序列化基础
1、简介
对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象。它允许把内存中的 Java 对象转换成平台无关的二进制流(序列化,也称编码),并持久地保存在磁盘上或通过网络把这种二进制流传输到另一个网络节点,其它程序获得这种二进制流也可以把它恢复成原来的 Java 对象(反序列化,也称解码)。这样就使得对象可以脱离程序的运行而独立存在。
序列化的使用场景有:
- 本地存储:将对象数据永久的保存在文件或者磁盘中。
- 网络传输:将对象数据在网络上进行传输。由于网络传输是以字节流的方式对数据进行传输的,因此序列化的目的是将对象数据转换成字节流的形式。
- 进程间通信:在 Android 中,对象数据在进程之间传递(如 Activity 之间传递数据),或者 Intent 之间传递复杂的数据类型时(基本数据类型直接传不用序列化)。
Android 中常用的序列化方案:Serializable,Parcelable,Json,Xml,Protocol buffer。
合理的选择序列化方案,可以从以下方面考虑:
- 通用性:是否跨平台、跨语言。流行程度(很少人使用的协议往往意味着昂贵的学习成本)。
- 健壮性:bug 要少。
- 可调试性/可读性:Xml 可读性高。
- 性能:时间、空间成本。
- 可扩展性/兼容性
- 安全性/访问限制:Android 的 Parcelable 曾有安全漏洞:漏洞预警 | Android系统序列化、反序列化不匹配漏洞
2、Serializable & Externalizable 接口
Serializable 是 Java 提供的一个标记接口,它只是表明该类的实例可以序列化,无须实现任何方法。Externalizable 接口是 Serializable 的子接口,其内部定义了 writeExternal(ObjectOutput) 和 readExternal(ObjectInput) 两个方法:
public interface Serializable {
}
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
我们先关注 Serializable 接口。
2.1 Serializable 基本使用
序列化时需要用 ObjectOutputStream 的 writeObject(OutputStream),反序列化时用 ObjectInputStream 的 readObject():
// 将 object 的序列化数据写入 path 表示的文件中
public synchronized static boolean saveObject(Object object, String path) {
if (object == null) return false;
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(path))) {
oos.writeObject(object);
return true;
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
// 从指定文件中读取数据进行反序列化
public synchronized static <T> T readObject(String path) {
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(path))) {
return (T) ois.readObject();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
return null;
}
序列化时可以在构造 ObjectOutputStream 时传入不同的输出流实现不同的效果。如传入 ByteArrayOutputStream,可以直接得到序列化的二进制数据:
public synchronized static byte[] getSerializedObject(Object object, String path) {
if (object == null) return null;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos)) {
oos.writeObject(object);
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
2.2 Serializable 实现类的创建
以实现了 Serializable 接口的 Person 类为例:
public class Person implements Serializable {
// serialVersionUID 唯一标识了一个可序列化的类
private static final long serialVersionUID = 1L;
private String name;
private int age;
// Food 也需要实现 Serializable 接口
private List<Food> foods;
/*
用transient关键字标记的成员变量不参与序列化。
在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象则为 null。
*/
private transient Date createTime;
/*
静态成员变量属于类不属于对象,所以不会参与序列化。
对象序列化保存的是对象的“状态”,也就是它的成员变量,因此序列化不会关注静态变量。
*/
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat();
public Person(String name, int age) {
this.name = name;
this.age = age;
foods = new ArrayList<>();
createTime = new Date();
}
// getters and setters...
}
下面关注创建 Serializable 的实现类时需要注意的问题。
serialVersionUID
作用是表明类的不同版本间的兼容性,保证序列化类在其对象已经序列化之后做了修改,该对象依然可以被正确反序列化。举个例子,对于上面的 Person 类,先序列化一个对象保存到文件中。然后,假设业务需求变更需要把 age 字段修改成 String 类型的,那么在修改 age 字段的同时,也要修改 serialVersionUID:
public class Person implements Serializable {
private static final long serialVersionUID = 2L;
private String age;
//...
}
这样的话,反序列化时根据 serialVersionUID 的值是可以正确执行的。倘若没有声明 serialVersionUID,修改前的已经被序列化的 Person 对象就会按照修改后的 Person 类进行反序列化,由于字段不匹配而抛出异常:
java.io.InvalidClassException: com.frank.serializable.Person; local class incompatible: stream classdesc serialVersionUID = -8357684236211496111, local class serialVersionUID = -657709351248511155
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1885)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
......
如果不显式定义 serialVersionUID,那么这个值会由 JVM 根据类的相关信息进行计算,通常修改后的计算结果与修改前不同,使得类版本不兼容,进而造成反序列化失败。说的直白一点,对象序列化数据中的 serialVersionUID 和反序列化时使用的 class 文件中的 serialVersionUID 不同,反序列化就会失败。
为了保证反序列化的正常执行,需要显式声明 serialVersionUID,最好是 private final 的,也可以使用 JDK bin 目录下的工具 serialver.exe 工具生成 serialVersionUID,当然 Android Studio 中的 GenerateSerialVersionUID 插件也可以帮我们生成。
不显式指定 serialVersionUID 的另一个坏处就是,即便类没有发生变化,但是两端使用不同的 JVM 时,由于编译器不同,计算策略不同,也可能会造成计算出来的 serialVersionUID 不同,导致反序列化失败。
那修改哪些程序单元时要更新 serialVersionUID 呢?需要看情况:
- 修改方法、静态变量、瞬态实例变量(transient 修饰的变量),不需要修改 serialVersionUID(因为以上元素不会被序列化)。
- 修改了非瞬态实例变量,可能会导致序列化版本不兼容。修改了变量类型(对象流中的对象和新类中包含同名实例变量,但实例变量类型不同)需要更新;删除了某个变量(流中的对象比新类中包含更多的实例变量,多出的被忽略),可以不更新;增加了某个变量(新类中包含的对象比流中包含的实例变量多),版本可以兼容,serialVersionUID 也可以不更新,但是反序列化时新对象中多出的实例变量值都是 null 或 0。
transient 关键字
transient 作用:非静态数据如不想被序列化,可以使用这个关键字修饰使之成为瞬态变量。
ObjectOutputStream 的 writeObject() 会将 Serializable 的实现类中非瞬态、非静态的成员变量都序列化,如果有非静态成员变量不想被序列化的话,就可以用 transient 修饰这个成员变量。例如 Person 类中的 Date 类型对象 createTime 被 transient 修饰,反序列化后该字段仍然存在,但是为 null。
具有类似情况的还有 static 修饰的静态变量,也不会被序列化。因为序列化的操作对象是实例对象,而 static 修饰的变量属于类,并不是序列化关注的内容。
transient 修饰的变量、static 修饰的变量和方法不会参与序列化。反序列化时这些变量的值为 0(基本数据类型)或者 null(引用数据类型)。
此外,Kotlin 中的 transient 不是一个关键字,而是一个注解 @Transient。
序列化的传递性
序列化具有一定的传递性:
1. 一个实现了序列化的类,它的子类也是可序列化的。
2. 要序列化的类中除了 transient、static 修饰的变量外,其它变量类型也要实现 Serializable 接口。
public class Student extends Person {
// Course 要实现 Serializable 接口
List<Course> courses;
public Student(String name, String age) {
super(name, age);
courses = new ArrayList<>();
}
}
Student 继承 Person,由于 Person 实现了序列化,那么 Student 也要实现序列化,这就要求 Course 类必须要实现 Serializable 接口,否则在序列化过程中会抛出 NotSerializableException。
此外,如果父类没有实现 Serializable,而子类实现了,需要父类中提供一个子类可访问到的空参构造方法,否则在反序列化调用 readObject() 时会抛出异常:
java.io.InvalidClassException: com.frank.serializable.Son; no valid constructor
at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:169)
at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:874)
示例代码:
public class Father {
private int age;
// 应该打开,否则抛异常
/*public Father() {
}*/
public Father(int age) {
this.age = age;
}
}
public class Son extends Father implements Serializable {
private String name;
public Son(String name) {
super(10);
this.name = name;
}
}
2.3 序列化步骤与数据格式
序列化步骤:
- 将对象实例相关的类元数据输出。
- 递归地输出类的超类描述直到不再有超类。
- 类元数据输出完毕以后,从最顶层的超类开始输出对象实例的实际数据值。
- 从上至下递归输出实例的数据。
比如说对于一个 Person 对象,序列化到文件后,查看其十六进制数据(使用 Notepad++ -> 插件 -> HEX Editor -> View in Hex 查看):
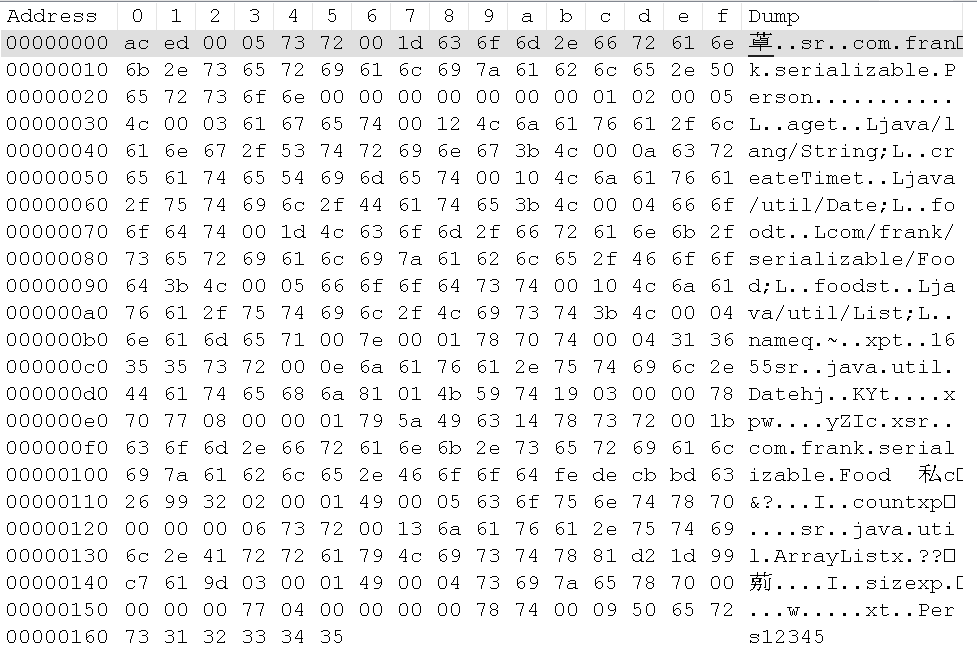
这些十六进制数据的含义:
- AC ED: STREAM_MAGIC 声明使用了序列化协议。
- 00 05: STREAM_VERSION 序列化协议版本。
- 0x73: TC_OBJECT 声明这是一个新的对象。
- 0x72: TC_CLASSDESC 声明这里开始一个新的 Class。
- 00 1d: Class 名字的长度。
2.4 源码流程
从 ObjectOutputStream 的 writeObject() 方法开始:
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
writeObjectOverride(obj);
return;
}
try {
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}
根据 enableOverride 的值决定调用 writeObjectOverride() 或 writeObject0()。enableOverride 仅在 ObjectOutputStream 的构造方法被赋值,如果调用的是空参构造方法,enableOverride 为 true,如果调用的是 ObjectOutputStream(OutputStream),则 enableOverride 为 false。
走一般流程,看 writeObject0() 的源码:
/**
* 写对象数据是一个递归流程。判断 obj 的类型是否可以直接写二进制数据,如 String、Array 或者
* 枚举类型。如果不是,就调用 writeOrdinaryObject(),再去写入这个“复合”对象中的每个属性,
* 此时会再调用到 writeObject0() 形成递归,直到 obj 的所有属性都可以直接写成二进制数据为止。
*/
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
// ......
try {
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
// 写对象,最终会递归拆分成直接可写的数据类型
writeOrdinaryObject(obj, desc, unshared);
} else {
// 如果没有实现 Serializable 接口,抛出 NotSerializableException
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
// ......
}
}
根据 obj 的类型,调用相应的写入数据的方法。如果 obj 不是 String、数组或枚举类型,并且还实现了 Serializable,就会调用 writeOrdinaryObject():
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared)
throws IOException
{
...
try {
desc.checkSerialize();
bout.writeByte(TC_OBJECT);
writeClassDesc(desc, false);
handles.assign(unshared ? null : obj);
// 写 Externalizable 或者 Serializable 数据
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj);
} else {
writeSerialData(obj, desc);
}
} finally {
...
}
}
如果实现的是 Serializable,会调用 writeSerialData() 写数据:
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
// 如果 Serializable 的实现类自定义了 writeObject() 就走 if,否则走 else。
if (slotDesc.hasWriteObjectMethod()) {
PutFieldImpl oldPut = curPut;
curPut = null;
SerialCallbackContext oldContext = curContext;
if (extendedDebugInfo) {
debugInfoStack.push(
"custom writeObject data (class \"" +
slotDesc.getName() + "\")");
}
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
// 调用自定义 writeObject()
slotDesc.invokeWriteObject(obj, this);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
curContext.setUsed();
curContext = oldContext;
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
curPut = oldPut;
} else {
defaultWriteFields(obj, slotDesc);
}
}
}
看默认流程,走 defaultWriteFields():
private void defaultWriteFields(Object obj, ObjectStreamClass desc)
throws IOException
{
Class<?> cl = desc.forClass();
if (cl != null && obj != null && !cl.isInstance(obj)) {
throw new ClassCastException();
}
desc.checkDefaultSerialize();
int primDataSize = desc.getPrimDataSize();
if (primVals == null || primVals.length < primDataSize) {
primVals = new byte[primDataSize];
}
desc.getPrimFieldValues(obj, primVals);
bout.write(primVals, 0, primDataSize, false);
// 获取类中所有属性
ObjectStreamField[] fields = desc.getFields(false);
Object[] objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
desc.getObjFieldValues(obj, objVals);
for (int i = 0; i < objVals.length; i++) {
...
try {
// 又调用到 writeObject0() 写属性数据,形成递归。
writeObject0(objVals[i],
fields[numPrimFields + i].isUnshared());
} finally {
...
}
}
}
递归直到要写入的是基本数据类型为止,整个流程图如下:
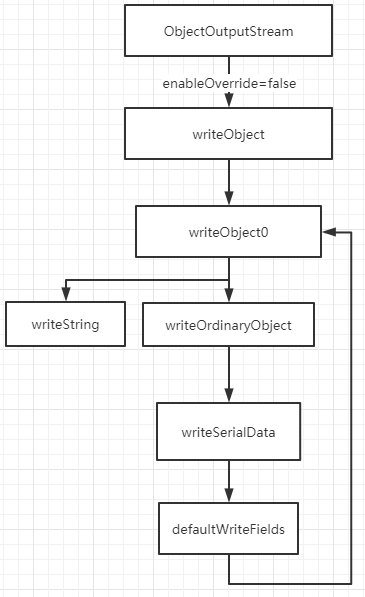
2.5 自定义序列化
writeObject()、readObject()
源码流程中提到,在 writeSerialData() 中,如果 Serializable 的实现类自定义了 writeObject(),那么就通过反射调用到这个 writeObject(),否则就调用 defaultWriteFields() 执行一般的序列化过程。因此,重写 writeObject()、readObject() 可以实现自定义序列化。
自定义序列化机制可以让程序控制如何序列化实例变量,甚至完全不序列化。在要进行序列化的类中要提供以下方法:

三个方法的用途:
- writeObject(out) 默认调用 out.defaultWriteObject 来保存各个实例变量,我们可以在方法内自己决定如何对实例变量进行序列化。
- readObject(in) 默认调用 in.defaultReadObject 来恢复对象的非瞬态实例变量。在这个方法内做与 writeObject(out) 操作相反的操作即可正确恢复该对象。
- 当序列化流不完整时,readObjectNoData() 可以用来正确地初始化反序列化的对象。例如两端使用的序列化的类版本不同,或者序列化流被篡改,系统都会调用这个方法来初始化反序列化对象。
示例代码:
public class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// getters...
private void writeObject(ObjectOutputStream outputStream) throws IOException {
outputStream.writeObject(new StringBuffer(name).reverse());
outputStream.writeInt(age);
}
private void readObject(ObjectInputStream inputStream) throws IOException, ClassNotFoundException {
name = ((StringBuffer) inputStream.readObject()).reverse().toString();
age = inputStream.readInt();
}
}
在 writeObject() 将 name 属性封装到 StringBuffer 中并倒序,在 readObject() 中将 StringBuffer 倒序转换成 String 类型实现还原。
writeObject() 和 readObject() 处理变量的顺序应该一致,否则不能正常恢复该对象。
writeReplace()、readResolve()
还有一种更彻底的自定义机制,它甚至可以在序列化对象时将该对象替换成其它对象。如果需要实现序列化某个对象时替换该对象,则应为序列化类提供如下方法:
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamException;
仍以 Person 类为例:
public class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
/*private void writeObject(ObjectOutputStream outputStream) throws IOException {
outputStream.writeObject(new StringBuffer(name).reverse());
outputStream.writeInt(age);
}
private void readObject(ObjectInputStream inputStream) throws IOException, ClassNotFoundException {
name = ((StringBuffer) inputStream.readObject()).reverse().toString();
age = inputStream.readInt();
}*/
private Object writeReplace() throws ObjectStreamException {
ArrayList<Object> arrayList = new ArrayList<>();
arrayList.add(name);
arrayList.add(age);
return arrayList;
}
}
writeReplace() 把 Person 需要序列化的成员变量都封装在 ArrayList 中,并返回这个 ArrayList 对象,那么在反序列化时,我们拿到的就是一个 ArrayList 对象而不是原来的 Person 对象了:
private void test3() {
try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("test.txt"));
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("test.txt"))) {
// 序列化
Person person = new Person("name", 10);
objectOutputStream.writeObject(person);
// 反序列化,这里拿到的不是 Person 而是 ArrayList。
//Person p = (Person) objectInputStream.readObject();
ArrayList<Object> arrayList = (ArrayList<Object>) objectInputStream.readObject();
System.out.println(arrayList.get(0) + "," +arrayList.get(1));
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
执行序列化过程时,系统先调用 writeReplace(),如果它返回另一个对象,则系统会再去调用另一个对象的 writeReplace(),直到该方法不再返回另一个对象为止。最后再调用 writeObject() 保存该对象。
与 writeReplace() 对应的方法是:
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException;
readResolve() 会紧跟在 readObject() 之后被调用,其返回值会替代原来反序列化的对象,而 readObject() 反序列化的对象会被立即丢弃。
readResolve() 的特殊用途
readResolve() 在序列化单例类、枚举类时尤其有用。这么说是因为在 Java5 的 enum 出现之前,老式定义枚举类的方法不使用 readResolve() 会有问题。看代码示例:
public class Orientation implements Serializable {
public static final Orientation HORIZONTAL = new Orientation(1);
public static final Orientation VERTICAL = new Orientation(2);
private int value;
public Orientation(int value) {
this.value = value;
}
}
这个 Orientation 是 enum 出现之前的枚举类定义方式,先序列化然后再反序列化:
private void test() {
try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("orientation.txt"));
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("orientation.txt"))) {
objectOutputStream.writeObject(Orientation.HORIZONTAL);
Orientation orientation = (Orientation) objectInputStream.readObject();
System.out.println(orientation == Orientation.HORIZONTAL); // false
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
发现反序列化得到的对象并不是枚举类中定义的枚举对象。为了解决这个问题,就要用 readResolve() 对反序列化的结果做进一步处理:
private Object readResolve() throws ObjectStreamException {
if (value == 1) {
return HORIZONTAL;
}
if (value == 2) {
return VERTICAL;
}
return null;
}
在序列化类中加入这个方法后,再测试发现结果就为 true 了。
但是这个问题在使用 enum 定义的枚举类中是没有的:
public enum Orientation implements Serializable {
HORIZONTAL,VERTICAL
}
测试反序列化的对象是否为枚举类中的枚举对象:
private void test() {
try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("orientation.txt"));
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("orientation.txt"))) {
objectOutputStream.writeObject(Orientation.HORIZONTAL);
Orientation orientation = (Orientation) objectInputStream.readObject();
System.out.println(orientation == Orientation.HORIZONTAL); // true
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
类似的,在序列化单例类时,也会发生反序列化得到的对象与原对象不是同一个对象的问题:
public class Single implements Serializable {
private static class SingleHolder {
private static Single instance = new Single();
}
public static Single getInstance() {
return SingleHolder.instance;
}
private Single() {
}
}
---------------------------------------------------------------------------------------
public static void main(String[] args) throws IOException, ClassNotFoundException {
Single single = Single.getInstance();
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(out);
objectOutputStream.writeObject(single);
byte[] bytes = out.toByteArray();
ObjectInputStream objectInputStream = new ObjectInputStream(new ByteArrayInputStream(bytes));
Single single1 = (Single) objectInputStream.readObject();
System.out.println(single == single1); // false
}
这时就需要使用 readResolve() 进行处理了,在 Single 类中添加:
private Object readResolve() {
return SingleHolder.instance;
}
writeReplace() 和 readResolve() 的隐患
writeReplace() 和 readResolve() 也有一些隐患。它们都可以被 public、protected 和 private 修饰,因此子类就可能会继承这些方法。对 readResolve() 来说,如果子类没有重写这个方法,反序列化时就会得到一个父类对象,这是一种不易发现的错误。但如果总让子类重写这个方法,又是一种负担。通常的建议是,对于 final 类重写 readResolve() 不会有任何问题,否则重写 readResolve() 时应尽量使用 private 修饰。
2.6 要注意的问题
对象变化
反序列化得到的对象不是序列化前的对象,测试代码:
private static void test1() throws IOException, ClassNotFoundException {
Person person = new Person("Test", 12);
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(out);
objectOutputStream.writeObject(person);
byte[] bytes = out.toByteArray();
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
Person person1 = (Person) ois.readObject();
System.out.println(person == person1); // false
}
序列化编号
这里的序列化编号不是之前说的那个 serialVersionUID,而是用来检查某个对象是否已经被序列化过的编号:

之所以要使用这个序列化编号,是为了避免多个对象对同一个对象引用进行重复序列化。比如说:
public class Teacher implements Serializable {
private String name;
private Person student;
}
已知 Person 类是可以序列化的,假设有如下特殊情形:
Person person = new Person("name",1);
Teacher t1 = new Teacher("teacher1",person);
Teacher t2 = new Teacher("teacher2",person);
t1 和 t2 在进行序列化的时候都需要对它们内部持有的 person 对象进行序列化。假如没有序列化编号,那么 t1 和 t2 就会分别对 person 各进行一次序列化,产生两个 person 对象。而另一端从输入流中反序列化出来也是两个 person 对象了,而不是一个。这违背了 Java 序列化机制的初衷。
采用了序列化编号之后,只有第一次使用 writeObject() 时才会将该对象转换成字节序列并输出,后面再重复调用时输出的是序列化编号,这样可以避免一个对象被多次序列化的问题。但是这样做会有另一个隐患,就是如果一个对象在第一次调用 writeObject() 之后发生了改变,那么后面再调用 writeObject() 也仍然会输出序列化编号。
序列化可变对象时一定要注意,只有第一次调用 writeObject() 输出对象时才会将对象转换成字节序列,并写入到 ObjectOutputStream。后面如果对象实例发生了改变,再次调用 writeObject() 输出该对象时,实例变量也不会被输出,而是输出序列化编号。
多引用写入
在序列化输出过一次之后,对序列化对象进行了修改再输出一次,要注意,第二次输出要特殊处理:
private static void test1() throws IOException, ClassNotFoundException {
Person person = new Person("Test", "13");
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(out);
// 序列化输出一次
objectOutputStream.writeObject(person);
// 修改序列化对象
person.setAge("14");
// 将修改后的对象再输出一次
writeObjectAgain(person, objectOutputStream);
// 反序列化,观察 person1 和 person2 的结果
byte[] bytes = out.toByteArray();
ObjectInputStream in = new ObjectInputStream(new ByteArrayInputStream(bytes));
Person person1 = (Person) in.readObject();
System.out.println(person1);
Person person2 = (Person) in.readObject();
System.out.println(person2);
}
如果还跟第一次一样只使用 objectOutputStream.writeObject(person),会发现反序列化得到的都是第一个对象(猜测原因就是上一节讲的序列化编号):
private static void writeObjectAgain1(Person person, ObjectOutputStream objectOutputStream) throws IOException {
objectOutputStream.writeObject(person); // {name='Test', age=13},Person{name='Test', age=13}
}
private static void writeObjectAgain2(Person person, ObjectOutputStream objectOutputStream) throws IOException {
objectOutputStream.writeUnshared(person); // {name='Test', age=13},Person{name='Test', age=14}
}
private static void writeObjectAgain3(Person person, ObjectOutputStream objectOutputStream) throws IOException {
objectOutputStream.reset();
objectOutputStream.writeObject(person); // {name='Test', age=13},Person{name='Test', age=14}
}
第二种和第三种是正确的处理方法,使用 writeUnshared() 或者在调用 writeObject() 之前先调用一次 reset()。
2.7 Externalizable
如果需要序列化的类实现的不是 Serializable 接口而其子接口是 Externalizable,自定义序列化方法也是和前者类似的。只不过 Externalizable 是要求强制自义定的,必须要实现 writeExternal() 和 readExternal() 两个方法,其作用和 Serializable 的 writeReplace() 和 readResolve() 非常相似,不再赘述。执行序列化和反序列化的方式与 Serializable 相同,都是调用 readObject() 和 writeObject():
public class Course implements Externalizable {
private static final long serialVersionUID = 1L;
private String name;
private float score;
/**
* 序列化类型必须提供一个可访问的空参构造方法,否则反序列化时会抛出
* InvalidClassException,原因是 no valid constructor
*/
public Course() {
}
public Course(String name, float score) {
this.name = name;
this.score = score;
}
/**
* @param out ObjectOutput 接口的实现类之一是 ObjectOutputStream,相当于
* 还是调用的输出流去做序列化,只不过你可以自定义序列化的内容了。
*/
@Override
public void writeExternal(ObjectOutput out) throws IOException {
System.out.println("writeExternal");
out.writeObject(name);
out.writeFloat(score);
}
/**
* @param in ObjectInput 接口的实现类之一是 ObjectInputStream,可以
* 根据序列化的过程调整反序列化属性的顺序。
*/
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
System.out.println("readExternal");
name = (String) in.readObject();
score = in.readFloat();
}
public static void main(String[] args) {
Course course = new Course("English", 85);
// 还是用 ObjectOutputStream 和 ObjectInputStream 做序列化与反序列化
try (ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos)) {
oos.writeObject(course);
byte[] bytes = baos.toByteArray();
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
Course resultCourse = (Course) ois.readObject();
System.out.println(resultCourse.name + ":" + resultCourse.score);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
虽然实现 Externalizable 接口能带来一定的性能提升,但是由于必须要实现 writeExternal() 和 readExternal() 两个方法导致编程复杂度增加,所以大部分时候采用实现 Serializable 接口来实现序列化。
2.8 总结
- 对象的类名、实例变量(包括基本类型、数组、对其它对象的引用)都会被序列化;方法、类变量、transient 实例变量(也称为瞬态实例变量)都不会被序列化。
- 实现 Serializable 接口的类如果需要让某个实例变量不被序列化,在该变量前加 transient 即可。虽然 static 也能达到这个效果,但是不能这样用。
- 可序列化类 A 需要保证所有实例变量类型也是可序列化的,如果有实例变量不可序列化可用 transient 修饰。否则,类 A 不可被序列化。
- 反序列化对象时必须有序列化对象的 class 文件。
- 通过文件、网络读取序列化后的对象时,必须按实际写入的顺序读取。
3、Parcelable
Parcelable 是 Android 为我们提供的序列化的接口,Parcelable 相对于 Serializable 的使用要复杂一些,但 Parcelable 的效率相对 Serializable 也高很多。Parcelable 是 Android SDK 提供的,它是基于内存的,由于内存读写速度高于硬盘,因此 Android 中的
跨进程对象的传递一般使用 Parcelable。
3.1 基本使用
public class Course implements Parcelable {
private String name;
private float score;
/**
* 反序列化创建对象时会用这个构造方法,读取属性,需要与 writeToParcel()
* 中写属性的顺序保持一致
*/
protected Course(Parcel in) {
name = in.readString();
score = in.readFloat();
}
/**
* 实现类必须有一个 Creator 属性,用于反序列化,将 Parcel 对象转换为 Parcelable
*/
public static final Creator<Course> CREATOR = new Creator<Course>() {
// 从序列化对象中,获取原始的对象;
// 反序列化的方法,将Parcel还原成Java对象
@Override
public Course createFromParcel(Parcel in) {
return new Course(in);
}
// 创建指定长度的原始对象数组,提供给外部类反序列化这个数组使用。
@Override
public Course[] newArray(int size) {
return new Course[size];
}
};
/**
* 描述,返回的是内容的描述信息,只针对一些特殊的需要描述信息的对象,需要返回1,其他情况返回0就可以
* 描述当前 Parcelable 实例的对象类型
* 比如说,如果对象中有文件描述符,这个方法就会返回上面的 CONTENTS_FILE_DESCRIPTOR
* 其他情况会返回一个位掩码
*/
@Override
public int describeContents() {
return 0;
}
/**
* 将对象转换成一个 Parcel 对象
*
* @param dest 表示要写入的 Parcel 对象
* @param flags 表示这个对象将如何写入
*/
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(name);
dest.writeFloat(score);
}
}
Kotlin 实现 Parcelable 借口的方式更简洁,可以通过 Generator 中的插件自动生成,也可以通过 @Parcelize 注解生成:
@Parcelize
data class CourseTest(var name: String, var score: Float) : Parcelable
3.2 理论知识
底层是通过 Parcel 先包装要传输的数据,然后在 Binder 中传输,也就是用于跨进程传输数据
简单来说,Parcel 提供了一套机制,可以将序列化之后的数据写入到一个共享内存中,其他进程通过 Parcel 可以从这块共享内存中读出字节流,并反序列化成对象,下图是这个过程的模型:
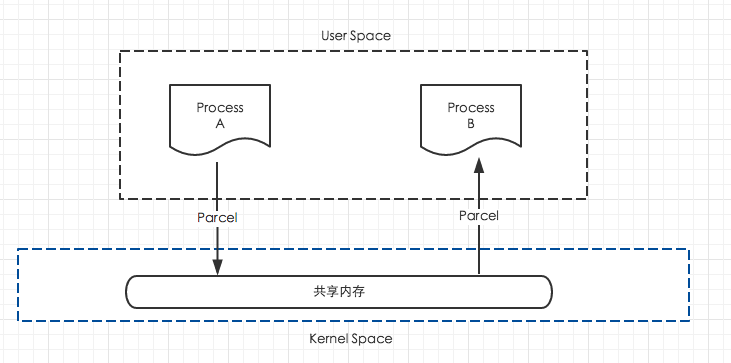
Parcel 可以包含原始数据类型(用各种对应的方法写入,比如 writeInt()、writeFloat() 等),可以包含 Parcelable 对象,它还包含了一个活动的 IBinder 对象的引用,这个引用导致另一端接收到一个指向这个 IBinder 的代理 IBinder。Parcelable 通过 Parcel 实现了 read 和 write 的方法,从而实现序列化和反序列化。
一个简单的 Parcel 的使用示例:
private static void test1() {
// 通过对象池拿到一个 Parcel 对象
Parcel writeParcel = Parcel.obtain();
// 填充数据
writeParcel.writeInt(12);
writeParcel.writeInt(19);
// 序列化,得到一个字节数组,IPC 操作就围绕这个数组
byte[] bytes = writeParcel.marshall();
Log.d("Frank", "byteArray = " + bytes.length); // 8
// 数据写入完成之后,需要将指针调整到最初的位置
writeParcel.setDataPosition(0);
// 释放 writeParcel
writeParcel.recycle();
Parcel readParcel = Parcel.obtain();
// 反序列化操作
readParcel.unmarshall(bytes, 0, bytes.length);
int dataSize = readParcel.dataSize();
Log.d("Frank", "readParcel size = " + dataSize); // 8
for (int i = 0; i < dataSize; i = i + 4) {
readParcel.setDataPosition(i);
Log.d("Frank", "value = " + readParcel.readInt()); // 12 19
}
readParcel.recycle();
}
3.3 Parcelable 与 Serializable 比较
- 在内存使用上,Serializable 在序列化过程中使用了反射机制会产生大量的临时变量导致频繁的 GC,而 Parcelable 以 IBinder 为信息载体,内存开销较小。
- 在读写数据上,Serializable 通过 IO 流的形式将数据写入到硬盘或者传输到网络上,而 Parcelable 是在内存中直接进行读写,所以速度较快。但是如果需要做数据持久化,还是要用 Serializable。(Parcelable 能转成 byte[],那么实际上也就是能持久化。但是 Parcelable 主要还是在内存中用作客户端通信用。)
参考:
Android中Parcelable的原理和使用方法
Android Parcel对象详解
Kotlin 一个好用的新功能:Parcelize
实用工具-JSON生成Java实体类