大数据毕设分享 opencv python 深度学习垃圾图像分类系统
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 opencv python 深度学习垃圾分类系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
课题简介
如今,垃圾分类已成为社会热点话题。其实在2019年4月26日,我国住房和城乡建设部等部门就发布了《关于在全国地级及以上城市全面开展生活垃圾分类工作的通知》,决定自2019年起在全国地级及以上城市全面启动生活垃圾分类工作。到2020年底,46个重点城市基本建成生活垃圾分类处理系统。
人工垃圾分类投放是垃圾处理的第一环节,但能够处理海量垃圾的环节是垃圾处理厂。然而,目前国内的垃圾处理厂基本都是采用人工流水线分拣的方式进行垃圾分拣,存在工作环境恶劣、劳动强度大、分拣效率低等缺点。在海量垃圾面前,人工分拣只能分拣出极有限的一部分可回收垃圾和有害垃圾,绝大多数垃圾只能进行填埋,带来了极大的资源浪费和环境污染危险。
随着深度学习技术在视觉领域的应用和发展,让我们看到了利用AI来自动进行垃圾分类的可能,通过摄像头拍摄垃圾图片,检测图片中垃圾的类别,从而可以让机器自动进行垃圾分拣,极大地提高垃圾分拣效率。
基于深度学习的垃圾分类系统,是非常好的毕业设计课题
一、识别效果
老样子, 废话不多说,先展示图像垃圾分类的识别效果
训练模型精度:
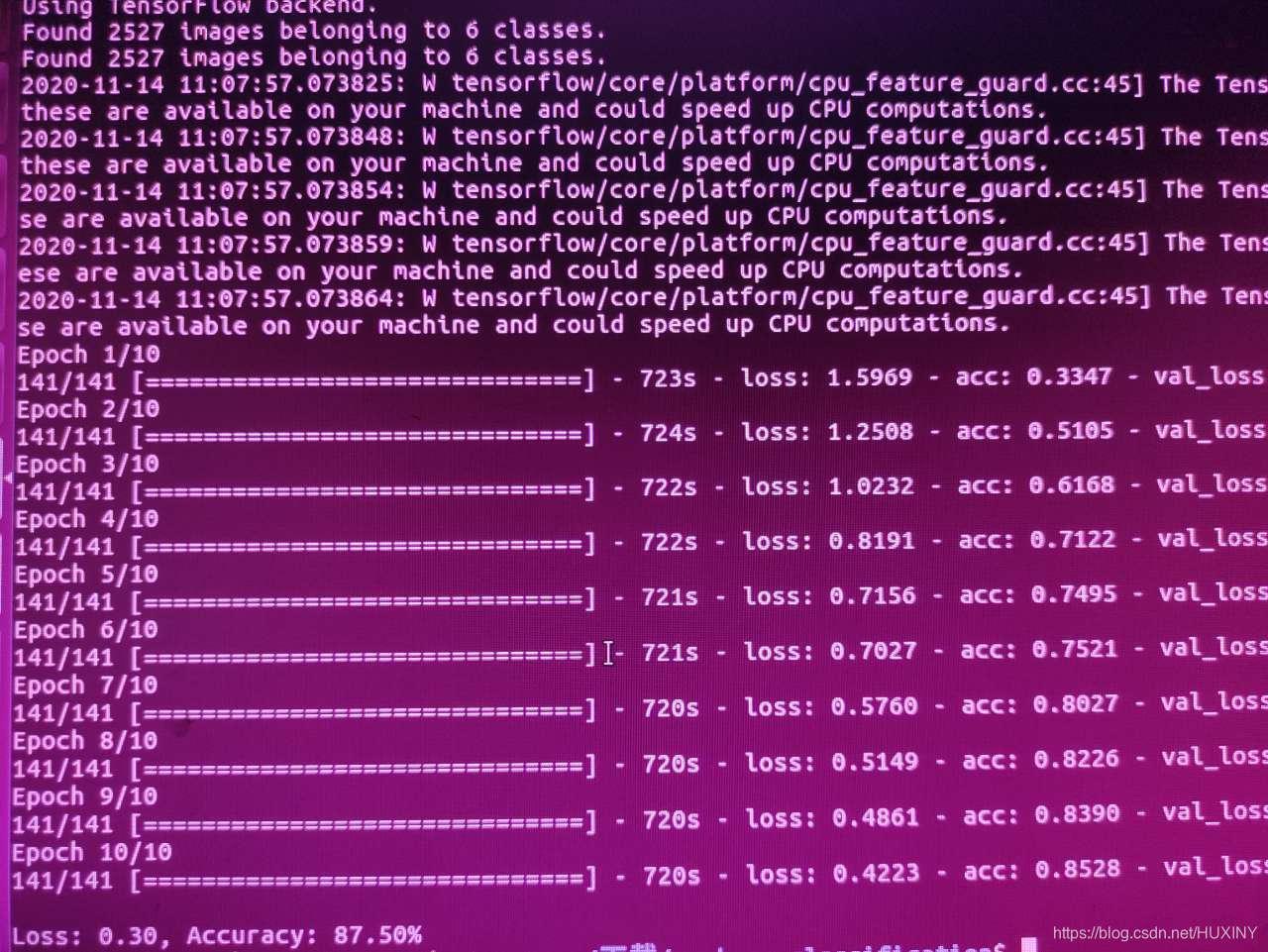
可以看到,只迭代了10轮精度达到87.50%,而且没有出现过拟合现象
我最高训练达到96%,迭代200轮
识别结果:

实际验证正确率还是很高的。
二、实现
1.数据集
该数据集包含了 2507 个生活垃圾图片。数据集的创建者将垃圾分为了 6 个类别,分别是:
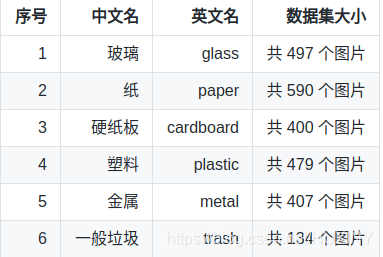
如下所示:

一共6类垃圾, 比如玻璃类的如下:
塑料类的如下:
其他的不列举了。
2.实现原理和方法
使用深度残差网络resnet50作为基石,在后续添加需要的层以适应不同的分类任务
模型的训练需要用生成器将数据集循环写入内存,同时图像增强以泛化模型
使用不包含网络输出部分的resnet50权重文件进行迁移学习,只训练我们在5个stage后增加的层
需要的第三方库主要有tensorflow1.x,keras,opencv,Pillow,scikit-learn,numpy
安装方式很简单,打开terminal,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
数据集与权重文件比较大,所以没有上传
如果环境配置方面有问题或者需要数据集与模型权重文件,可以在评论区说明您的问题,我将远程帮助您
3.网络结构
这里我只使用了resnet50的5个stage,后面的输出部分需要我们自己定制,网络的结构图如下:
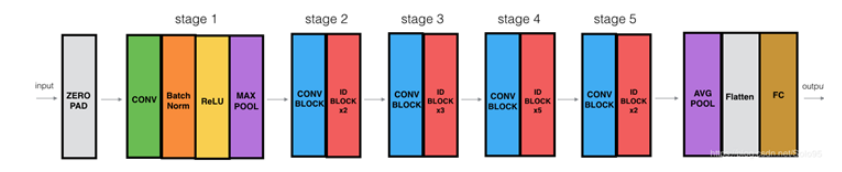
stage5后我们的定制网络如下:
"""定制resnet后面的层"""
def custom(input_size,num_classes,pretrain):
# 引入初始化resnet50模型
base_model = ResNet50(weights=pretrain,
include_top=False,
pooling=None,
input_shape=(input_size,input_size, 3),
classes=num_classes)
#由于有预权重,前部分冻结,后面进行迁移学习
for layer in base_model.layers:
layer.trainable = False
#添加后面的层
x = base_model.output
x = layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = layers.Dropout(0.5,name='dropout1')(x)
#regularizers正则化层,正则化器允许在优化过程中对层的参数或层的激活情况进行惩罚
#对损失函数进行最小化的同时,也需要让对参数添加限制,这个限制也就是正则化惩罚项,使用l2范数
x = layers.Dense(512,activation='relu',kernel_regularizer= regularizers.l2(0.0001),name='fc2')(x)
x = layers.BatchNormalization(name='bn_fc_01')(x)
x = layers.Dropout(0.5,name='dropout2')(x)
#40个分类
x = layers.Dense(num_classes,activation='softmax')(x)
model = Model(inputs=base_model.input,outputs=x)
#模型编译
model.compile(optimizer="adam",loss = 'categorical_crossentropy',metrics=['accuracy'])
return model
网络的训练是迁移学习过程,使用已有的初始resnet50权重(5个stage已经训练过,卷积层已经能够提取特征),我们只训练后面的全连接层部分,4个epoch后再对较后面的层进行训练微调一下,获得更高准确率,训练过程如下:
class Net():
def __init__(self,img_size,gar_num,data_dir,batch_size,pretrain):
self.img_size=img_size
self.gar_num=gar_num
self.data_dir=data_dir
self.batch_size=batch_size
self.pretrain=pretrain
def build_train(self):
"""迁移学习"""
model = resnet.custom(self.img_size, self.gar_num, self.pretrain)
model.summary()
train_sequence, validation_sequence = genit.gendata(self.data_dir, self.batch_size, self.gar_num, self.img_size)
epochs=4
model.fit_generator(train_sequence,steps_per_epoch=len(train_sequence),epochs=epochs,verbose=1,validation_data=validation_sequence,
max_queue_size=10,shuffle=True)
#微调,在实际工程中,激活函数也被算进层里,所以总共181层,微调是为了重新训练部分卷积层,同时训练最后的全连接层
layers=149
learning_rate=1e-4
for layer in model.layers[:layers]:
layer.trainable = False
for layer in model.layers[layers:]:
layer.trainable = True
Adam =adam(lr=learning_rate, decay=0.0005)
model.compile(optimizer=Adam, loss='categorical_crossentropy', metrics=['accuracy'])
model.fit_generator(train_sequence,steps_per_epoch=len(train_sequence),epochs=epochs * 2,verbose=1,
callbacks=[
callbacks.ModelCheckpoint('./models/garclass.h5',monitor='val_loss', save_best_only=True, mode='min'),
callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1,patience=10, mode='min'),
callbacks.EarlyStopping(monitor='val_loss', patience=10),],
validation_data=validation_sequence,max_queue_size=10,shuffle=True)
print('finish train,look for garclass.h5')