Pandas教程:教你DataFrame数据的条件筛选——精选篇
1.1DataFrame数据的筛选与分布统计的示例用法
import pandas as pd
data = {'诗人': ['李白', '苏轼', '李清照', '杜甫', '岳飞'],
'性别': ['男', '男', '女', '男', '男'],
'芳龄': [18, 26, 13, 15, 28],
'朝代': ['唐', '北宋', '宋', '唐', '南宋'],
'薪资': [9000, 7000, 8000, 5000, 7000]}
df = pd.DataFrame(data, index=['一', '二', '三', '四', '五'])
print('0.原始DataFrame数据'.center(40, '-'))
print(df)
print('1.计数器:统计性别字段里面,男女的分别个数'.center(40, '-'))
print(df['性别'].value_counts())
print('显示占比,在数量统计的基础上加一个参数 normalize=True'.center(40, '-'))
print(df['性别'].value_counts(normalize=True))
print('2.筛选出性别为男的数据'.center(40, '-'))
print(df[df['性别'] == '男'])
print('3.筛选出朝代是唐,宋的数据'.center(40, '-'))
print(df[df['朝代'].isin(['唐', '宋'])])
print('4.筛选出薪资大于等于8000的数据'.center(40, '-'))
print(df[df['薪资'] >= 8000])
输出内容:
------------0.原始DataFrame数据-------------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
二 苏轼 男 26 北宋 7000
三 李清照 女 13 宋 8000
四 杜甫 男 15 唐 5000
五 岳飞 男 28 南宋 7000
---------1.计数器:统计性别字段里面,男女的分别个数---------
性别
男 4
女 1
Name: count, dtype: int64
---显示占比,在数量统计的基础上加一个参数 normalize=True---
性别
男 0.8
女 0.2
Name: proportion, dtype: float64
--------------2.筛选出性别为男的数据--------------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
二 苏轼 男 26 北宋 7000
四 杜甫 男 15 唐 5000
五 岳飞 男 28 南宋 7000
-------------3.筛选出朝代是唐,宋的数据-------------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
三 李清照 女 13 宋 8000
四 杜甫 男 15 唐 5000
-----------4.筛选出薪资大于等于8000的数据-----------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
三 李清照 女 13 宋 8000
2.不同列/字段的数据值的比较: 例如我们可以筛选出A列大于等于B列的数据,如果ab是一个字符串的类型数据,可以使用astype(int)先将他们转化成数值类型,再作比较运算,可以使用下面的代码。
import pandas as pd
data = {'A': [100, 10, 50, 34, 20],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
print('0.原始dataFrame数据'.center(40, '-'))
print(df)
print('0.筛选A列大于等于B列的数据'.center(40, '-'))
# 先将B列字段类型转为数值类型
# df['B'] = df['B'].astype(int)
print(df[df['A'] >= df['B']])
输出内容:
------------0.原始dataFrame数据-------------
A B
0 100 10
1 10 20
2 50 30
3 34 40
4 20 50
------------0.筛选A列大于等于B列的数据-------------
A B
0 100 10
2 50 30
3.筛选数据data中年龄字段值,不为空的数据
import pandas as pd
import numpy as np
data = {'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, np.nan, 35],
'city': ['New York', np.nan, np.nan]}
df = pd.DataFrame(data, index=[0, 1, 2])
print('0.原始DataFrame数据'.center(40, '-'))
print(df)
print('1.获取字段值不为空的数据'.center(40, '-'))
print(df[df['age'].notna()])
print('2.获取字段值为空的数据'.center(40, '-'))
print(df[df['age'].isna()])
输出内容:
------------0.原始DataFrame数据-------------
name age city
0 Alice 25.0 New York
1 Bob NaN NaN
2 Charlie 35.0 NaN
-------------1.检查字段值不为空的数据--------------
name age city
0 Alice 25.0 New York
2 Charlie 35.0 NaN
-------------2.检查字段值不为空的数据--------------
name age city
1 Bob NaN NaN
4.按关键字匹配文本数据
import pandas as pd
data = {'诗人': ['李白', '苏轼', '李清照', '杜甫', '岳飞'],
'性别': ['男', '男', '女', '男', '男'],
'芳龄': [18, 26, 13, 15, 28],
'朝代': ['唐', '北宋', '宋', '唐', '南宋'],
'薪资': [9000, 7000, 8000, 5000, 7000]}
df = pd.DataFrame(data, index=['一', '二', '三', '四', '五'])
print('0.原始DataFrame数据'.center(40, '-'))
print(df)
print('1.在朝代列中筛选出,含有宋的关键字,即南宋,北宋,宋'.center(40, '-'))
print(df[df['朝代'].str.contains('宋')])
print('2.使用~符号,选出不含有"宋"的数据'.center(40, '-'))
print(df[~df['朝代'].str.contains('宋')])
print('3.字段中含有 唐|北宋 的数据'.center(40, '-'))
print(df[df['朝代'].str.contains('唐|北宋')])
print('4.字段中字符长度,小于等于2的数据'.center(40, '-'))
print(df[df['诗人'].str.len() <= 2])
输出内容:
------------0.原始DataFrame数据-------------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
二 苏轼 男 26 北宋 7000
三 李清照 女 13 宋 8000
四 杜甫 男 15 唐 5000
五 岳飞 男 28 南宋 7000
------1.在朝代列中筛选出,含有宋的关键字,即南宋,北宋,宋-------
诗人 性别 芳龄 朝代 薪资
二 苏轼 男 26 北宋 7000
三 李清照 女 13 宋 8000
五 岳飞 男 28 南宋 7000
----------2.使用~符号,选出不含有"宋"的数据-----------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
四 杜甫 男 15 唐 5000
------------3.字段中含有 唐|北宋 的数据------------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
二 苏轼 男 26 北宋 7000
四 杜甫 男 15 唐 5000
-----------4.字段中字符长度,小于等于2的数据-----------
诗人 性别 芳龄 朝代 薪资
一 李白 男 18 唐 9000
二 苏轼 男 26 北宋 7000
四 杜甫 男 15 唐 5000
五 岳飞 男 28 南宋 7000
5.日期筛选:除了对数值和字符进行筛选,Pandas也能像 Excel 那样根据日期筛选数据,例如筛选 2023 年>=(2023, 12, 15)的数据,就可以使用下面的代码。同样如果****字段列,不是日期类型的数据,需要先使用.astype转化,然后才能比较。
import pandas as pd
import numpy as np
# 创建日期序列
date_list = pd.date_range('2023-12-01', periods=20, freq='D')
value_list = np.random.randn(len(date_list))
df = pd.DataFrame({
'日期': date_list,
'数值': value_list})
print('0.原始DataFrame数据'.center(40, '-'))
print(df)
# 先将 上市日期 字段转为 python 中的日期类型
print('1.筛选日期 >=(2023, 12, 15)的数据'.center(40, '-'))
# df['日期'] = df['日期'].astype('datetime64[ns]')
# 筛选 2023 年新上市的A股企业
print(df[df['日期'] >= pd.Timestamp(2023, 12, 15)])
**6.多条件筛选:当存在多个条件时,每个条件最好都使用括号括起来,如果其中两个条件是“或”关系,那么使用逻辑或符号|来连接它们;如果两个条件的关系是“与”关系,那么就要用逻辑与符号&**来连接它们
import pandas as pd
data = {'诗人': ['李白', '苏轼', '李清照', '杜甫', '岳飞'],
'性别': ['男', '男', '女', '男', '男'],
'芳龄': [18, 26, 13, 15, 28],
'朝代': ['唐', '北宋', '宋', '唐', '南宋'],
'薪资': [9000, 7000, 8000, 5000, 7000]}
df = pd.DataFrame(data)
print('0.原始DataFrame数据'.center(40, '-'))
print(df)
print('1.且用法: 即朝代为唐或北宋,且薪资>=7000'.center(40, '-'))
print(df[(df['朝代'].isin(['唐', '北宋'])) & (df['薪资'] >= 7000)])
print('2.或用法: 筛选出性别为女,或薪资 >= 9000的数据'.center(40, '-'))
print(df[(df['性别'] == '女') | (df['薪资'] >= 9000)])
输出内容:
------------0.原始DataFrame数据-------------
诗人 性别 芳龄 朝代 薪资
0 李白 男 18 唐 9000
1 苏轼 男 26 北宋 7000
2 李清照 女 13 宋 8000
3 杜甫 男 15 唐 5000
4 岳飞 男 28 南宋 7000
-------1.且用法: 即朝代为唐或北宋,且薪资>=7000--------
诗人 性别 芳龄 朝代 薪资
0 李白 男 18 唐 9000
1 苏轼 男 26 北宋 7000
-----2.或用法: 筛选出性别为女,或薪资 >= 9000的数据------
诗人 性别 芳龄 朝代 薪资
0 李白 男 18 唐 9000
2 李清照 女 13 宋 8000
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

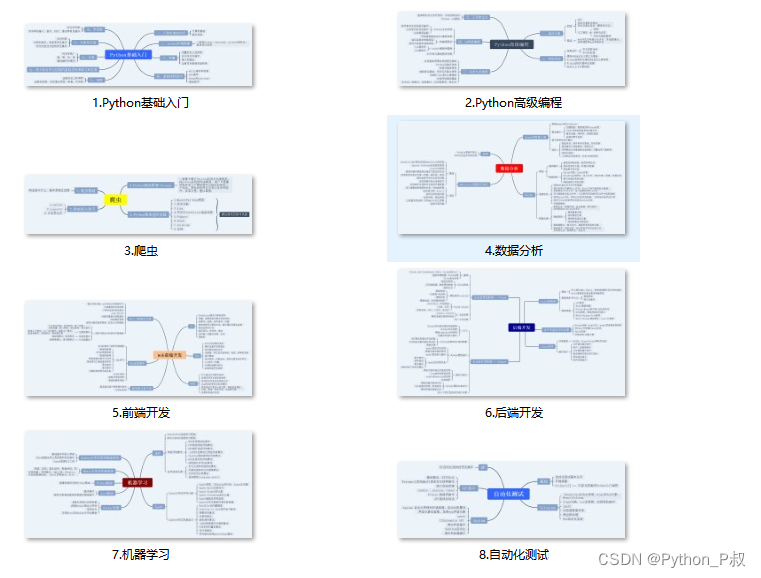
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
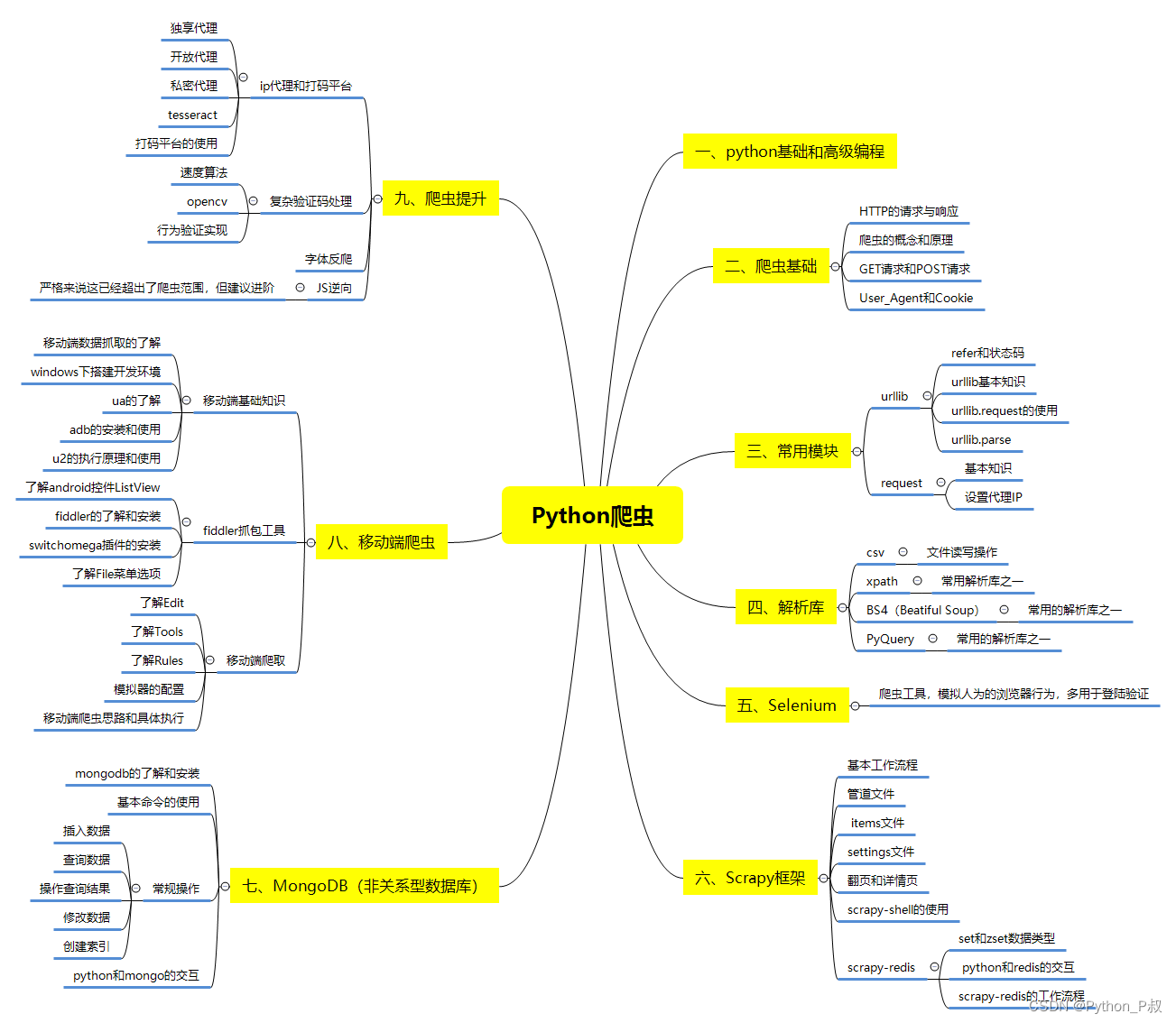
二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典
简历模板
 若有侵权,请联系删除
若有侵权,请联系删除