
# 创建梯度带,用于反向计算导数
with tf.GradientTape() as tape:
# 对输入的文本编码
enc_output, enc_hidden = encoder(src)
# 设置解码的神经元数目与编码的神经元数目相等
dec_hidden = enc_hidden
# 根据标签对数据解码
for t in range(tgt_length - 1):
# 更新维度,新增1维
dec_input = tf.expand_dims(tgt[:, t], 1)
# 解码
predictions, dec_hidden, dec_out = decoder(dec_input, dec_hidden, enc_output)
# 计算损失值
loss += loss_function(loss_object, tgt[:, t + 1], predictions)
# 计算一次训练的平均损失值
batch_loss = loss / tgt_length
# 更新预测值
variables = encoder.trainable_variables + decoder.trainable_variables
# 反向求导
gradients = tape.gradient(loss, variables)
# 利用优化器更新权重
optimizer.apply_gradients(zip(gradients, variables))
return batch_loss # 返回每次迭代训练的损失值
print(f'[{datetime.datetime.now()}] 开始训练模型...')
# 根据设定的训练次数去训练模型
for ep in range(epoch):
# 设置损失值
total_loss = 0
# 将每批次的数据取出,放入模型里
for batch, (src, tgt) in enumerate(train_dataset):
# 训练并计算损失值
batch_loss = train_step(src, tgt)
total_loss += batch_loss
if ep % 100 == 0:
# 每100训练次保存一次模型
checkpoint_prefix = os.path.join(checkpoint_path, 'ckpt')
checkpoint.save(file_prefix=checkpoint_prefix)
print(f'[{datetime.datetime.now()}] 迭代次数: {ep+1} 损失值: {total_loss:.4f}')
# 模型预测
def predict(sentence='你好'):
# 导入训练参数
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_path))
# 给句子添加开始和结束标记
sentence = '_BOS' + sentence + '_EOS'
# 读取字段
with open(os.path.join(data_path, 'all_dict.txt'), 'r', encoding='utf-8') as f:
all_dict = f.read().split()
# 构建: 词-->id的映射字典
word2id = {j: i+len(CONST) for i, j in enumerate(all_dict)}
word2id.update(CONST)
# 构建: id-->词的映射字典
id2word = dict(zip(word2id.values(), word2id.keys()))
# 分词时保留_EOS 和 _BOS
from jieba import lcut, add_word
for i in ['_EOS', '_BOS']:
add_word(i)
# 添加识别不到的词,用_UNK表示
inputs = [word2id.get(i, CONST['_UNK']) for i in lcut(sentence)]
# 长度填充
inputs = tf.keras.preprocessing.sequence.pad_sequences(
[inputs], maxlen=MAX_LENGTH, padding='post', value=CONST['_PAD'])
# 将数据转为tensorflow的数据类型
inputs = tf.convert_to_tensor(inputs)
# 空字符串,用于保留预测结果
result = ''
# 编码
enc_out, enc_hidden = encoder(inputs)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([word2id['_BOS']], 0)
for t in range(MAX_LENGTH):
# 解码
predictions, dec_hidden, attention_weights = decoder(dec_input, dec_hidden, enc_out)
# 预测出词语对应的id
predicted_id = tf.argmax(predictions[0]).numpy()
# 通过字典的映射,用id寻找词,遇到_EOS停止输出
if id2word.get(predicted_id, '_UNK') == '_EOS':
break
# 未预测出来的词用_UNK替代
result += id2word.get(predicted_id, '_UNK')
dec_input = tf.expand_dims([predicted_id], 0)
return result # 返回预测结果
print('预测示例: \n', predict(sentence='你好,在吗'))第四步
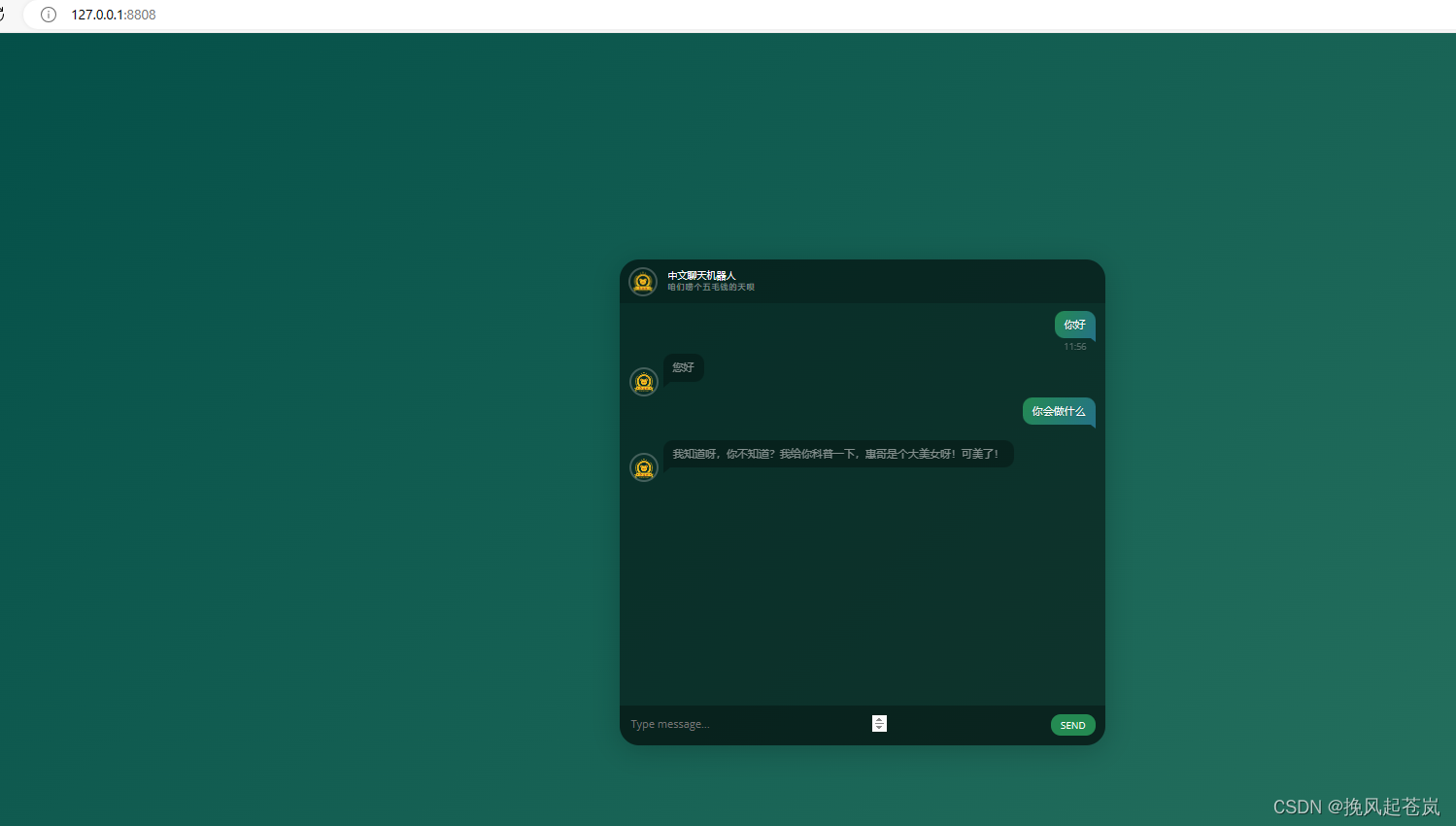
通过给出的前端代码,调用flask前端进行测试,完成app.py文件,使用网页端聊天机器人聊天对话。
app.py代码
import tensorflow as tf
import os
from Seq2Seq import Encoder, Decoder
from jieba import lcut, add_word
from flask import Flask, render_template, request, jsonify
# 设置参数
data_path = '../data/ids' # 数据路径
embedding_dim = 256 # 词嵌入维度
hidden_dim = 512 # 隐层神经元个数
checkpoint_path = '../tmp/model' # 模型参数保存的路径
MAX_LENGTH = 50 # 句子的最大词长
CONST = {'_BOS': 0, '_EOS': 1, '_PAD': 2, '_UNK': 3}
# 聊天预测
def chat(sentence='你好'):
# 初始化所有词语的哈希表
table = tf.lookup.StaticHashTable( # 初始化后即不可变的通用哈希表。
initializer=tf.lookup.TextFileInitializer(
os.path.join(data_path, 'all_dict.txt'),
tf.string,
tf.lookup.TextFileIndex.WHOLE_LINE,
tf.int64,
tf.lookup.TextFileIndex.LINE_NUMBER
), # 要使用的表初始化程序。有关支持的键和值类型,请参见HashTable内核。
default_value=CONST['_UNK'] - len(CONST) # 表中缺少键时使用的值。
)
# 实例化编码器和解码器
encoder = Encoder(table.size().numpy() + len(CONST), embedding_dim, hidden_dim)
decoder = Decoder(table.size().numpy() + len(CONST), embedding_dim, hidden_dim)
optimizer = tf.keras.optimizers.Adam() # 优化器
# 模型保存路径
checkpoint = tf.train.Checkpoint(optimizer=optimizer, encoder=encoder, decoder=decoder)
# 导入训练参数
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_path))
# 给句子添加开始和结束标记
sentence = '_BOS' + sentence + '_EOS'
# 读取字段
with open(os.path.join(data_path, 'all_dict.txt'), 'r', encoding='utf-8') as f:
all_dict = f.read().split()
# 构建: 词-->id的映射字典
word2id = {j: i + len(CONST) for i, j in enumerate(all_dict)}
word2id.update(CONST)
# 构建: id-->词的映射字典
id2word = dict(zip(word2id.values(), word2id.keys()))
# 分词时保留_EOS 和 _BOS
for i in ['_EOS', '_BOS']:
add_word(i)
# 添加识别不到的词,用_UNK表示
inputs = [word2id.get(i, CONST['_UNK']) for i in lcut(sentence)]
# 长度填充
inputs = tf.keras.preprocessing.sequence.pad_sequences(
[inputs], maxlen=MAX_LENGTH, padding='post', value=CONST['_PAD'])
# 将数据转为tensorflow的数据类型
inputs = tf.convert_to_tensor(inputs)
# 空字符串,用于保留预测结果
result = ''
# 编码
enc_out, enc_hidden = encoder(inputs)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([word2id['_BOS']], 0)
for t in range(MAX_LENGTH):
# 解码
predictions, dec_hidden, attention_weights = decoder(dec_input, dec_hidden, enc_out)
# 预测出词语对应的id
predicted_id = tf.argmax(predictions[0]).numpy()
# 通过字典的映射,用id寻找词,遇到_EOS停止输出
if id2word.get(predicted_id, '_UNK') == '_EOS':
break
# 未预测出来的词用_UNK替代
result += id2word.get(predicted_id, '_UNK')
dec_input = tf.expand_dims([predicted_id], 0)
return result # 返回预测结果
# 实例化APP
app = Flask(__name__, static_url_path='/static')
@app.route('/message', methods=['POST'])
# 定义应答函数,用于获取输入信息并返回相应的答案
def reply():
# 从请求中获取参数信息
req_msg = request.form['msg']
# 将语句使用结巴分词进行分词
# req_msg = " ".join(jieba.cut(req_msg))
# 调用decode_line对生成回答信息
res_msg = chat(req_msg)
# 将unk值的词用微笑符号代替
res_msg = res_msg.replace('_UNK', '^_^')
res_msg = res_msg.strip()
# 如果接受到的内容为空,则给出相应的回复
if res_msg == ' ':
res_msg = '我们来聊聊天吧'
return jsonify({'text': res_msg})
@app.route("/")
# 在网页上展示对话
def index():
return render_template('index.html')
# 启动APP
if (__name__ == '__main__'):
app.run(host='127.0.0.1', port=8808)
页面代码
<!DOCTYPE html>
<html >
<head>
<meta charset="UTF-8">
<title>TIPDM</title>
<link rel="stylesheet" href="static/css/normalize.css">
<link rel='stylesheet prefetch' href='https://fonts.googleapis.com/css?family=Open+Sans'>
<link rel='stylesheet prefetch' href='/static/js/jquery.mCustomScrollbar.min.css'>
<link rel="stylesheet" href="static/css/style.css">
<script src="/static/js/jquery-latest.js"></script>
</head>
<body onload="init()" id="page_body">
<div class="chat">
<div class="chat-title">
<h1>中文聊天机器人</h1>
<h2>咱们唠个五毛钱的天呗</h2>
<figure class="avatar">
<img src="static/res/7.png" /></figure>
</div>
<div class="messages">
<div class="messages-content"></div>
</div>
<div class="message-box">
<textarea type="text" class="message-input" placeholder="Type message..."></textarea>
<button type="submit" class="message-submit">Send</button>
</div>
</div>
<div class="bg"></div>
<script src='/static/js/jquery.min.js'></script>
<script src='/static/js/jquery.mCustomScrollbar.concat.min.js'></script>
<script src="static/js/index.js"></script>
</body>
</html>