【mmrotate代码解读】以FasterRcnn中的RPN+ROI部分为例
文章目录
1.RPN部分的代码
我们首先定位到RPN部分代码的forward_train部分,位于two_stage.py文件下
经历了Resnet50和FPN两部分的操作后,我们得到了如下的向量:

下面我们要对特征向量进行RPN操作。
if self.with_rpn:
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
rpn_losses, proposal_list = self.rpn_head.forward_train(
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=gt_bboxes_ignore,
proposal_cfg=proposal_cfg,
**kwargs)
losses.update(rpn_losses)
else:
proposal_list = proposals
1.1 rpn_head.forward_train的代码(base_dense_head.py)
可以发现,主要代码位于self.rpn_head.forward_train这个函数,我们来看其定义,位于base_dense_head.py文件下
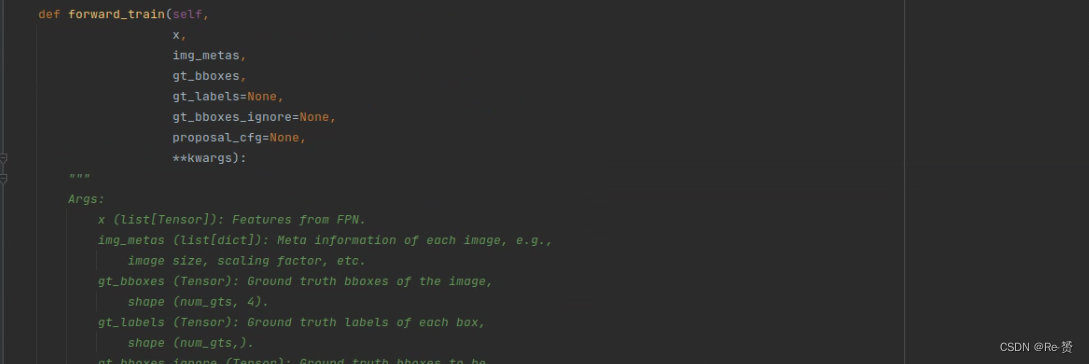
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): Features from FPN.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): A dictionary of loss components.
proposal_list (list[Tensor]): Proposals of each image.
"""
函数的第一句调用了如下的函数
outs = self(x)
这个self是预先定义好的,定义在rotated_rpn_head.py文件下
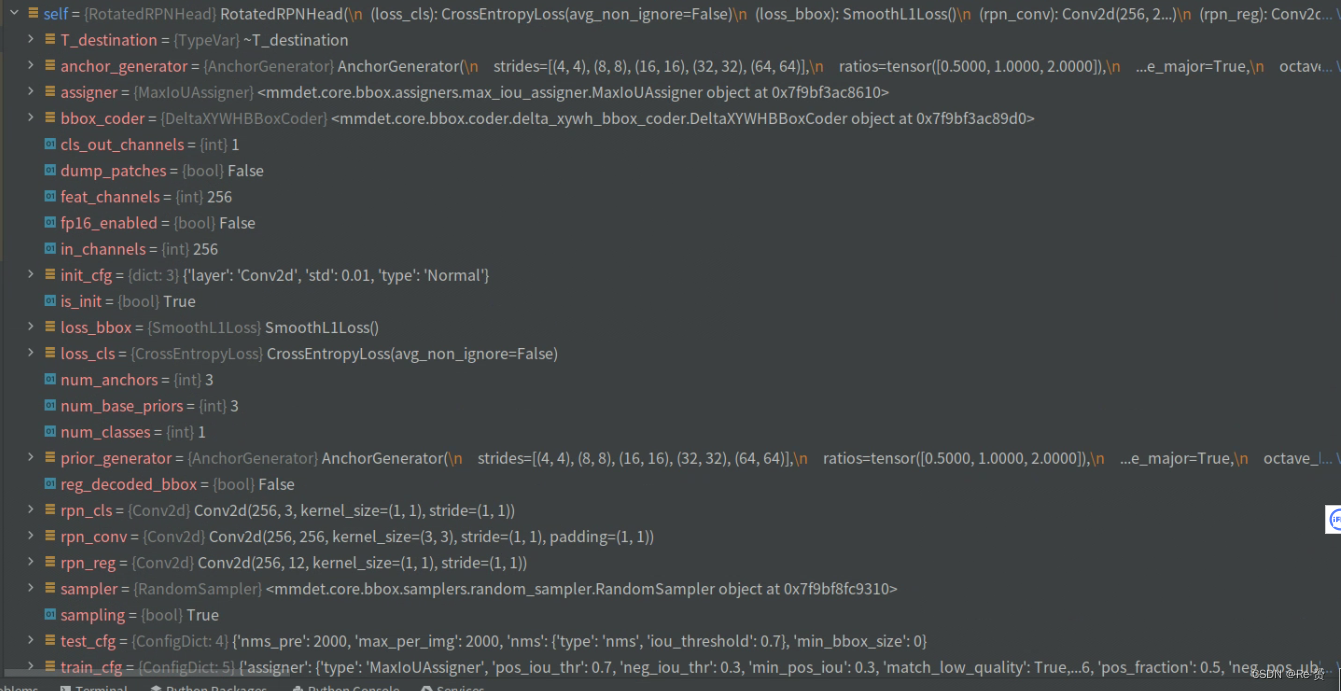
def _init_layers(self):
"""Initialize layers of the head."""
self.rpn_conv = nn.Conv2d(
self.in_channels, self.feat_channels, 3, padding=1)
self.rpn_cls = nn.Conv2d(self.feat_channels,
self.num_anchors * self.cls_out_channels, 1)
self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
def forward_single(self, x):
"""Forward feature map of a single scale level."""
x = self.rpn_conv(x)
x = F.relu(x, inplace=True)
rpn_cls_score = self.rpn_cls(x)
rpn_bbox_pred = self.rpn_reg(x)
return rpn_cls_score, rpn_bbox_pred
将FPN得到的5个特征值进行了卷积操作,将outs对结果和gt_bboxes和img_meta组合成一个元组,其中outs是维度为3和12的向量。
其中3的含义是每一个特征点产生3个anchor,每一个anchor进行0、1分类,所以self.num_anchors * self.cls_out_channels为 1 * 3为3
其中12的含义是每一个特征点产生3个anchor,每一个anchor有4个坐标,所以 3*4为12
gt_bboxes包含了这一个图片包含的ground truth数量
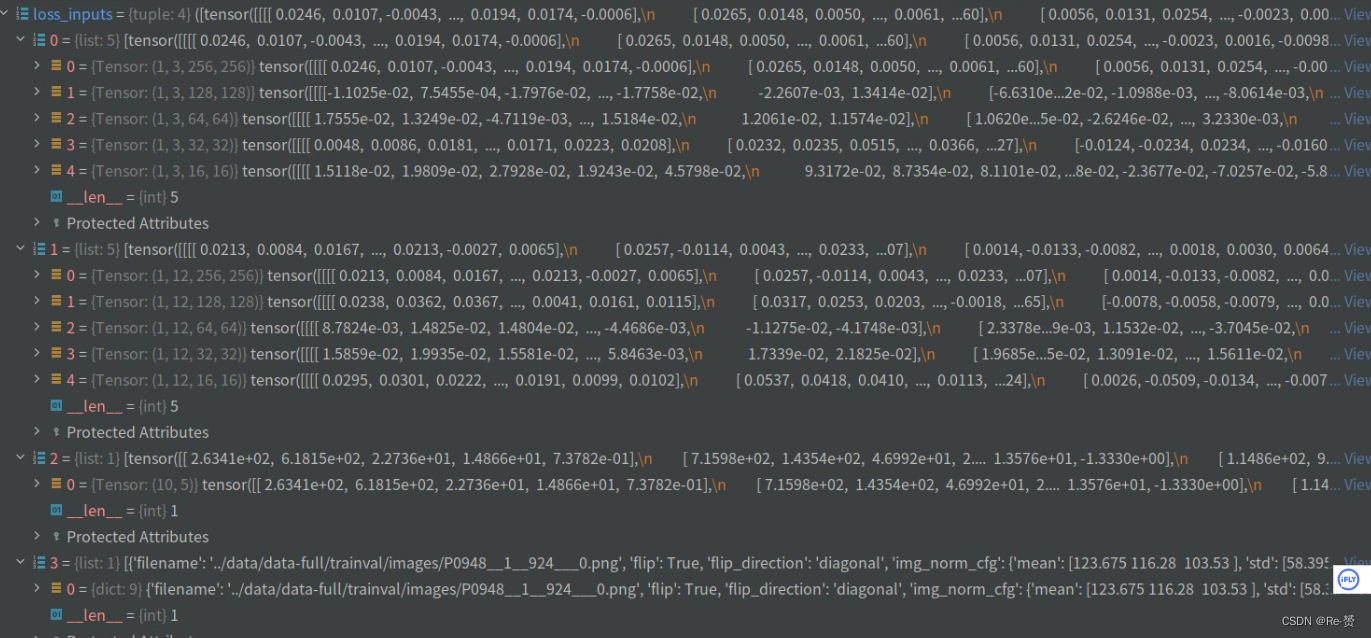
经历了以上处理后,函数将整合的结果送入了self.loss函数中进行损失计算(详见1.2)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
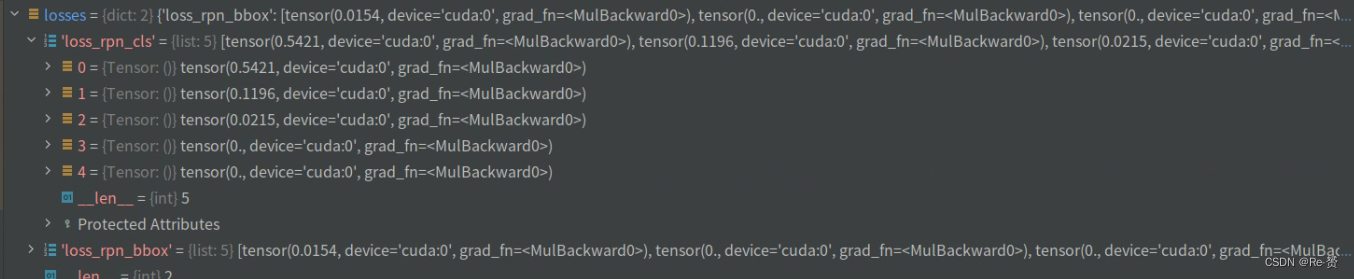
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(
*outs, img_metas=img_metas, cfg=proposal_cfg)
return losses, proposal_list
如果 proposal_cfg 为 None,则直接返回 losses,即损失。
否则,生成候选框列表 proposal_list(详见1.3)
1.2 self.loss的代码(rotated_rpn_head.py)
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 5, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 5) in [cx, cy, w, h, a] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss. Default: None
Returns:
dict[str, Tensor]: A dictionary of loss components.
来看具体的代码实现
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
assert len(featmap_sizes) == self.anchor_generator.num_levels
获取分类分数张量 cls_scores 中每个特征图的尺寸,并与锚框生成器的层数进行检查。

下面的代码调用了get_anchors方法,其定义位于anchor_head.py下,详见1.2.1章节
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas, device=device)
调用 get_anchors 方法来生成锚框列表 anchor_list 和有效标志列表 valid_flag_list


label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
如果模型使用 sigmoid 函数作为分类器的激活函数。则 值为 self.cls_out_channels
如果模型使用 softmax 函数作为分类器的激活函数,则 label_channels 的值为 1
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=None,
label_channels=label_channels)
根据输入的锚框、有效标志、真实边界框等信息计算得到的分类和回归目标(详见1.2.2)

(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
num_total_samples = (
num_total_pos + num_total_neg if self.sampling else num_total_pos)
将cls_reg_targets中的元素解包赋值给labels_list、label_weights_list、bbox_targets_list、bbox_weights_list、num_total_pos和num_total_neg

num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
# concat all level anchors and flags to a single tensor
concat_anchor_list = []
for i, _ in enumerate(anchor_list):
concat_anchor_list.append(torch.cat(anchor_list[i]))
all_anchor_list = images_to_levels(concat_anchor_list,
num_level_anchors)
首先计算每个级别anchors的数量
然后,将每个图像的anchors拼接成一个单独的张量,保存在concat_anchor_list列表中
使用images_to_levels函数将concat_anchor_list转换为按级别分组的anchors列表


losses_cls, losses_bbox = multi_apply(
self.loss_single,
cls_scores,
bbox_preds,
all_anchor_list,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_samples)
把loss_single函数应用到每个级别的分类得分、边界框预测值、anchors、标签、标签权重、边界框目标和边界框权重上,以计算分类和边界框损失
详见(1.2.3)
1.2.1 get_anchors的代码(anchor_head.py)
def get_anchors(self, featmap_sizes, img_metas, device='cuda'):
"""Get anchors according to feature map sizes.
Args:
featmap_sizes (list[tuple]): Multi-level feature map sizes.
img_metas (list[dict]): Image meta info.
device (torch.device | str): Device for returned tensors
Returns:
tuple:
anchor_list (list[Tensor]): Anchors of each image.
valid_flag_list (list[Tensor]): Valid flags of each image.
"""
num_imgs = len(img_metas)
# since feature map sizes of all images are the same, we only compute
# anchors for one time
multi_level_anchors = self.prior_generator.grid_priors(
featmap_sizes, device=device)
anchor_list = [multi_level_anchors for _ in range(num_imgs)]
# for each image, we compute valid flags of multi level anchors
valid_flag_list = []
for img_id, img_meta in enumerate(img_metas):
multi_level_flags = self.prior_generator.valid_flags(
featmap_sizes, img_meta['pad_shape'], device)
valid_flag_list.append(multi_level_flags)
return anchor_list, valid_flag_list
首先获取输入图像的数量
然后通过self.prior_generator.grid_priors(详见1.2.1.1 )生成多层级的锚框
接着通过调用 self.prior_generator.valid_flags计算多层级锚框的有效标志
最后返回 anchor_list 和 valid_flag_list
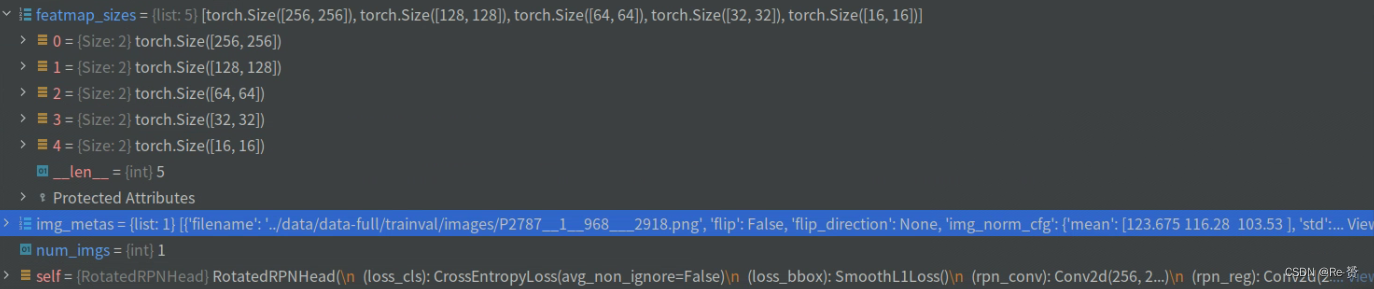
看一下anchor_lis的结果

关于valid_flag_list的代码我们就不细看了,这个主要是为了判断哪些anchor是有效的,看一下结果

1.2.1.1 grid_priors的代码(anchor_generator.py)
def grid_priors(self, featmap_sizes, dtype=torch.float32, device='cuda'):
"""Generate grid anchors in multiple feature levels.
Args:
featmap_sizes (list[tuple]): List of feature map sizes in
multiple feature levels.
dtype (:obj:`torch.dtype`): Dtype of priors.
Default: torch.float32.
device (str): The device where the anchors will be put on.
Return:
list[torch.Tensor]: Anchors in multiple feature levels. \
The sizes of each tensor should be [N, 4], where \
N = width * height * num_base_anchors, width and height \
are the sizes of the corresponding feature level, \
num_base_anchors is the number of anchors for that level.
"""
assert self.num_levels == len(featmap_sizes)
multi_level_anchors = []
for i in range(self.num_levels):
anchors = self.single_level_grid_priors(
featmap_sizes[i], level_idx=i, dtype=dtype, device=device)
multi_level_anchors.append(anchors)
return multi_level_anchors
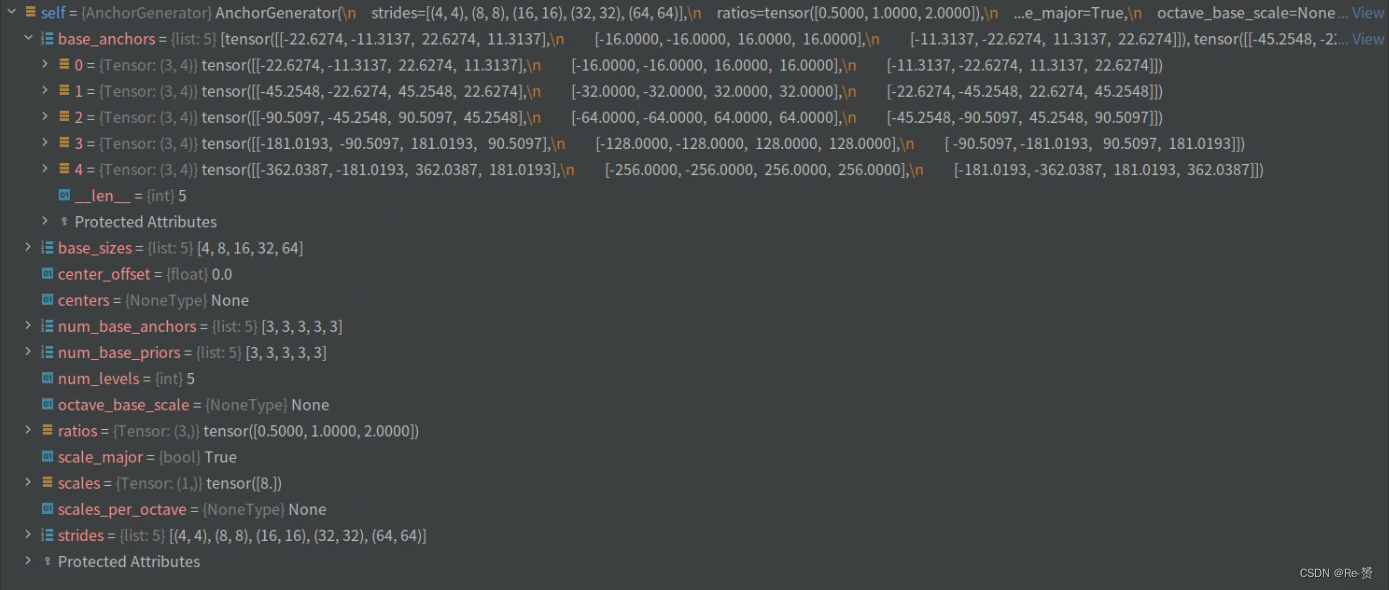
代码定义了一个名为grid_priors的方法,用于在多个特征级别生成网格锚点
主要的操作位于single_level_grid_priors函数中,详见1.2.1.2
这个函数位于anchor_generator类当中,这是我们初始化anchor的函数,看一下这个类的基本结构
1.2.1.2 single_level_grid_priors的代码(anchor_generator.py)
def single_level_grid_priors(self,
featmap_size,
level_idx,
dtype=torch.float32,
device='cuda'):
"""Generate grid anchors of a single level.
Note:
This function is usually called by method ``self.grid_priors``.
Args:
featmap_size (tuple[int]): Size of the feature maps.
level_idx (int): The index of corresponding feature map level.
dtype (obj:`torch.dtype`): Date type of points.Defaults to
``torch.float32``.
device (str, optional): The device the tensor will be put on.
Defaults to 'cuda'.
Returns:
torch.Tensor: Anchors in the overall feature maps.
"""
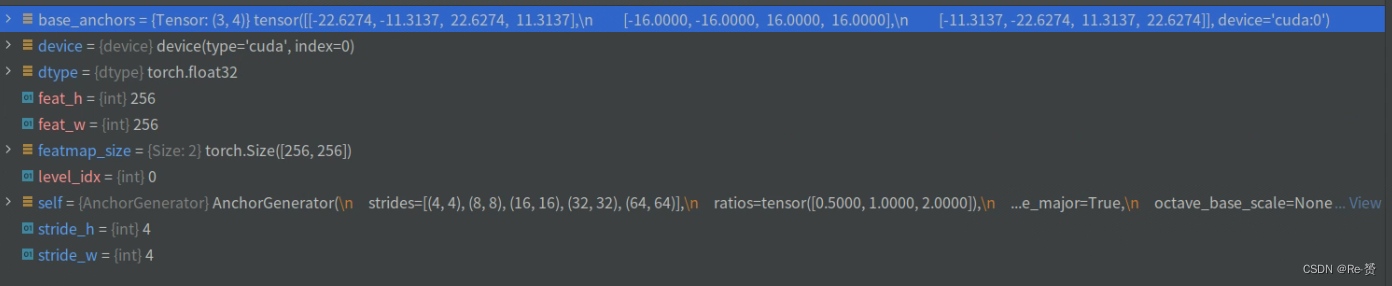
因为函数输入每个特征维度的特征长度,我们以第一个维度256 x 256的大小来研究
base_anchors = self.base_anchors[level_idx].to(device).to(dtype)
feat_h, feat_w = featmap_size
stride_w, stride_h = self.strides[level_idx]
从self.base_anchors中获取对应特征图层级的基础先验框,base_anchors的得到详见1.2.1.3
从featmap_size中获取特征图的高度和宽度
从self.strides中获取对应特征图层级的步长。
shift_x = torch.arange(0, feat_w, device=device).to(dtype) * stride_w
shift_y = torch.arange(0, feat_h, device=device).to(dtype) * stride_h
使用torch.arange函数生成在设备上的等差数列,作为先验框的偏移量。
shift_x表示水平方向的偏移量,shift_y表示垂直方向的偏移量

shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
调用self._meshgrid方法生成两个网格矩阵shift_xx和shift_yy用于组合成所有的偏移量

all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
all_anchors = all_anchors.view(-1, 4)
return all_anchors
将基础先验框和偏移量相加,得到所有的先验框

all_anchors为196608的原因: 256 x 256 x 3,其余的特征值大小也同样处理
1.2.1.3 gen_single_level_base_anchors(anchor_generator.py)
def gen_single_level_base_anchors(self,
base_size,
scales,
ratios,
center=None):
"""Generate base anchors of a single level.
Args:
base_size (int | float): Basic size of an anchor.
scales (torch.Tensor): Scales of the anchor.
ratios (torch.Tensor): The ratio between between the height
and width of anchors in a single level.
center (tuple[float], optional): The center of the base anchor
related to a single feature grid. Defaults to None.
Returns:
torch.Tensor: Anchors in a single-level feature maps.
"""
w = base_size
h = base_size
if center is None:
x_center = self.center_offset * w
y_center = self.center_offset * h
else:
x_center, y_center = center
算基础先验框的宽度w和高度h
如果center参数为None,则使用self.center_offset乘以w和h来计算基础先验框的中心位置x_center和y_center
如果center参数不为None,则直接使用给定的中心位置center。

h_ratios = torch.sqrt(ratios)
w_ratios = 1 / h_ratios
if self.scale_major:
ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
else:
ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
根据ratios计算先验框的高度比例h_ratios,然后根据高度比例计算宽度比

base_anchors = [
x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws,
y_center + 0.5 * hs
]
base_anchors = torch.stack(base_anchors, dim=-1)
根据先验框的中心位置和宽度、高度计算基础先验框的坐标,所以最后返回到4个值含义是:
首先,通过将中心位置x_center减去宽度的一半0.5 * ws,得到基础先验框的左上角x坐标。
然后,通过将中心位置y_center减去高度的一半0.5 * hs,得到基础先验框的左上角y坐标。
接着,通过将中心位置x_center加上宽度的一半0.5 * ws,得到基础先验框的右下角x坐标。
最后,通过将中心位置y_center加上高度的一半0.5 * hs,得到基础先验框的右下角y坐标。

1.2.2 get_targets的代码(rotated_rpn_head.py)
def get_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None,
label_channels=1,
unmap_outputs=True,
return_sampling_results=False):
Args:
anchor_list (list[list[Tensor]]): Multi level anchors of each
image. The outer list indicates images, and the inner list
corresponds to feature levels of the image. Each element of
the inner list is a tensor of shape (num_anchors, 4).
valid_flag_list (list[list[Tensor]]): Multi level valid flags of
each image. The outer list indicates images, and the inner list
corresponds to feature levels of the image. Each element of
the inner list is a tensor of shape (num_anchors, )
gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image.
img_metas (list[dict]): Meta info of each image.
gt_bboxes_ignore_list (list[Tensor]): Ground truth bboxes to be
ignored.
gt_labels_list (list[Tensor]): Ground truth labels of each box.
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple: Usually returns a tuple containing learning targets.
- labels_list (list[Tensor]): Labels of each level.
- label_weights_list (list[Tensor]): Label weights of each \
level.
- bbox_targets_list (list[Tensor]): BBox targets of each level.
- bbox_weights_list (list[Tensor]): BBox weights of each level.
- num_total_pos (int): Number of positive samples in all \
images.
- num_total_neg (int): Number of negative samples in all \
images.
additional_returns: This function enables user-defined returns from
`self._get_targets_single`. These returns are currently refined
to properties at each feature map (i.e. having HxW dimension).
The results will be concatenated after the end
首先看一下我们传入的参数
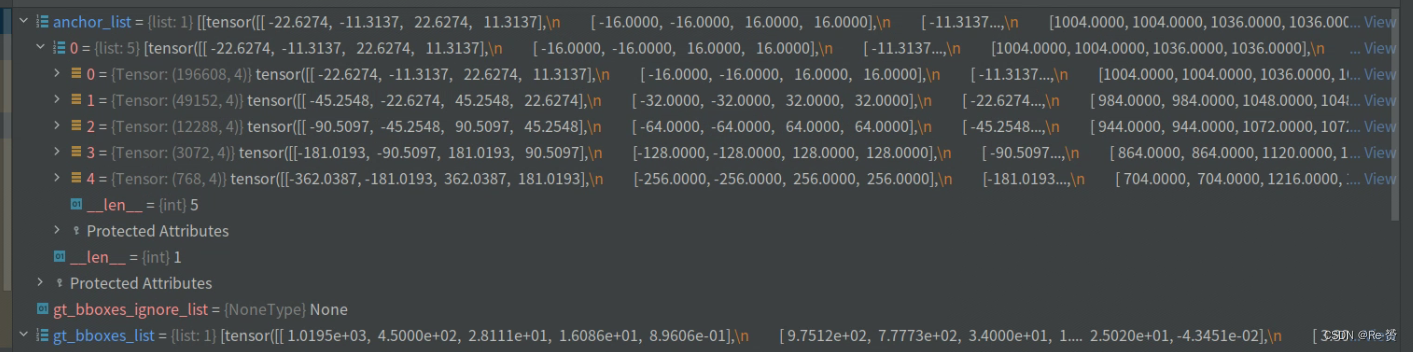
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
通过遍历anchor_list[0]中的每个特征层的锚框张量
获取每个张量的第一个维度大小(锚框数量),并将其添加到列表中

concat_anchor_list = []
concat_valid_flag_list = []
for i in range(num_imgs):
assert len(anchor_list[i]) == len(valid_flag_list[i])
concat_anchor_list.append(torch.cat(anchor_list[i]))
concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
首先将anchor_list[i]中的每个特征层的锚框张量连接起来
并将连接后的结果添加到concat_anchor_list中。
这样,concat_anchor_list中的每个元素都是一个包含所有特征层锚框的张量。
同样地使concat_valid_flag_list中的每个元素都是一个包含所有特征层有效标志的张量

if gt_bboxes_ignore_list is None:
gt_bboxes_ignore_list = [None for _ in range(num_imgs)]
if gt_labels_list is None:
gt_labels_list = [None for _ in range(num_imgs)]
处理gt_bboxes_ignore_list和gt_labels_list的默认值
results = multi_apply(
self._get_targets_single,
concat_anchor_list,
concat_valid_flag_list,
gt_bboxes_list,
gt_bboxes_ignore_list,
gt_labels_list,
img_metas,
label_channels=label_channels,
unmap_outputs=unmap_outputs)
将_get_targets_single函数应用于每个图像的锚框和相应的标签信息(详见1.2.2.1)

(all_labels, all_label_weights, all_bbox_targets, all_bbox_weights,
pos_inds_list, neg_inds_list, sampling_results_list) = results[:7]
rest_results = list(results[7:]) # user-added return values
从results中解包获取了多项返回结果
all_labels:所有样本的标签,形状为(num_total_anchors,),包含了正样本和负样本的标签信息。
all_label_weights:所有样本的标签权重,形状为(num_total_anchors,),用于在训练中调整正样本和负样本的权重。
all_bbox_targets:所有样本的回归目标,形状为(num_total_anchors, 4),包含了正样本的回归目标值,负样本的回归目标值为0。
all_bbox_weights:所有样本的回归权重,形状为(num_total_anchors, 4),用于在训练中调整正样本和负样本的回归权重。
pos_inds_list:正样本的索引列表,每个元素是一个形状为(num_pos_samples,)的张量,表示每个样本中被选中的正样本的索引。
neg_inds_list:负样本的索引列表,每个元素是一个形状为(num_neg_samples,)的张量,表示每个样本中被选中的负样本的索引。
sampling_results_list:采样结果列表,每个元素是一个采样结果对象,包含了正样本和负样本的信息。
all_labels:

all_label_weights:

all_bbox_targets:

all_bbox_weights:

pos_inds_list:

neg_inds_list:

sampling_results_list:
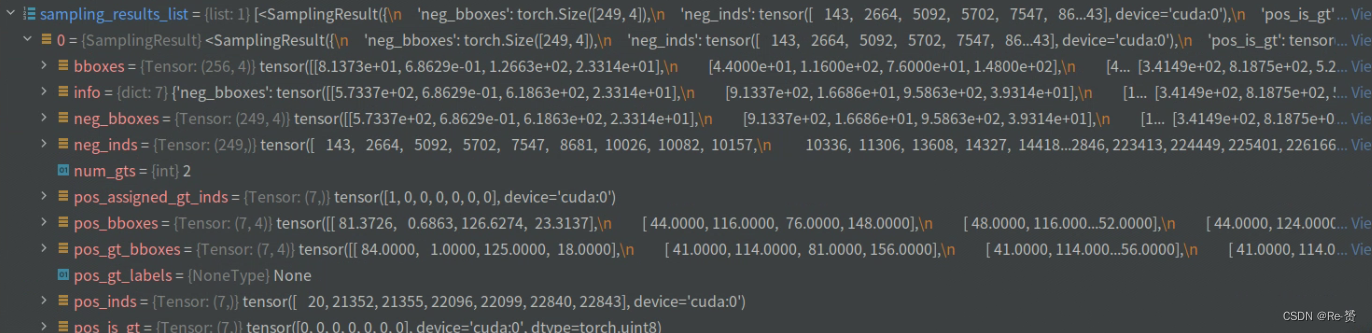
num_total_pos = sum([max(inds.numel(), 1) for inds in pos_inds_list])
num_total_neg = sum([max(inds.numel(), 1) for inds in neg_inds_list])
num_total_pos表示所有图像中的正样本数量
num_total_neg表示所有图像中的负样本数

labels_list = images_to_levels(all_labels, num_level_anchors)
label_weights_list = images_to_levels(all_label_weights,
num_level_anchors)
bbox_targets_list = images_to_levels(all_bbox_targets,
num_level_anchors)
bbox_weights_list = images_to_levels(all_bbox_weights,
num_level_anchors)
res = (labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, num_total_pos, num_total_neg)
labels_list是一个列表,其中每个元素对应一个特征图级别,表示该级别上的所有样本的标签
images_to_levels用于将图像的标签按照特征图级别进行分组,保证每个级别上的样本标签数量一致
剩下的与labels_list一致
res包含了所有值作为最终的学习目标返回


if return_sampling_results:
res = res + (sampling_results_list, )
for i, r in enumerate(rest_results): # user-added return values
rest_results[i] = images_to_levels(r, num_level_anchors)
如果设置了return_sampling_results为True,则将sampling_results_list添加到结果res中
1.2.2.1 _get_targets_single函数的代码(rotated_rpn_head.py)
def _get_targets_single(self,
flat_anchors,
valid_flags,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
img_meta,
label_channels=1,
unmap_outputs=True):
"""Compute regression and classification targets for anchors in a
single image.
Args:
flat_anchors (torch.Tensor): Multi-level anchors of the image,
which are concatenated into a single tensor of shape
(num_anchors ,4)
valid_flags (torch.Tensor): Multi level valid flags of the image,
which are concatenated into a single tensor of
shape (num_anchors,).
gt_bboxes (torch.Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_bboxes_ignore (torch.Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
img_meta (dict): Meta info of the image.
gt_labels (torch.Tensor): Ground truth labels of each box,
shape (num_gts,).
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple:
labels_list (list[Tensor]): Labels of each level
label_weights_list (list[Tensor]): Label weights of each level
bbox_targets_list (list[Tensor]): BBox targets of each level
bbox_weights_list (list[Tensor]): BBox weights of each level
num_total_pos (int): Number of positive samples in all images
num_total_neg (int): Number of negative samples in all images
"""
来看一下传入的参数
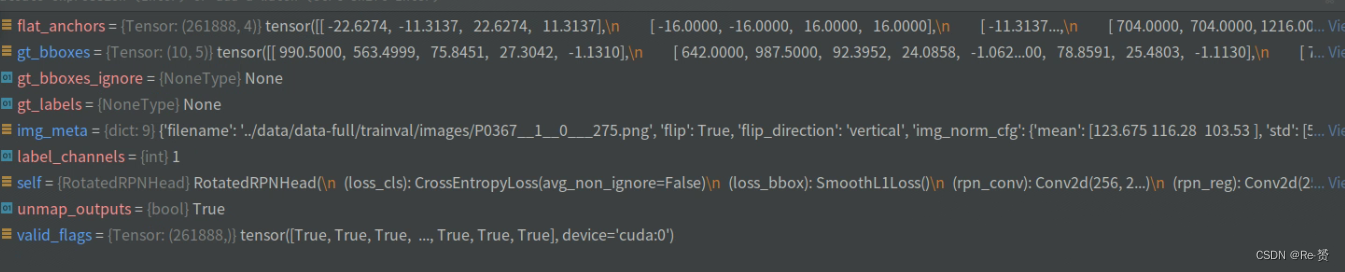
inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
img_meta['img_shape'][:2],
self.train_cfg.allowed_border)
使用anchor_inside_flags函数对锚框进行筛选,将位于图像内部的锚框标记为有效


gt_hbboxes = obb2xyxy(gt_bboxes, self.version)
使用obb2xyxy函数将真实框的表示从旋转框转换为水平框

assign_result = self.assigner.assign(
anchors, gt_hbboxes, gt_bboxes_ignore,
None if self.sampling else gt_labels)
sampling_result = self.sampler.sample(assign_result, anchors,
gt_hbboxes)
使用目标分配器对锚框(anchors)和真实框(gt_hbboxes)进行目标分配
标分配器根据预先定义的规则,将每个锚框分配给与其重叠最大的真实框,或者将其标记为背景
接下来对分配结果进行采样,从分配为正样本和负样本的锚框中选择一部分用于训练

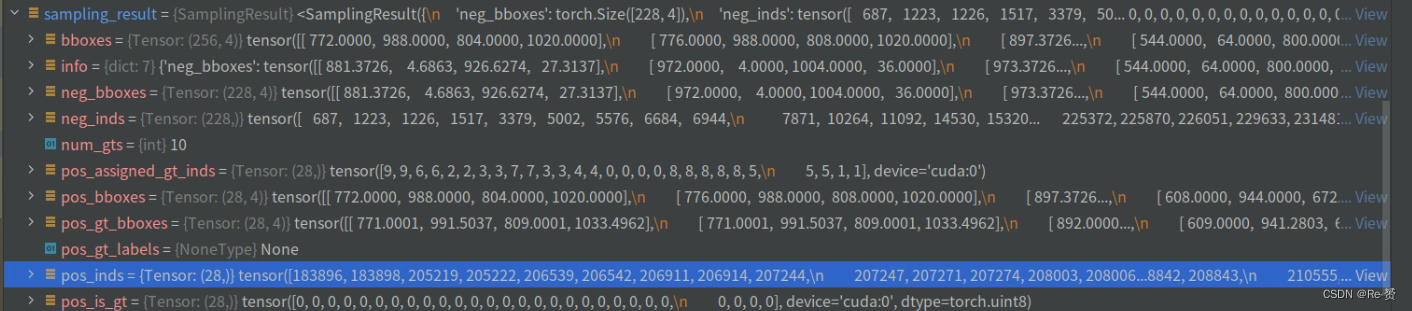
num_valid_anchors = anchors.shape[0]
bbox_targets = torch.zeros_like(anchors)
bbox_weights = torch.zeros_like(anchors)
labels = anchors.new_full((num_valid_anchors, ),
self.num_classes,
dtype=torch.long)
label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
首先获取有效锚框的数量num_valid_anchors
创建与锚框形状相同的零张量bbox_targets和bbox_weights,存储目标框的回归目标和权重
创建一个张量labels每个元素被填充为self.num_classes,表示所有锚框的默认标签都为背景
最后,创建一个零张量label_weights用于存储每个锚框的标签权重


pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
if len(pos_inds) > 0:
if not self.reg_decoded_bbox:
pos_bbox_targets = self.bbox_coder.encode(
sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
else:
pos_bbox_targets = sampling_result.pos_gt_bboxes
bbox_targets[pos_inds, :] = pos_bbox_targets
bbox_weights[pos_inds, :] = 1.0
if gt_labels is None:
labels[pos_inds] = 0
else:
labels[pos_inds] = gt_labels[
sampling_result.pos_assigned_gt_inds]
if self.train_cfg.pos_weight <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = self.train_cfg.pos_weight
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
首先获取采样结果中的正样本索引pos_inds和负样本索引neg_inds
如果存在正样本,则计算正样本的回归目标pos_bbox_targets
如果reg_decoded_bbox为False,则使用bbox_coder对正样本的预测框和目标框进行编码
如果reg_decoded_bbox为True,则直接将采样结果中的正样本目标框作为回归目标
将正样本的回归目标和权重分配给对应的bbox_targets和bbox_weights张量
如果gt_labels为None(仅在RPN阶段为None),将正样本的标签设置为0,表示前景类
最后,根据训练配置中的pos_weight设置正样本的标签权重
对于负样本,将其标签权重设置为1.0
正样本索引pos_inds和负样本索引neg_inds,本例子中pos_inds有7个,neg_inds有249个

if unmap_outputs:
num_total_anchors = flat_anchors.size(0)
labels = unmap(
labels, num_total_anchors, inside_flags,
fill=self.num_classes) # fill bg label
label_weights = unmap(label_weights, num_total_anchors,
inside_flags)
bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
neg_inds, sampling_result)
如果unmap_outputs为True,则将填充的目标信息映射回原始的anchor集合
1.2.3 loss_single函数的代码(rotated_rpn_head.py)
def loss_single(self, cls_score, bbox_pred, anchors, labels, label_weights,
bbox_targets, bbox_weights, num_total_samples):
"""Compute loss of a single scale level.
Args:
cls_score (torch.Tensor): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W).
bbox_pred (torch.Tensor): Box energies / deltas for each scale
level with shape (N, num_anchors * 5, H, W).
anchors (torch.Tensor): Box reference for each scale level with
shape (N, num_total_anchors, 4).
labels (torch.Tensor): Labels of each anchors with shape
(N, num_total_anchors).
label_weights (torch.Tensor): Label weights of each anchor with
shape (N, num_total_anchors)
bbox_targets (torch.Tensor): BBox regression targets of each anchor
weight shape (N, num_total_anchors, 5).
bbox_weights (torch.Tensor): BBox regression loss weights of each
anchor with shape (N, num_total_anchors, 4).
num_total_samples (int): If sampling, num total samples equal to
the number of total anchors; Otherwise, it is the number of
positive anchors.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
看一下传入的参数

这里我们演示的是256 x 256维度上的特征anchor loss计算
labels = labels.reshape(-1)
label_weights = label_weights.reshape(-1)
cls_score = cls_score.permute(0, 2, 3,
1).reshape(-1, self.cls_out_channels)
使用reshape函数对labels进行形状变换,将其变为一维张量
对label_weights也进行相同的操作,将其变为一维张量
对cls_score进行形状变换。使用permute函数将最后一维(类别维度)移动到倒数第二维,并使用reshape函数将其变为二维张量

loss_cls = self.loss_cls(
cls_score, labels, label_weights, avg_factor=num_total_samples)
通过调用 self.loss_cls 函数,将类别得分、真实标签、标签权重以及样本总数传递给分类损失函数进行计算

bbox_targets = bbox_targets.reshape(-1, 4)
bbox_weights = bbox_weights.reshape(-1, 4)
bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
bbox_targets 被重新调整为形状为 (-1, 4) 的二维张量
bbox_weights 也被调整为形状为 (-1, 4) 的二维张量

loss_bbox = self.loss_bbox(
bbox_pred,
bbox_targets,
bbox_weights,
avg_factor=num_total_samples)
计算边界框损失(loss_bbox)

1.3 get_bboxes的代码(rotated_rpn_head.py)
def get_bboxes(self,
cls_scores,
bbox_preds,
img_metas,
cfg=None,
rescale=False,
with_nms=True):
"""Transform network output for a batch into bbox predictions.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 5, H, W)
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
cfg (mmcv.Config | None): Test / postprocessing configuration,
if None, test_cfg would be used
rescale (bool): If True, return boxes in original image space.
Default: False.
with_nms (bool): If True, do nms before return boxes.
Default: True.
Returns:
list[tuple[Tensor, Tensor]]: Each item in result_list is 2-tuple.
The first item is an (n, 6) tensor, where the first 5 columns
are bounding box positions (cx, cy, w, h, a) and the
6-th column is a score between 0 and 1. The second item is a
(n,) tensor where each item is the predicted class label of the
corresponding box.
"""
查看参数
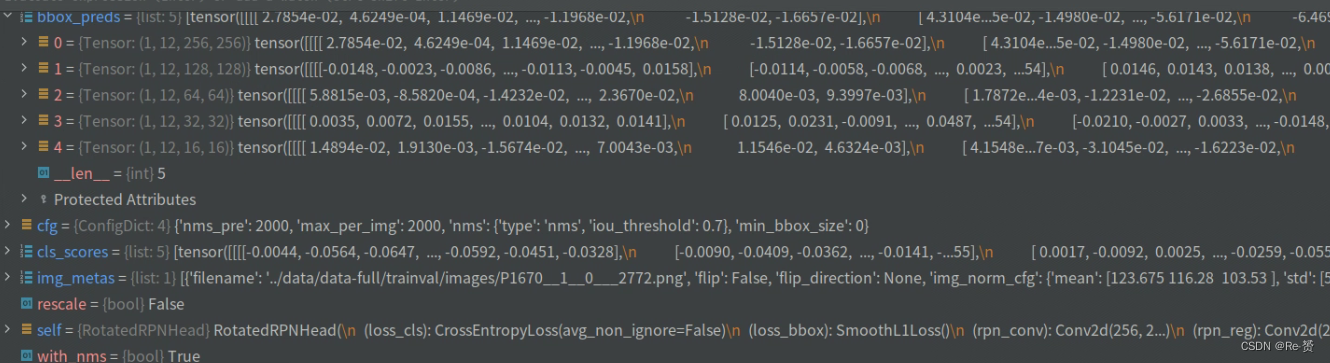
num_levels = len(cls_scores)
device = cls_scores[0].device
featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
获取了特征图的层数
使用列表推导式遍历range(num_levels),获取每个特征图的尺寸大小

mlvl_anchors = self.anchor_generator.grid_priors(
featmap_sizes, device=device)
生成多层特征图对应的锚框(详见1.2.1.1)

result_list = []
for img_id, _ in enumerate(img_metas):
cls_score_list = [
cls_scores[i][img_id].detach() for i in range(num_levels)
]
bbox_pred_list = [
bbox_preds[i][img_id].detach() for i in range(num_levels)
]
img_shape = img_metas[img_id]['img_shape']
scale_factor = img_metas[img_id]['scale_factor']
proposals = self._get_bboxes_single(cls_score_list, bbox_pred_list,
mlvl_anchors, img_shape,
scale_factor, cfg, rescale)
result_list.append(proposals)
首先根据img_id从cls_scores和bbox_preds中提取对应图像的分类分数和边界框回归结果
从img_metas中获取当前图像的形状img_shape和缩放因子scale_factor
调用self._get_bboxes_single方法计算当前图像的候选框
将proposals添加到result_list中,完成当前图像的候选框计算。
查看得到的proposals

1.3.1 _get_bboxes_single的代码(rotated_rpn_head.py)
def _get_bboxes_single(self,
cls_scores,
bbox_preds,
mlvl_anchors,
img_shape,
scale_factor,
cfg,
rescale=False):
"""Transform outputs for a single batch item into bbox predictions.
Args:
cls_scores (list[Tensor]): Box scores of all scale level
each item has shape (num_anchors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas of all
scale level, each item has shape (num_anchors * 4, H, W).
mlvl_anchors (list[Tensor]): Anchors of all scale level
each item has shape (num_total_anchors, 4).
img_shape (tuple[int]): Shape of the input image,
(height, width, 3).
scale_factor (ndarray): Scale factor of the image arrange as
(w_scale, h_scale, w_scale, h_scale).
cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used.
rescale (bool): If True, return boxes in original image space.
Default: False.
Returns:
Tensor: Labeled boxes in shape (n, 5), where the first 4 columns
are bounding box positions (cx, cy, w, h, a) and the
6-th column is a score between 0 and 1.
"""
查看传入的参数

level_ids = []
mlvl_scores = []
mlvl_bbox_preds = []
mlvl_valid_anchors = []
初始化空的列表
for idx, _ in enumerate(cls_scores):
rpn_cls_score = cls_scores[idx]
rpn_bbox_pred = bbox_preds[idx]
assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.reshape(-1)
scores = rpn_cls_score.sigmoid()
else:
rpn_cls_score = rpn_cls_score.reshape(-1, 2)
# We set FG labels to [0, num_class-1] and BG label to
# num_class in RPN head since mmdet v2.5, which is unified to
# be consistent with other head since mmdet v2.0. In mmdet v2.0
# to v2.4 we keep BG label as 0 and FG label as 1 in rpn head.
scores = rpn_cls_score.softmax(dim=1)[:, 0]
获取当前级别的分类得分
获取当前级别的边界框预测
确保分类得分和边界框预测的尺寸匹配
将分类得分的维度进行转置
如果使用sigmoid函数进行分类得分的处理:
将分类得分展平为一维
通过sigmoid函数将分类得分转换为概率值
如果不使用sigmoid函数:
将分类得分展平为二维
通过softmax函数将分类得分转换为概率值
rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1, 4)
anchors = mlvl_anchors[idx]
if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:
# sort is faster than topk
# _, topk_inds = scores.topk(cfg.nms_pre)
ranked_scores, rank_inds = scores.sort(descending=True)
topk_inds = rank_inds[:cfg.nms_pre]
scores = ranked_scores[:cfg.nms_pre]
rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
anchors = anchors[topk_inds, :]
mlvl_scores.append(scores)
mlvl_bbox_preds.append(rpn_bbox_pred)
mlvl_valid_anchors.append(anchors)
level_ids.append(
scores.new_full((scores.size(0), ), idx, dtype=torch.long))
将边界框预测的维度进行转置,并展平为二维
获取当前级别的锚框
如果配置中指定了nms_pre且得分数量超过nms_pre:
对得分进行降序排序,并返回排序后的得分和对应的索引
获取排名前nms_pre的索引
获取排名前nms_pre的得分
根据索引获取对应的边界框预测
根据索引获取对应的锚框
将处理后的得分添加到mlvl_scores列表中
将处理后的边界框预测添加到mlvl_bbox_preds列表中
将有效的锚框添加到mlvl_valid_anchors列表中


scores = torch.cat(mlvl_scores)
anchors = torch.cat(mlvl_valid_anchors)
rpn_bbox_pred = torch.cat(mlvl_bbox_preds)
proposals = self.bbox_coder.decode(
anchors, rpn_bbox_pred, max_shape=img_shape)
ids = torch.cat(level_ids)
将mlvl_scores列表中的张量沿着第0维度进行拼接,创建一个名为scores的张量
将mlvl_valid_anchors列表中的张量沿着第0维度进行拼接,创建一个名为anchors的张量
将mlvl_bbox_preds列表中的张量沿着第0维度进行拼接,创建一个名为rpn_bbox_pred的张量
使用self.bbox_coder对象的decode方法对锚点和边界框预测进行解码,生成候选框
将level_ids列表中的张量沿着第0维度进行拼接,创建一个名为ids的张量





if cfg.min_bbox_size > 0:
w = proposals[:, 2] - proposals[:, 0]
h = proposals[:, 3] - proposals[:, 1]
valid_mask = (w >= cfg.min_bbox_size) & (h >= cfg.min_bbox_size)
if not valid_mask.all():
proposals = proposals[valid_mask]
scores = scores[valid_mask]
ids = ids[valid_mask]
if proposals.numel() > 0:
dets, keep = batched_nms(proposals, scores, ids, cfg.nms)
else:
return proposals.new_zeros(0, 5)
根据配置中的cfg.min_bbox_size参数对候选框进行筛选
使用非极大值抑制(NMS)算法对候选框进行进一步筛选
2. ROI部分的代码
同样的,我们定位到forward_train函数下
def forward_train(self,
x,
img_metas,
proposal_list,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None):
"""
Args:
x (list[Tensor]): list of multi-level img features.
img_metas (list[dict]): list of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmdet/datasets/pipelines/formatting.py:Collect`.
proposals (list[Tensors]): list of region proposals.
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 5) in [cx, cy, w, h, a] format.
gt_labels (list[Tensor]): class indices corresponding to each box
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
gt_masks (None | Tensor) : true segmentation masks for each box
used if the architecture supports a segmentation task. Always
set to None.
Returns:
dict[str, Tensor]: a dictionary of loss components.
"""
看一下初始参数
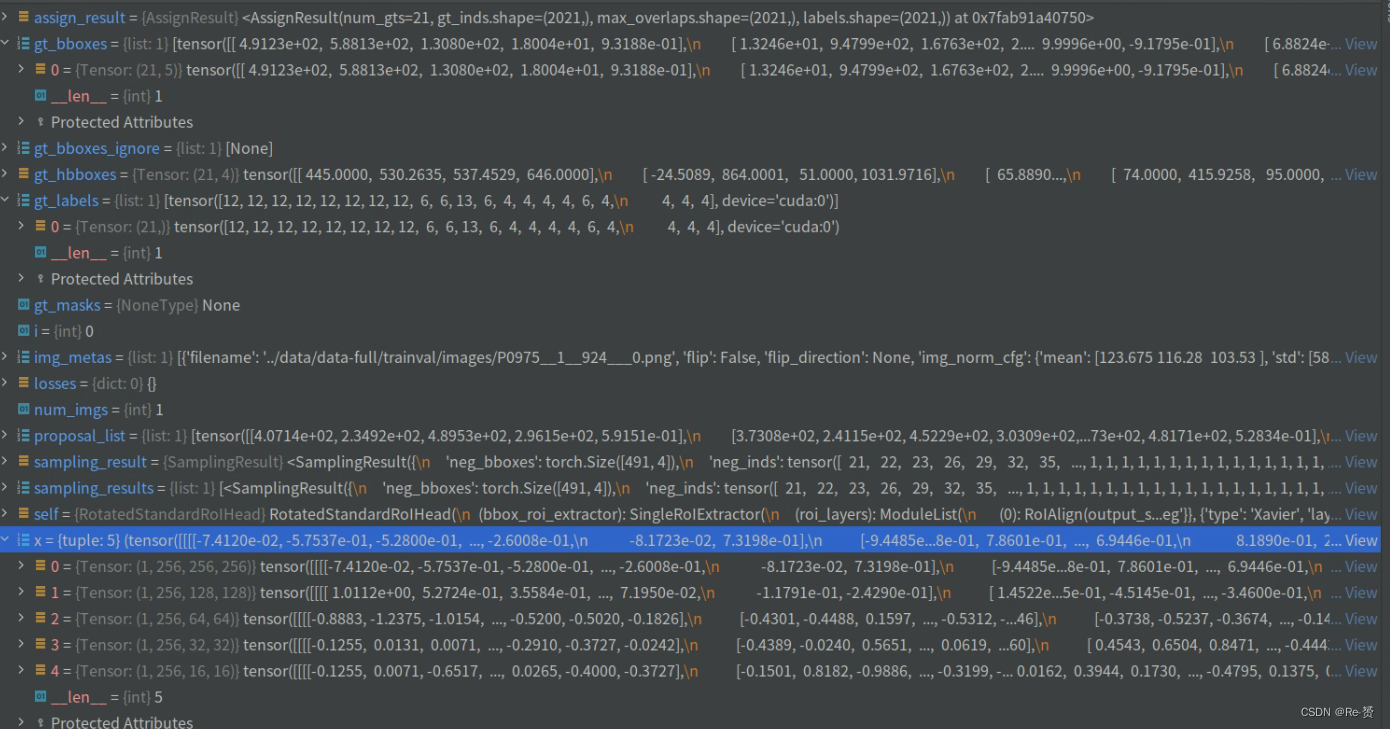
if self.with_bbox:
num_imgs = len(img_metas)
if gt_bboxes_ignore is None:
gt_bboxes_ignore = [None for _ in range(num_imgs)]
sampling_results = []
for i in range(num_imgs):
gt_hbboxes = obb2xyxy(gt_bboxes[i], self.version)
assign_result = self.bbox_assigner.assign(
proposal_list[i], gt_hbboxes, gt_bboxes_ignore[i],
gt_labels[i])
sampling_result = self.bbox_sampler.sample(
assign_result,
proposal_list[i],
gt_hbboxes,
gt_labels[i],
feats=[lvl_feat[i][None] for lvl_feat in x])
if gt_bboxes[i].numel() == 0:
sampling_result.pos_gt_bboxes = gt_bboxes[i].new(
(0, gt_bboxes[0].size(-1))).zero_()
else:
sampling_result.pos_gt_bboxes = \
gt_bboxes[i][sampling_result.pos_assigned_gt_inds, :]
sampling_results.append(sampling_result)
获取图片的数量
如果忽略的gt_bboxes_ignore,则初始化一个包含num_imgs个元素的列表,每个元素为None。
初始化采样结果列表
遍历每张图片进行采样
将真实框的格式从OBB转换为XYXY
使用bbox_assigner分配预测框和真实框之间的匹配关系,得到分配结果
使用bbox_sampler对预测框和真实框进行采样,生成采样结果
如果当前图片没有真实框,将采样结果中的正样本真实框置零
如果当前图片有真实框,根据采样结果中的正样本真实框索引获取相应的真实框
将采样结果添加到采样结果列表中
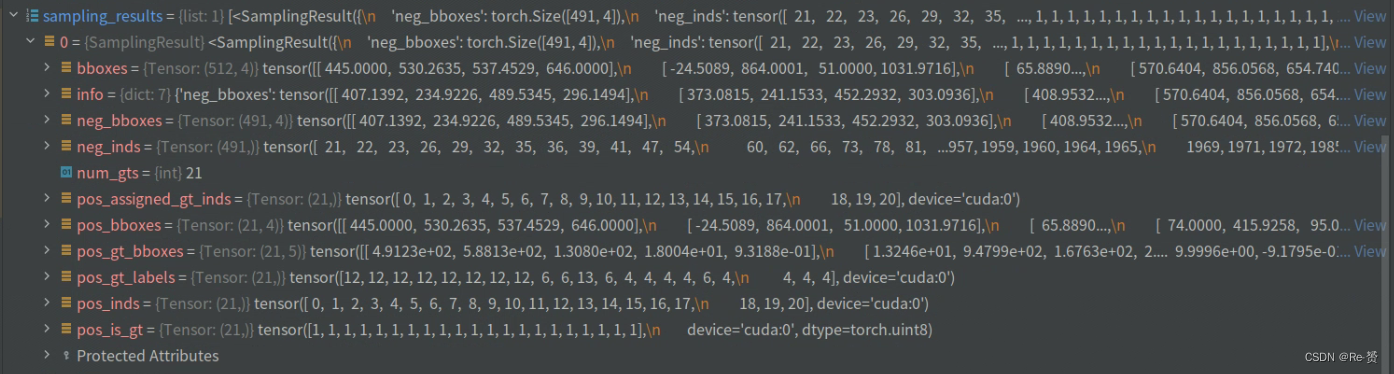
losses = dict()
# bbox head forward and loss
if self.with_bbox:
bbox_results = self._bbox_forward_train(x, sampling_results,
gt_bboxes, gt_labels,
img_metas)
losses.update(bbox_results['loss_bbox'])
用_bbox_forward_train方法进行bbox head的前向传播和损失计算(详见2.1)
2.1 _bbox_forward_train的代码(rotate_standard_roi_head.py)
def _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,
img_metas):
"""Run forward function and calculate loss for box head in training.
Args:
x (list[Tensor]): list of multi-level img features.
sampling_results (list[Tensor]): list of sampling results.
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 5) in [cx, cy, w, h, a] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): list of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
Returns:
dict[str, Tensor]: a dictionary of bbox_results.
"""

rois = bbox2roi([res.bboxes for res in sampling_results])
将采样结果中的边界框(bboxes)转换为RoI (详见2.1.1)

bbox_results = self._bbox_forward(x, rois)
调用_bbox_forward方法对RoIs进行bbox head的前向传播(详见2.1.2)

bbox_targets = self.bbox_head.get_targets(sampling_results, gt_bboxes,
gt_labels, self.train_cfg)
计算目标框的训练目标(详见2.1.3)这一步是为了产生loss计算时的ground truth

loss_bbox = self.bbox_head.loss(bbox_results['cls_score'],
bbox_results['bbox_pred'], rois,
*bbox_targets)
计算目标框头部网络(bbox_head)的损失函数
bbox_results是我们网络预测的结果,bbox_targets是得到的ground truth

bbox_results.update(loss_bbox=loss_bbox)
return bbox_results
更新了bbox_results字典
将更新后的bbox_results返回作为结果

2.1.1 bbox2roi的代码(transformer.py)
def bbox2roi(bbox_list):
"""Convert a list of bboxes to roi format.
Args:
bbox_list (list[Tensor]): a list of bboxes corresponding to a batch
of images.
Returns:
Tensor: shape (n, 5), [batch_ind, x1, y1, x2, y2]
"""

rois_list = []
for img_id, bboxes in enumerate(bbox_list):
if bboxes.size(0) > 0:
img_inds = bboxes.new_full((bboxes.size(0), 1), img_id)
rois = torch.cat([img_inds, bboxes[:, :4]], dim=-1)
else:
rois = bboxes.new_zeros((0, 5))
rois_list.append(rois)
rois = torch.cat(rois_list, 0)
return rois
创建一个空列表,用于存储每个图像的RoIs
遍历每个图像及其对应的边界框:
检查当前图像是否有边界框:
创建一个与边界框数量相同的张量
将图像ID和边界框的坐标信息按列拼接起来,形成RoIs
如果当前图像没有边界框,则创建一个全零的RoIs张量
将当前图像的RoIs添加到RoIs列表中
将RoIs列表中的所有RoIs按行拼接起来,形成最终的RoIs张量
返回RoIs张量,其形状为(n, 5),其中n表示总的RoI数量,每行包含图像ID和边界框的坐标信息(x1, y1, x2, y2)

2.1.2 _bbox_forward的代码(rotate_standard_roi_head.py)
def _bbox_forward(self, x, rois):
"""Box head forward function used in both training and testing.
Args:
x (list[Tensor]): list of multi-level img features.
rois (list[Tensors]): list of region of interests.
Returns:
dict[str, Tensor]: a dictionary of bbox_results.
"""

bbox_feats = self.bbox_roi_extractor(
x[:self.bbox_roi_extractor.num_inputs], rois)
利用RoIs从多层级的图像特征中提取目标框特征

if self.with_shared_head:
bbox_feats = self.shared_head(bbox_feats)
cls_score, bbox_pred = self.bbox_head(bbox_feats)
如果配置中指定了共享的头部网络,则将目标框特征 bbox_feats 传入共享头部网络进行处理,以获得更高层级的特征表示
cls_score, bbox_pred = self.bbox_head(bbox_feats)
将处理后的目标框特征传入目标框头部网络进行分类得分和边界框预测的计算

注意,这里与原本的FasterRcnn有所不同,回归出来的结果是5,而不是4,因为增加点旋转角,这里是作者做的修改,为了适应旋转框

bbox_results = dict(
cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)
return bbox_results
将分类得分、边界框预测和目标框特征组合成一个字典
2.1.3 bbox_head.get_targets的代码(rotated_bbox_head.py)
def get_targets(self,
sampling_results,
gt_bboxes,
gt_labels,
rcnn_train_cfg,
concat=True):
"""Calculate the ground truth for all samples in a batch according to
the sampling_results.
Almost the same as the implementation in bbox_head, we passed
additional parameters pos_inds_list and neg_inds_list to
`_get_target_single` function.
Args:
sampling_results (List[obj:SamplingResults]): Assign results of
all images in a batch after sampling.
gt_bboxes (list[Tensor]): Gt_bboxes of all images in a batch,
each tensor has shape (num_gt, 5), the last dimension 5
represents [cx, cy, w, h, a].
gt_labels (list[Tensor]): Gt_labels of all images in a batch,
each tensor has shape (num_gt,).
rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
concat (bool): Whether to concatenate the results of all
the images in a single batch.
Returns:
Tuple[Tensor]: Ground truth for proposals in a single image.
Containing the following list of Tensors:
- labels (list[Tensor],Tensor): Gt_labels for all
proposals in a batch, each tensor in list has
shape (num_proposals,) when `concat=False`, otherwise
just a single tensor has shape (num_all_proposals,).
- label_weights (list[Tensor]): Labels_weights for
all proposals in a batch, each tensor in list has
shape (num_proposals,) when `concat=False`, otherwise
just a single tensor has shape (num_all_proposals,).
- bbox_targets (list[Tensor],Tensor): Regression target
for all proposals in a batch, each tensor in list
has shape (num_proposals, 5) when `concat=False`,
otherwise just a single tensor has shape
(num_all_proposals, 5), the last dimension 4 represents
[cx, cy, w, h, a].
- bbox_weights (list[tensor],Tensor): Regression weights for
all proposals in a batch, each tensor in list has shape
(num_proposals, 5) when `concat=False`, otherwise just a
single tensor has shape (num_all_proposals, 5).
"""
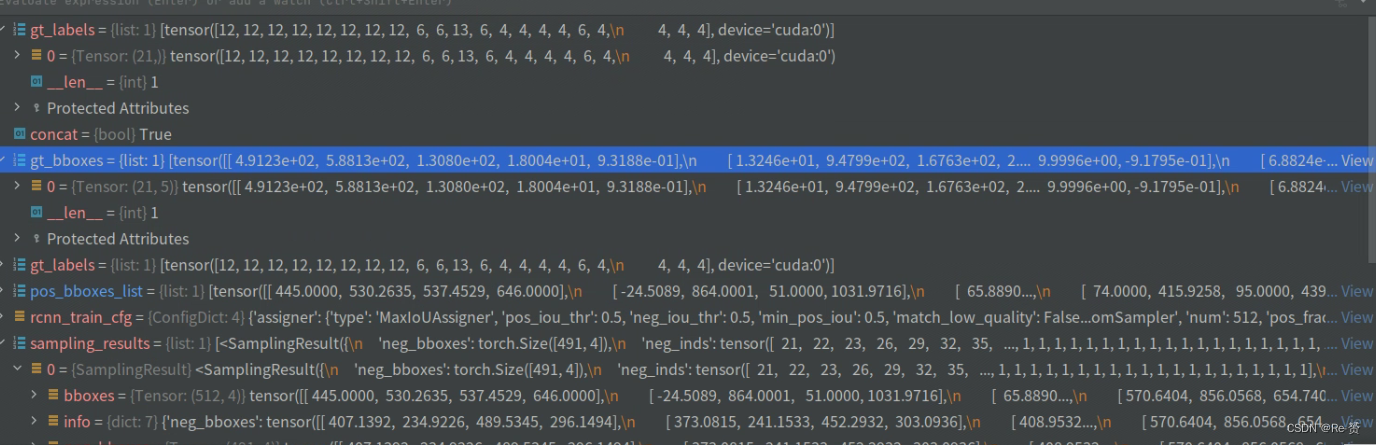
pos_bboxes_list = [res.pos_bboxes for res in sampling_results]
neg_bboxes_list = [res.neg_bboxes for res in sampling_results]
pos_gt_bboxes_list = [res.pos_gt_bboxes for res in sampling_results]
pos_gt_labels_list = [res.pos_gt_labels for res in sampling_results]
labels, label_weights, bbox_targets, bbox_weights = multi_apply(
self._get_target_single,
pos_bboxes_list,
neg_bboxes_list,
pos_gt_bboxes_list,
pos_gt_labels_list,
cfg=rcnn_train_cfg)
if concat:
labels = torch.cat(labels, 0)
label_weights = torch.cat(label_weights, 0)
bbox_targets = torch.cat(bbox_targets, 0)
bbox_weights = torch.cat(bbox_weights, 0)
return labels, label_weights, bbox_targets, bbox_weights
从sampling_results中提取正样本边界框、负样本边界框、正样本的真实边界框和正样本的标签
通过调用multi_apply函数,将这些数据作为参数传递给self._get_target_single方法(详见2.1.3.1)
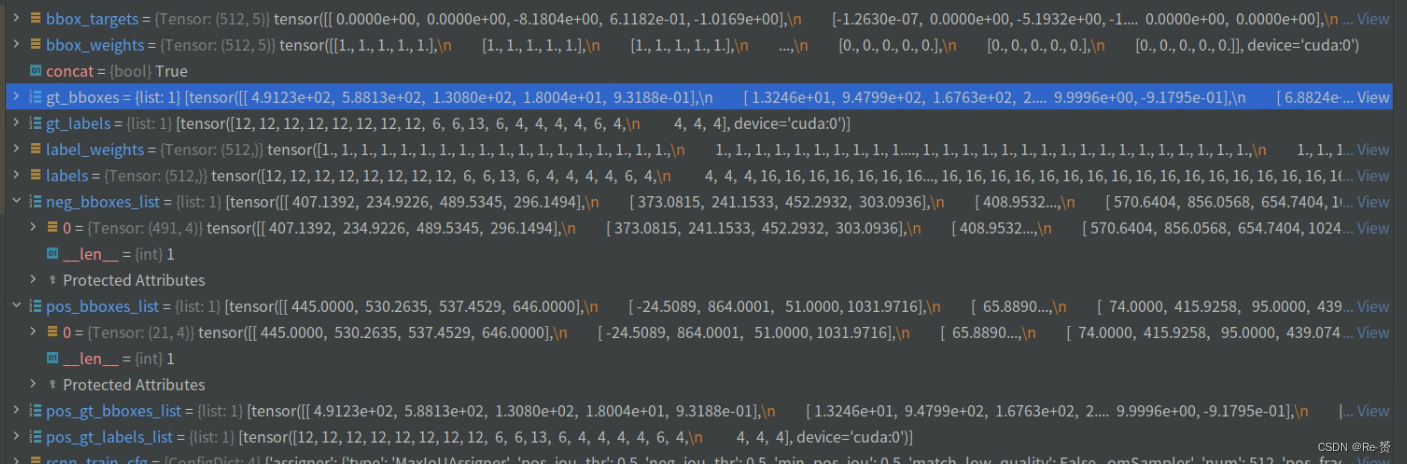
2.1.3.1 _get_target_single的代码(rotated_bbox_head.py)
def _get_target_single(self, pos_bboxes, neg_bboxes, pos_gt_bboxes,
pos_gt_labels, cfg):
"""Calculate the ground truth for proposals in the single image
according to the sampling results.
Args:
pos_bboxes (torch.Tensor): Contains all the positive boxes,
has shape (num_pos, 5), the last dimension 5
represents [cx, cy, w, h, a].
neg_bboxes (torch.Tensor): Contains all the negative boxes,
has shape (num_neg, 5), the last dimension 5
represents [cx, cy, w, h, a].
pos_gt_bboxes (torch.Tensor): Contains all the gt_boxes,
has shape (num_gt, 5), the last dimension 5
represents [cx, cy, w, h, a].
pos_gt_labels (torch.Tensor): Contains all the gt_labels,
has shape (num_gt).
cfg (obj:`ConfigDict`): `train_cfg` of R-CNN.
Returns:
Tuple[Tensor]: Ground truth for proposals
in a single image. Containing the following Tensors:
- labels(torch.Tensor): Gt_labels for all proposals, has
shape (num_proposals,).
- label_weights(torch.Tensor): Labels_weights for all
proposals, has shape (num_proposals,).
- bbox_targets(torch.Tensor):Regression target for all
proposals, has shape (num_proposals, 5), the
last dimension 5 represents [cx, cy, w, h, a].
- bbox_weights(torch.Tensor):Regression weights for all
proposals, has shape (num_proposals, 5).
"""
num_pos = pos_bboxes.size(0)
num_neg = neg_bboxes.size(0)
num_samples = num_pos + num_neg
获取正样本和负样本的数量
计算总样本数

labels = pos_bboxes.new_full((num_samples, ),
self.num_classes,
dtype=torch.long)
label_weights = pos_bboxes.new_zeros(num_samples)
bbox_targets = pos_bboxes.new_zeros(num_samples, 5)
bbox_weights = pos_bboxes.new_zeros(num_samples, 5)
创建标签张量labels,形状为(num_samples,),初始值为self.num_classes,表示背景类别
创建标签权重张量label_weights
创建边界框目标张量bbox_targets
创建边界框权重张量bbox_weights
if num_pos > 0:
labels[:num_pos] = pos_gt_labels
pos_weight = 1.0 if cfg.pos_weight <= 0 else cfg.pos_weight
label_weights[:num_pos] = pos_weight
if not self.reg_decoded_bbox:
pos_bbox_targets = self.bbox_coder.encode(
pos_bboxes, pos_gt_bboxes)
else:
# When the regression loss (e.g. `IouLoss`, `GIouLoss`)
# is applied directly on the decoded bounding boxes, both
# the predicted boxes and regression targets should be with
# absolute coordinate format.
pos_bbox_targets = pos_gt_bboxes
bbox_targets[:num_pos, :] = pos_bbox_targets
bbox_weights[:num_pos, :] = 1
if num_neg > 0:
label_weights[-num_neg:] = 1.0
如果正样本数量大于0:
将正样本的类别标签pos_gt_labels赋值给labels[:num_pos]。
根据配置参数cfg.pos_weight确定正样本的权重pos_weight。
将pos_weight赋值给label_weights[:num_pos]。
如果不是直接应用于解码后的边界框的回归损失函数
使用编码器对正样本的边界框pos_bboxes和真实边界框pos_gt_bboxes进行编码
(这里的encode将pos_bboxes对4维转换为了5维)
否则,直接将真实边界框作为边界框目标。
将pos_bbox_targets赋值给bbox_targets[:num_pos, :]。
将权重张量的对应位置设置为1,即bbox_weights[:num_pos, :] = 1
如果负样本数量大于0,将负样本的标签权重设置为1
