三维重建——NeuralRecon项目源码解读
代码链接见文末
首先,需要指明的是NeuralRecon项目不支持windows,主要是使用到的例如torchsprase等不支持windows,您也可以在网上查找相应的替代方法。
1.数据与环境配置
ScanNet数据的获取首先需要向作者发送邮件,作者会回复一个下载的脚本,在提供的代码中,提供了这个下载的脚本data.py。
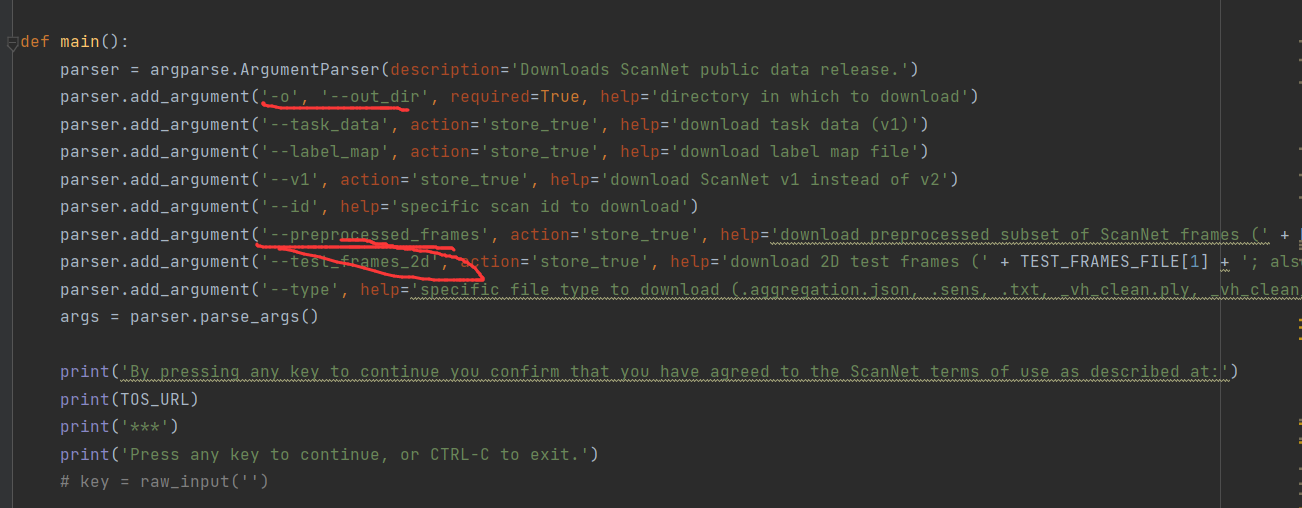
执行这个脚本文件即可下载,但是需要注意两个参数。-o是指定下载后存放的路径,--preprocessed_frames原始数据集太大,有1.2T,指定后,保留场景个数,但是对场景的图片进行采样,下载一个较小的数据集版本,供跑项目使用。
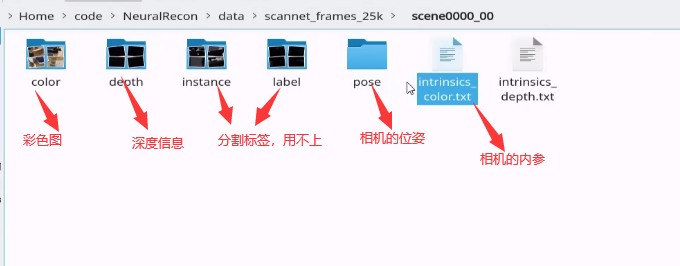
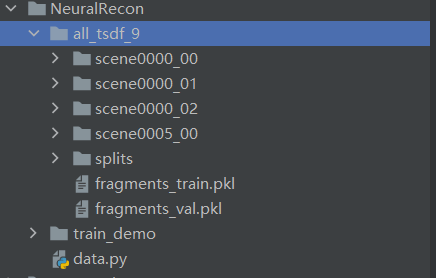
其中,每个文件夹的数据包含以下部分:
代码中提供的train_demo取了四个场景的很小部分,能够供跑通代码使用。
而all_tsdf_9中是对应生成的tsdf标签
2.生成TSDF标签
TSDF标签的生成主要使用NeuralRecon/NeuralRecon-master/tools/tsdf_fusion下的文件,
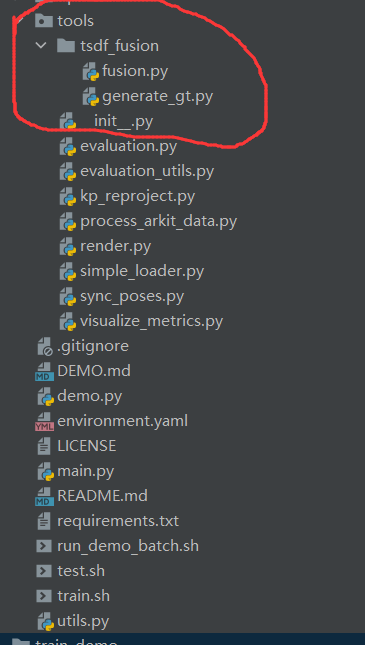
在这个过程可能会遇到很多路径上的问题,报错方面本博客可能不能涵盖全部,仅仅只展示我本人所遇到的问题。
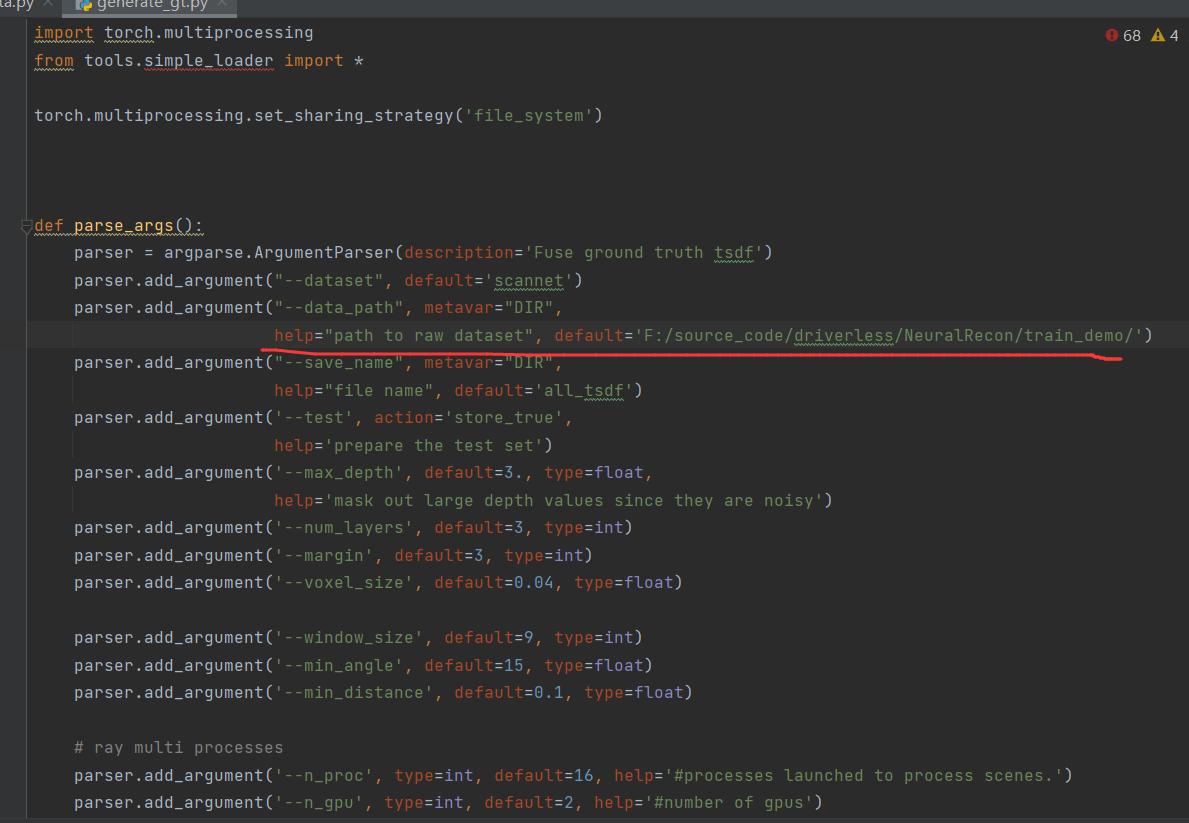
首先是generate_gt.py文件中的--data_path配置参数,修改为自己下载数据集的路径。
3.环境的配置
进入目录后:使用pip install -r requirements.txt即可配置环境,其中pycuda可能会安装失败
pycuda的安装
pycuda直接使用pip install会报错,建议采用离线安装,参考:
安装pycuda及问题解决_卷中卷的博客-CSDN博客_pycuda安装
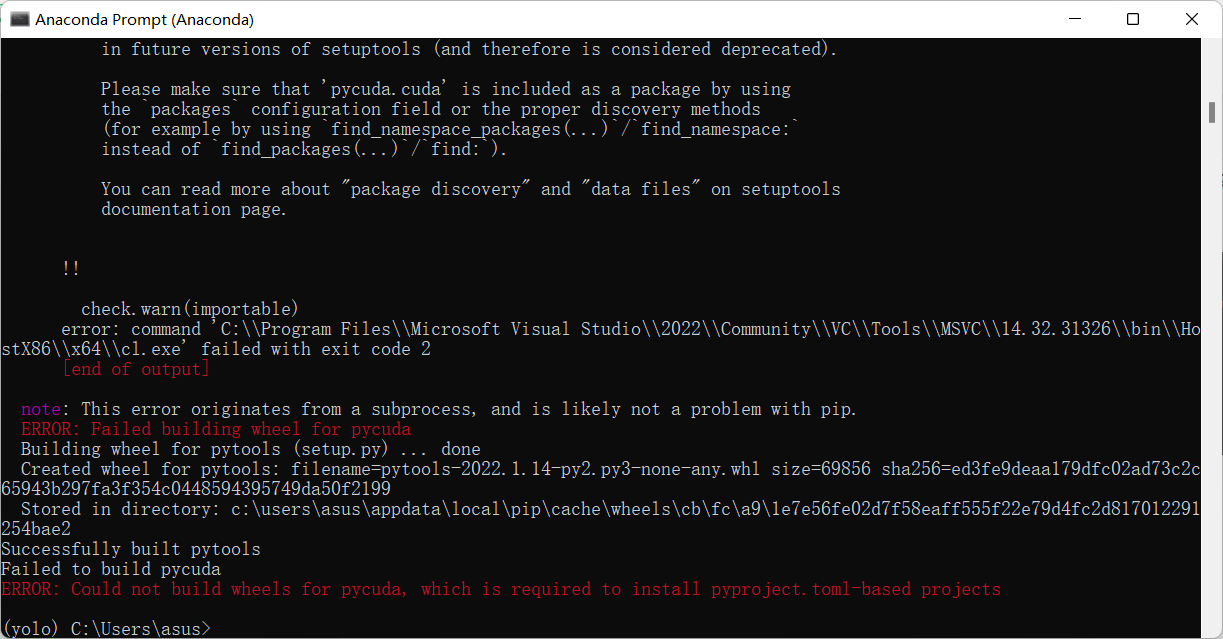
在运行过程中,pycuda可能会报错,因为找不到cuda,这时可以进入cmd看看nvcc -v指令是否能够运行,如果不能运行,可能是没有装cuda和没有指定cuda环境变量,可能需要重装cuda。如果能够运行。解决方法参考:uwsgi+pycuda启动报错 pytools.prefork.ExecError: error invoking nvcc --version‘:_qq591840685的博客-CSDN博客
如果只想跑跑代码,进行debug操作,不想重装cuda的话或在这方面耗费过多的时间,源码中提供了已经生成的少量数据的tsdf标签,能够供跑代码使用
此外,还需要安装torchsparse,参考github:GitHub - mit-han-lab/torchsparse: [MLSys'22] TorchSparse: Efficient Point Cloud Inference Engine 使用
sudo apt-get install libsparsehash-dev
或:
pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git@v1.4.0
进行安装
4.demo
源码中提供的demo文件可以指定预训练模型进行运行,但是设备仅限制于IPhone和MAC。详见: NeuralRecon/DEMO.md at master · zju3dv/NeuralRecon · GitHub
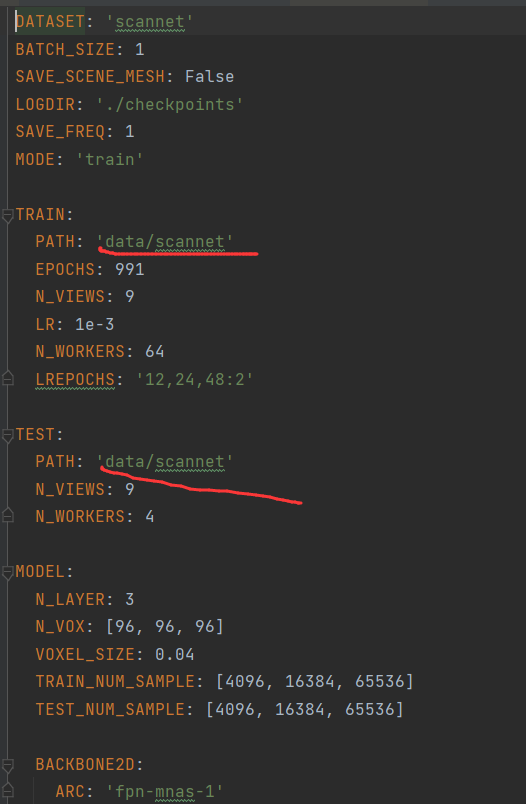
5.训练
训练可以执行train.sh,也可以在main.py配置参数--cfg ./config/train.yaml进行运行,train.yaml为训练配置文件,路径需要自己指定一下:
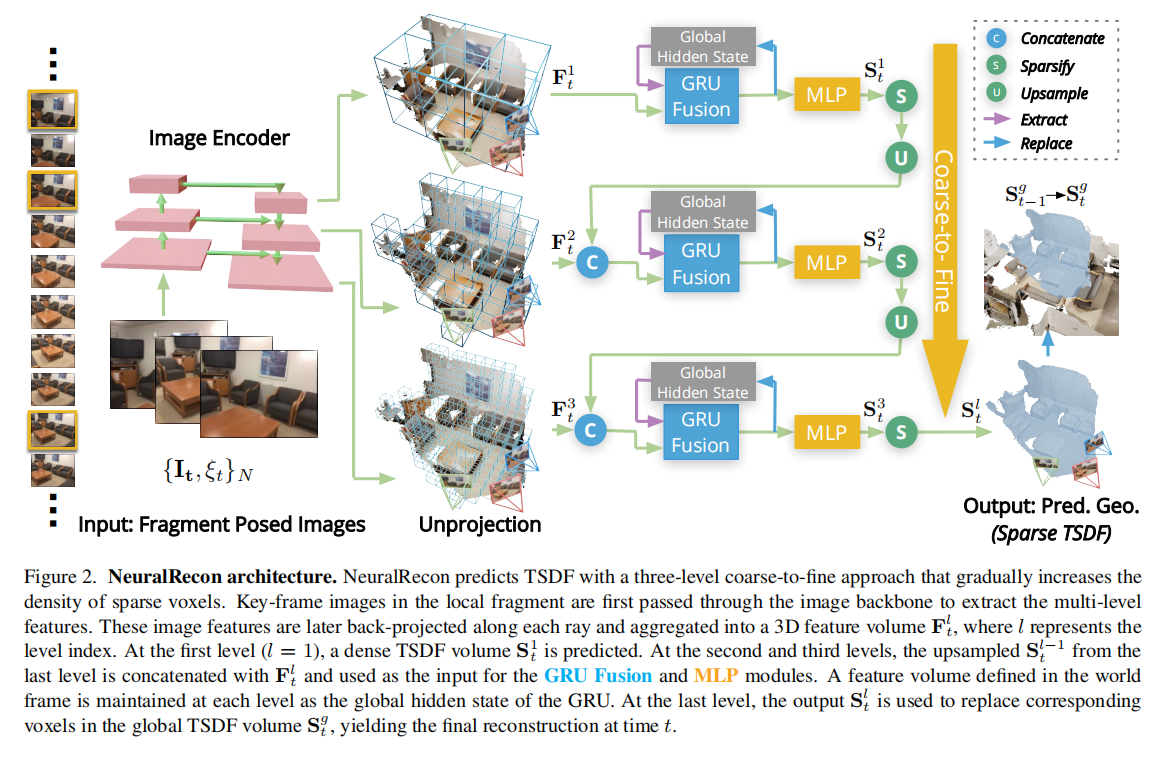
6.网络结构
(1)backbone得到特征图
在算法中,通过9张图片重构一个片段,因此,输入中每个batch包含一个片段(9张图片),并对每张图片经过backbone进行特征提取,得到特征图。backbone作者采用的是MNASNet,也可以替换为其他的Backbone。
(2)三维重建模块
整个网络采用由粗到细的网络结构,即首先重构整体框架,然后再重构局部细节。在第一个阶段重构的体素间隔为4,第二个阶段间隔为2,最后一个阶段间隔为1。
第一阶段
在第一个阶段,需要对体素进行初始化,得到体素的索引,后续阶段可由上一阶段进行上采样。初始化过程即以间隔为4初始化网格,代码如下:
def generate_grid(n_vox, interval):
with torch.no_grad():
# Create voxel grid
grid_range = [torch.arange(0, n_vox[axis], interval) for axis in range(3)]
grid = torch.stack(torch.meshgrid(grid_range[0], grid_range[1], grid_range[2])) # 3 dx dy dz
grid = grid.unsqueeze(0).cuda().float() # 1 3 dx dy dz
grid = grid.view(1, 3, -1)
return grid然后,我们需要将特征图的特征映射到对应体素上,其具体过程为首先由初始化的体素索引得到体素的实际位置,然后将体素的实际坐标通过坐标变换映射到像素坐标。映射的像素坐标很可能是小数,因此采用插值法得到体素对应的特征。一个体素对应于9张特征图的特征,求平均即得到体素的特征。坐标变换参见我的博客:三维重建——商汤NeuralRecon算法详解与论文解读_樱花的浪漫的博客-CSDN博客
代码如下:
def back_project(coords, origin, voxel_size, feats, KRcam):
'''
Unproject the image fetures to form a 3D (sparse) feature volume
:param coords: coordinates of voxels,
dim: (num of voxels, 4) (4 : batch ind, x, y, z)
:param origin: origin of the partial voxel volume (xyz position of voxel (0, 0, 0))
dim: (batch size, 3) (3: x, y, z)
:param voxel_size: floats specifying the size of a voxel
:param feats: image features
dim: (num of views, batch size, C, H, W)
:param KRcam: projection matrix
dim: (num of views, batch size, 4, 4)
:return: feature_volume_all: 3D feature volumes
dim: (num of voxels, c + 1)
:return: count: number of times each voxel can be seen
dim: (num of voxels,)
'''
n_views, bs, c, h, w = feats.shape
# 体素特征初始化,c+1表示有c个特征是从图像中获取,还有1个特征深度特征
feature_volume_all = torch.zeros(coords.shape[0], c + 1).cuda()
count = torch.zeros(coords.shape[0]).cuda()
for batch in range(bs):
# 找到当前batch对应的片段
batch_ind = torch.nonzero(coords[:, 0] == batch).squeeze(1)
coords_batch = coords[batch_ind][:, 1:]
coords_batch = coords_batch.view(-1, 3)
origin_batch = origin[batch].unsqueeze(0)
feats_batch = feats[:, batch]
# 相机内外参
proj_batch = KRcam[:, batch]
# 体素索引*体素大小+初始位置得到体素的实际位置
grid_batch = coords_batch * voxel_size + origin_batch.float()
# 初始化一个[9,3,体素个数]的坐标矩阵
rs_grid = grid_batch.unsqueeze(0).expand(n_views, -1, -1)
rs_grid = rs_grid.permute(0, 2, 1).contiguous()
nV = rs_grid.shape[-1]
# 将矩阵再拼接一个全为1的维度,变为4个维度,以方便进行坐标变换
rs_grid = torch.cat([rs_grid, torch.ones([n_views, 1, nV]).cuda()], dim=1)
# Project grid
# 进行坐标映射得到像素坐标,因为对坐标添加了一个维度,
# 所以除以z得到x,y坐标
im_p = proj_batch @ rs_grid
im_x, im_y, im_z = im_p[:, 0], im_p[:, 1], im_p[:, 2]
im_x = im_x / im_z
im_y = im_y / im_z
# mask操作,转化为像素坐标后可能会出现越界,mask掉
im_grid = torch.stack([2 * im_x / (w - 1) - 1, 2 * im_y / (h - 1) - 1], dim=-1)
mask = im_grid.abs() <= 1
mask = (mask.sum(dim=-1) == 2) & (im_z > 0)
# 特征图
feats_batch = feats_batch.view(n_views, c, h, w)
# 每个体素的映射坐标
im_grid = im_grid.view(n_views, 1, -1, 2)
# 大多数体素对应的像素坐标很可能是小数,通过周围四个点插值得到对应的特征
features = grid_sample(feats_batch, im_grid, padding_mode='zeros', align_corners=True)
# 去掉越界和nan值
features = features.view(n_views, c, -1)
mask = mask.view(n_views, -1)
im_z = im_z.view(n_views, -1)
# remove nan
features[mask.unsqueeze(1).expand(-1, c, -1) == False] = 0
im_z[mask == False] = 0
count[batch_ind] = mask.sum(dim=0).float()
# aggregate multi view
# 整合9张特征图的特征(求平均)
features = features.sum(dim=0)
mask = mask.sum(dim=0)
invalid_mask = mask == 0
mask[invalid_mask] = 1
in_scope_mask = mask.unsqueeze(0)
features /= in_scope_mask
features = features.permute(1, 0).contiguous()
# concat normalized depth value
# 第81个维度的信息就是z,即深度信息,进行标准化
im_z = im_z.sum(dim=0).unsqueeze(1) / in_scope_mask.permute(1, 0).contiguous()
im_z_mean = im_z[im_z > 0].mean()
im_z_std = torch.norm(im_z[im_z > 0] - im_z_mean) + 1e-5
im_z_norm = (im_z - im_z_mean) / im_z_std
im_z_norm[im_z <= 0] = 0
features = torch.cat([features, im_z_norm], dim=1)
feature_volume_all[batch_ind] = features
return feature_volume_all, count然后对得到的体素的特征进行稀疏卷积,并使用gru进行片段的融合,即每一个片段需要考虑到之前的片段的特征,同时gru还可以对重复的部分进行遗忘。最后使用全连接层预测得到TSDF值。
第二阶段和第三阶段
每一阶段的处理过程大致相似,不同的是,后一阶段体素的特征需要与经过上采样的前一阶段的特征进行拼接。
整体流程如下:
class NeuConNet(nn.Module):
'''
Coarse-to-fine network.
'''
def __init__(self, cfg):
super(NeuConNet, self).__init__()
self.cfg = cfg
self.n_scales = len(cfg.THRESHOLDS) - 1
alpha = int(self.cfg.BACKBONE2D.ARC.split('-')[-1])
ch_in = [80 * alpha + 1, 96 + 40 * alpha + 2 + 1, 48 + 24 * alpha + 2 + 1, 24 + 24 + 2 + 1]
channels = [96, 48, 24]
if self.cfg.FUSION.FUSION_ON:
# GRU Fusion
self.gru_fusion = GRUFusion(cfg, channels)
# sparse conv
self.sp_convs = nn.ModuleList()
# MLPs that predict tsdf and occupancy.
self.tsdf_preds = nn.ModuleList()
self.occ_preds = nn.ModuleList()
for i in range(len(cfg.THRESHOLDS)):
self.sp_convs.append(
SPVCNN(num_classes=1, in_channels=ch_in[i],
pres=1,
cr=1 / 2 ** i,
vres=self.cfg.VOXEL_SIZE * 2 ** (self.n_scales - i),
dropout=self.cfg.SPARSEREG.DROPOUT)
)
self.tsdf_preds.append(nn.Linear(channels[i], 1))
self.occ_preds.append(nn.Linear(channels[i], 1))
def get_target(self, coords, inputs, scale):
'''
Won't be used when 'fusion_on' flag is turned on
:param coords: (Tensor), coordinates of voxels, (N, 4) (4 : Batch ind, x, y, z)
:param inputs: (List), inputs['tsdf_list' / 'occ_list']: ground truth volume list, [(B, DIM_X, DIM_Y, DIM_Z)]
:param scale:
:return: tsdf_target: (Tensor), tsdf ground truth for each predicted voxels, (N,)
:return: occ_target: (Tensor), occupancy ground truth for each predicted voxels, (N,)
'''
with torch.no_grad():
tsdf_target = inputs['tsdf_list'][scale]
occ_target = inputs['occ_list'][scale]
coords_down = coords.detach().clone().long()
# 2 ** scale == interval
coords_down[:, 1:] = (coords[:, 1:] // 2 ** scale)
tsdf_target = tsdf_target[coords_down[:, 0], coords_down[:, 1], coords_down[:, 2], coords_down[:, 3]]
occ_target = occ_target[coords_down[:, 0], coords_down[:, 1], coords_down[:, 2], coords_down[:, 3]]
return tsdf_target, occ_target
def upsample(self, pre_feat, pre_coords, interval, num=8):
'''
:param pre_feat: (Tensor), features from last level, (N, C)
:param pre_coords: (Tensor), coordinates from last level, (N, 4) (4 : Batch ind, x, y, z)
:param interval: interval of voxels, interval = scale ** 2
:param num: 1 -> 8
:return: up_feat : (Tensor), upsampled features, (N*8, C)
:return: up_coords: (N*8, 4), upsampled coordinates, (4 : Batch ind, x, y, z)
'''
with torch.no_grad():
pos_list = [1, 2, 3, [1, 2], [1, 3], [2, 3], [1, 2, 3]]
n, c = pre_feat.shape
up_feat = pre_feat.unsqueeze(1).expand(-1, num, -1).contiguous()
up_coords = pre_coords.unsqueeze(1).repeat(1, num, 1).contiguous()
for i in range(num - 1):
up_coords[:, i + 1, pos_list[i]] += interval
up_feat = up_feat.view(-1, c)
up_coords = up_coords.view(-1, 4)
return up_feat, up_coords
def forward(self, features, inputs, outputs):
'''
:param features: list: features for each image: eg. list[0] : pyramid features for image0 : [(B, C0, H, W), (B, C1, H/2, W/2), (B, C2, H/2, W/2)]
:param inputs: meta data from dataloader
:param outputs: {}
:return: outputs: dict: {
'coords': (Tensor), coordinates of voxels,
(number of voxels, 4) (4 : batch ind, x, y, z)
'tsdf': (Tensor), TSDF of voxels,
(number of voxels, 1)
}
:return: loss_dict: dict: {
'tsdf_occ_loss_X': (Tensor), multi level loss
}
'''
# batch是片段的个数,一个片段通过9张图片进行重构
bs = features[0][0].shape[0]
pre_feat = None
pre_coords = None
loss_dict = {}
# ----coarse to fine----
# 由粗到细,三个阶段
for i in range(self.cfg.N_LAYER):
interval = 2 ** (self.n_scales - i)
scale = self.n_scales - i
# 在第一个阶段,初始化体素位置
if i == 0:
# ----generate new coords----
coords = generate_grid(self.cfg.N_VOX, interval)[0]
up_coords = []
for b in range(bs):
up_coords.append(torch.cat([torch.ones(1, coords.shape[-1]).to(coords.device) * b, coords]))
up_coords = torch.cat(up_coords, dim=1).permute(1, 0).contiguous()
# 后一阶段根据第一个阶段进行上采样
else:
# ----upsample coords----
up_feat, up_coords = self.upsample(pre_feat, pre_coords, interval)
# ----back project----
# 提取得到的特征图的特征
feats = torch.stack([feat[scale] for feat in features])
# 相机的内外参数
KRcam = inputs['proj_matrices'][:, :, scale].permute(1, 0, 2, 3).contiguous()
# 将特征映射到对应的体素
volume, count = back_project(up_coords, inputs['vol_origin_partial'], self.cfg.VOXEL_SIZE, feats,
KRcam)
grid_mask = count > 1
# ----concat feature from last stage----
# 第二阶段和第三阶段的最终得到的结果需要与上一阶段上采样得到的结果进行拼接
if i != 0:
feat = torch.cat([volume, up_feat], dim=1)
else:
feat = volume
if not self.cfg.FUSION.FUSION_ON:
tsdf_target, occ_target = self.get_target(up_coords, inputs, scale)
# ----convert to aligned camera coordinate----
r_coords = up_coords.detach().clone().float()
for b in range(bs):
batch_ind = torch.nonzero(up_coords[:, 0] == b).squeeze(1)
coords_batch = up_coords[batch_ind][:, 1:].float()
coords_batch = coords_batch * self.cfg.VOXEL_SIZE + inputs['vol_origin_partial'][b].float()
coords_batch = torch.cat((coords_batch, torch.ones_like(coords_batch[:, :1])), dim=1)
coords_batch = coords_batch @ inputs['world_to_aligned_camera'][b, :3, :].permute(1, 0).contiguous()
r_coords[batch_ind, 1:] = coords_batch
# batch index is in the last position
# 将体素的索引增加一个维度,方便进行3d的稀疏卷积
r_coords = r_coords[:, [1, 2, 3, 0]]
# ----sparse conv 3d backbone----
# 对体素的特征进行3d稀疏卷积
point_feat = PointTensor(feat, r_coords)
feat = self.sp_convs[i](point_feat)
# ----gru fusion----
if self.cfg.FUSION.FUSION_ON:
# 使用gru进行片段的融合
up_coords, feat, tsdf_target, occ_target = self.gru_fusion(up_coords, feat, inputs, i)
if self.cfg.FUSION.FULL:
grid_mask = torch.ones_like(feat[:, 0]).bool()
# 使用全连接层得到预测的体素值
tsdf = self.tsdf_preds[i](feat)
occ = self.occ_preds[i](feat)
# -------compute loss-------
if tsdf_target is not None:
loss = self.compute_loss(tsdf, occ, tsdf_target, occ_target,
mask=grid_mask,
pos_weight=self.cfg.POS_WEIGHT)
else:
loss = torch.Tensor(np.array([0]))[0]
loss_dict.update({f'tsdf_occ_loss_{i}': loss})
# ------define the sparsity for the next stage-----
occupancy = occ.squeeze(1) > self.cfg.THRESHOLDS[i]
occupancy[grid_mask == False] = False
num = int(occupancy.sum().data.cpu())
if num == 0:
logger.warning('no valid points: scale {}'.format(i))
return outputs, loss_dict
# ------avoid out of memory: sample points if num of points is too large-----
if self.training and num > self.cfg.TRAIN_NUM_SAMPLE[i] * bs:
choice = np.random.choice(num, num - self.cfg.TRAIN_NUM_SAMPLE[i] * bs,
replace=False)
ind = torch.nonzero(occupancy)
occupancy[ind[choice]] = False
pre_coords = up_coords[occupancy]
for b in range(bs):
batch_ind = torch.nonzero(pre_coords[:, 0] == b).squeeze(1)
if len(batch_ind) == 0:
logger.warning('no valid points: scale {}, batch {}'.format(i, b))
return outputs, loss_dict
pre_feat = feat[occupancy]
pre_tsdf = tsdf[occupancy]
pre_occ = occ[occupancy]
pre_feat = torch.cat([pre_feat, pre_tsdf, pre_occ], dim=1)
if i == self.cfg.N_LAYER - 1:
outputs['coords'] = pre_coords
outputs['tsdf'] = pre_tsdf
return outputs, loss_dict 代码链接:https://pan.baidu.com/s/1HnZUMJuX0ejYAN6Pcd3ESg?pwd=uqrb
提取码:uqrb