Java多线程<二>多线程经典场景
leetcode 多线程刷题
-
上锁上一次,还是上多次?
-
同步的顺序。
1. 交替打印字符
- 使用sychronize同步锁
- 使用lock锁
- 使用concurrent的默认机制
- 使用volitale关键字 + Thread.sleep() / Thread.yield机制
- 使用automic原子类
方式1 :使用互斥访问state + Number中控制当前state进行
- 实现1:使用synchornized上锁,wait让出cpu
- 实现2:使用semophore上锁, sleep或者yield让出cpu
- 实现3:使用原子Integer进行访问 + yield或者sleep让出cpu
- 实现4:使用Lock进行访问 + condition让出cpu
- 实现5: 使用blockingQueue放入state,如果不是自己的state,在放进去,然后让出cpu。
方式2:使用互斥访问全局cur进行,cur代表当前数字是多少,如果cur >= n,就直接return让线程终止。
- 其中cur代表的是当前的数字是多少。
- 互斥的访问方式仍然是上面的那些种。
方式3:使用同步的通知模式
上面的方式,四个线程都是一直处于活跃状态,也就是Runnable的状态。(使用wait的除外)。另外判断是否可以运行都需要while进行判断。
但实际上,四个线程在同一时间,只需要一个线程可以运行。其他线程都必须进行阻塞。所以可以使用同步通知的方式进行,在其他线程运行的时候,阻塞另外的三个线程,并且运行完成一个线程后,可以实现精准通知另一个线程启动。
2. 打印0和奇偶数字
-
使用锁 sychornized和Lock
-
使用并发工具
-
barrier
-
semopher
-
-
使用cas + Thread.sleep/volatile + ThreadSleep
-
使用blocking que进行实现
经典模型
1. 生产者消费者的几种实现方式
- 操作系统课本上的经典信号量机制。
- 锁使用synchornized关键字
- 加上while(true)死循环
package cn.itedus.lottery.test;
import lombok.SneakyThrows;
import java.util.Stack;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author: Zekun Fu
* @date: 2023/11/13 11:28
* @Description:
*/
public class test434 {
static Stack<String> que = new Stack<>();
static Object full = new ReentrantLock();
static Object empty = new ReentrantLock();
static ReentrantLock lock = new ReentrantLock();
static int n = 0;
static final int st = 10;
static class Consumer {
void consume() {
while (true) {
lock.lock();
if (n > 0) {
lock.unlock();
System.out.println("消费者消费..." + que.pop());
n--;
synchronized (full) {
full.notifyAll();
}
} else {
lock.unlock();
synchronized (empty) {
try {
empty.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Producer {
void produce() {
while (true) {
lock.lock();
if (n < st) {
lock.unlock();
String id = "" + (int)(Math.random() * 100);
System.out.println("生产者生产..." + id);
que.add(id);
n++;
synchronized (empty) {
empty.notifyAll();
}
} else {
lock.unlock();
synchronized (full) {
try {
full.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
Producer p = new Producer();
p.produce();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
new Consumer().consume();
}
}).start();
}
}
- 使用阻塞队列进行实现。 --> Java实现好的生产者消费者
- 手动加锁进行实现。 -->
2. 哲学家进餐
3. 读者写者
4. 并行的统计
- 第一个例子是课本上的匹配问题。
- 对于每一个文件夹可以使用线程池进行一个新的线程创建
- 最后对Future进行统计
package threadBase.threadPool;
/*
*
*
* java核心技术卷上面的线程池
* 使用线程池统计文件中含有关键字的文件个数
* 默认一个文件夹开启一个线程进行处理
*/
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.concurrent.*;
public class Test1 {
public static void main(String[] args) {
String dir = "D:\\projects\\java\\javaBase\\threads\\data";
System.out.println("文件夹的绝对路径是: " + dir);
ExecutorService pool = Executors.newCachedThreadPool();
String keyWord = "this";
System.out.println("关键词是: " + keyWord);
MatchCounter counter = new MatchCounter(pool, keyWord, new File(dir));
Future<Integer> result = pool.submit(counter);
try {
System.out.println("含有关键词的文件个数为:" + result.get());
} catch (Exception e) {
e.printStackTrace();
}
int largestPoolSize = ((ThreadPoolExecutor)pool).getLargestPoolSize();
System.out.println("线程池的最大数量是:" + largestPoolSize);
pool.shutdown(); // 别忘了关闭线程池
}
}
class MatchCounter implements Callable<Integer> {
private ExecutorService pool;
private String keyWord;
private File dir;
public MatchCounter(ExecutorService pool, String keyWord, File dir) {
this.pool = pool;
this.keyWord = keyWord;
this.dir = dir;
}
@Override
public Integer call() throws Exception {
int cnt = 0;
try {
File[] files = dir.listFiles();
List<Future<Integer>> ress = new ArrayList<>();
for (File f: files) { // 分治
if (f.isDirectory()) { // 开启新线程,从线程池中
MatchCounter mc = new MatchCounter(pool, keyWord, f);
Future<Integer>res = pool.submit(mc);
ress.add(res);
}
else { // 如果是文件直接计算
if (search(f)) cnt++;
}
}
for (Future<Integer>res : ress) {
cnt += res.get();
}
}catch (Exception e) {
e.printStackTrace();
}
return cnt;
}
public boolean search(File file) {
try {
try (Scanner sc = new Scanner(file, "UTF-8")){
boolean flag = false;
while(!flag && sc.hasNextLine()) {
String line = sc.nextLine();
if (line.contains(keyWord)) flag = true;
}
return flag;
}
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
}
5.并行的搜索
- bfs的每一个结点开启一个新的线程进行搜索,使用并发的Map作为vis数组,使用并发的queue存入结点,同时使用并发的List放入结点。
- 适用于请求子节点会需要大量的时间的情况,这种适合一个异步的操作。在请求的时候,对以前请求到的结点进行一个过滤和统计。
package leetcode;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/*
*
* 使用线程池 + future进行爬取
*
*
* */
public class Crawl4 {
HashMap<String, List<String>> G = new HashMap<>();
private class HtmlParser {
List<String>getUrls(String start) {
if (G.containsKey(start)) {
List<String>ans = G.get(start);
System.out.println("start = " + start + ", sz = "+ ans.size());
return ans;
}
return new ArrayList<>();
}
}
String hostName;
private ConcurrentHashMap<String, Boolean> totalUrls = new ConcurrentHashMap<>();
public List<String> crawl(String startUrl, HtmlParser htmlParser) {
// bfs开始
hostName = extractHostName(startUrl);
ExecutorService pool = Executors.newCachedThreadPool();
Future<List<String>>taskRes = pool.submit(new Chore(this, htmlParser, startUrl, pool));
List<String>ans = new ArrayList<>();
try {
ans = taskRes.get();
}catch (Exception e) {
e.printStackTrace();
}
pool.shutdown();
// System.out.println("最大的线程数量:" + ((ThreadPoolExecutor)pool).getLargestPoolSize());
return ans;
}
private class Chore implements Callable<List<String>> {
private Crawl4 solution;
private HtmlParser htmlParser;
private String urlToCrawl;
private ExecutorService pool;
public Chore(Crawl4 solution, HtmlParser htmlParser, String urlToCrawl, ExecutorService pool) {
this.solution = solution;
this.htmlParser = htmlParser;
this.pool = pool;
this.urlToCrawl = urlToCrawl;
}
@Override
public List<String> call() throws Exception {
// System.out.println("url = " + urlToCrawl);
// 此处不需要使用并发的,因为统计只有主线程进行
List<String>ans = new ArrayList<>();
ans.add(urlToCrawl);
this.solution.totalUrls.put(urlToCrawl, true);
List<String> urls = htmlParser.getUrls(urlToCrawl);
List<Future<List<String>>> ress = new ArrayList<>();
for (String url : urls) { // 每一个结点开启一个新的线程进行计算
if (this.solution.totalUrls.containsKey(url)) continue;
this.solution.totalUrls.put(url, true);
String hostName = this.solution.extractHostName(url);
if (!hostName.equals(this.solution.hostName)) continue;
Chore c = new Chore(solution, htmlParser, url, pool);
Future<List<String>> res = pool.submit(c);
ress.add(res);
}
// 计算完成所有的任务,直接进行返回就行了
for (Future<List<String>>f:ress) {
ans.addAll(f.get());
}
return ans;
}
}
private String extractHostName(String url) {
String processedUrl = url.substring(7);
int index = processedUrl.indexOf("/");
if (index == -1) {
return processedUrl;
} else {
return processedUrl.substring(0, index);
}
}
public void build(int[][] edges) {
String[] s = {"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.google.com"};
for (int[] e : edges) {
String u = s[e[0]];
String v = s[e[1]];
if (G.containsKey(u)) {
G.get(u).add(v);
} else {
List<String> l = new ArrayList<>();
l.add(v);
G.put(u, l);
}
}
// for (String t : G.get("http://news.yahoo.com/news/topics/")) {
// System.out.println(t);
// }
}
public static void main(String[] args) {
Crawl4 c = new Crawl4();
String input = " [[0,2],[2,1],[3,2],[3,1],[3,0],[2,0]]";
input = input.replace("[", "{");
input = input.replace("]", "}");
System.out.println(input);
int[][] edges = {{0,2},{2,1},{3,2},{3,1},{3,0},{2,0}};
c.build(edges);
List<String> ans = c.crawl("http://news.yahoo.com/news/topics/", c.new HtmlParser());
for (String s: ans) {
System.out.println(s);
}
}
}
线程对效率的影响
1. 实现分治计算数组和
task放在循环外面
一个小实验,用来测试线程对性能的提升
- 计算数组中每一个数字乘以100的和。
- 使用双重循环计算,不用数学公式,这样计算时间长一点,容易做对比。
- 总共实现了四种不同的方式
- 使用单线程
- 使用4个手动写的线程
- 使用分治,先拷贝数组分成t份,之后进行合并
- 使用for循环生成4个手写的线程。
最后可以看到手动实现4个线程进行分治可以把效率提升到4倍左右。
详细代码请看下面代码1。
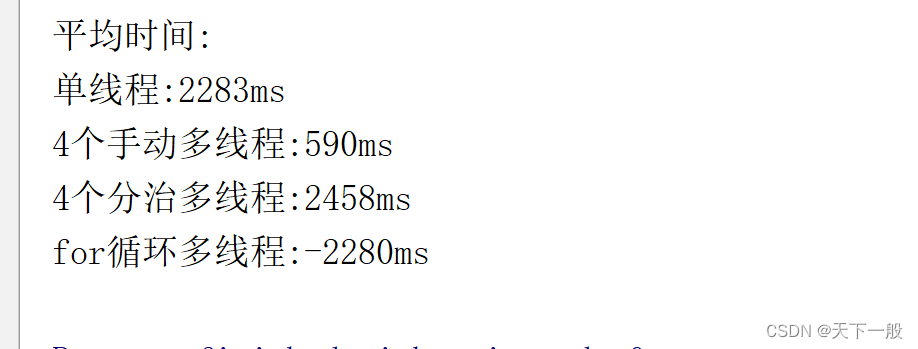
分析1:
- 由于我的计算机是8核16线程的,所以最多可以实现16个线程的并行计算。所以4个线程最多可以把效率提升到4倍。但是最多的效率提升就到16倍了。
- 使用分治,由于由大量的数组拷贝,所以计算的效率会低很多。
- 使用for循环创建线程,由于task的get()是阻塞的,会导致for循环没法执行,从而使得下面的线程没法执行。解决办法是
- 保存生成的task, 在for循环外面调用get方法。
- 之后的效率如下。
详细代码请看下面代码2。

分析2:提升线程个数带来的影响
- 可以看到最终的效率提升了15倍左右。
- 这是由于16个逻辑处理器并行工作的原因。
- 这么一看电脑设计的还不错。16个逻辑处理器能并行提升15倍的性能。这还是在上下文切换的情况下。在我代码垃圾的情况下。hhhh
详细代码请看下面代码3。


代码1
package threadBase.baseKey;
import java.lang.reflect.Array;
import java.util.Arrays;
import java.util.Random;
import java.util.Stack;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
import java.util.concurrent.atomic.AtomicInteger;
/*
*
*
* 线程启动的三种方式
* 1. implement
* 2. extends
* 3. FutureT
*
* 4.
* */
public class StartThread {
private static final int MAXN = 100000000;
private static int[] nums = new int[MAXN]; // 计算数组中100个数字的和
private AtomicInteger cur = new AtomicInteger();
static {
Arrays.fill(nums, 1);
}
private static long testSingle() throws Exception {
long startTime = System.currentTimeMillis();
long sum = 0;
for (int i = 0; i < MAXN; i++) {
for (int j = 0; j < 100; j++) {
sum += nums[i];
}
}
long endTime = System.currentTimeMillis();
System.out.println("单线程: ");
System.out.println("sum = " + sum + " t = " + (endTime - startTime) + "ms");
return endTime - startTime;
}
private static long test1() throws Exception{
long startTime = System.currentTimeMillis();
FutureTask<Long> task1 = new FutureTask<Long>(() -> {
long tsum = 0;
for (int i = 0; i < 25000000; i++) {
for (int j = 0; j < 100; j++) {
tsum += nums[i];
}
}
return tsum;
});
FutureTask<Long> task2 = new FutureTask<Long>(() -> {
long tsum = 0;
for (int i = 25000000; i < 50000000; i++) {
for (int j = 0; j < 100; j++) {
tsum += nums[i];
}
}
return tsum;
});
FutureTask<Long> task3 = new FutureTask<Long>(() -> {
long tsum = 0;
for (int i = 50000000; i < 75000000; i++) {
for (int j = 0; j < 100; j++) {
tsum += nums[i];
}
}
return tsum;
});
FutureTask<Long> task4 = new FutureTask<Long>(() -> {
long tsum = 0;
for (int i = 75000000; i < 100000000; i++) {
for (int j = 0; j < 100; j++) {
tsum += nums[i];
}
}
return tsum;
});
new Thread(task1).start();
new Thread(task2).start();
new Thread(task3).start();
new Thread(task4).start();
long sum = task1.get() + task2.get() + task3.get() + task4.get();
long endTime = System.currentTimeMillis();
System.out.println("4线程:");
System.out.println("sum = " + sum + " t = " + (endTime - startTime) + "ms");
return endTime - startTime;
}
private static long test2() throws Exception{
/*
*
* 首先需要一个线程进行任务的划分。
* 然后由这个划分线程生成划分任务的线程数目。
* 在有这个线程进程组装。
* 在这使用主线程进行划分。
* */
int t = 5; // 划分线程的数量
int len = MAXN / t;
long sum = 0;
long startTime = System.currentTimeMillis();
for (int i = 0; i < t; i++) { // 进行任务划分
int[] numt = new int[len];
for (int j = i * len; j < (i + 1) * len; j++) {
numt[j - (i * len)] = nums[j];
}
// 线程执行
FutureTask<Long>task = new FutureTask<Long>(()->{
long ans = 0;
for (int x: numt) {
for (int j = 0; j < 100; j++) {
ans += x;
}
}
return ans;
});
new Thread(task).start();
sum += task.get();
}
long endTime = System.currentTimeMillis();
System.out.println("使用分治进行" + t + "线程划分执行:");
System.out.println("sum = " + sum + " t = " + (endTime - startTime) + "ms");
return endTime - startTime;
}
private static long test3() throws Exception {
StartThread startThread = new StartThread();
int cnt = 4; // 控制线程的个数
int sz = MAXN / cnt; // 每一个线程计算的数量是多少
long sum = 0; // 计算和是多少
long startTime = System.currentTimeMillis();
for (int i = 0; i < cnt; i++) {
FutureTask<Long> task = new FutureTask<Long>(()->
{
long ans = 0L;
int bg = startThread.cur.getAndIncrement();
for (int j = bg * sz; j < (bg + 1) * sz; j++) {
for (int k = 0; k <100; k++) {
ans += nums[j];
}
}
return ans;
});
new Thread(task).start();
sum += task.get();
}
long endTime = System.currentTimeMillis();
System.out.println(cnt + "个线程:");
System.out.println("sum = " + sum + " t = " + (endTime - startTime) + "ms");
return endTime - startTime;
}
// 可以从第三遍开始,统计一个平均的时间
public static void main(String[] args)throws Exception {
long t1 = 0, t2 = 0, t3 = 0, t4 = 0;
for (int i = 0; i < 11; i++) { // 后面的8轮次进行统计
System.out.println("-----------第" + i + "轮----------");
if (i >= 3) {
t1 += testSingle();
t2 += test1();
t3 += test2();
t4 += test3();
} else {
testSingle();
test1();
test2();
test3();
}
}
System.out.println("平均时间:");
System.out.println("单线程:" + t1 / 8 + "ms");
System.out.println("4个手动多线程:" + t2 / 8 + "ms");
System.out.println("4个分治多线程:" + t3 / 8 + "ms");
System.out.println("for循环多线程:" + t4 / 8 + "ms");
}
}
代码2
主要就是修改了test2和test3的方法。
- 把task.get()放在循环外面计算。
- 使用数组保存生成的task。
private static long test2() throws Exception{
/*
*
* 首先需要一个线程进行任务的划分。
* 然后由这个划分线程生成划分任务的线程数目。
* 在有这个线程进程组装。
* 在这使用主线程进行划分。
* */
int t = 5; // 划分线程的数量
int len = MAXN / t;
long sum = 0;
long startTime = System.currentTimeMillis();
FutureTask<Long>[]tasks = new FutureTask[t];
for (int i = 0; i < t; i++) { // 进行任务划分
int[] numt = new int[len];
for (int j = i * len; j < (i + 1) * len; j++) {
numt[j - (i * len)] = nums[j];
}
// 线程执行
FutureTask<Long>task = new FutureTask<Long>(()->{
long ans = 0;
for (int x: numt) {
for (int j = 0; j < 100; j++) {
ans += x;
}
}
return ans;
});
new Thread(task).start();
tasks[i] = task;
// sum += task.get(); // 这个会阻塞线程,所以会慢
}
for (int i = 0; i < 4; i++) {
sum += tasks[i].get();
}
long endTime = System.currentTimeMillis();
System.out.println("使用分治进行" + t + "线程划分执行:");
System.out.println("sum = " + sum + " t = " + (endTime - startTime) + "ms");
return endTime - startTime;
}
public static long test4() throws Exception{
StartThread startThread = new StartThread();
int cnt = 4; // 控制线程的个数
int sz = MAXN / cnt; // 每一个线程计算的数量是多少
long sum = 0; // 计算和是多少
long startTime = System.currentTimeMillis();
FutureTask<Long>[]tasks = new FutureTask[cnt];
for (int i = 0; i < cnt; i++) {
FutureTask<Long> task = new FutureTask<Long>(()->
{
long ans = 0L;
int bg = startThread.cur.getAndIncrement();
for (int j = bg * sz; j < (bg + 1) * sz; j++) {
for (int k = 0; k <100; k++) {
ans += nums[j];
}
}
return ans;
});
new Thread(task).start();
tasks[i] = task;
}
for (int i = 0; i < cnt; i++) {
sum += tasks[i].get();
}
long endTime = System.currentTimeMillis();
System.out.println(cnt + "个线程:");
System.out.println("sum = " + sum + " t = " + (endTime - startTime) + "ms");
return endTime - startTime;
}
代码3
- 测试多少个线程对性能提升最大
- 结论是逻辑处理器的个数个。
public static void testNumOfThread() throws Exception{
int cnt = 32;
long []times = new long[cnt];
for (int i = 1; i < cnt; i++) {
times[i] = test4(i);
}
for (int i = 1; i < cnt; i++) {
System.out.println(i + "个线程:" + times[i] + "ms");
}
}
// 可以从第三遍开始,统计一个平均的时间
public static void main(String[] args)throws Exception {
testNumOfThread();
}
总结
- task.get()是阻塞的,最好不要放在主线程中,更不要放在线程创建的路径上,最好在开一个线程,进行归并。
- 多线程对效率的提升体现在多处理器的并行上。
- 这里实现的计算是平均划分数组进行求和,如果不能平均划分就会出错。应该使用归并式的那种划分。
- 明天实现一下多线程的归并排序和多线程的斐波那契数列。