Python爬虫——片库网 爬取 视频
片库url:http://tv.cnco.me/
一、进入网站
二、输入关键字跳转界面
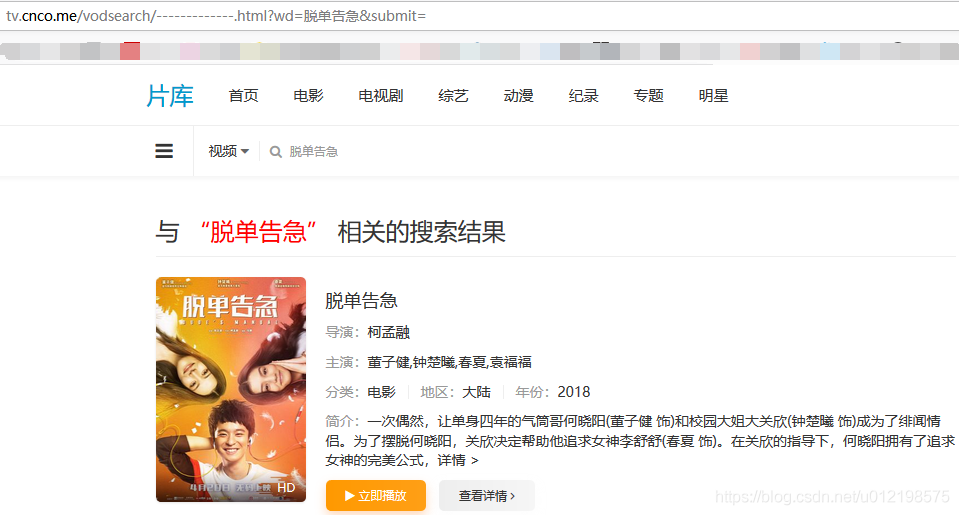
格式:
url = "http://tv.cnco.me/"
search_keyword = '脱单告急'
search_url = url + "vodsearch/-------------.html?wd=" + search_keyword + '&submit='三、点击立即播放进入播放界面
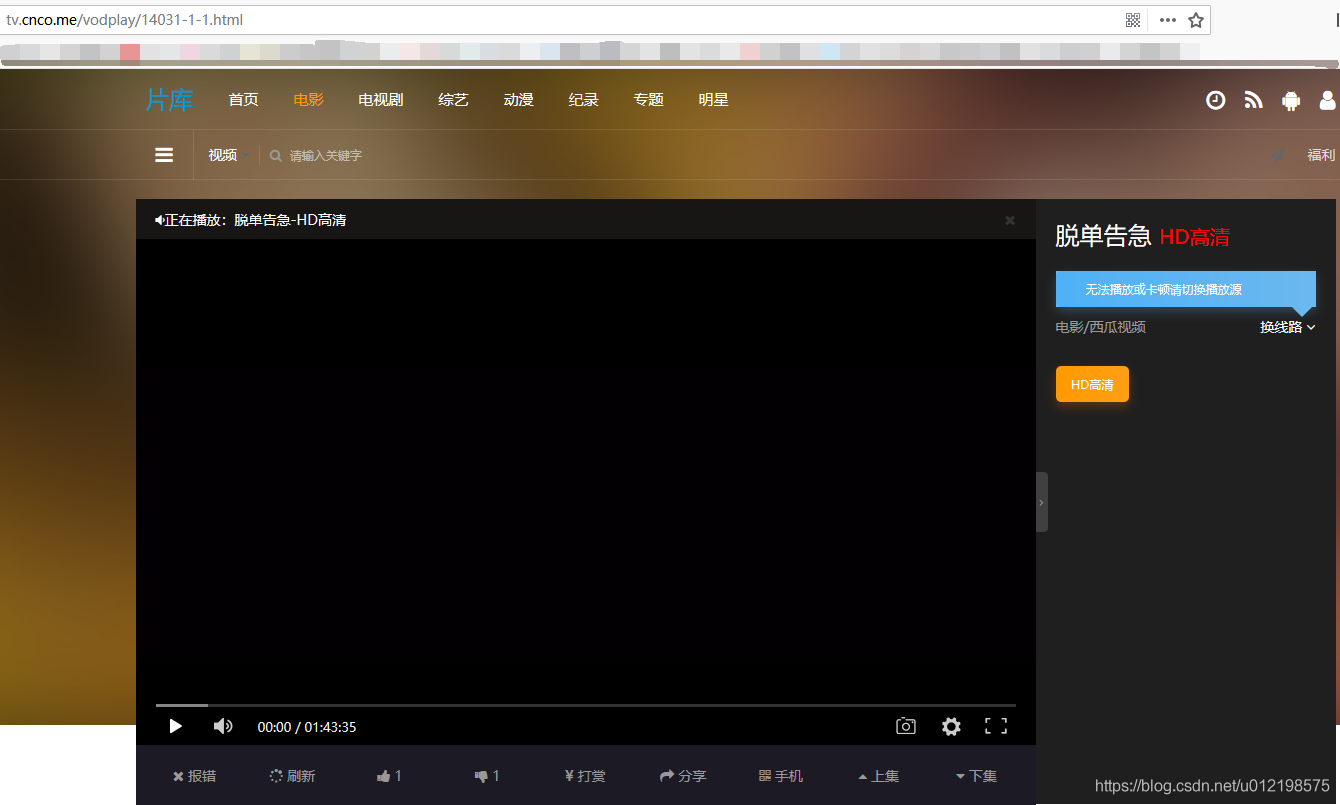
导入BeautifulSoup模块
获取该视频的网址:在上个界面按下F12,利用查看器点击立即播放。得到播放网站
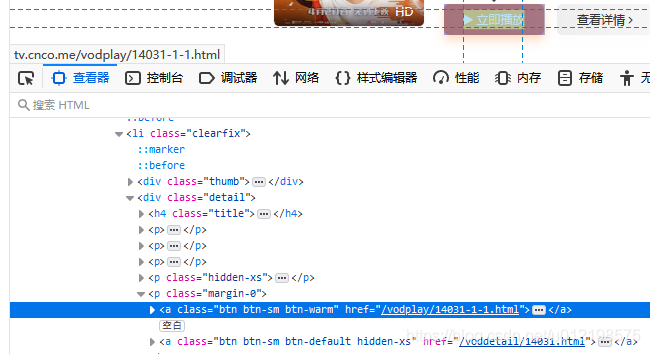
url = "http://tv.cnco.me/"
search_keyword = '脱单告急'
search_url = url + "vodsearch/-------------.html?wd=" + search_keyword + '&submit='
def find_url(search_url):
r = requests.get(search_url)
r.encoding = 'utf-8'
html = r.text
bs = BeautifulSoup(html, 'lxml')
search_bs = bs.find_all(class_='margin-0')
href = ""
for s in search_bs:
if s.a:
print(s.a)
href = s.a['href']
dst_url = url + href
return dst_url在播放页面按下F12,点开网络选项,看到传输的视频格式为m3u8
 解释下m3u8:
解释下m3u8:
现在很多视频都是分段存储的,你看视频的时候,其实是在加载一个个 ts 视频片段,一个片段是几秒钟的视频。
这种视频要怎么下载?怎么将 ts 视频片段组合成一个视频?
其实,如果知道方法,就很简单。
m3u8 这种格式的视频,就是由一个个 ts 视频片段组成的。
一个 m3u8 文件并不大,你可以把它理解为链表,每个 ts 视频片段文件,都有下一个时序的 ts 视频片段的地址。

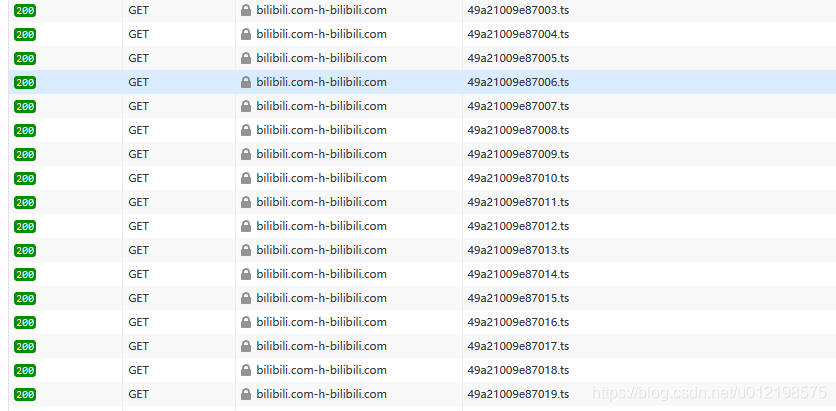
搜索m3u8找到对应的第一级m3u8的url,第一级你可以直接下载
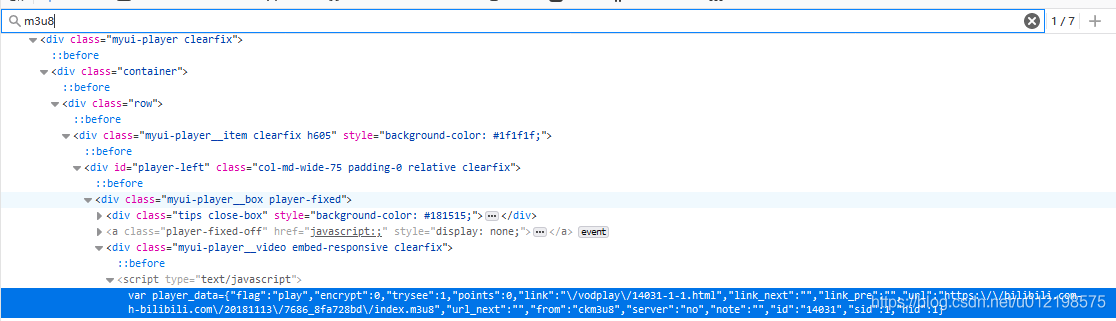

可以看到是一个ts文件序列,这便是第二级url,需要将每个ts拼接上前面的url即可
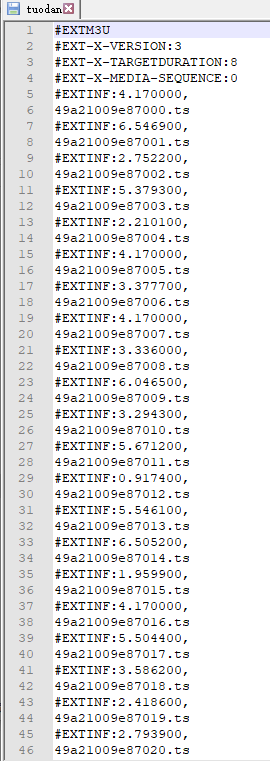
最后下载和保存成MP4格式
附上代码:
import requests
from bs4 import BeautifulSoup
import os
from multiprocessing.dummy import Pool as ThreadPool
url = "http://tv.cnco.me/"
search_keyword = '脱单告急'
search_url = url + "vodsearch/-------------.html?wd=" + search_keyword + '&submit='
global_m3u8_url_2 = '' #第二级m3u8的url
global_downloaded_num = 0 #已经下载ts文件个数
global_down_all_num = 0 #下载所有ts文件个数
root = 'movie' #保存根路径
def find_url(search_url):
r = requests.get(search_url)
r.encoding = 'utf-8'
html = r.text
bs = BeautifulSoup(html, 'lxml')
search_bs = bs.find_all(class_='margin-0')
href = ""
for s in search_bs:
if s.a:
print(s.a)
href = s.a['href']
dst_url = url + href
return dst_url
# 寻找字符串s中最后出现字符c的index
def findLastchr(s, c):
ls = []
sum = 0
while True:
i = s.find(c)
if i != -1:
s = s[i+1:]
ls.append(i)
else:
break
for i in range(len(ls)):
sum += (ls[i] + 1)
return sum - 1
# 字符(十六进制)转ASCII码
def hexToAscii(h):
d = int(h,16) # 转成十进制
return chr(d) # 转成ASCII码
# 从得到的html代码中获取m3u8链接(不同网站有区别)
def getM3u8(http_s):
detail_bs = BeautifulSoup(http_s, 'lxml')
#print(detail_bs)
search_bs = detail_bs.find_all(type='text/javascript')
#print(search_bs)
for each_script in search_bs:
value = each_script.string
value = str(value)
index1 = value.find('var player_data=')
num = len('var player_data=')
index2 = findLastchr(value, '\n')
if index1 != -1:
#print(index1)
#print(index2)
string = value[index1 + num : index2] + '}'
print(string)
dict = eval(string)
ret = str(dict['url']).replace('\\', '')
print(ret)
return ret
def getM3u8_2(m3u8_url_1):
r1 = requests.get(m3u8_url_1)
r1.raise_for_status()
text = r1.text
print(text)
idx = findLastchr(text, '\n')
key = text[idx + 1:] # 得到第一层m3u8中的key
idx = findLastchr(m3u8_url_1, '/')
m3u8_url_2 = m3u8_url_1[:idx + 1] + key # 组成第二层的m3u8链接
return m3u8_url_2
def getTsFile(url, filename):
try:
url = find_url(search_url)
r = requests.get(url)
r.encoding = "utf-8"
r.raise_for_status()
http_s = r.text
#print(http_s)
m3u8_url_1 = getM3u8(http_s)
print("第一层m3u8链接" + m3u8_url_1)
m3u8_url_2 = getM3u8_2(m3u8_url_1)
print("第二层m3u8链接" + m3u8_url_2)
global global_m3u8_url_2
global_m3u8_url_2 = m3u8_url_2
print('global : ', global_m3u8_url_2)
# 通过新的m3u8链接,获取真正的ts播放列表
# 由于列表比较长,为他创建一个txt文件
r2 = requests.get(m3u8_url_2)
f = open(filename, "w", encoding="utf-8") # 这里要改成utf-8编码,不然默认gbk
f.write(r2.text)
f.close()
print("创建ts列表文件成功")
return "success"
except:
print("爬取失败")
return "failed"
# 提取ts列表文件的内容,逐个拼接ts的url,形成list
def getPlayList(filename, m3u8_url_2):
ls = []
f = open(filename, "r")
line = " " # line不能为空,不然进不去下面的循环
idx = findLastchr(m3u8_url_2, '/')
while line:
line = f.readline()
if line != '' and line[0] != '#':
line = m3u8_url_2[:idx+1] + line
ls.append(line[:-1]) # 去掉'\n'
print(ls)
return ls
# 批量下载ts文件
def loadTs(i):
global root
#print(i)
#root = "movie"
#length = len(ls)
try:
if not os.path.exists(root):
os.mkdir(root)
tsname = i.split('/')[-1][11:]
#print(tsname)
path = root + "\\" + tsname
r = requests.get(i)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
global global_downloaded_num
global_downloaded_num+= 1
print('\n' + tsname + " -->OK ({}/{}){:.2f}%".format(global_downloaded_num, global_down_all_num, global_downloaded_num*100/global_down_all_num), end='')
except:
print("批量下载失败")
def file_walker(path):
file_list = []
for root, dirs, files in os.walk(path): # 生成器
for fn in files:
p = str(root + '/' + fn)
file_list.append(p)
file_list.sort(key = lambda x: int(x[6:-3])) #排序 防止视频拼接顺序错误
print(file_list)
return file_list
# 将所有下载好的ts文件组合成一个文件
# ts_path: 下载好的一堆ts文件的文件夹
# combine_path: 组合好的文件的存放位置
# file_name: 组合好的视频文件的文件名
def combine(ts_path, combine_path, file_name):
file_list = file_walker(ts_path)
file_path = combine_path + file_name + '.mp4'
with open(file_path, 'wb+') as fw:
for i in range(len(file_list)):
fw.write(open(file_list[i], 'rb').read())
if __name__ == "__main__":
getTsFile(url, "tuodan") #"tuodan"是ts列表文件
ls = getPlayList("tuodan", global_m3u8_url_2)
ls_len = len(ls)
global_down_all_num = ls_len
pool = ThreadPool(8) #开8个线程下载快
results = pool.map(loadTs, ls)
pool.close()
pool.join()
loadTs(ls)
combine('movie', "movie/", "tuodan")
最后,看下效果
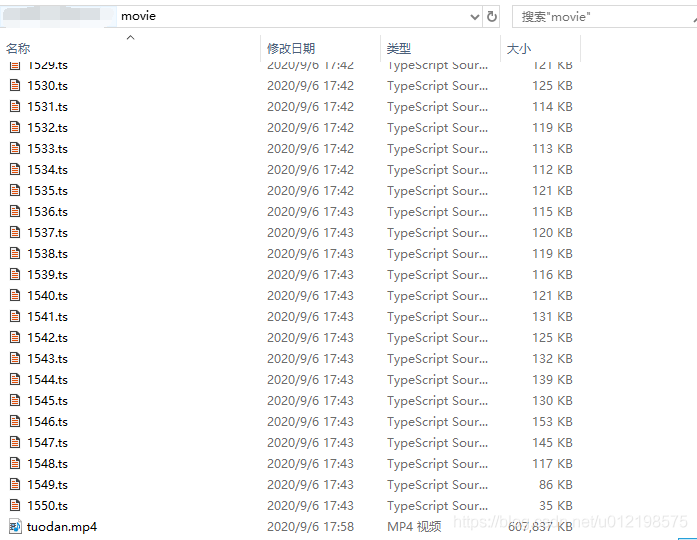
大家快去试试把,代码亲测有效。