【软件测试学习】MongoDB入门(基于Navicat)
引入:电商平台商品信息存储
Mysql:针对不同商品创建不同的表;建一张打表,所有商品存储到表里;公共属性提取出来建表,特有属性各自建表;
MongoDB:没有表结构概念(无需建表),文档内容可以非常灵活地去定制。
与Mysql相比优势在于速度快、操作简单、使用便捷、灵活;
劣势:安全性、数据的一致性、稳定性不够
基本概念
一款流行的文档数据库。
主要特点:高性能(处理请求速度快)、高可用性(大多数时间都能正常运行)、自动扩展(有应对快速负载的能力)、免费开源
MongoDB三元素:数据库、集合(collection)、文档(document)
注解:一个数据库(书)可以包含多个集合(章),一个集合又可以包含多个文档(每一页);
MongoDB将数据存储为一个文档,文档数据由键值对组成。
键值对:键:属性/字段;值:属性/字段的取值;(放在一起叫键值对)
文档格式:{key1:value1,key2:value2,kye3:value3…}
键:字符串类型
值:的类型多种多样(数字,字符串、数组、文档等)
环境搭建
安装教程
安装成功

掌握全部操作
常见操作
围绕mongodb三元素----数据库、集合、文档(重点)
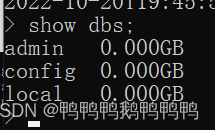
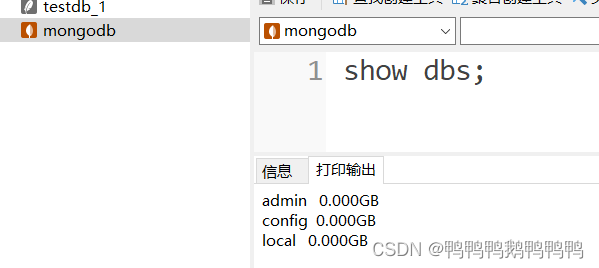
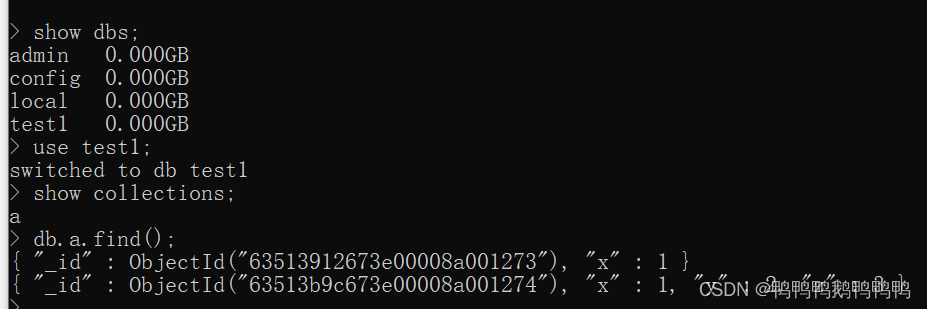
- 查看所有数据库列表
show dbs; - 建库
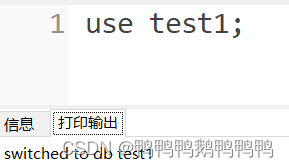
use 数据库名;(两重含义:如果use后面跟的数据库名在当前连接下没有,这创建数据库,并选择该数据库;如果当前连接下有该数据库,则直接选择该数据库。)
举例:
use test1;
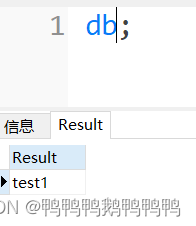
- 显示当前连接的是哪个数据库
db;
- 查看当前数据库下有那些集合
show collections;

- 创建集合插入文档
db.collection_name.insert()
insert()两种含义:执行插入操作时会去检查collection_name在当前数据库下有没有,如果有则往该集合下插入数据;如果没有则会创建该集合并插入数据。
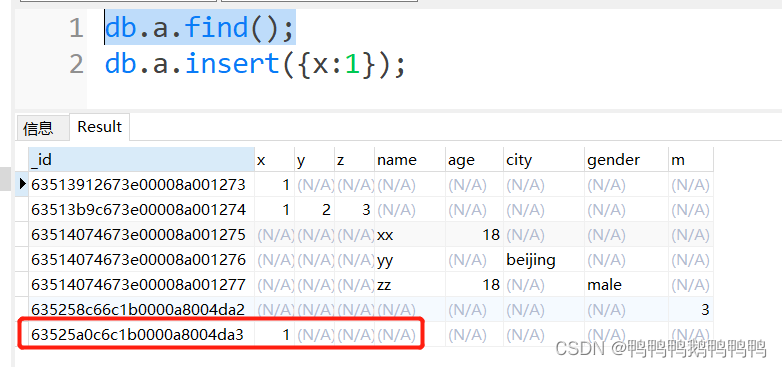
举例:db.a.insert({x:1});
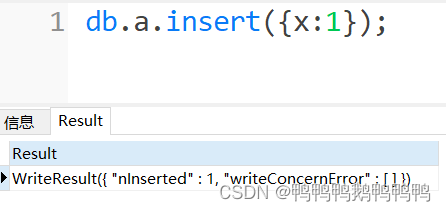

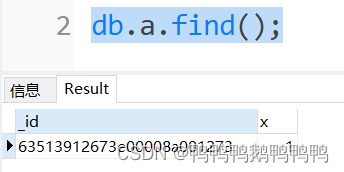
_id为做文档插入时系统给每个文档分配的一个编号,这个编号在每次数据插入时都会自动生成有别于其他文档的编号作为这个文档的标识。
文档的操作
数据的增删改查
- 文档的插入
1.插入单个文档
db.a.insert({x:1,y:2,z:3}) ;
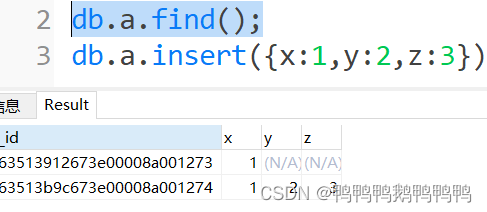
并实际没有按表的方式存储
2. 一次性往集合插入多个文档
多个文档以数组的方式插入
数组:一组数据;格式:[data1,data2,…datan]
db.a.insert([{},{},{}]);
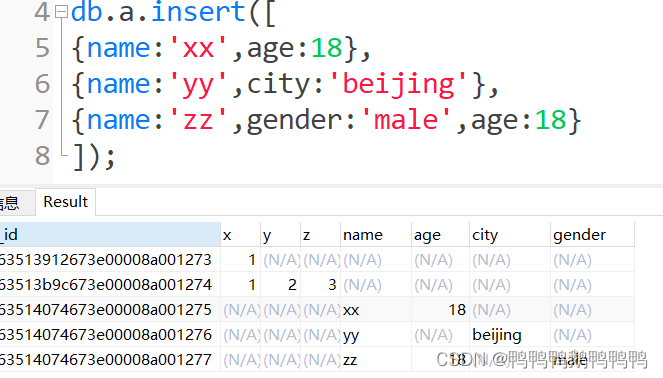
当给同一个键赋多个值的时候,取最后一个值
db.a.insert({m:1,m:2,m:3});
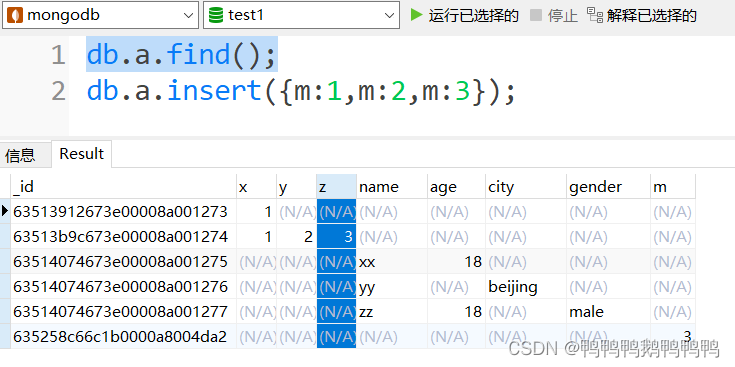
允许重复插入多次相同的文档,因为系统每次给文档分配不同的编号(_id)不同的编号代表着不同的文档
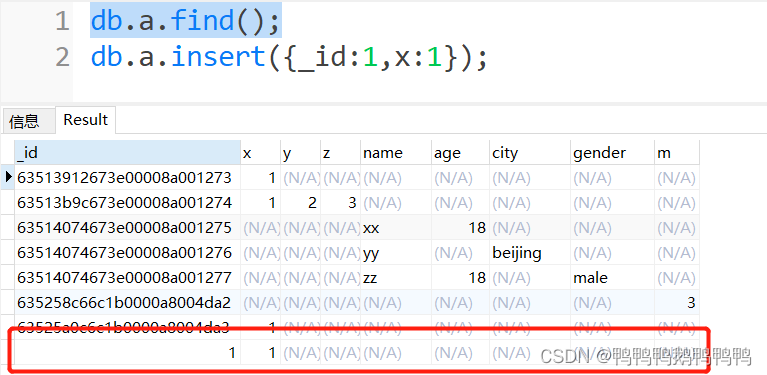
- 允许用户自定义_id,但不可两次取值相同
db.a.insert({_id:编号,键:值});
文档的查询
运算符
- 算术运算符
$eq equal =
$ne not equal !=
$gt greater than >
$gte greater than equal >=
$lt lower than <
$lte <=
$in 在。。。里面
$nin 不在。。。里面
{field:{运算符:value}}
查询导演是冯小刚的商品信息
两种写法

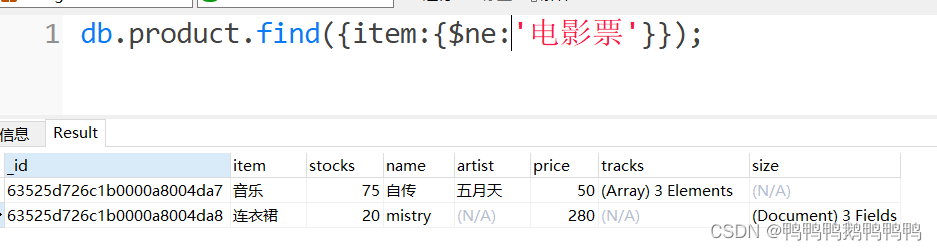
查询非电影票的信息
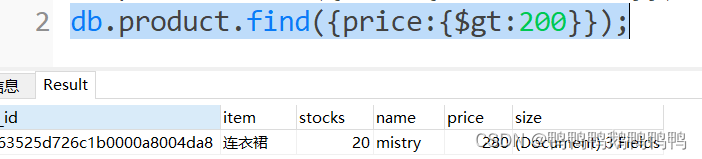
查询价格高于200块的商品信息
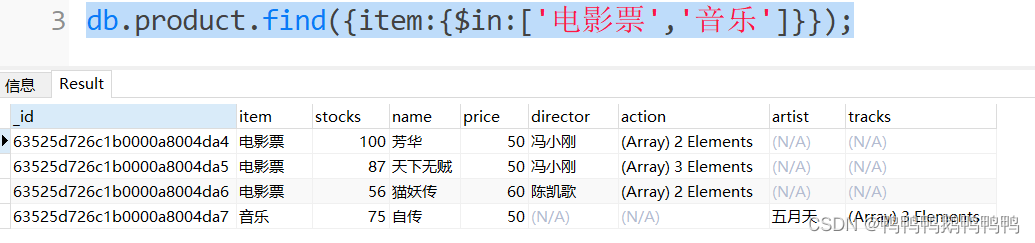
查询电影票和音乐的商品信息
- 逻辑运算符
$and 与
$or 或
$not 非
{$and/$or:[{条件1},{条件2}....]}
{键:{$not:{条件1},{条件2}.....}}
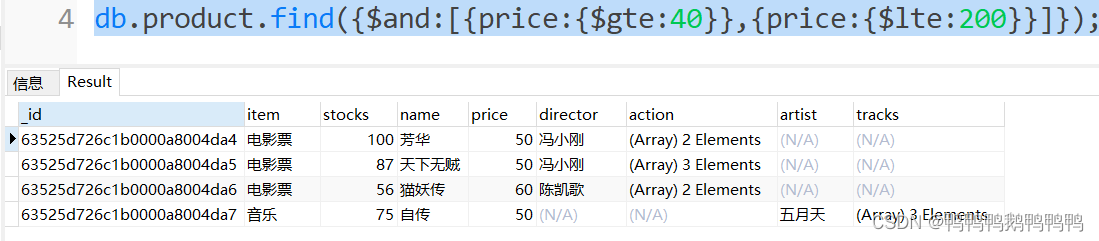
查询价格在40到280之间的商品信息
查询导演是冯小刚的电影票信息

或者db.product.find({director:'冯小刚',item:'电影票'});
查询电影票和音乐的商品信息

或者db.product.find({$or:[{item:'电影票'},{item:'音乐'}]});
内嵌文档的查询
查询商品尺寸满足长度为75,宽度为50,度量单位为cm的商品信息

以上这种写法,如果不按内嵌文档录入时的顺序写就会查询不到(保证顺序保持一致)
希望顺序不匹配也能查询到,则写成
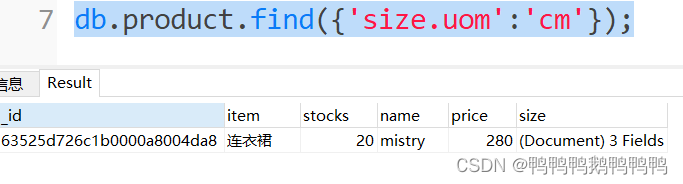
db.product.find({'size.width':50,'size.length':75,'size.uom':'cm'});
注意:涉及到内嵌文档里的字段的引用,通过.的方式引用,内嵌字段的引号一定要加

查询商品尺寸度量单位为cm的商品信息
数组的查询
数组(array):[data1,data2,…,datan]
数组里的每一个数据称为元素(element),元素是由编号的,编号是从0开始,这就意味着我们可以通过数组名.编号的方式取值
举例:取演员列表里的第二个值,用actor.1表示
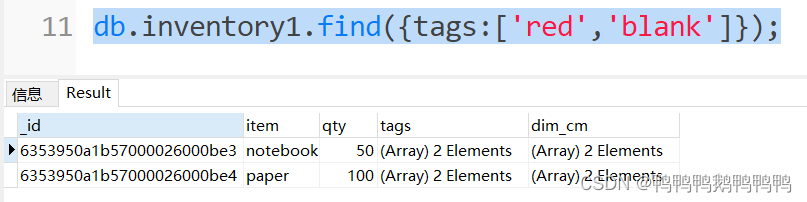
- 完全匹配一个数组
查询tags数组只包含red和blank,且red在前blank在后的商品信息
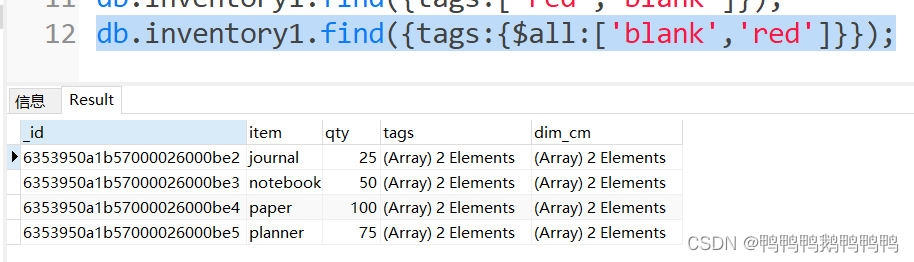
- 部分匹配
查询tags数组包含了red和blank的商品信息
使用了 $all
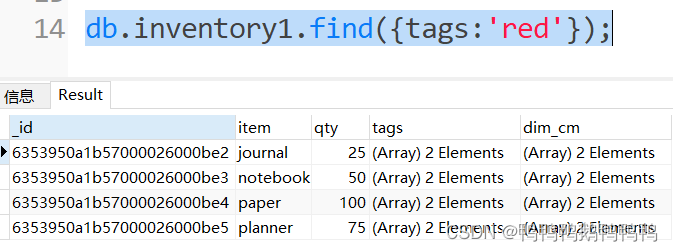
举例:
找到tags数组里由red元素的记录
找到dim_cm数组里包含至少一个元素的值大于25的记录

找到数组dim_cm中某个元素大于15且小于20
使用elemMatch作用把后面两个条件锁定在同一个数组元素上去
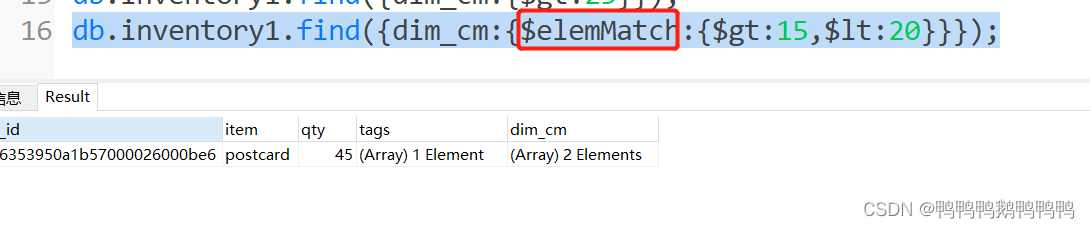
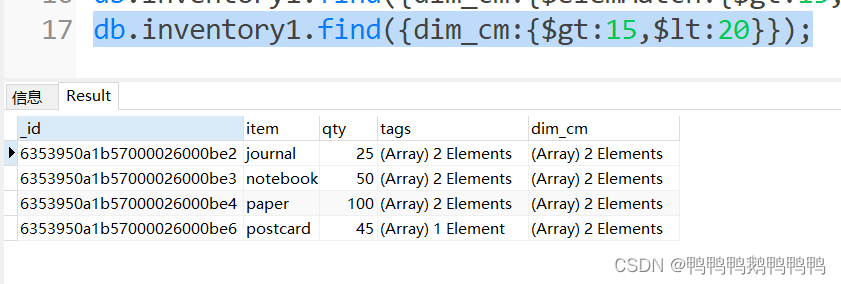
以下写法会将一个元素大于15另外一个元素小于20的记录也查询出来
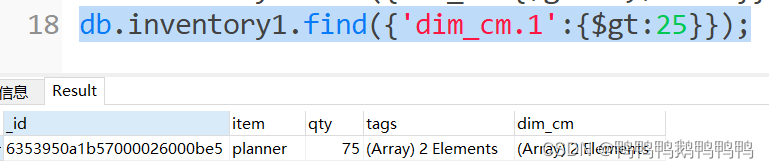
找到数组dim_cm的第二个元素值大于25的记录
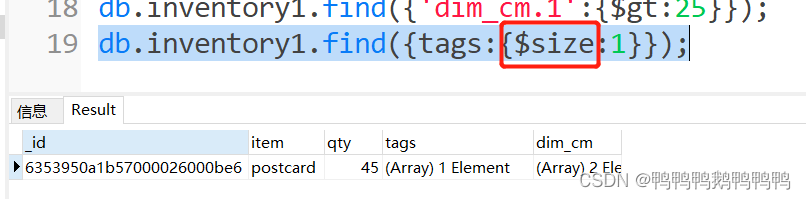
找到tags数组里包含一个元素的记录
$size用来统计数组元素的个数
- 进阶:
查询A仓库有5个数量的商品信息
完全查询(此语句需要注意顺序)

部分查询

查询instock第一个数组元素的qty值小于等于20 的记录

查询instock任意数组元素的qty值小于等于20 的记录
(将.0删掉)
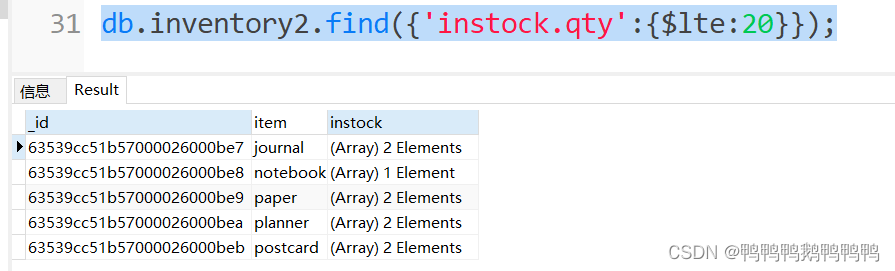
查询特定的字段信息
查询猫妖传的价格

排除_id(除了_id其他字段置0或置1不可以混用,否则会报错)

查询所有商品的名字
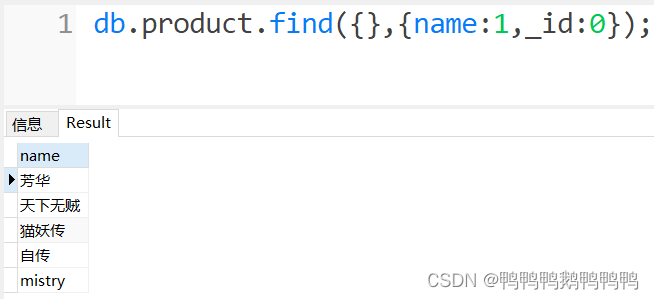
小结:find();方法时会跟两个参数,每个参数都是文档的类型
第一个参数位置放的是查询条件,第二个位置是字段显示的说明
-
排序显示sort
- 按价格升序
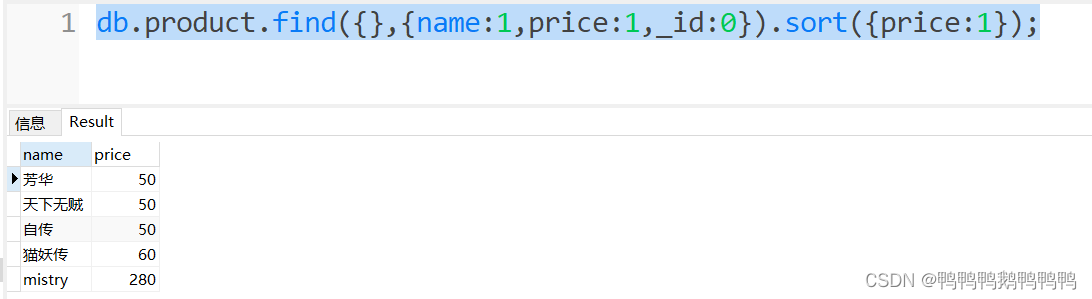
2.按价格降序
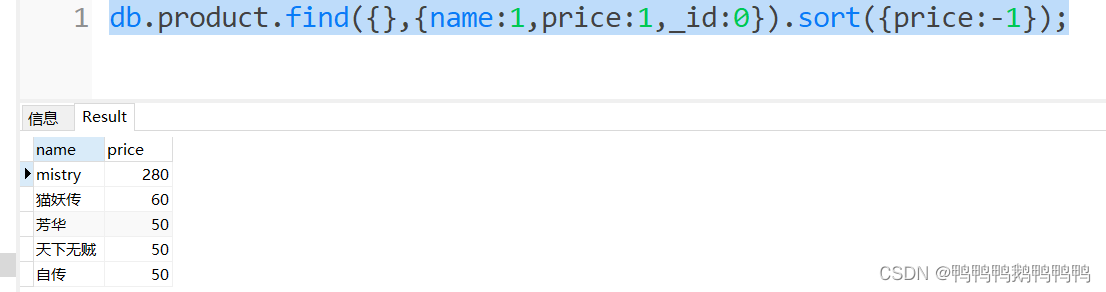
3. 先按价格升序,再按库存降序
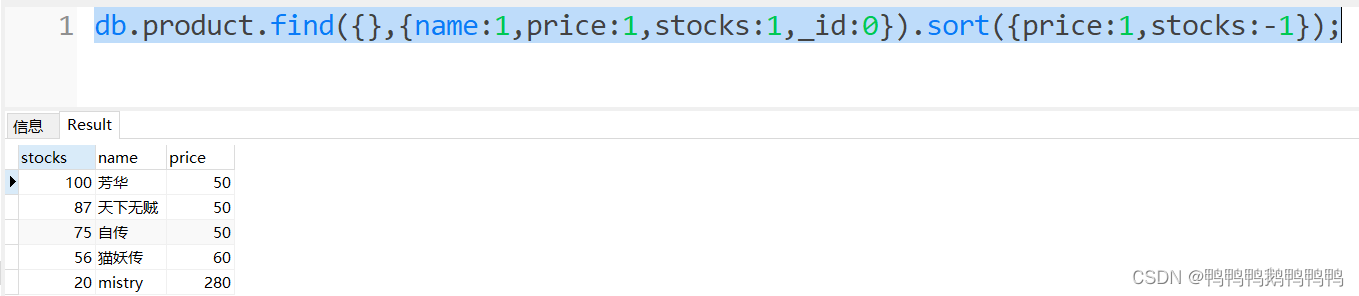
- 按价格升序
-
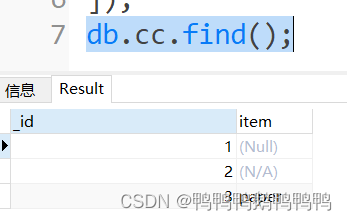
空值查询
N/A:Not Applicable的缩写,表示不适用
block:阻塞状态
- 查询item为空
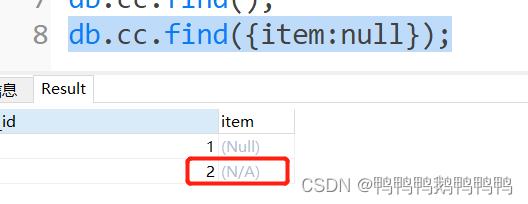
只想只想查询item为空的字段
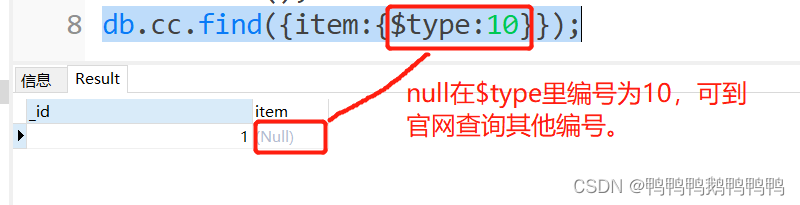
只想查询没有item的字段文档
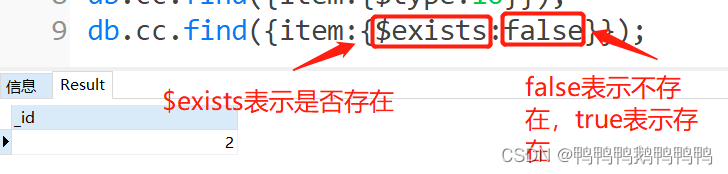
- 查询item为空
文档的更新和删除
$set两重含义:当set后面的字段是原来没有的,就会把字段加进去,如果是原本就有的,则会做相应修改
-
文档的更新
update();
updateMany);
通常跟两个参数第一个参数位置放的是更新的条件,第二个参数放的是更新的内容
更新一个文档
将猫妖传的票价更新为55
不能写成db.product.update({name:'猫妖传'},{price:55});,因为它会使price覆盖掉满足这个条件的文档的所有字段(_id除外的其他字段都会被覆盖),需要加$set

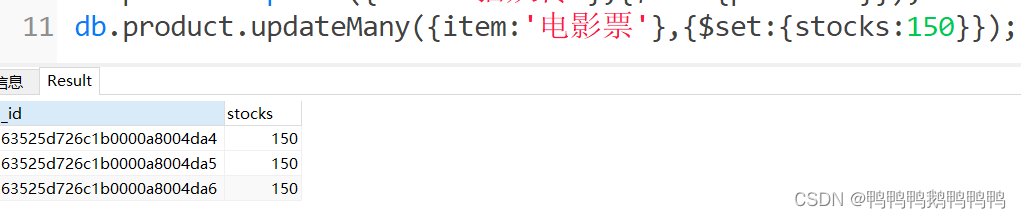
更新多个文档
将电影票的库存更新为150
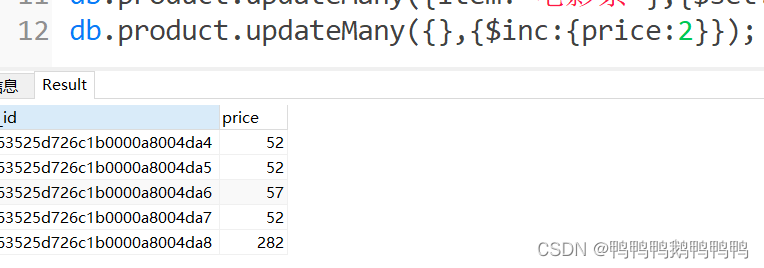
将所有商品的价格上涨2块钱
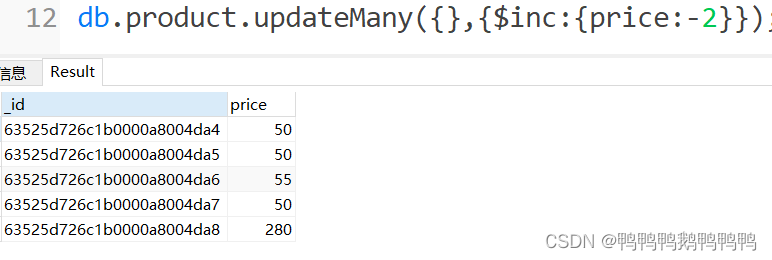
降价两块钱
将所有商品的stocks字段删除
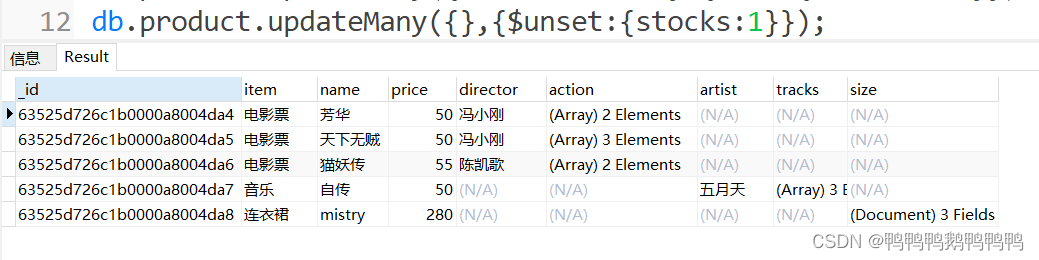
将stock是字段追加回来

-
文档是删除
deleteOne()
deleteMany()- 删除一条文档
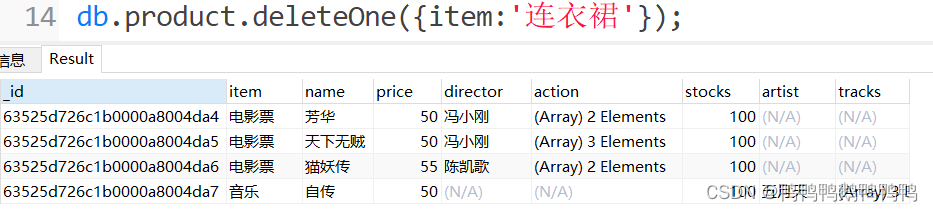
- 删除多条文档

- 删除所有文档
集合还在里面的数据还在

- 删除一条文档
补充
集合的相关操作
- 创建
隐式创建:db.xxx.insert({x:1});
显示创建:db.createCollection(‘xxx’); - 删除集合
db.product.drop();
数据库相关操作
- 创建
use xxx;
需要插入一条数据,show dbs;才会显示
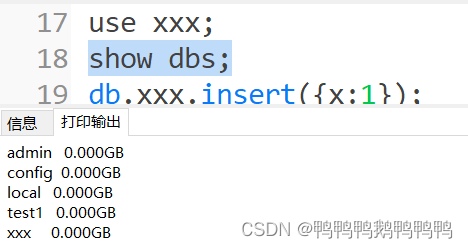
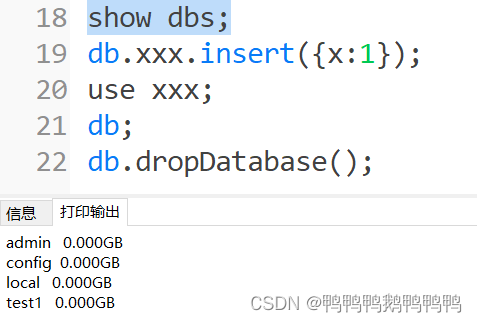
- 删除xxx数据库
先切换到要删除的数据库,再用db.dropDatabase();来删除
sql和mongodb对照表