C++ 在线刷题网站
文章目录
1. 前言
环境:CentOS 7.6
项目:在线刷题网站,是一个类似于「力扣」那样的刷题网站
项目基本功能:和力扣的核心功能一样,需要完成用户代码的编译,运行,跑测试用例,并将用户代码的执行结果返回给用户
所涉及库:除了一些基础库之外,还用到了
Boost标准库,使用了操作字符串,时间戳,uuid 相关接口cpp-httplib:开源网络库,简化开发,不需要再写客户端服务端的套接字等繁琐代码ctemplate:开源库,用来渲染前端页面jsoncpp:开源库,用于序列化和反序列化MySQL C connect:用于操作数据库Ace代码编辑器
亮点:
- 使用了
Boost,MySQL,ctemplate,pthread等相关库 - 实现负载均衡:一个服务器用来接收所有的代码编译请求,其他服务器用来编译用户代码,而前者会将请求均匀地发送给这些 编译服务器
- 对用户账号中的密码以 「盐值 + md5」 的方式进行密文存储,就算数据库被盗取,用户的密码仍然安全
- 手动实现了会话功能,可以自动登录
- 实现了管理员的录题功能
- 题库页面中,在用户已经完成的题目,的题号前打钩,就像这样

2. 效果展示
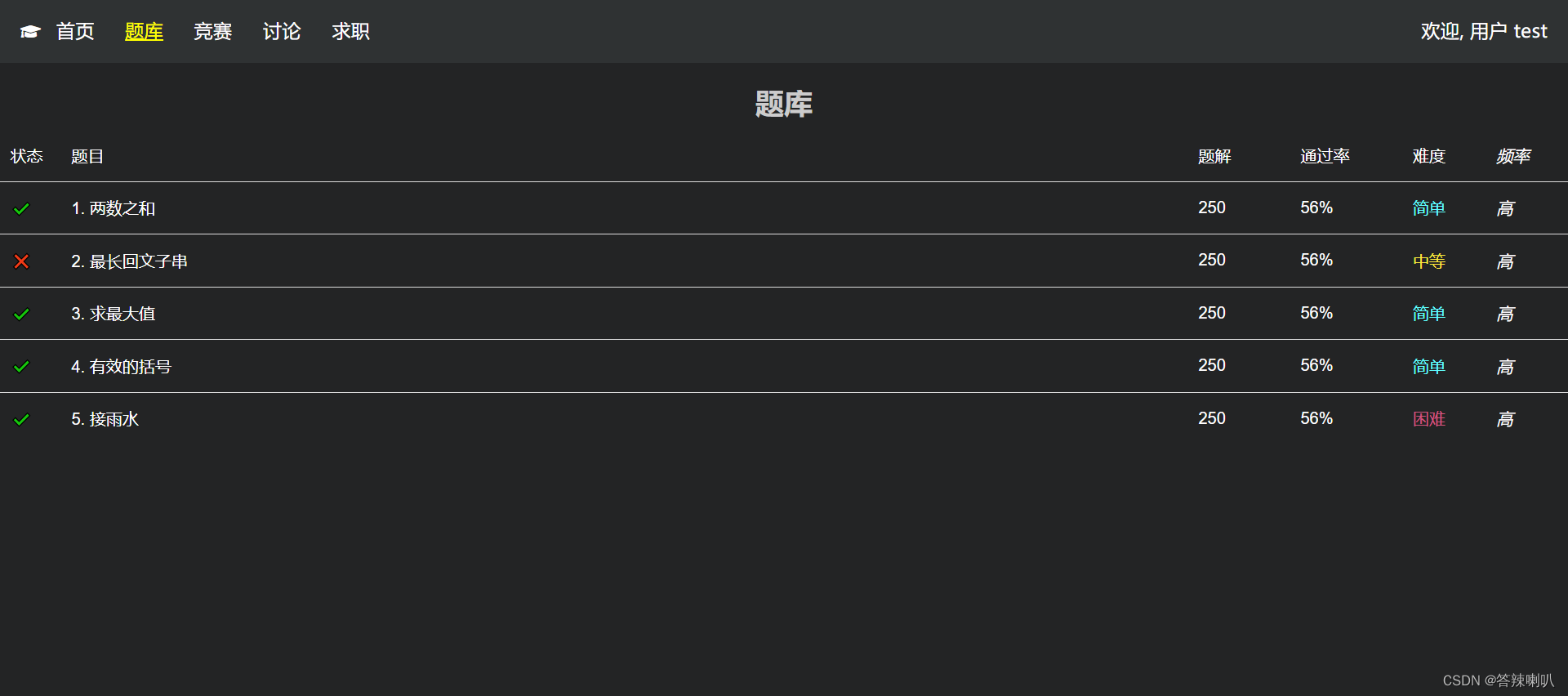
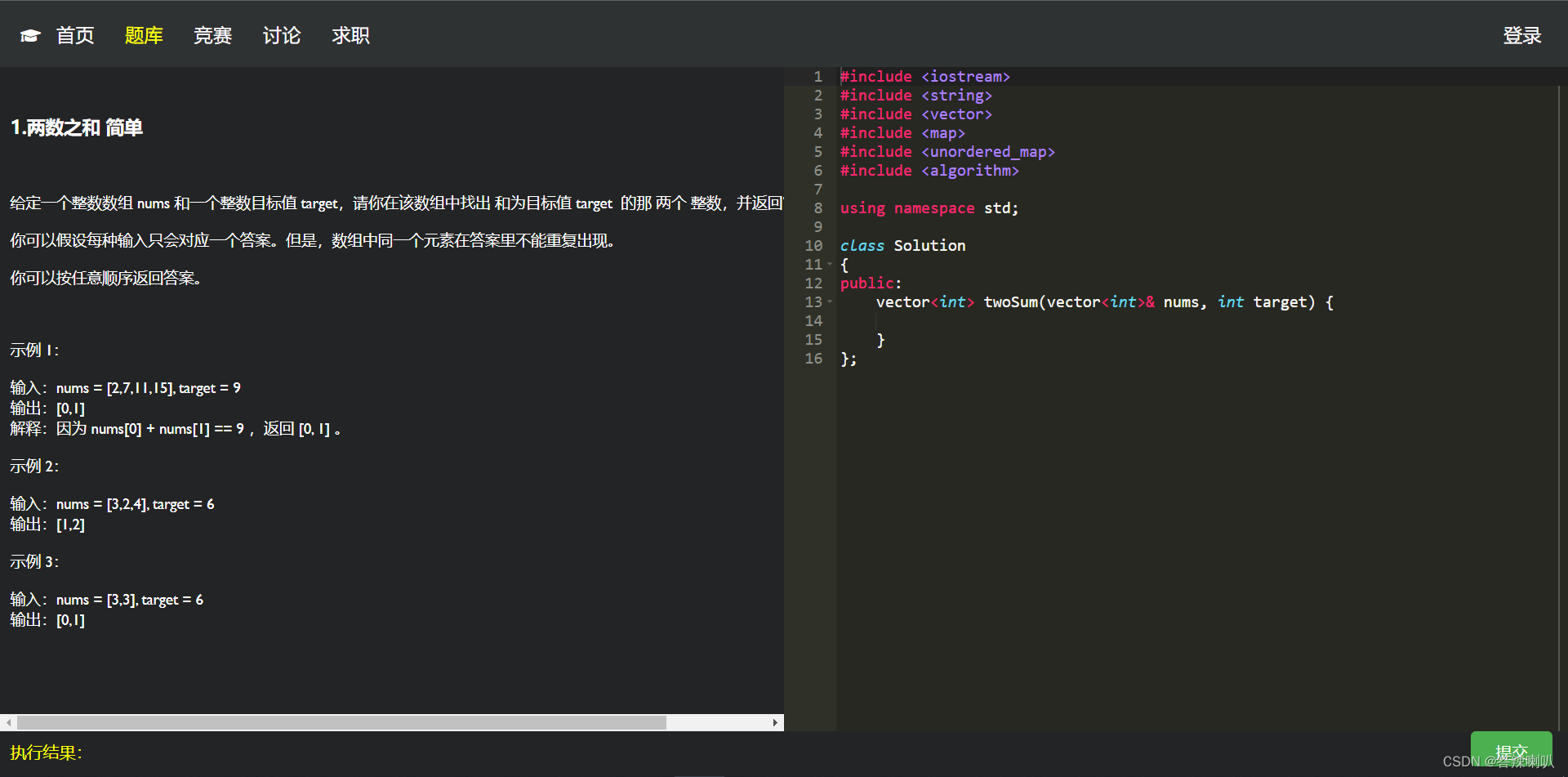
3. 框架
首先,先捋一下流程:用户会向服务器发送请求,比如申请获取题库,或者获得一个具体题目的具体信息,或者是将用户自己的代码交给服务器编译,运行,并获取结果
结合前面提到了负载均衡,上述流程可以交给两个角色来完成,分别为 dispatcher,和 executor
- 上述请求中,很明显,代码的编译,运行,跑测试用例环节是最费时的,所以这个请求可以专门给「编译 / 运行服务器」来处理
dispatcher:用来将编译 / 运行请求均匀地分给「编译服务器」处理,除此之外,对于「申请获取题库」等等这些开销不大的请求,一个dispatcher也可以顺手完成executor:就是一个专门「完成用户代码运行」请求的服务器,并且可能有多个
具体就是:对用户代码进行编译,如果编译不通过,那就将编译结果返回给用户;否则拿用户代码来跑所有的测试用例,并按照自己的业务逻辑返回给用户一定的结果
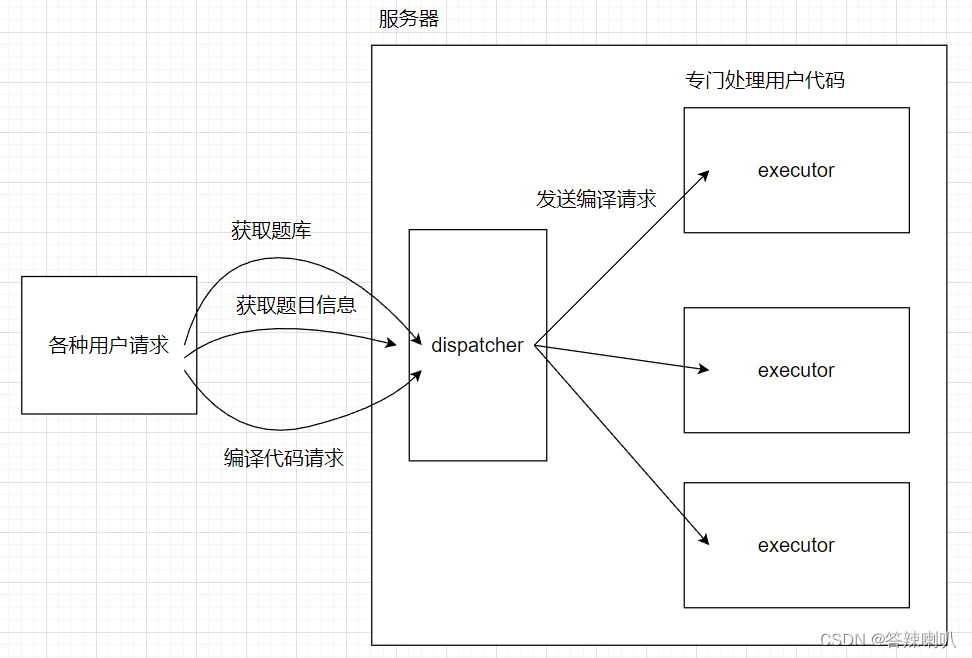
所以项目可以分为三个文件夹,ojserver (dispatcher) 和 compile_server (executor),再加一个大家都用得到的工具文件夹 common,专门提供各种使用频率高的接口
4. common
4.1 工具类
在后续操作中,可能需要对时间进行操作,对字符串操作,对文件操作…,所以需要创建一个 util.hpp 文件,里面专门提供对各种数据进行操作的接口
在这一切之前,先在 common 定义一个全局函数 log,用来打印日志,需要打印日志,也就需要打印相应时间,这里我们打印时间戳
打印时间戳 —— 这里可以使用 Boost 库的相关接口
Boost 库的安装
yum install -y boost-devel
然后引入生成时间戳的相关头文件
// 时间戳接口 Boost 库
#include <chrono>
随后,,就可以编写时间戳(ms)为单位,返回 long long 类型的整数时间戳,然后放在 TimeUtil 类中
class TimeUtil
{
public:
static long long CurrentTimeStamp()
{
auto now = std::chrono::system_clock::now();
auto timestamp = std::chrono::time_point_cast<std::chrono::milliseconds>(now);
return timestamp.time_since_epoch().count();
}
};
4.2 日志
比如现在我需要打印一行日志,那么我们需要的信息有:日志等级,文件名(哪个文件打印的日志),以及该文件的代码行数。比如:INFO: executor.cpp 182 行
于是就可以创建这样一个打印日志函数,然后返回一个 std::ostream 对象,方便进行 Log(level) << filename << line 操作
// LOG() << msg
inline std::ostream& Log(const string& level, const string& filename, int line)
{
// 添加日志等级
string msg = "[" + level + "]";
// 添加文件的名称
msg += "[" + filename + ']';
// 添加报错行
msg += "[" + std::to_string(line) + "]";
// 添加日志的打印时间戳
msg += "[";
msg += to_string(TimeUtil::CurrentTimeStamp());
msg += "] ";
cout << msg; // 输入到缓冲区中, 但是不刷新
return std::cout;
}
但是在打印日志的时候,每次都需要手动输入文件名,和当前行,很不方便,所以在使用的时候可以这么用:Log("WARNING", __FILE__, __LINE__)就可以自动获取当前的文件名以及当前行数
然后定义几个日志等级
enum { // 日志等级
INFO, // 普通通知
DEBUG, // 用于调式
WARNING, // 警告
ERROR, // 错误
FATAL // 崩溃,可能导致服务器无法对外提供服务
};
然后再定义个宏,来简化 Log 函数的调用
#define LOG(level) Log(#level, __FILE__, __LINE__)
解释:直接让 LOG(level) 来自动替换这个函数,不必重复输入,并且每次输入日志等级的字符串也麻烦,所以 Log(#level, __FILE__, __LINE__) 中的 井号# 可以让传进来的参数直接变成字符串
比方说,调用 LOG(INFO) << "发生错误"; 的时候,最终会被替换成 Log("INFO", __FILE__, __LINE__) << "发生错误";
5. 编译
5.1 前言
根据上面说的,ojserver 会接收到用户的代码,然后将编译,运行请求交给 compiler 进行处理
也就是说 compiler的工作可以分为以下几个部分:接收请求,编译,跑测试用例,将结果返回
大致思路:compiler 服务器会收到请求,请求里面包括用户的代码,然后需要将 用户代码 写入到一个 .cpp 的临时文件中,然后对这个源文件进行编译,随后生成可执行文件,再用这个可执行文件来跑测试用例,最后返回用户结果。
所以需要一个临时文件夹来存放这里面产生的各种临时文件,命名为 temp
5.2 正文
先想想,在编译代码之前,需要有什么?—— cpp 源文件,也就是需要知道文件名和文件路径
首先所以这里创建一个文件 compiler.hpp,里面创建一个类 Compiler 专门负责编译,对于编译
- 如果编译成功,那就什么都不说,并且生成一个可执行文件。所以可以靠这个可执行文件是否存在,来判断是否编译成功
- 如果编译失败,那么这个编译结果需要告知用户,所以需要写在一个文件里
所以规定:假设现在有一个文件名 F,那么源文件命名为 F.cpp,对应的可执行文件为 F.exe,如果编译失败,那么编译失败的原因写入 F.compile_err文件,并且这些文件都会放在 temp目录下
- 相应的,后面这个可执行文件可能会有输入,输出,错误等数据,也需要为其建立相应的文件,分别是
F.stdin,F.stdout,F.stderr
所以在编译的时候,只需要传入一个文件名,compiler 就可以找到对应的 .cpp, .compile_err 等文件,当然,前提是这个文件名是唯一的。
5.3 PathUtil
所以为了根据 文件名,从而获取各种格式的文件,这里就需要 关于路径的工具类,传入一个文件名,获取其完整路径
// 这个存放临时文件的文件夹的路径
const string tempPath = "./temp/";
// 负责处理路径的工具类, 可以对路径进行各种拼接操作
class PathUtil
{
public:
// 拼接出完整的文件路径, 添加前缀和后缀
static string Joint(const string& filename, const string& suffix)
{
string result = tempPath;// temp 文件夹的路径
result += filename; // 添加文件名
result += suffix; // 添加后缀
return result;
}
// 获取源文件路径
static string SrcPath(const string& filename)
{
return Joint(filename, ".cpp");
}
// 获取可执行程序路径
static string ExePath(const string& filename)
{
return Joint(filename, ".exe");
}
// 获取存储编译错误信息的程序路径
static string CompileErrPath(const string& filename)
{
return Joint(filename, ".compile_err");
}
// 用户程序运行时的 stderr 文件路径
static string StderrPath(const string& filename)
{
return Joint(filename, ".stderr");
}
// 用户程序的 stdin 文件路径
static string StdinPath(const string& filename)
{
return Joint(filename, ".stdin");
}
// 用户程序的 stdout 路径
static string StdoutPath(const string& filename)
{
return Joint(filename, ".stdout");
}
};
5.4 Compile
于是 Compiler 类中就可以对外提供一个编译的接口 Compile
该接口的实现思路:
- 外界提供一个文件名,该接口就可以找到该文件的
.cpp文件路径 - 然后创建子进程,子进程需要先将
.compile_err文件打开,因为编译过程可能会出错,所以需要预先打开,如果编译出错,就可以直接往这个文件中写入 - 使用程序替换,调用
g++来编译这个.cpp程序,然后形成对应的可执行文
execlp("g++", "g++", "-o", exe_path.c_str(), src_path.c_str(), "-std=c++11", nullptr); - 如果编译错误,那么 g++ 会将错误信息写进 标准错误 中,所以在程序替换之前,还需要进行重定向,将原本写入 标准错误 中的信息,重定向到
.compile_err文件中 - 然后父进程还需要等待子进程,如果编译成功,那么会生成相应的可执行文件,这里需要检验是否生成
所以这里还需要在 util.hpp 工具类中补充「FileUtil」类,来添加 「判断文件是否存在」的接口 man 2 stat
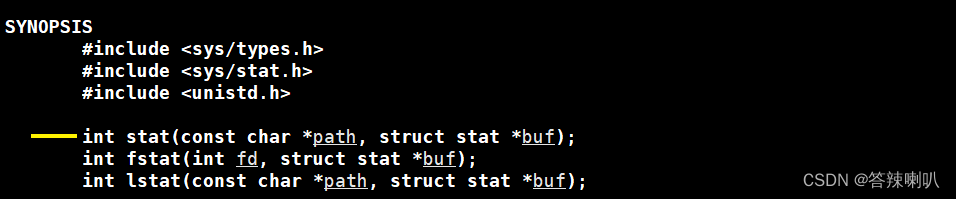
char* path:文件路径struct stat* buf:输出型参数,里面记录了文件的状态等信息,这里暂时用不到,这里只需要判断是否存在就够了return val:返回 0 表示成功
// 对文件操作的工具类
class FileUtil
{
public:
static bool Exists(const string& path)
{
struct stat file_stat;
// 获取文件属性成功就会返回 0, 第二个参数 struct stat 就是文件属性,是输出型
if (stat(path.c_str(), &file_stat) == 0)
{
return true;
}
return false;
}
};
所以 Compiler 类中的 Compile —— 编译接口如下
// 返回值:是否编译成功
// 参数:编译的文件名
// file_name -- ./temp/file_name.cpp
// file_name -- ./temp/file_name.exe
// file_name -- ./temp/file_name.compile_err
static bool Compile(const string& file_name)
{
const string src_path = PathUtil::SrcPath(file_name);
const string exe_path = PathUtil::ExePath(file_name);
const string compile_err_path = PathUtil::CompileErrPath(file_name);
int pid = fork();
if (pid < 0) {
LOG(ERROR) << "创建子进程失败" << endl;
return false;
}
else if (pid == 0) {
umask(0);
// 如果编译错误, 那么就将 stderr 重定向到日志文件中
int fileErr = open(compile_err_path.c_str(), O_CREAT | O_WRONLY, 0644);
if (fileErr < 0) { // 创建失败, 直接退出
LOG(WARNING) << "error 文件创建失败" << endl;
}
dup2(fileErr, stderr->_fileno); // 重定向到 stderr 中
// 程序替换并不会影响原进程的文件描述符表,所以编译错误的话,错误信息会写入 .compile_err
// 程序替换, 负责编译文件
execlp("g++", "g++", "-o", exe_path.c_str(), src_path.c_str(), "-std=c++11", nullptr);
LOG(ERROR) << "g++ 程序替换失败, 编译失败" << endl;
// 编译完就退出
exit(0);
}
else {
// 要等待子进程, 来检验是否生成了可执行程序
waitpid(pid, nullptr, 0);
// 如果存在这个文件的可执行文件, 那么就可以认为编译成功, 否则就是编译失败
if (FileUtil::Exists(exe_path.c_str())) {
LOG(INFO) << src_path << " 成功生成可执行程序" << endl;
return true;
}
}
LOG(WARNING) << src_path << " 生成可执行文件失败" << endl;
return false;
}
};
6. 运行
大致思路:
- 如果编译成功,那么对应就会存在可执行文件,运行的时候就直接运行这个可执行文件。
- 创建子进程,让子进程发生程序替换执行这个可执行程序
- 该程序也应该有标准输入,标准输出,标准错误,所以在程序替换之前,需要分别打开对应的文件,并且进行重定向
- 父进程还需要等待子进程完成运行功能,并且获取子进程的退出结果,并裁去低 8 位,如果返回值为 0,说明一切顺利;如果返回值大于 0 ,说明程序运行时出现异常;如果返回值小于 0,说明出现了其他问题
- 补充:用户的代码在运行的时候不能过分占用资源,所以应该为用户代码运行资源设限制,比如 CPU 占用时间不能太长,申请的空间不能太多
6.1 限制进程资源
Linux 中提供了限制进程资源的接口 setrlimit ,可以对 CPU 占用时间,内存空闲等等资源做限制
- 其中涉及到了一个结构体,
struct rlimit结构体,里面有两个成员,rlim_max和rlim_cur,分别表示资源的最大限制以及当前限制 - 也就是对于一个资源,对应的结构体需要填写两个属性,一个是最大限制,一个当前限制
- 当前限制可以控制进程在当前时间内对资源的限制,确保资源可以被合理地分配
- 最大限制是为了防止进程由于一些不可控因素导致资源过度使用,不过这里的最大限制我们就不关心了,具体还得看实际情况,所以设为最大值
// 限制进程的资源, 并且 memory_limit 的单位是 KB
static void LimitProcResource(int cpu_limit, int memory_limit)
{
// 设置 CPU 最大占用时长
struct rlimit cpu;
cpu.rlim_max = RLIM_INFINITY;
cpu.rlim_cur = cpu_limit;
setrlimit(RLIMIT_CPU, &cpu);
// 设置最大内存占用大小
struct rlimit memory;
memory.rlim_max = RLIM_INFINITY;
memory.rlim_cur = memory_limit * 1024;
setrlimit(RLIMIT_AS, &memory);
}
6.2 Run
于是 Runner 就可以对外提供一个跑用户代码的接口 Run,需要传入 文件名,CPU 限制,以及内存限制
class Runner
{
public:
Runner() = default;
~Runner() = default;
// 用于执行用户代码(可执行程序),只需要指明文件名就好了
// 如果返回值 > 0 ,那么就是程序异常
// 如果返回值 == 0,运行正常, 没有异常
// 如果返回值 < 0 ,那么就是其他问题
static int Run(const string& file_name, int cpu_limit, int memory_limit, int question_id)
{
const string exe_path = PathUtil::ExePath(file_name); // 这个可执行文件的路径
const string stdin_path = PathUtil::StdinPath(file_name); // 标准输入的路径
const string stdout_path = PathUtil::StdoutPath(file_name); // 标准输入的路径
const string stderr_path = PathUtil::StderrPath(file_name); // 标准输出的路径
umask(0);
int stdin_fd = open(stdin_path.c_str(), O_CREAT | O_WRONLY, 0644);
int stdout_fd = open(stdout_path.c_str(), O_CREAT | O_WRONLY, 0644);
int stderr_fd = open(stderr_path.c_str(), O_CREAT | O_WRONLY, 0644);
// 将执行结果写入文件的读写 fd
if (stdin_fd < 0 || stdout_fd < 0 || stderr_fd < 0) {
LOG(ERROR) << "文件打开失败" << endl;
return -1;
}
pid_t pid = fork();
if (pid < 0) {
LOG(ERROR) << "创建子线程失败" << endl;
close(stdin_fd);
close(stdout_fd);
close(stderr_fd);
return -2;
}
else if (pid == 0) {
LOG(INFO) << "开始执行" << exe_path << "文件" << endl;
cout << "stdout_fd: " << stdout_fd << " " << "stdout: " << stdout->_fileno << endl;
dup2(stdin_fd, stdin->_fileno);
dup2(stdout_fd, stdout->_fileno);
dup2(stderr_fd, stderr->_fileno);
LimitProcResource(cpu_limit, memory_limit);
// 执行程序替换, 并且携带一个参数 judge_fd, 也就是往 特定的文件 中写入数据
execl(exe_path.c_str(), exe_path.c_str(), nullptr);
LOG(WARNING) << "程序替换失败, 代码没能运行" << endl;
exit(1);
}
else {
close(stdin_fd);
close(stdout_fd);
close(stderr_fd);
int status = 0; // 获取子进程的退出结果
waitpid(pid, &status, 0); // 阻塞等待
LOG(INFO) << "等待判题完成" << endl;
LOG(INFO) << "运行成功" << endl;
return status & 0x7F; // 返回进程的退出信号,如果是异常,就是正数
}
}
// 限制进程的资源, 并且 memory_limit 的单位是 KB
static void LimitProcResource(int cpu_limit, int memory_limit)
{
// 设置 CPU 最大占用时长
struct rlimit cpu;
cpu.rlim_max = RLIM_INFINITY;
cpu.rlim_cur = cpu_limit;
setrlimit(RLIMIT_CPU, &cpu);
// 设置最大内存占用大小
struct rlimit memory;
memory.rlim_max = RLIM_INFINITY;
memory.rlim_cur = memory_limit * 1024;
setrlimit(RLIMIT_AS, &memory);
}
};
7. 执行
至此为止,已经提供了编译 和 运行,接下来需要将这两个行为拼凑在一起,形成一个完成的服务,称为 执行 (runtime)
接下来再创建一个文件 runtime.hpp ,其中提供一个类 Runtime,对外提供一个接口 Start,这个其实就是将编译和运行逻辑两个功能整合一下。
大致思路:
- 编译的时候只知道了文件名,源文件的生成并不由编译负责,所以
Start需要将用户代码写入到.cpp文件中,再将文件名传给Compile接口,其会去编译这个.cpp文件 - 而文件名是
Start中随机生成的一个全局唯一的字符串命名的,然后这个名字会以传参形式告知Compile和Run Compile函数编译完成之后,如果一切正常,那么可执行文件就可以顺利生成,此时就可以再调用Run函数来执行用户代码- 记录
Run函数的返回值,并将这个返回值转化成 对应的执行情况,比如 “代码运行成功”,“代码执行过程中发生段错误” - 代码的编译,运行都会产生很多临时文件,所以在对一个用户请求构造完响应之后,需要将这个请求产生的中间文件都清理掉
补充:
- 当服务器收到请求之后,就会调用
Start接口,所以Start需要网络中传输过来的json数据 - 同时,也需要将
Start的运行结果转化成json形式的数据返回给前端 - 所以就需要用到序列化和反序列化
7.1 json
安装 json 库,其中接口的使用可以看一下这篇文章 jsoncpp 常用方法,挺详细的
yum install jsoncpp-devel
并且在编译的时候记得加上 -ljsoncpp 选项
7.2 Start 参数
综上所述,我们内部规定:传到 Start 中的 json 数据需要有什么呢?
question_id:当前用户写的题目对应的编号cpu_limit:就是上面说的,CPU 占用的时间,不同的题目可能会有不同的限制要求memory_limit:同上,内存的最大使用量input:可以是用户输入的测试用例,本文暂不实现code:用户运行的代码
那么 Start 函数完成之后,需要告知前端什么数据?
status:该程序运行的状态码,可以自定义数字对应的含义,0 表示一切正常,> 0 表示的是程序运行中发生的异常,比如发生段错误收到的SIGSEGV信号, < 0 可以表示一些其他错误,比如 -1 表示代码为空,-2 表示编译不通过…reason:将status数字翻译成对应的信息描述stdout:编译成功且运行正常的程序,在运行过程中,可能会往标准输入和标准错误中打印数据,比如cout << "Debug: i = " << i << endl或者cerr << ...,那么这些数据也需要提取出来告知用户
并且,在上文中 [ 6.2 运行 大致思路 ] 中提到了,我们将用户程序的标准输出 / 错误重定向到对应后缀的文件中了,所以 这里就是读文件操作strerr:同上stdout,当然,这两个存在的前提是程序正常跑完了
然后将这些数据直接序列化成 json 数据,作为输出型参数传递给上层
7.3 FileUtil
所以,还需要在工具类 FileUtil 补充:生成全局唯一文件名,从文件中读取数据,往文件中写入数据的函数,清理产生的临时文件
- 生成全局唯一文件名
直接通过 ms 级时间戳 + 全局唯一递增因子,进行拼接可以了
// 生成唯一的文件名
static string GetUniqueName()
{
// 通过毫秒级时间戳 以及 原子性递增来保证唯一性
static std::atomic_uint id(0);
id ++;
string ms_stamp = to_string(TimeUtil::CurrentTimeStamp());
string uid = std::to_string(id);
return ms_stamp + '_' + uid;
}
- 从文件中写入数据
传入一个文件路径,再传入要写入的文件,无脑写入就好
static bool WriteToFile(const string& tar, const string& code)
{
ofstream out(tar); // 打开流
if (out.is_open() == false) { // 如果没有被打卡
return false;
}
out.write(code.c_str(), code.size());
out.close();
return true;
}
- 从文件中读取数据
传入文件路径,这里可以区分一下:如果用户传入一个 true,那么将按文件原样读取内容到字符串中;如果传入一个 false,那么读取文件的时候会去掉换行符
static bool ReadFromFile(const string& tar, string* data, bool newline)
{
ifstream in(tar);
if (in.is_open() == false) { // 如果没有打开
return false;
}
// 读取一行数据读到换行就停, 并且不会读取换行符
string line ;
while (getline(in, line)) {
*data += line;
*data += newline ? "\n" : "";
}
in.close();
return true;
}
- 清理产生的临时文件
刚刚建立的各种文件,.cpp,.compile_err,.stdout文件都是以 生成的唯一file_name为前缀的文件名,所以删除这些文件,传入file_name,然后:如果文件存在,那删除
// unlink: Linux 中提供的接口, 传入文件路径可以删除文件
static void RemoveTempFiles(const string& filename)
{
string path = PathUtil::SrcPath(filename);
if (FileUtil::Exists(path)) unlink(path.c_str());
path = PathUtil::CompileErrPath(filename);
if (FileUtil::Exists(path)) unlink(path.c_str());
path = PathUtil::ExePath(filename);
if (FileUtil::Exists(path)) unlink(path.c_str());
path = PathUtil::StdinPath(filename);
if (FileUtil::Exists(path)) unlink(path.c_str());
path = PathUtil::StdoutPath(filename);
if (FileUtil::Exists(path)) unlink(path.c_str());
path = PathUtil::StderrPath(filename);
if (FileUtil::Exists(path)) unlink(path.c_str());
}
7.4 Start
所以最终 Runtime 代码如下
class Runtime
{
public:
static void Start(const string& in_json, string* out_json)
{
// 将 json 数据反序列化成一个个具体的数据
Json::Value root;
Json::Reader reader;
reader.parse(in_json, root);
string code = root["code"].asString();
string input = root["input"].asString();
int cpu_limit = root["cpu_limit"].asInt();
int memory_limit = root["memory_limit"].asInt();
int question_id = root["question_id"].asInt(); // 题目的编号
// 提取完成
// goto 中间的代码,不能出现变量的定义
Json::Value ret_root;
// 获取唯一文件名
string file_name = FileUtil::GetUniqueName();
int run_case = 0;
int final_status = 0; // start 中最终的运行状态
if (code.empty()) {
final_status = -1;
goto END;
}
// 获取唯一性的文件名
// 将 code 中的代码写入到文件中
if (FileUtil::WriteToFile(PathUtil::SrcPath(file_name), code) == false) {
LOG(INFO) << "用户代码写入源文件中失败" << endl;
final_status = -2;
goto END;
}
// 编译, 如果编译失败, 那么直接从这个 .compile_err 的文件中读取数据
if (Compiler::Compile(file_name) == false) {
final_status = -3;
goto END;
}
// 获取 Run 函数的执行结果
run_case = Runner::Run(file_name, cpu_limit, memory_limit, question_id);
if (run_case < 0) {
final_status = -2;
goto END;
}
else if (run_case > 0) { // 程序出现异常, 就是收到了信号, 这时候返回值就是信号
final_status = run_case;
}
else { // 运行正常, 需要判断运行结果, 运行结果在 stdout 里面
final_status = 0;
}
END:
ret_root["status"] = final_status;
ret_root["reason"] = Translate(final_status, file_name);
if (final_status == 0) { // 全部运行顺利
string stdout_str;
FileUtil::ReadFromFile(PathUtil::StdoutPath(file_name), &stdout_str, true);
ret_root["stdout"] = stdout_str;
string stderr_str;
FileUtil::ReadFromFile(PathUtil::StderrPath(file_name), &stderr_str, true);
ret_root["stderr"] = stderr_str;
}
Json::StyledWriter writer;
*out_json = writer.write(ret_root);
// 然后去掉这些临时文件
FileUtil::RemoveTempFiles(file_name);
cout << "删除文件" << endl;
}
// 将信号翻译成具体的原因
static string Translate(int number, const string& file_name)
{
string desc ;
switch(number)
{
case 0:
desc = "代码运行成功";
break;
case -1:
desc = "代码为空";
break;
case -2:
desc = "未知错误";
break;
case -3: // -3 表示编译错误, 这时候就去 .compile_err 文件中读取编译错误的原因
FileUtil::ReadFromFile(PathUtil::CompileErrPath(file_name), &desc, true);
break;
case SIGSEGV:
desc = "段错误";
break;
case SIGFPE:
desc = "浮点数计算错误";
break;
case SIGABRT:
desc = "内存溢出";
break;
case SIGXCPU:
desc = "运行超时";
break;
default:
desc = "未知错误 code = " + std::to_string(number);
break;
}
return desc;
}
};
8. 启动服务
有了 Start 函数之后,上层只需要传递给 Start 函数 json 字符串,就可以获取到 这段代码 的编译,运行等相关情况了
于是现在就需要一个能够接收到 服务请求的TCP服务器,这里使用开源库 cpp-httplib
8.1 安装 httplib
安装网址:cpp-httplib – github
使用方式:将 cpp-httplib.h 文件直接放到项目文件夹中,用 #include 导入就好了
但是这个玩意需要使用 高版本的 g++,所以这里还需要安装高版本的 g++,比如 7 版本
sudo yum instal1 centos-release-scl scl-utils-build
// 安装 G++ 高版本
sudo yum insta11 -y devtoolset-7-gcc devtoolset-7-gcc-c++
ls /opt/rh/
// 改用 g++ 7, 仅本次登录 xshell 时有效
scl enable devtoolset-7 bash
gcc -v
// 然后在下面这个文件中添加上面那条 scl enable ... 命令,可以保持每次登录的时候都是高版本的 g++
vim ~/.bash_profile
8.2 compile_server.cpp
这里面放一个 .cpp 文件,使用 httplib 库中的接口启动一个服务器,用来接收用户的 代码 编译 / 运行请求,然后拿请求中用户发送的数据,交给 Runtime.Start() 处理,并将其返回的数据发回给前端
// ./executor port 的方式运行, 也就是需要指定端口号
int main(int argc, char* argv[])
{
if (argc != 2) return 0;
Server server;
// 注册这个路由以及它的回调函数
server.Post("/runtime", [](const Request& req, Response& resp) {
// 从 请求中的 body 获取 json 格式的数据, 包括用户代码, 题号等数据
string in_json = req.body;
// 返回给前端的 json 数据, 输出型参数
string out_json ;
if (!in_json.empty()) {
Runtime::Start(in_json, &out_json);
cout << "Start 执行完成" << endl;
resp.set_content(out_json, "application/json; charset=utf-8");
}
});
// 开始监听, 第二个参数是端口号
server.listen("0.0.0.0", atoi(argv[1]));
return 0;
}
9. 测试 compiler
至此,executor (compiler) 模块就差不多完成了,下文在项目主体完成之后,会有拓展,到时再来修改这里的代码。
接下来我们测试一下:编写 Makefile 并执行
executor: compile_server.cpp
g++ -o $@ $^ -std=c++11 -ljsoncpp -lpthread
.PHONY:clean
clean:
rm -rf executor

⚠ 注意一下:executor 只负责编译运行程序,这里还不涉及到判题,所以我们用 postman 传一串 json 数据进去试试
-
测试情况 1:代码耗时

响应:

-
测试情况 2:编译错误,代码少个分号
 响应:
响应:

-
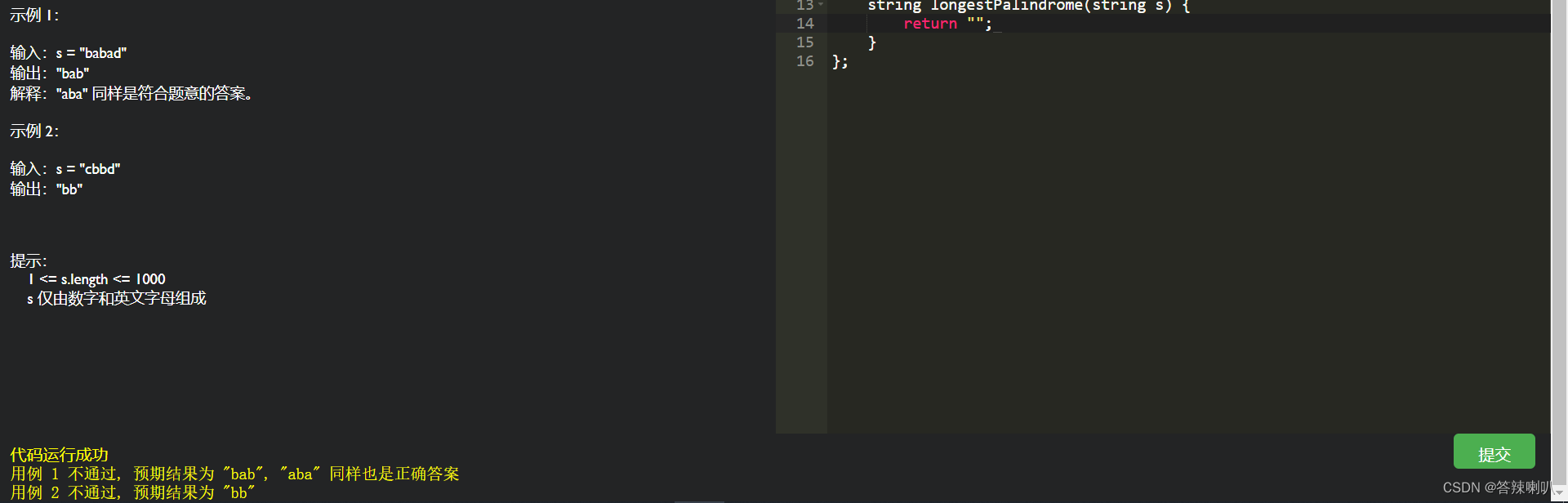
测试情况 3:正常运行,并且代码需要打印数据
hello
 响应:可以看出,该程序打印的数据也被提取了出来
响应:可以看出,该程序打印的数据也被提取了出来

10. 梳理题目逻辑
在本项目中,一个单独的题目应该具有以下数据:
- 编号
id - 标题
title - 难度
difficulty - 题目描述
desc - 预代码
pre_code - 测试代码
test_code - 时间要求
cpu_limit - 空间要求
memory_limit
关于预代码 pre_code
意思就是用户的代码,比如下面这个,同时也是用户写代码的地方
测试代码 test_code
这里需要针对每个题目设计测试用例,比如 Test1(), Test2()...等等,然后在 main 函数中调用这两个测试用例
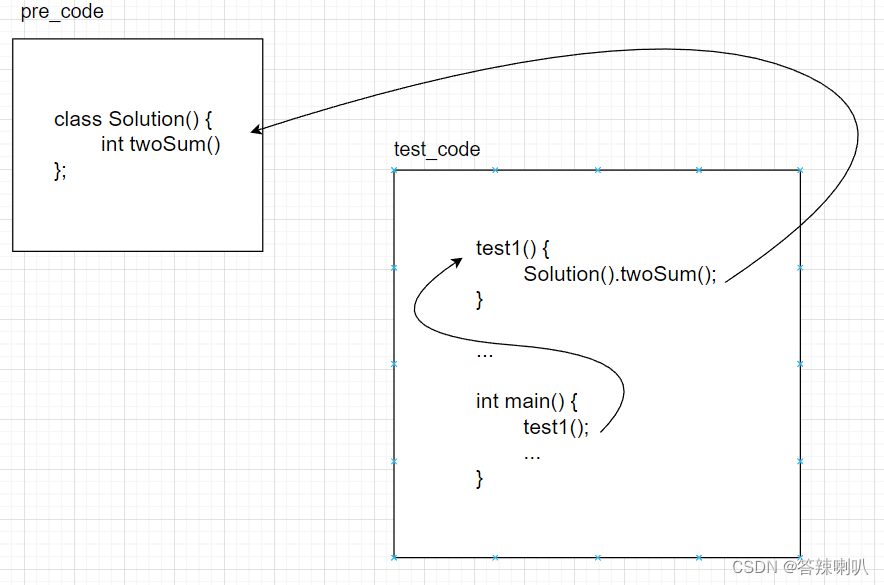
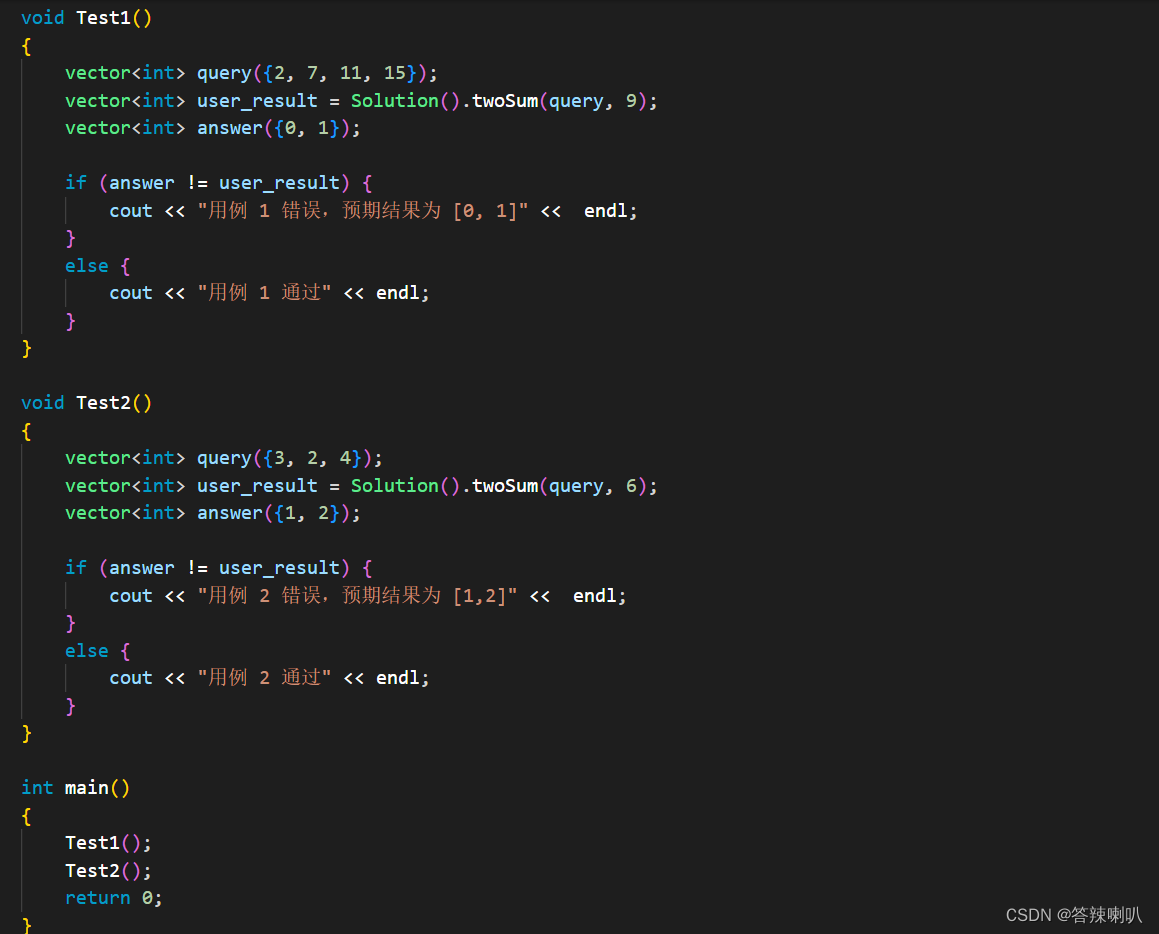 所以最终的逻辑结构大致如下
所以最终的逻辑结构大致如下
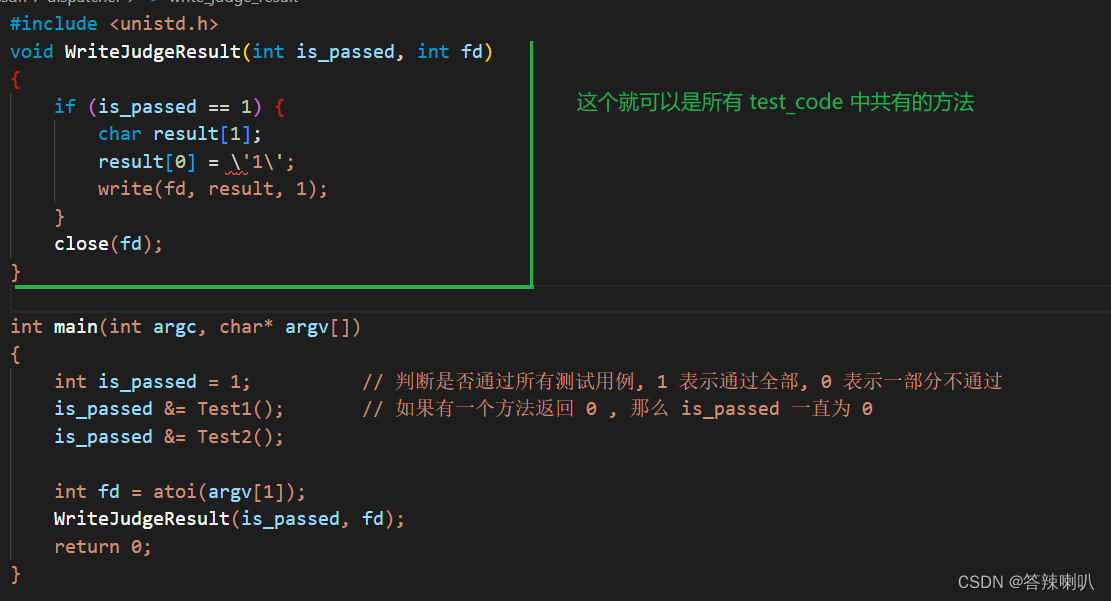
 但是后续有个功能是需要记录用户的题目回答情况。处理方法是这样的:
但是后续有个功能是需要记录用户的题目回答情况。处理方法是这样的:
- 程序替换的时候,传入一个参数
fd,这个fd就是记录该程序运行结果的文件对应的fd - 最终程序即将运行完成的时候,将程序的运行结果写入到这个文件里面
- 后续主进程就可以去这个文件里面读数据,从而得到这个程序的运行情况,比如 100 个用例,用过了多少个,是否通过了所有的测试用例…
- 本文只记录是否通过所有的测试用例,所以只需要定义一个
passed = 1,然后规定所有的测试用例方法返回值为int,如果通过一个测试用例,那么返回 1,否则返回 0,然后让passed &= test(1 - n)(),如果其中一个不通过,那么passed最终就为 0 - 然后如果
passed = 1,那么就往文件中写入1,否则不写
那么这样的话,所有的 test_code 就有一个公共的代码段,可以将其读取出来。并且需要注意,这部分代码需要写入数据库中,所以相关的单引号和双引号需要注意格式
11. 建表
然后在数据库中建立 [ 题库 ] 表,在这之前,因为远程登录的用户可能需要对表进行一系列操作,所以这里需要为他们授权
1. use mysql;
2. select User, Host from user;
3. create user oj_client@'%' identified by '123456'
4. create database oj_blog
5. grant all on oj_blog.* to oj_client@'%'
6. grant all on oj_blog.* to oj_client@'localhost'
然后按照上面的要求建表
use oj_blog
CREATE TABLE IF NOT EXISTS questions (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(256) NOT NULL,
difficulty VARCHAR(30) NOT NULL,
`desc` TEXT NOT NULL,
pre_code TEXT NOT NULL,
test_code TEXT NOT NULL,
cpu_limit INT DEFAULT 1,
memory_limit INT DEFAULT 50000
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
建完表之后,再插入一条数据方便测试
insert questions (title, difficulty, `desc`, pre_code, test_code) values
("两数之和", "简单",
'给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]',
'
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <unordered_map>
#include <algorithm>
using namespace std;
class Solution
{
public:
vector<int> twoSum(vector<int>& nums, int target) {
}
};',
'int Test1()
{
vector<int> query({2, 7, 11, 15});
vector<int> user_result = Solution().twoSum(query, 9);
vector<int> answer({0, 1});
if (answer != user_result) {
cout << "用例 1 错误,预期结果为 [0, 1]" << endl;
return 0;
}
else {
cout << "用例 1 通过" << endl;
return 1;
}
}
int Test2()
{
vector<int> query({3, 2, 4});
vector<int> user_result = Solution().twoSum(query, 6);
vector<int> answer({1, 2});
if (answer != user_result) {
cout << "用例 2 错误,预期结果为 [1,2]" << endl;
return 0;
}
else {
cout << "用例 2 通过" << endl;
return 1;
}
}
#include <unistd.h>
void WriteJudgeResult(int is_passed, int fd)
{
if (is_passed == 1) {
char result[1];
result[0] = \'1\';
write(fd, result, 1);
}
close(fd);
}
int main(int argc, char* argv[])
{
int is_passed = 1; // 判断是否通过所有测试用例, 1 表示通过全部, 0 表示一部分不通过
is_passed &= Test1(); // 如果有一个方法返回 0 , 那么 is_passed 一直为 0
is_passed &= Test2();
int fd = atoi(argv[1]);
WriteJudgeResult(is_passed, fd);
return 0;
}');
12. 连接数据库
有了 questions 表之后,我们就可以直接查询这个表中的所有内容,来构建题库了,在这之前,需要先连接数据库,并且编写查询数据库的相关接口
创建一个 model 类,来专门负责对数据库进行操作
12.1 MySQL 库
而数据库,这里用的库的下载链接是:MySQL
安装过程
- 可以直接下载到 Windows 中,然后将压缩包直接拖到 Linux 机器上
- 然后在自己的项目目录里面建立这个 玩意 的头文件和库的软链接,具体可以参考下面这个:(需要根据自己的实际文件目录修改)
ln -s ~/third-party/mysql-connector-c-6.1.11-linux-glibc2.12-x86_64/include include
ln -s ~/third-party/mysql-connector-c-6.1.11-linux-glibc2.12-x86_64/lib lib
12.2 查询操作
创建一个 Model 类,来专门实现对 MySQL 的访问,并且可以设计成单例模式
- 首先实现第一个接口
visitMySQL(sql, result)然后利用 库 里面的接口,完成一个查询操作,这里查询特指的是select *的,就是需要获取一行的所有属性 - 并且这个函数可以设计成函数模板,类型 T,只要求对应的对象提供一个
getObjectByRow函数就好了(根据一行构建对象)
template<class T> // vect_out 输出型参数
bool visitMySQL(const string& sql, vector<T> *vect_out)
{
LOG(INFO) << "执行 SQL 语句: " << sql << endl;
// 开始执行 MySQL 的语句
if (mysql_query(mysql, sql.c_str()) != 0) {
LOG(WANING) << sql << " 执行失败 | " << endl;
return false;
}
// 提取结果, 这里是指针, 后面需要被释放
MYSQL_RES* result = mysql_store_result(mysql);
// 分析结果, 获取行数
int rows = mysql_num_rows(result);
int cols = mysql_num_fields(result); // 获取列数
for (int i = 0; i < rows; i ++) {
MYSQL_ROW row_result = mysql_fetch_row(result); // 获取一行
T t;
t.getObjectByRow(row_result); // 根据 row_result 这一行来构建这个对象
vect_out->push_back(t); // 然后放进结果数组里面
}
free(result); // 释放结果空间
return true;
}
- 然后因为要从数据库中查出所有的题目,所以创建一个实体类
Question,里面的数据成员和数据库中的定义一样,然后提供getObjectByRow接口
struct Question
{
string id; // 编号
string title; // 题目标题
string difficulty; // 难度, 简单,中等,困难
string desc; // 题目的描述
string pre_code; // 预代码
string test_code; // 测试用例, 需要和 pre_code 进行拼接
int cpu_limit; // 时间要求
int memory_limit; // 题目的空间要求(单位KB)
void getObjectByRow(const MYSQL_ROW& row_result) {
id = row_result[0];
title = row_result[1];
difficulty = row_result[2];
desc = row_result[3];
pre_code = row_result[4];
test_code = row_result[5];
cpu_limit = atoi(row_result[6]);
memory_limit = atoi(row_result[7]);
}
};
- 接着就可以很简单地实现获取题库所有题目的接口:
bool getAllQuestions(vector<Question>* vect_out)
{
string sql = "select * from ";
sql += mysql_questions_table;
return visitMySQL(sql, vect_out);
}
- 并且将
Model设计成单例模式,全代码如下
const string mysql_questions_table = "questions"; // 题库表的名字
const string mysql_database = "oj_blog"; // 要操作的 database 名字
const string host = "127.0.0.1"; // 连的机器
const string user = "oj_client"; // 身份
const string pwd = "password"; // 相应的密码
const int port = 3306;
// 需要改造成单例模式
class Model
{
private:
static Model* model;
static mutex mtx;
MYSQL* mysql;
public:
static Model* GetInstance()
{
if (model == nullptr) {
std::lock_guard<mutex> guard(mtx);
if (model == nullptr) {
return model = new Model();
}
}
return model;
}
template<class T>
bool visitMySQL(const string& sql, vector<T> *vect_out)
{
LOG(INFO) << "执行 SQL 语句: " << sql << endl;
// 开始执行 MySQL 的语句
if (mysql_query(mysql, sql.c_str()) != 0) {
LOG(WANING) << sql << " 执行失败 | " << endl;
return false;
}
// 提取结果, 这里是指针, 后面需要被释放
MYSQL_RES* result = mysql_store_result(mysql);
// 分析结果, 获取行数
int rows = mysql_num_rows(result);
int cols = mysql_num_fields(result); // 获取列数
for (int i = 0; i < rows; i ++) {
MYSQL_ROW row_result = mysql_fetch_row(result); // 获取一行
T t;
t.getObjectByRow(row_result);
vect_out->push_back(t);
}
free(result); // 释放结果空间
return true;
}
bool getAllQuestions(vector<Question>* vect_out)
{
string sql = "select * from ";
sql += mysql_questions_table;
return visitMySQL(sql, vect_out);
}
private:
Model()
{
// 创建 mysql 句柄
mysql = mysql_init(nullptr);
if (nullptr == mysql_real_connect(mysql, host.c_str(), user.c_str(),
pwd.c_str(), mysql_database.c_str(), port, nullptr, 0)) {
LOG(FATAL) << "连接数据库失败" << endl;
return ;
}
LOG(INFO) << "连接数据库成功" << endl;
// 设置编码集
mysql_set_character_set(mysql, "utf8");
}
Model(const Model&) = delete;
Model& operator=(const Model&) = delete;
~Model()
{
// 关闭 mysql 连接
mysql_close(mysql);
}
};
Model* Model::model = nullptr;
mutex Model::mtx;
13. 题目页面
- 创建一个
controller类来负责处理所有的业务,当然controller也需要model*成员来方便操作数据库 - 除此之外,还需要
view模块,来将controller处理完成的业务数据转化成前端的页面
13.1 ctemplate
想要对页面进行动态地渲染的话,这里使用的库是 ctemplate
安装 ctemplate
1. git clone https://hub.fastgit.xyz/OlafvdSpek/ctemplate.git
2. ./autogen.sh
3. ./configure
4. make
编译
5. make install
安装到系统中
如果出现了问题:顺利安装,编译也能通过,但是运行的时候报错,错误是找不到共享库的位置
那么需要找到安装的 ctemplate 里面库,cd 到库文件夹 ctemplate/.libs 中,然后执行
cp * /lib64
cp * /usr/lib64
ldconfig
然后是相关的接口使用:
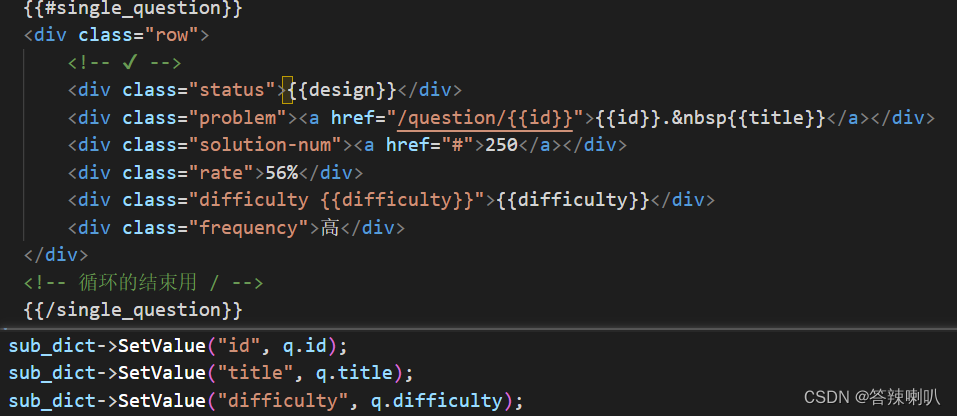
ctemplate::TemplateDictionary* sub_dict = dict.AddSectionDictionary("single_question");创建一个数据字典,可以通过dict.SetValue()接口来构建HTML页面和想要渲染的数据的映射关系,比如下面这图- 然后生成 HTML 页面
ctemplate::Template *tpl = ctemplate::Template::GetTemplate(src_html, ctemplate::DO_NOT_STRIP);这里的src_html就是需要别动态渲染的 HTML 文件路径 - 最后传入 输出型参数,以及字典地址,就可以完成页面的渲染了
tpl->Expand(out_html, &dict);
13.2 前端题库页面
然后统一:将需要动态渲染的页面放在一个统一的文件夹中,这里定为 temphtml 即渲染
然后首先制作一个基础的前端题库页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css">
<title>OJ 题库</title>
<style>
* {
margin: 0px;
padding: 0px;
}
/* 将导航栏和游览器周围取消贴合 */
body {
width: 100%;
height: 100%;
background-color: #232425;
}
/* 不要紧紧挨在一起 */
.header {
top: 0;
left: 0;
right: 0;
z-index: 9999;
}
.header {
/* 设置导航栏的背景颜色 */
background-color: #2f3233;
/* 文本颜色 */
color: #fff;
/* 设置内边距 */
padding: 20px;
}
nav ul {
/* 导航栏使用横向排列 */
list-style-type: none;
margin: 0;
padding: 0;
display: flex;
}
nav ul .left {
/* 导航栏链接之间的右边距 */
margin-right: 20px;
}
nav ul .left {
/* 导航栏链接之间的右边距 */
margin-right: 30px;
}
nav ul li a {
color: #fff;
font-size: 2.0ch;
/* 去除下划线 */
text-decoration: none;
}
nav ul li a:hover {
/* 鼠标悬停的时候, 链接下面有下划线效果 */
text-decoration: underline;
}
/* 题库 */
/* 开始制作题单 */
.leetcode {
display: flex;
background-color: #232425;
flex-direction: column;
align-items: center;
font-family: Arial, sans-serif;
}
.title {
font-size: 28px;
color: #ccc;
font-weight: bold;
margin-bottom: 8px;
padding-top: 20px;
}
.table {
display: flex;
flex-direction: column;
width: 100%;
}
.row {
display: flex;
align-items: center;
padding: 10px;
border-bottom: 1px solid #ddd;
}
.row:last-child {
border-bottom: none;
}
.status {
margin-right: 10px;
width: 50px;
}
.problem {
width: 100px;
flex-grow: 1;
margin-right: 10px;
}
.problem a {
text-decoration: none;
color: white;
transition: 0.3s;
}
.problem a:hover {
color: cyan;
}
.solution-num {
margin-right: 10px;
width: 50px;
}
.solution-num a {
margin-right: 10px;
color: white;
text-decoration: none;
}
.difficulty {
padding: 5px 10px;
border-radius: 4px;
margin-left: 40px;
}
.简单 {
color: #61ffff;
}
.中等 {
color: #ffea3e;
}
.困难 {
color: #d35580;
}
.rate {
margin-right: 10px;
color: white;
width: 50px;
margin-left: 40px;
}
.frequency {
margin-left: 40px;
width: 60px;
color: white;
font-style: italic;
}
.footer {
position: fixed;
bottom: 7px;
width: 100%;
text-align: center;
background-color: #232425;
background: linear-gradient(to right, #00f, #00ffff);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
font-size: 2.1vh;
}
</style>
</head>
<body>
<div class="header">
<!-- 设置导航部分 ------------------------------------------------------------------------------------- -->
<nav>
<ul>
<!-- / 就是跳转到默认的地方 -->
<li class="left"><i class="fas fa-graduation-cap"></i><a href="/" style="margin-left: 15px;">首页</a></li>
<li class="left"><a href="/list" style="color: yellow;">题库</a></li>
<li class="left"><a href="#">竞赛</a></li>
<li class="left"><a href="#">讨论</a></li>
<li class="left"><a href="#">求职</a></li>
<li class="left"><a href="../entry.html" style="color: yellow;">{{entry_question}}</a></li>
<li class="login" style="margin-left: auto;"><a href="login_and_reg.html">{{welcome}}</a></li>
</ul>
</nav>
<!-- 导航栏结束 --------------------------------------------------------------------------------------- -->
</div>
<!-- 题库开始 -->
<div class="main">
<!-- 左边内容 -->
<div class="main-left">
<!-- 设置题库开始 ----------------------------------------------------------------------------------------- -->
<div class="leetcode">
<div class="title">题库</div>
<div class="table">
<!-- 标题 -->
<div class="row">
<div llass="status" style="color: white; width: 50px; margin-right: 10px;">️状态</div>
<div class="problem"><a href="#">题目</a></div>
<div class="solution-num"><a href="#">题解</a></div>
<div class="rate">通过率</div>
<div class="difficulty" style="color: white;">难度</div>
<div class="frequency">频率</div>
</div>
<!-- 主体 -->
<!-- 循环的开始用 # -->
{{#single_question}}
<div class="row">
<!-- ✔ -->
<div class="status">️{{design}}</div>
<div class="problem"><a href="/question/{{id}}">{{id}}. {{title}}</a></div>
<div class="solution-num"><a href="#">250</a></div>
<div class="rate">56%</div>
<div class="difficulty {{difficulty}}">{{difficulty}}</div>
<div class="frequency">高</div>
</div>
<!-- 循环的结束用 / -->
{{/single_question}}
</div>
</div>
<!-- 设置题库结束 ----------------------------------------------------------------------------------------- -->
<div class="footer">
<h4>@CSDN: https://blog.csdn.net/weixin_63519461</h4>
</div>
</div>
</body>
</html>
然后是 view 中渲染题库的代码
// 渲染所有题目的 html 页面
void renderAllQuestions(vector<Question>& all, string* out_html)
{
// 形成路径
string src_html = temphtml_path + "all_questions.html";
// 数据字典
ctemplate::TemplateDictionary dict ("all_questions"); // 起个名
for (const Question& q : all) {
// 这个 single_question 和 html 页面里面的 每一个循环中的名字有关系
ctemplate::TemplateDictionary* sub_dict = dict.AddSectionDictionary("single_question");
sub_dict->SetValue("id", q.id);
sub_dict->SetValue("title", q.title);
sub_dict->SetValue("difficulty", q.difficulty);
}
// 3. 生成 html 页面
ctemplate::Template *tpl = ctemplate::Template::GetTemplate(src_html, ctemplate::DO_NOT_STRIP);
// 4. 完成最终渲染
tpl->Expand(out_html, &dict);
}
然后 controller 就可以调用渲染的函数了
class Controller
{
private:
Model* model;
View view;
public:
Controller()
: model(Model::GetInstance())
{}
// 根据题目数据构建网页, html 是一个输出型参数
bool getAllQuestions(string* html)
{
bool ret = true;
vector<Question> all;
if (model->getAllQuestions(&all)) { // 获取题库中所有题目的数据, 存放在 vector all 中
sort(all.begin(), all.end(), [](const Question x, const Question y) {
return atoi(x.id.c_str()) < atoi(y.id.c_str());
});
// 将所有的题目数据 来 构建 html 页面
view.renderAllQuestions(all, html);
}
else {
*html = "获取题目列表失败";
ret = false;
}
return ret;
}
};
13.3 接收请求
然后就可以在 ojserver 里面利用 httplib 创建一个服务器了,然后注册路由,当有请求发送的时候,就会调用 controller.getAllQuestions() ,然后将渲染好的前端页面直接返回给前端
int main()
{
Controller ctrl;
// 用户请求的服务路由功能
Server server;
// 获取题目页面
server.Get("/list", [&ctrl](const Request& req, Response& resp) {
// 返回所有题目的 html 网页
string html;
ctrl.getAllQuestions(&html);
// 直接以 html 的数据格式返回
resp.set_content(html, "text/html; charset=utf-8");
});
// 设置基础目录
server.set_base_dir("./web");
server.listen("0.0.0.0", 44444);
LOG(FATAL) << "服务器终止" << endl;
return 0;
}
然后编译程序,运行之后,访问,就可以看到对应题库页面了

14. 单个题目
题库和单个题库的编写页思路是大致一样的,只不过单个题目的编写需要用到在线的编辑器,ACE 编辑器
- 首先在 Model 类中编写第二个接口,根据
question_id获得题目的具体对象
bool getQuestionById(const string& id, Question* ques_out)
{
string sql = "select * from " + mysql_questions_table + " ";
sql += "where id = ";
sql += id;
vector<Question> result;
if (visitMySQL(sql, &result)) {
if (result.size() == 1) {
*ques_out = result[0];
return true;
}
}
return false;
}
- 编写
view模块中渲染单个页面的代码,out_html 是输出型参数,是渲染完的 HTML 页面字符串
// 渲染 单个题目 的 html 页面
void renderSingleQuestion(const Question& q, string* out_html)
{
string src_html = temphtml_path + "single_question.html";
ctemplate::TemplateDictionary dict("single_question");
dict.SetValue("id", q.id);
dict.SetValue("title", q.title);
dict.SetValue("difficulty", q.difficulty);
// 换行的问题可以交给 <pre> 标签, 它可以最大限度地保留文本的原貌
dict.SetValue("desc", q.desc); // 实现换行效果
dict.SetValue("pre_code", q.pre_code);
// 生成 html 页面(可能并未完成渲染,我的理解), 这里的 src_html 是一个路径
// 这里估计就是完成一些字符串替换的工作,真正 Expand 才是返回真正的 html 页面
ctemplate::Template* tpl = ctemplate::Template::GetTemplate(src_html, ctemplate::DO_NOT_STRIP);
// 开始渲染, 最终的结果放在 html 里面
tpl->Expand(out_html, &dict);
}
- 然后是
controller:
bool getQuestionById(const string& id, string* html)
{
bool ret = true;
Question q;
if (model->getQuestionById(id, &q)) { // 获取单个题目的具体信息
view.renderSingleQuestion(q, html);
}
else {
*html = "获取指定题目 " + q.id + " 题目失败";
ret = false;
}
return ret;
}
- 接着是
ojserver.cpp中给服务器注册一项服务
这里需要规定:在访问具体某一个题目的时候,url中要带上题号,下面的/question/(\d+)后边的 d 表示匹配任意数字,并且可以通过req中的matches数组获取这个参数
server.Get(R"(/question/(\d+))", [&ctrl](const Request& req, Response& resp) {
string question_id = req.matches[1];
string html;
ctrl.getQuestionById(question_id, &html);
resp.set_content(html, "text/html; charset=utf-8");
});
- 然后编译,执行,访问一下这个服务试试效果;
15. 负载均衡
在上面的 single_question 页面中,当用户提交代码的时候,首先应该由 ojserver 服务器接收到这个请求,然后再由 ojserver 判断所有的 compiler 负载最小的机器,再进行后续操作
15.1 Machine
想要管理这些 compiler 服务器,就需要对他们抽象起来进行管理,所以可以使用 Machine 类管理,为了知道该服务器的负载情况,添加一个字段 load 表示现在正在处理的请求数量就好了,并且对外提供操作 load 的函数,并且可能同一时间会有多个请求,所以 load 需要加锁保护
struct Machine
{
string ip; // 该负载机器的 ip
int port; // 该负载机器的 port
uint64_t load; // 该编译服务器的负载, 将来可能会有很多请求到这个机器上, 所以需要及时为这个 load 做更新
mutex* mtx;
Machine()
: ip("")
, port(-1)
, load(-1)
, mtx(nullptr)
{
}
void loadIncrease() // 负载增加
{
if (mtx != nullptr) mtx->lock();
++ load;
if (mtx != nullptr) mtx->unlock();
}
void loadDecrease() // 负载减少
{
if (mtx != nullptr) mtx->lock();
-- load;
if (mtx != nullptr) mtx->unlock();
}
uint64_t getLoad() // 获取当前机器的负载情况
{
uint64_t result = 0;
if (mtx != nullptr) mtx->lock();
result = load;
if (mtx != nullptr) mtx->unlock();
return result;
}
void resetLoad() // 将负载情况归 0
{
if (mtx != nullptr) mtx->lock();
load = 0;
if (mtx != nullptr) mtx->unlock();
}
};
15.2 LoadBalancer
这个类负责从所有的 compiler 中选择一个负载最小的,所以需要对这些 Machine 进行管理
- 该类在初始化的时候,就需要获取所有
compiler的信息,关于这些 机器 的信息,可以写在文件里,然后在构造函数中读取出来并添加到容器中管理,并且默认这些机器具有能力接收请求
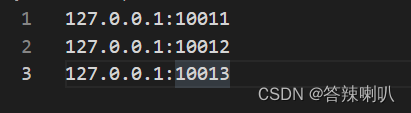
- 用三个容器管理这些
Machine,第一个all_machines数组,下标表示这个Machine的 ID,内容表示这个Machine的相关属性;第二个online数组,存储所有正在工作或者等待接收工作的Machine下标,这个下标就是在all_machine里面的下标;第三个offline,存储所有下线 / 崩溃导致异常 的机器下标 - 还需要提供让主机重新上线,或者下线的能力
- 最重要的还是,选择负载最小的主机,并返回这个机器的相关信息,同样,选择合适的机器的时候需要加锁保护
class LoadBalancer
{
private:
// 所有 Machines, 每一台主机都有自己的下标, 每个主机都有自己主机的 ID
vector<Machine> all_machines;
// 所有在线主机的 ID
vector<int> online;
// 所有离线主机的 ID
vector<int> offline;
// 保证负载均衡的时候的数据安全
mutex mtx;
public:
LoadBalancer()
{
if (loadConf(servers_conf_path) == false) {
LOG(ERROR) << "加载负载服务器失败" << endl;
}
else {
LOG(INFO) << "加载 " << servers_conf_path << " 配置文件成功" << endl;
}
}
// 加载配置文件, 将配置文件里面机器的数据都读取出来
bool loadConf(const string& conf_path)
{
string conf_content; // 配置文件里面的内容
FileUtil::ReadFromFile(conf_path, &conf_content, true);
conf_content.pop_back(); // 会多出一个空格
vector<string> lines; // 切分每一行
StringUtil::Split(conf_content, &lines, "\n");
// 切分每一个 ip 和端口号
for (int i = 0; i < lines.size(); i ++) {
// 单独处理每一行 ip:port
vector<string> line;
// 拆分字符串,以 ":" 为分隔符
StringUtil::Split(lines[i], &line, ":");
if (line.size() != 2) {
LOG(WARNING) << "配置文件异常,切分数据失败" << endl;
continue;
}
Machine m;
m.ip = line[0];
m.port = atoi(line[1].c_str());
m.load = 0;
m.mtx = new mutex();
all_machines.push_back(m);
// 这个机器启动之后, 默认是在线的, 并且存储的是主机在 all_machines 里面的下标
online.push_back(all_machines.size() - 1);
}
return true;
}
// id 输出型参数
// machine 也是输出型参数
bool choose(int* id, Machine** out_mac)
{
// 选择合适的主机, 并且更新负载
// 后续可能需要离线主机
// 负载均衡选择主机的时候需要加锁
mtx.lock();
// 负载均衡的算法
// 1. 随机数 + hash
// 2. 轮询 + hash
int online_count = online.size();
if (online_count == 0) {
mtx.unlock();
LOG(FATAL) << "可用负载服务器为 0" << endl;
return false;
}
// 通过遍历的方式找到所有负载最小的机器
uint64_t min_load = all_machines[online[0]].getLoad();
*id = online[0];
*out_mac = &all_machines[online[0]];
for (int i = 1; i < online_count; i ++) {
uint64_t cur_load = all_machines[online[i]].getLoad();
if (min_load > cur_load) {
min_load = cur_load;
*id = online[i];
*out_mac = &all_machines[online[i]];
}
}
mtx.unlock();
return true;
}
// 让所有主机上线
bool enable()
{
mtx.lock();
// 将 offline 所有内容插入到 offlilne 里面
online.insert(online.end(), offline.begin(), offline.end());
offline.erase(offline.begin(), offline.end());
mtx.unlock();
LOG(INFO) << "上线所有主机" << endl;
return true;
}
// 让一台主机下线
bool disable(int which)
{
mtx.lock();
for (vector<int>::iterator it = online.begin(); it != online.end(); it ++) {
if (*it == which) { // 找到了需要离线的主机
all_machines[which].resetLoad(); // 负载清 0
online.erase(it);
offline.emplace_back(which);
break; // 直接 break , 不用考虑 迭代器失效的问题
}
else {
}
}
mtx.unlock();
return true;
}
~LoadBalancer()
{}
};
15. 运行用户代码
用户在编写完代码之后需要将代码交给服务器判题,用户在提交的时候提交的只是 Solution() 那部分代码,也就是 pre_code,所以最终判题的时候,需要将用户的 pre_code 和 数据库中的 test_code 进行拼接之后才能运行
- 首先注册一下判题服务,并且 ctrl 里面需要提供一个
judge判题函数,并且请求中含有的参数有:question_id, 用户代码
server.Post(R"(/judge/(\d+))", [&ctrl](const Request& req, Response& resp) {
string result_json ;
string question_id = req.matches[1];
ctrl.judge(question_id, req.body, &result_json);
resp.set_content(result_json, "application/json; charset=utf-8");
});
- 在
ctrl.judge函数中,将请求中的数据序列化,然后得到question_id和pre_code。然后将question_id去查表,来获取这个question的具体数据,于是就可以在model中再补充一个函数
bool getQuestionById(const string& id, Question* ques_out)
{
string sql = "select * from " + mysql_questions_table + " ";
sql += "where id = ";
sql += id;
vector<Question> result;
if (visitMySQL(sql, &result)) {
if (result.size() == 1) {
*ques_out = result[0];
return true;
}
}
return false;
}
- 接着,根据该
question的具体数据以及用户的pre_code代码,重新组装一个请求,再让选择器选择一个负载最低的机器,并发送,如果该请求失败,那么就重新选择机器再发送。如果请求成功,那么就将响应原样交付给前端处理
bool judge(const string& id, const string in_json, string* out_json)
{
// if (session == nullptr) return false;
// cout << "题目 id = " << id << endl;
// cout << "user_id = " << to_string(session->user_info.id) << endl;
Question q;
model->getQuestionById(id, &q);
Json::Reader reader;
Json::Value in_root;
reader.parse(in_json, in_root);
string code = in_root["code"].asString();
// 重新拼接要编译的代码, 因为需要发送给远端服务器进行编译和运行, 所以也需要是 json 格式的字符串
Json::Value send_root; // 还需要发送给远端
send_root["input"] = in_root["input"].asString();
send_root["code"] = code + "\n" + q.test_code;
send_root["cpu_limit"] = q.cpu_limit;
send_root["memory_limit"] = q.memory_limit;
// 生成一个 时间戳 + uuid 来定制当次的判题结果
send_root["question_id"] = atoi(id.c_str());
// send_root["user_id"] = session->user_info.id;
// 完成发送给负载服务器的 json 字符串
Json::StyledWriter writer;
string send_str = writer.write(send_root);
LOG(INFO) << "收到一个判题请求" << ", 开始选择编译服务器" << endl;
// 选择负载服务器进行发送
while (true) {
int id = 0;
Machine* mac = nullptr;
if (balancer.choose(&id, &mac) == false) {
break;
}
// 发送 http 请求
Client cli(mac->ip, mac->port);
mac->loadIncrease(); // 发送了请求, 负载增加
LOG(INFO) << "选择主机成功, 主机 id = " << id << " | ip: " << mac->ip << " | port: " << mac->port <<
" | 当前主机的负载是 " << mac->getLoad() << endl;
// 向这个负载服务器发送 post 请求
// 这个 result 其实就是一个智能指针, 里面装的是一个 Response
if (auto result = cli.Post("/execute", send_str, "application/json; charset=utf-8")) {
if (result->status == 200) {
LOG(INFO) << "成功将请求发送给负载服务器, 完成编译和运行工作" << endl;
*out_json = result->body; // 将这个请求的结果放到 out_json 中
mac->loadDecrease(); // 请求完成, 负载减少
break; // 请求成功, 就不需要再找其他机器了
}
// 如果状态码不是 200 , 那么就重新选择主机
mac->loadDecrease();
}
else {
// 请求失败
LOG(ERROR) << "当前请求主机离线, id: " << id << " | ip: " << mac->ip << " | port: " << mac->port << endl;
balancer.disable(id); // 让它离线
}
}
return true;
}
不过到这里之后,还是有点小问题,这里后边再解决(可能会出现段错误)
16. 密码密文存储
由于文章篇幅有限,登录和注册功能无非就是往用户表中进行操作,但是用户的密码直接明文存在 MySQL 厘米不安全,所以推荐使用密文存储,而密文存储的思路在我的这篇文章里面有讲到 Blog,实现思路都是一样的
这里分享一个本项目使用的 md5 代码:github – md5
17. 实现会话
接着就是会话的实现,首先处理一下会话的相关数据结构
- 首先管理会话的类
SessionMgr设计成到单例模式,并且里面存一个哈希表,Key 是 SessionId,Value 是 HttpSession
然后除了存储用户的直接个人数据之外,还需要存储一些会话相关的信息
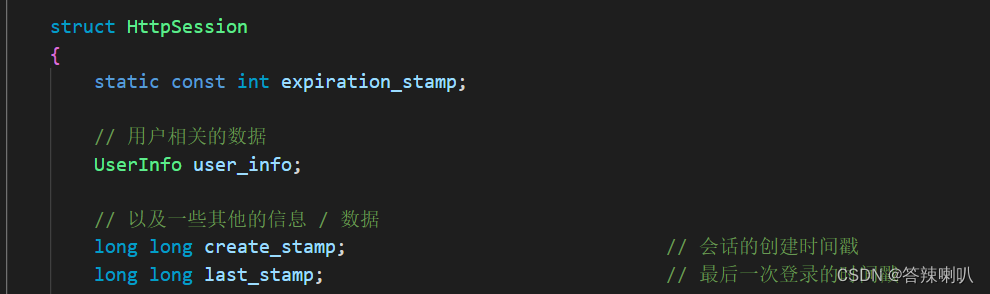
create_stamp是用户不存在会话且第一次登录的时间,而last_stamp是用户在会话有效期内,最后一次登录的时间- 用户每次登录,都需要更新
last_stamp(如果没过期的话)
void update()
{
last_stamp = TimeUtil::CurrentTimeStamp();
}
static long long CurrentTimeStamp()
{
auto now = std::chrono::system_clock::now();
auto timestamp = std::chrono::time_point_cast<std::chrono::milliseconds>(now);
return timestamp.time_since_epoch().count();
}
- 然后 HttpSession 再提供一个判断过期的方法,其实就是
last_stamp+ 过期的时间间隔对应的时间戳如果 < 当前时间戳,那么判定为过期
bool isExpired()
{
// 1. 获取最晚登陆时间的 3 天后的时间戳
long long expired_stamp = last_stamp + expiration_stamp;
// 2. 获取当前的时间戳
long long cur_stamp = TimeUtil::CurrentTimeStamp();
return expired_stamp < cur_stamp;
}
- 然后管理这个会话的类
SessionMgr需要提供一系列操作会话的函数,比如
1、根据 SessionId 判断会话是否存在,如果存在,那么返回对应的 HttpSession
2、如果用户是最近第一次登录,那么需要为用户分配一个全局唯一的 SessionID
3、游览器发送的 SessionId 可能存在多个,所以需要逐个匹配到存在会话记录的用户
4、会话是会过期的,还要定义一个扫描函数,将过期的会话移除
5、Controller 在启动的时候,需要一个线程一起启动,每隔一段时间调用一次 扫描 函数
所以最终 SessionMgr 类的编写如下
// 默认在 3 天之后, 这个会话会过期, 测试中使用 10 min
const int HttpSession::expiration_stamp = 10 * 60 * 1000;
// 设计成单例模式?
class SessionMgr
{
private:
static SessionMgr* session_mgr; // 单例模式中的对象
static std::mutex mtx; // 互斥锁
static std::mutex session_lock; // 用来保护 session 哈希表的线程安全
static boost::uuids::random_generator generator; // 用来生成随机的 session_id
unordered_map<string, HttpSession*> session_mapper; // 用来管理 session 的哈希表
public:
static SessionMgr* GetInstance()
{
if (session_mgr == nullptr) {
{ // 定义作用域 来 限定这个智能锁
std::lock_guard<std::mutex> guard(mtx);
if (session_mgr == nullptr) {
return session_mgr = new SessionMgr();
}
}
}
return session_mgr;
}
// 根据 session_id 来匹配对应的 HttpSession
// 返回相应的指针
HttpSession* find(const string& session_id)
{
std::lock_guard<std::mutex> guard(session_lock); // 对哈希表加锁
unordered_map<string, HttpSession*>::iterator it = session_mapper.find(session_id);
if (it == session_mapper.end()) {
return nullptr;
}
return it->second;
}
// 分配一个新的 HttpSession, 参数是 用户名
// 如果已经存在有 session_id, 那么就更新 last_stamp
string generate(int id, const string& username, int grade)
{
// 生成一个随机的 session_id
boost::uuids::uuid uuid = generator();
string session_id = boost::uuids::to_string(uuid);
std::lock_guard<std::mutex> guard(session_lock); // 对哈希表加锁
session_mapper.emplace(session_id, new HttpSession(id, username, grade));
// 返回 为这个会话 分配的 session_id
LOG(INFO) << "分配了一个 session_id = " << session_id << endl;
return session_id;
}
// 如果用户在 3 天内登录了, 那么就继续更新
// 参数传入这个会话, 然后更新这个会话的 最晚登录时间
void update(HttpSession* http_session)
{
http_session->update();
}
// 扫描整个 session 表, 如果过期, 就删除
void scan()
{
std::lock_guard<std::mutex> guard(session_lock);
for (unordered_map<string, HttpSession*>::iterator it = session_mapper.begin(); it != session_mapper.end(); ) {
auto temp = it; // 保存一下 迭代器 的位置, 防止迭代器失效
it ++;
// 如果过期了, 那么直接将会话里面数据删除
if (temp->second->isExpired()) {
delete temp->second; // 释放这个 HttpSession* 的空间
session_mapper.erase(temp);
}
}
}
// ids 表示 session_id 的集合
// 用来判断 这些 session_id 中有没有匹配的 会话, 存在匹配的会话就返回这个用户的会话信息
string getLoginUser(const vector<string>& ids, HttpSession** out)
{
for (const string& id : ids) {
HttpSession* session = find(id);
// 存在会话, 如果存在会话, 那就更新一下
if (session != nullptr) {
session->update();
if (out != nullptr) {
*out = session;
return id;
}
}
}
return "";
}
private:
SessionMgr() {}
SessionMgr(const SessionMgr&) = delete; // 拷贝构造
SessionMgr& operator=(const SessionMgr&) = delete; // 赋值构造
~SessionMgr() {} // 析构函数
};
boost::uuids::random_generator SessionMgr::generator;
SessionMgr* SessionMgr::session_mgr = nullptr;
std::mutex SessionMgr::session_lock;
std::mutex SessionMgr::mtx;
// 负责每隔一段 时间扫描一下 所有的 Session, 如果有过期的, 就进行清理
void* Scanner(void* args)
{
// 线程分离, 不必等待父进程回收资源
pthread_detach(pthread_self());
LOG(INFO) << "自动回收过期 Session 线程启动" << endl;
while (true)
{
// 10 分钟就过一次
SessionMgr* session_mgr = SessionMgr::GetInstance(); // 获取这个对象
session_mgr->scan(); // 扫描并删除
sleep(60 * 10);
}
}
18. 拦截器
然后可以再实现一个简易版的拦截器,提供一个函数,专门负责从请求中获取 会话哈希表中存在的会话,并能得到对应的 SessionID 以及其匹配的会话 HttpSession。
需要注意的是游览器可能会发送多个会话,所以这里还需要将请求中 Cookie 中的会话都提取出来
class Interceptor
{
private:
static Interceptor* inter;
static SessionMgr* session_mgr;
static std::mutex mtx;
public:
static Interceptor* GetInstance()
{
if (inter == nullptr) {
std::lock_guard<std::mutex> guard(mtx);
if (inter == nullptr) {
session_mgr = SessionMgr::GetInstance(); // 会话管理对象(指针)
return inter = new Interceptor(); // 拦截器单例模式对象(指针)
}
}
return inter;
}
// 拦截请求, 验证登录状态
// 将会话中的 userinfo 提取出来, 如果存在会话, 那么返回用户信息, 并返回 session_id, 如果不存在返回, 那么返回 ""
string interceptRequest(const Request& req, HttpSession** out)
{
// 需要验证用户的登录状态, 从 Request header 中里面获取 session_id
static const string prefix = "session_id=";
string cookie = req.get_header_value("Cookie");
vector<string> session_ids;
size_t beg = 0;
while (beg != string::npos) {
string session_id;
// 查找下一个 session_id= 的位置
beg = cookie.find(prefix, beg);
if (beg == string::npos)
break;
beg += prefix.length();
// 查找分号的位置
size_t end = cookie.find(";", beg);
// 提取 session_id
if (end == string::npos)
session_id = cookie.substr(beg);
else
session_id = cookie.substr(beg, end - beg);
session_ids.emplace_back(session_id);
beg = end; // 将查找起始位置移动到分号后的位置继续查找下一个 session_id
LOG(INFO) << "用户发送的会话 Id = " << session_id << endl;
}
return session_mgr->getLoginUser(session_ids, out);
}
private:
Interceptor() {}
Interceptor(const Interceptor&) = delete;
Interceptor& operator=(const Interceptor&) = delete;
~Interceptor() {}
};
std::mutex Interceptor::mtx;
Interceptor* Interceptor::inter = nullptr;
SessionMgr* Interceptor::session_mgr = nullptr;
然后在用户每一个申请的服务中,都可以获取用户的会话,然后可以从会话中获取该用户的数据,从而实现自动登录功能。
补充一点,如果用户是第一次登录,那么需要为该用户创建一个新的会话,并分配一个 SessionID,然后再将这个 SessionID 放在 响应中的 Set-Cookie 字段中,这样游览器收到之后,下次访问该网站的资源的时候,就都会带上这个 SessionID 一起发送过来
所以登录函数里面还要传一个拦截器获取到的 会话



19. 记录用户答题情况
这个功能的实现,还需要依靠一个表 completed ,表示所有用户完成的题目,如下是表结构,以及建表语句
CREATE TABLE IF NOT EXISTS completed (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
question_id INT,
completed_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (question_id) REFERENCES questions(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
每一条记录:哪个用户,完成了,哪一个题
接着,想要实现这个功能,需要基于会话之上
- 上文已经实现了判题功能,并且在判完一个题目之后,如果通过,会往给定参数的
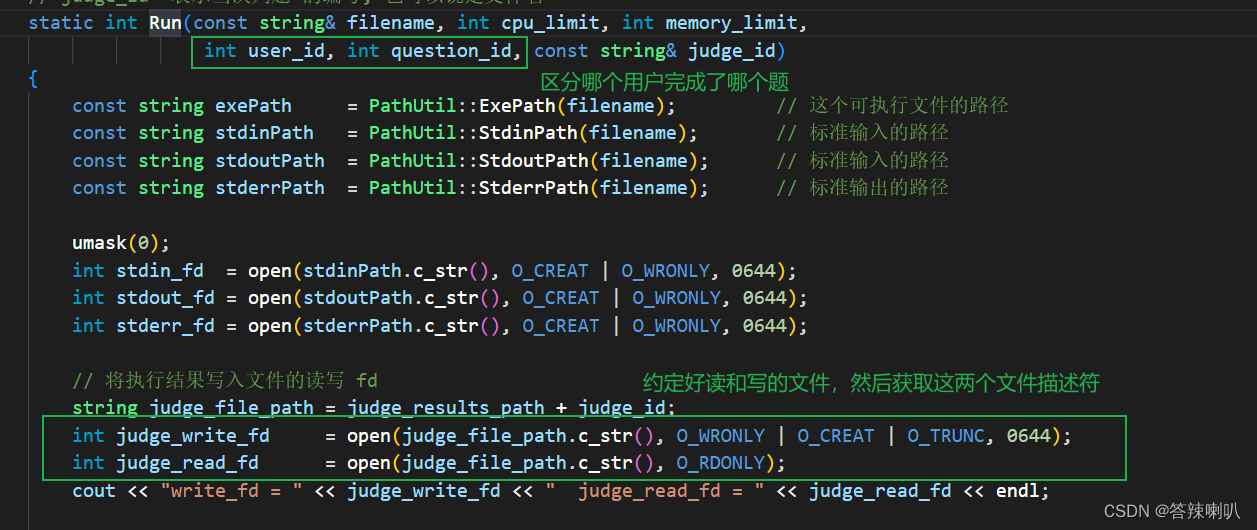
fd文件描述符中写入数据 - 所以主线程只要基于这个会话,就能知道这个题目的用户
id,以及题号,然后再分别以读,写方式打开两个文件描述符,write_fd给判题程序,read_fd给主线程自己用,然后主线程等待完判题程序之后,就可以往read_fd中读数据了 - 如果能读到数据,那么就认为这个用户完成了这个题
- 注意:
judge_id是我用来 约定读写文件的文件名,反正只是一个唯一的文件名就可以了,怎么搞的都行
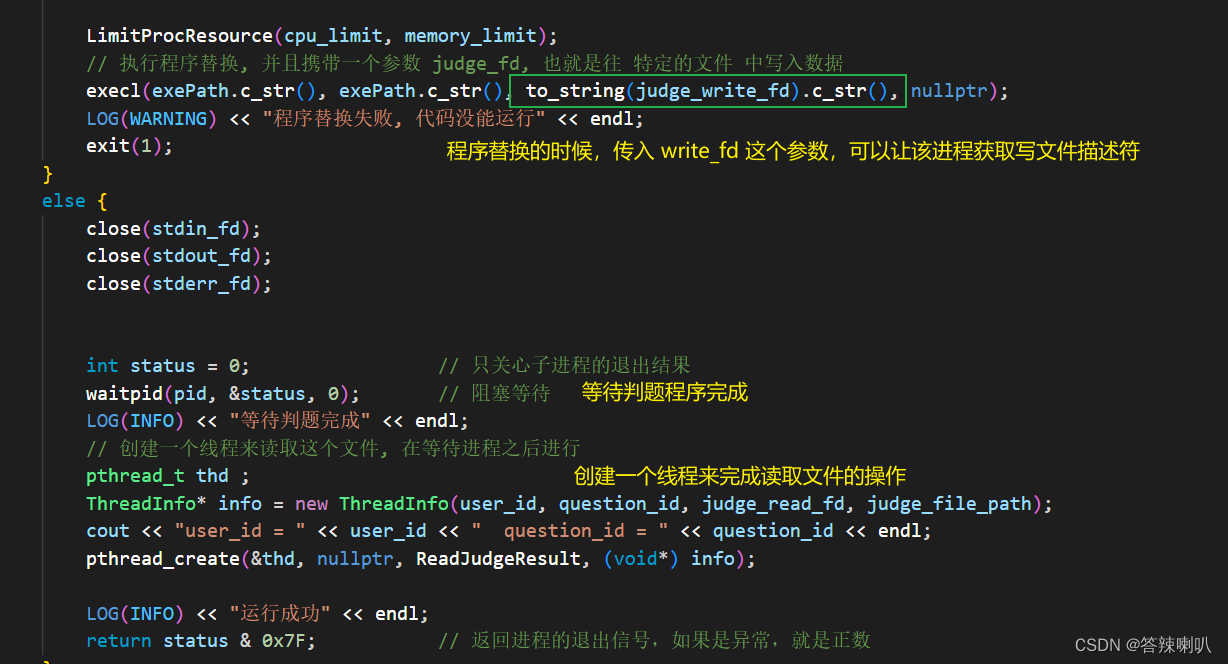 接着是这个读文件的线程对应的函数
接着是这个读文件的线程对应的函数
// 读取该判题结果
void* ReadJudgeResult(void* args)
{
pthread_detach(pthread_self());
LOG(INFO) << "启动线程读取结果" << endl;
ThreadInfo* info = (ThreadInfo*)args;
cout << "read_fd = " << info->judge_read_fd << endl;
char result[10];
int rd = read(info->judge_read_fd, result, sizeof(result));
cout << "rd = " << rd << endl;
if (rd == 1) {
cout << "user_id = " << info->user_id << " question_id = " << info->question_id << endl;
LOG(INFO) << "读取到一个通过的判题结果" << endl;
// 然后往数据库中插入数据
Model* model = Model::GetInstance();
// 如果已经通过了, 那么什么都不做
if (model->hasPassed(info->user_id, info->question_id) == true) {
LOG(INFO) << "该用户再次通过该题" << endl;
}
else {
if (model->insertPassedQuestion(info->user_id, info->question_id) == 1) {
LOG(INFO) << "user_id = " + info->user_id << " 的用户成功完成编号为 " << info->question_id << " 的题目" << endl;
}
else {
LOG(WARNING) << "用户通过题目时发生未知错误" << endl;
}
}
}
else {
cout << "rd = " << rd << endl;
LOG(WARNING) << "读取判题结果失败" << endl;
}
// 将这个临时文件文件删除
if (FileUtil::Exists(info->judge_file_path)) {
unlink(info->judge_file_path.c_str());
}
// 然后关闭 读端口
close(info->judge_read_fd);
delete info;
}
然后是往 completed 表中添加一条用户答题记录的 model 中的接口
// 往数据库中执行 insert 语句
int insertMySQL(const string& sql)
{
LOG(INFO) << "执行 SQL 语句: " << sql << endl;
if (mysql_query(mysql, sql.c_str()) != 0) {
LOG(WANING) << sql << " 执行失败" << endl;
return -1;
}
// 否则返回受影响的行数, 也就是插入的行数
return mysql_affected_rows(mysql);
}
// 添加一条通过记录
bool insertPassedQuestion(int user_id, int question_id)
{
string sql = "insert completed (user_id, question_id) values(" + to_string(user_id) + ", " +
to_string(question_id) + ")";
if (insertMySQL(sql) == 1) { // 受影响的行数位 1
return true;
}
return false;
}
20. 展示用户完成的题目
每当用户完成一个题目之后,completed 表中就会多增加一条记录,那么如果想知道一个用户总共完成了哪些题目,那么只需要 select question_id from completed where user_id = 用户ID,就可以得知该用户的答题情况了
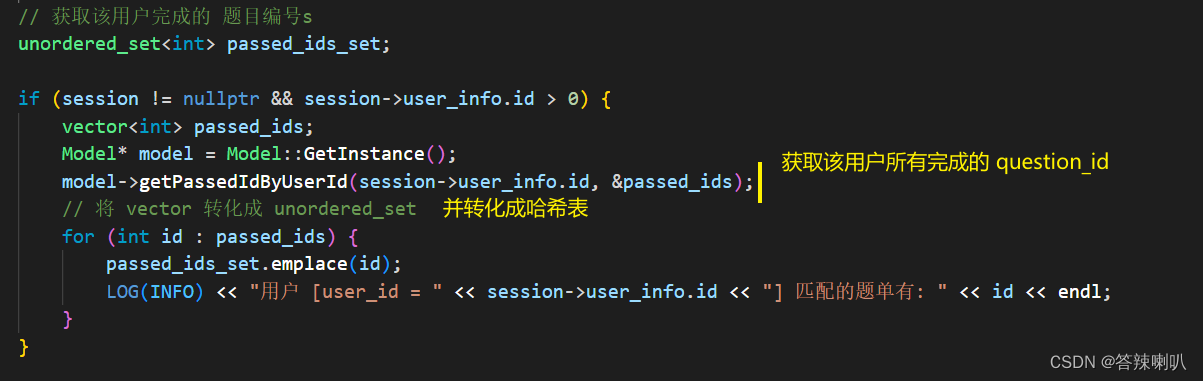
接着就可以在 view 中,根据 HttpSession 来获取该用户所有完成的题目ID,然后再将这些 question_id 存入哈希表中,方便后续查找
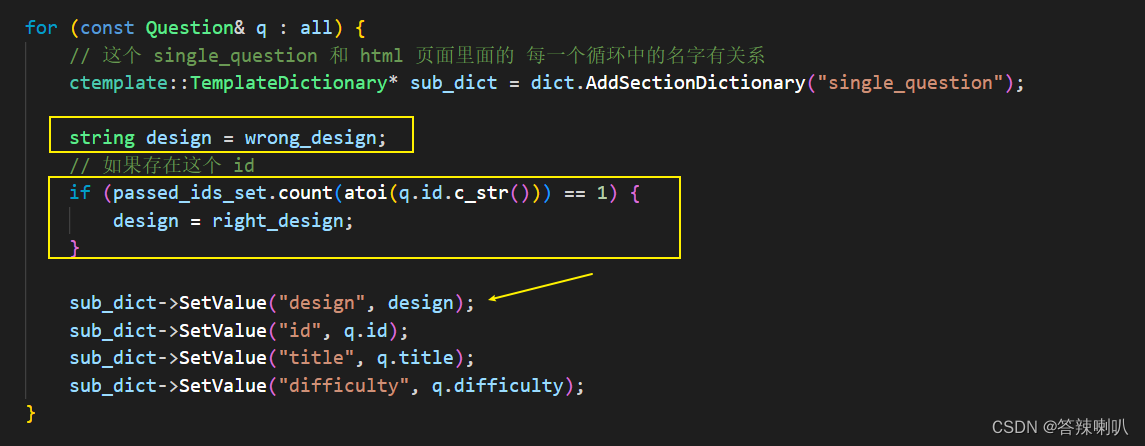
 然后后面再渲染题库页面中的所有题库的时候,就判断一下该题号是否在哈希表中,如果存在,那么在打个勾;如果不存在,那就打个叉
然后后面再渲染题库页面中的所有题库的时候,就判断一下该题号是否在哈希表中,如果存在,那么在打个勾;如果不存在,那就打个叉

 于是就可以达成这种效果
于是就可以达成这种效果
