pyspark_自定义udf_解析json列【附代码】
一、背景:
车联网数据有很多车的时序数据,现有一套云端算法需要对每一辆车历史数据进行计算得到结果,每日将全部车算一遍存到hive数仓中
二、调研方案:
1、python脚本运行,利用pyhive拉取数据到pandas进行处理,将结果to_parquet后用hdfs_client存到数仓中
问题:数据量上亿,对内存要求极大,无法直接拉取到python脚本所在的服务器内存中运算
2、将算法内容改写成SQL或者SPARKSQL,每日调度
问题:代码改写SQL要重新梳理代码逻辑,且很多函数SQL实现复杂,有些函数不支持
三、利用Pyspark + udf自定义函数实现大数据并行计算
整体流程
1、pyspark-spark sql拉取数据到spark df
2、spark df 按 车辆唯一标识分组,执行udf自定义函数(算法),每一个分组的返回值是String类型的json字符串,执行完成后返回的是result_df, spark_df【索引(车辆唯一标识)、数据(String类型的json字符串)】
3、解析json并拼接成spark_df
4、spark_df生成临时表,将临时表数据写入hive数仓
案例代码运行结果:
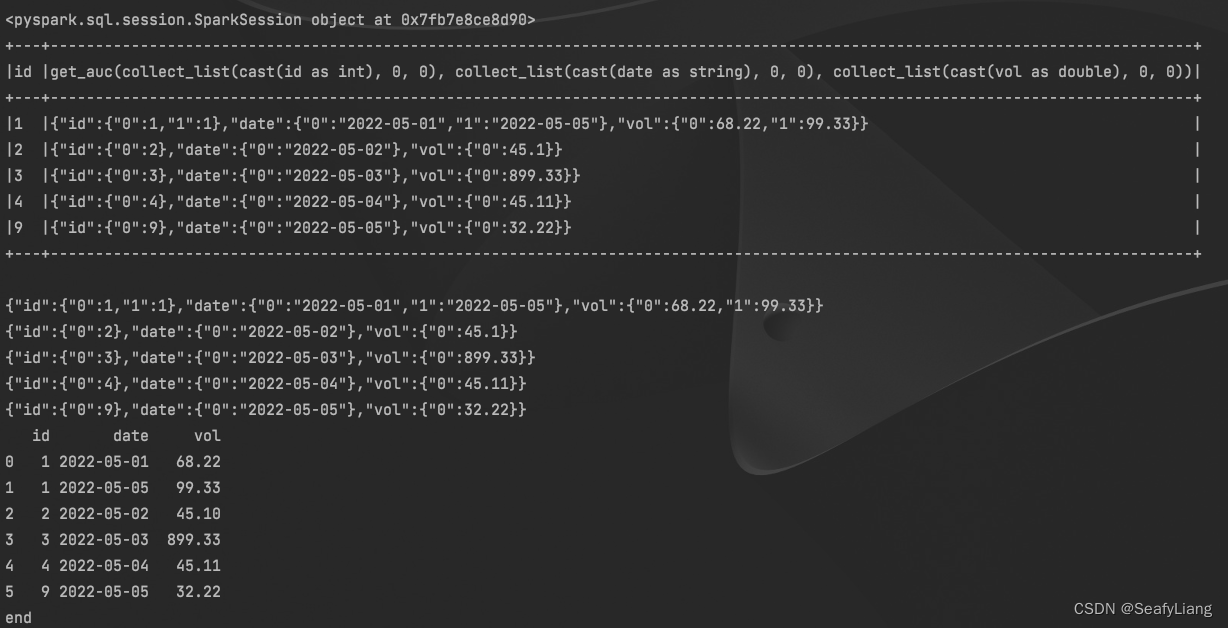
案例代码:
代码地址:
https://github.com/SeafyLiang/Python_study/blob/master/pyspark_demo/pyspark_udf_json.py
代码
from pyspark.sql import SparkSession # SparkConf、SparkContext 和 SQLContext 都已经被封装在 SparkSession
from pyspark.sql import functions as F
import pandas as pd
from pyspark.sql import types as T # spark df的数据类型
from pyspark.sql.functions import array, from_json, col, explode
import sys
def get_auc(id, date, vol):
temp_df = pd.DataFrame({
'id': id,
'date': date,
'vol': vol
})
temp_df['date'] = temp_df['date'].apply(lambda x: x + 'aaa')
temp_df_json = temp_df.to_json(orient='records') # orient='records'是关键,可以把json转成array<json>
return temp_df_json
if __name__ == '__main__':
spark = SparkSession.builder.appName('test_sklearn_pyspark') \
.config("spark.sql.warehouse.dir", "hdfs://nameservice1/user/hive/warehouse") \
.config("hive.exec.dynamici.partition", True) \
.config("hive.exec.dynamic.partition.mode", "nonstrict") \
.config("spark.sql.crossJoin.enabled", "true"). \
config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.enableHiveSupport() \
.getOrCreate()
print(spark)
temp_dict = {
'id': [1, 2, 3, 4, 1, 1],
'date': ['2022-05-01', '2022-05-02', '2022-05-03', '2022-05-04', '2022-05-05', '2022-05-05'],
'vol': [68.22, 45.10, 899.33, 45.11, 32.22, 99.33]
}
tempdf = pd.DataFrame(temp_dict)
df = spark.createDataFrame(tempdf)
# 自定义函数(计算AUC),并且变成UDF
"""注意:自定义函数的重点在于定义返回值的数据类型,这个返回值的数据类型必须与该函数return值的数据类型一致,否则会报错。
该例子中,该函数return的值auc,是string类型,在将该函数定义成udf的时候,指定的返回值类型,也必须是string!!"""
get_auc_udfs = F.udf(get_auc, returnType=T.StringType()) # 定义成udf,并且此udf的返回值类型为string
# 分组聚合操作:分别计算每月样本量、逾期率、AUC
"""使用上面定义的UDF,结合F.collect_list(col)来实现UDAF的功能。
F.collect_lits(col)的作用是将列col的值变成一个list返回."""
df_result = df.groupby('id').agg(get_auc_udfs(
F.collect_list(F.col('id').cast('int')),
F.collect_list(F.col('date').cast('string')),
F.collect_list(F.col('vol').cast('double'))
).alias('json_str')) # 利用自定的UDF,实现指定聚合计算
df_result.show(truncate=False)
opn = 2
if opn == 1:
# 【不推荐】方式一:spark_df转成pandas_df,拼接json成pandas_all_df后再转成spark_df写入
# 数据量大时会把大量数据拉到driver本地,导致内存溢出
all_result_df = pd.DataFrame()
df_result_pandas = df_result.toPandas()
for row in df_result_pandas.itertuples():
print(row.json_str)
temp_df = pd.read_json(row.json_str)
all_result_df = pd.concat([all_result_df, temp_df], ignore_index=True)
print(all_result_df)
elif opn == 2:
# 【推荐】方式二:解析json成新的spark_df
json_schema = T.ArrayType(
T.StructType().add("id", T.IntegerType()).add("date", T.StringType()).add("vol", T.DoubleType()))
df_result = df_result.withColumn('parsed_json', from_json(col('json_str'), json_schema))
df_result.show()
df_result.select('parsed_json').show(3, truncate=False)
df_result = df_result.select(explode(col('parsed_json')).alias('parsed_json_explode'))
df_result.show()
df_result = df_result.select(col('parsed_json_explode.id').alias('id'),
col('parsed_json_explode.date').alias('date'),
col('parsed_json_explode.vol').alias('vol'))
df_result.show()
print('df_result:', df_result.count())
# 写入hive表
# dt_before1day = sys.argv[1]
# print('dt_before1day:', dt_before1day)
# # df 转为临时表/临时视图
# df_result.createOrReplaceTempView("df_tmp_view")
# # spark.sql 插入hive
# spark.sql("""
# insert overwrite table table_name partition(dt='{DT}')
# select
# *
# from df_tmp_view
# """.format(DT=dt_before1day))
# print('spark write end!')
print('end')