cilium host-routing模式流程分析
本文分析cilium host routing模式下的报文路径和涉及到的ebpf源码分析。
使能host routing
在满足下面条件下会自动使能,进程启动时会进行判断,如果不满足会自动降级为legacy模式,也就是native routing模式
Requirements:
Kernel >= 5.10
Direct-routing configuration or tunneling
eBPF-based kube-proxy replacement
eBPF-based masquerading
使能eBPF-based kube-proxy replacement
参考:https://docs.cilium.io/en/v1.12/gettingstarted/kubeproxy-free/
上面的链接是通过kubeadm从头开始创建k8s集群时替换kube-proxy的流程,如果已经有了k8s集群,并且使用cilium cni时,可按如下
步骤操作
- 在master节点上删除kube-proxy的daemonset和configmap
kubectl -n kube-system delete ds kube-proxy
kubectl -n kube-system delete cm kube-proxy
- 删除所有节点上的KUBE相关的iptables规则
# Run on each node with root permissions:
iptables-save | grep -v KUBE | iptables-restore
- 修改cilium的配置文件,增加如下两项配置
kubectl -n kube-system edit configmap cilium-config
kube-proxy-replacement: strict
k8s-api-server: https://192.168.56.2:6443
配置说明如下:
kube-proxy-replacement有如下三个可选值,默认为partial,可参考函数initKubeProxyReplacementOptions
partial: 只使能部分功能,比如使能--enable-node-port,--enable-host-port等
strict: 使能所有功能,如果有不支持的会panic
disabled: 关闭replacement
k8s-api-server:用来指定k8s apiserver。cilium启动时默认会通过kubernetes svc(cluster ip 10.96.0.1)连接k8s,
前面已经把kube-proxy相关的删除了,所以也连不上kubernetes svc,只能通过此参数显示指定,可参考函数createConfig
- 删除旧的cilium相关pod,等新pod起来后,可以查看替换情况
root@master:~# kubectl exec -it -n kube-system cilium-5rwsg -- cilium status --verbose
...
KubeProxyReplacement Details:
Status: Strict
Socket LB: Enabled
Socket LB Protocols: TCP, UDP
Devices: enp0s8 192.168.56.2 (Direct Routing)
Mode: SNAT -->通过nodeport连接service时,会做snat,也支持dsr
Backend Selection: Random
Session Affinity: Enabled
Graceful Termination: Enabled
NAT46/64 Support: Disabled
XDP Acceleration: Disabled
Services:
- ClusterIP: Enabled
- NodePort: Enabled (Range: 30000-32767)
- LoadBalancer: Enabled
- externalIPs: Enabled
- HostPort: Enabled
使能 eBPF-based masquerading
修改cilium的配置文件,增加如下配置,删除旧的cilium pod,等新pod起来
kubectl -n kube-system edit configmap cilium-config
enable-bpf-masquerade: "true"
验证
可使用cilium status --verbose查看是否使能host routing
host routing生效前
Host Routing: Legacy
Masquerading: IPTables [IPv4: Enabled, IPv6: Disabled]
host routing生效后
Host Routing: BPF
Masquerading: BPF [enp0s8] 10.0.0.0/8 [IPv4: Enabled, IPv6: Disabled]
拓扑图如下
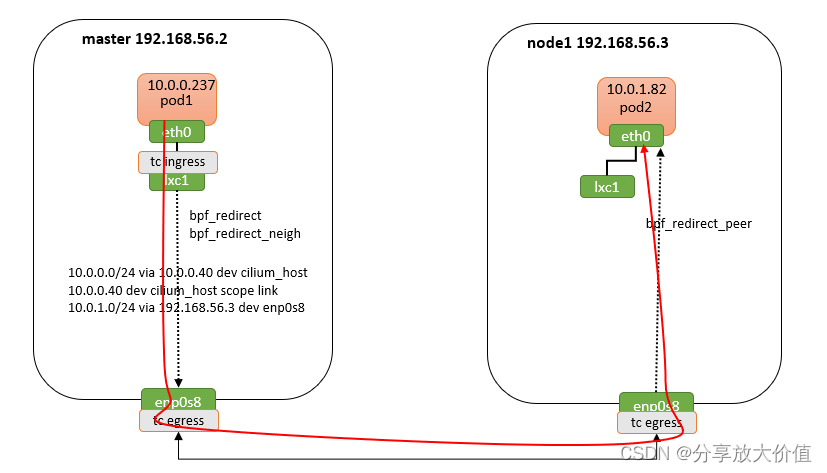
这里主要分析一下,对比其他模式,host routing有什么优势,
master上发报文方向时,在lxc1的ebpf程序中执行路由(图中的路由表是在ebpf程序中被查找)和邻居查找,如果成功则调用bpf_redirect/bpf_redirect_neigh直接将报文从出接口enp0s8发出,跳过了host协议栈中netfilter的处理。
node1上收报文方向时,在enp0s8收到报文执行ebpf程序,查找podmap确认目的ip为本地pod后,则调用bpf_redirect_peer将报文直接发到pod内部的eth0,不仅跳过了host协议栈中netfilter的处理,也减少了一次软中断的处理
由此可见bpf_redirect_neigh和bpf_redirect_peer是实现host routing模式的关键。
流程分析
本文只分析跨host两个pod之间的通信过程。
从pod1发送的ip报文路径如下
报文路径
eth0(pod1) -> lxc1(tc ingress:from-container) -> enp0s8(master,tc egress:to-netdev)
eth0(pod1):
//pod内部发出的报文,最终会调用veth_xmit发出
//根据veth原理,会将报文的dev改成对端dev(即lxc)后调用netif_rx走host协议栈
static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev)
struct veth_priv *rcv_priv, *priv = netdev_priv(dev);
struct net_device *rcv;
rcv = rcu_dereference(priv->peer);
veth_forward_skb(rcv, skb, rq, rcv_xdp)
netif_rx(skb)
lxc1(tc ingress:from-container):
//在协议栈入口调用sch_handle_ingress执行ebpf程序,查路由表和邻居表,如果成功的互,会返回CTX_ACT_REDIRECT,
//调用skb_do_redirect将报文重定向到出接口
//ebpf程序处理流程后面会详细介绍
__netif_receive_skb_core
...
if (static_branch_unlikely(&ingress_needed_key)) {
bool another = false;
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
//执行ebpf程序,如果返回值为TC_ACT_REDIRECT,将调用skb_do_redirect将报文重定向到其他接口
switch (tcf_classify_ingress(skb, miniq->block, miniq->filter_list, &cl_res, false)) {
...
case TC_ACT_REDIRECT:
/* skb_mac_header check was done by cls/act_bpf, so
* we can safely push the L2 header back before
* redirecting to another netdev
*/
__skb_push(skb, skb->mac_len);
if (skb_do_redirect(skb) == -EAGAIN) {
__skb_pull(skb, skb->mac_len);
//如果返回值为-EAGAIN,则设置another为true,表示要goto到another重新走一遍协议栈
*another = true;
break;
}
return NULL;
...
}
}
ebpf程序分析
lxc1(tc ingress:from-container)
handle_xgress
send_trace_notify(ctx, TRACE_FROM_LXC, SECLABEL, 0, 0, 0,
TRACE_REASON_UNKNOWN, TRACE_PAYLOAD_LEN);
ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC); //tail_handle_ipv4
__tail_handle_ipv4
tail_handle_ipv4_cont
handle_ipv4_from_lxc
//根据目的ip到cilium_ipcache map中查找,cilium_ipcache中保存的是整个集群所有的pod信息
info = lookup_ip4_remote_endpoint(ip4->daddr);
ipcache_lookup4(&IPCACHE_MAP, addr, V4_CACHE_KEY_LEN)
if (info && info->sec_label) {
//主要用在egress policy中,检查是否允许访问此业务
*dst_id = info->sec_label;
tunnel_endpoint = info->tunnel_endpoint;
encrypt_key = get_min_encrypt_key(info->key);
} else {
*dst_id = WORLD_ID;
}
//执行egress policy
verdict = policy_can_egress4(ctx, tuple, SECLABEL, *dst_id, &policy_match_type, &audited);
...
//在host routing模式下,直接在ebpf程序中查找路由,如果查找成功则直接重定向到出接口,
//不用再返回host协议栈处理
if (is_defined(ENABLE_HOST_ROUTING)) {
int oif;
ret = redirect_direct_v4(ctx, ETH_HLEN, ip4, &oif);
//调用bpf helper函数 fib_lookup(bpf_ipv4_fib_lookup),查找路由和邻居表
//如果查找路由表成功,则将下一跳保存到 fib_params->ipv4_dst,将出接口保存到 params->ifindex
//如果查找邻居表成功,则将出接口mac保存到params->smac,将下一跳mac保存到params->dmac
ret = fib_lookup(ctx, &fib_params, sizeof(fib_params), BPF_FIB_LOOKUP_DIRECT);
switch (ret) {
//路由表和邻居表都查到了,则更改报文源目的mac,调用bpf helper ctx_redirect将报文重定向到出接口
case BPF_FIB_LKUP_RET_SUCCESS:
break;
//只查到路由表,未查到邻居表,调用bpf helper redirect_neigh查找邻居表,
//如果仍然查不到(大概率还是查不到),则创建邻居表,发送arp学习对端mac
case BPF_FIB_LKUP_RET_NO_NEIGH:
/* GW could also be v6, so copy union. */
nh_params.nh_family = fib_params.family;
__bpf_memcpy_builtin(&nh_params.ipv6_nh, &fib_params.ipv6_dst,
sizeof(nh_params.ipv6_nh));
no_neigh = true;
//下一跳
nh = &nh_params;
break;
default:
//其他情况则返回DROP
return CTX_ACT_DROP;
}
//ttl减一
ipv4_l3(ctx, l3_off, NULL, NULL, ip4);
if (no_neigh) {
if (nh)
//已经有了下一跳,则调用redirect_neigh只需要查找邻居表
return redirect_neigh(*oif, nh, sizeof(*nh), 0);
else
//这个分支是定义了ENABLE_SKIP_FIB的情况,此时调用redirect_neigh会查找路由表和邻居表
return redirect_neigh(*oif, NULL, 0, 0);
}
//更新源目的mac
if (eth_store_daddr(ctx, fib_params.dmac, 0) < 0)
return CTX_ACT_DROP;
if (eth_store_saddr(ctx, fib_params.smac, 0) < 0)
return CTX_ACT_DROP;
//重定向到出接口(此时还未真正重定向,只是设置了标志位和出接口索引,
//后面调用skb_do_redirect时才真正执行报文重定向)
return ctx_redirect(ctx, *oif, 0);
if (likely(ret == CTX_ACT_REDIRECT))
send_trace_notify(ctx, TRACE_TO_NETWORK, SECLABEL, *dst_id, 0, oif, trace.reason, trace.monitor);
return ret;
}
enp0s8(master,tc egress:to-netdev) 这个场景下没具体的作用,只看个trace即可
__section("to-netdev")
int to_netdev(struct __ctx_buff *ctx __maybe_unused)
...
if (!traced)
send_trace_notify(ctx, TRACE_TO_NETWORK, 0, 0, 0,
0, trace.reason, trace.monitor);
return ret;
报文到达node1后的路径如下
报文路径
enp0s8(node1)(tc ingress:from-netdev) -> eth0(pod2)
enp0s8(node1)(tc ingress:from-netdev):
//网卡接收到报文后,走host协议栈处理流程,执行enp0s8接口上挂载的ebpf程序
//ebpf程序处理流程后面会详细介绍
__netif_receive_skb_core
...
if (static_branch_unlikely(&ingress_needed_key)) {
bool another = false;
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
//执行ebpf程序,如果返回值为TC_ACT_REDIRECT,将调用skb_do_redirect将报文重定向到其他接口
switch (tcf_classify_ingress(skb, miniq->block, miniq->filter_list, &cl_res, false)) {
...
case TC_ACT_REDIRECT:
/* skb_mac_header check was done by cls/act_bpf, so
* we can safely push the L2 header back before
* redirecting to another netdev
*/
__skb_push(skb, skb->mac_len);
if (skb_do_redirect(skb) == -EAGAIN) {
__skb_pull(skb, skb->mac_len);
//如果返回值为-EAGAIN,则设置another为true,表示要goto到another重新走一遍协议栈
*another = true;
break;
}
return NULL;
...
}
}
ebpf程序分析
__section("from-netdev")
int from_netdev(struct __ctx_buff *ctx)
return handle_netdev(ctx, false);
return do_netdev(ctx, proto, from_host);
ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_NETDEV);
tail_handle_ipv4_from_netdev
tail_handle_ipv4(ctx, 0, false);
handle_ipv4(ctx, proxy_identity, ipcache_srcid, from_host);
static __always_inline int
handle_ipv4(struct __ctx_buff *ctx, __u32 secctx,
__u32 ipcache_srcid __maybe_unused, const bool from_host)
/* Lookup IPv4 address in list of local endpoints and host IPs */
ep = lookup_ip4_endpoint(ip4);
if (ep) {
/* Let through packets to the node-ip so they are processed by
* the local ip stack.
*/
if (ep->flags & ENDPOINT_F_HOST)
return CTX_ACT_OK;
return ipv4_local_delivery(ctx, ETH_HLEN, secctx, ip4, ep, METRIC_INGRESS, from_host);
mac_t router_mac = ep->node_mac;
mac_t lxc_mac = ep->mac;
ipv4_l3(ctx, l3_off, (__u8 *) &router_mac, (__u8 *) &lxc_mac, ip4);
ctx_store_meta(ctx, CB_SRC_LABEL, seclabel);
ctx_store_meta(ctx, CB_IFINDEX, ep->ifindex);
ctx_store_meta(ctx, CB_FROM_HOST, from_host ? 1 : 0);
//跳转到处理policy的ebpf程序
tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id);
}
__section_tail(CILIUM_MAP_POLICY, TEMPLATE_LXC_ID)
int handle_policy(struct __ctx_buff *ctx)
handle_policy 最终调用到 tail_ipv4_policy
int tail_ipv4_policy(struct __ctx_buff *ctx)
{
struct ipv4_ct_tuple tuple = {};
int ret, ifindex = ctx_load_meta(ctx, CB_IFINDEX);
__u32 src_label = ctx_load_meta(ctx, CB_SRC_LABEL);
bool from_host = ctx_load_meta(ctx, CB_FROM_HOST);
bool proxy_redirect __maybe_unused = false;
enum ct_status ct_status = 0;
__u16 proxy_port = 0;
ctx_store_meta(ctx, CB_SRC_LABEL, 0);
ctx_store_meta(ctx, CB_FROM_HOST, 0);
//执行ingress policy
ret = ipv4_policy(ctx, ifindex, src_label, &ct_status, &tuple, &proxy_port, from_host);
/* Store meta: essential for proxy ingress, see bpf_host.c */
ctx_store_meta(ctx, CB_PROXY_MAGIC, ctx->mark);
return ret;
}
执行ingress policy,如果允许通过则将报文重定向到pod的lxc或者peer口
static __always_inline int
ipv4_policy(struct __ctx_buff *ctx, int ifindex, __u32 src_label, enum ct_status *ct_status,
struct ipv4_ct_tuple *tuple_out, __u16 *proxy_port,
bool from_host __maybe_unused)
//执行ingress policy
verdict = policy_can_access_ingress(ctx, src_label, SECLABEL,
tuple->dport, tuple->nexthdr,
is_untracked_fragment,
&policy_match_type, &audited);
//取出endpoint的ifindex
ifindex = ctx_load_meta(ctx, CB_IFINDEX);
if (ifindex)
//重定向到网卡
return redirect_ep(ctx, ifindex, from_host);
在host routing模式下,ENABLE_HOST_ROUTING会被定义,可将报文直接重定向到lxc的peer接口,即pod内部的eth0
static __always_inline int redirect_ep(struct __ctx_buff *ctx __maybe_unused,
int ifindex __maybe_unused,
bool needs_backlog __maybe_unused)
{
/* Going via CPU backlog queue (aka needs_backlog) is required
* whenever we cannot do a fast ingress -> ingress switch but
* instead need an ingress -> egress netns traversal or vice
* versa.
*/
if (needs_backlog || !is_defined(ENABLE_HOST_ROUTING)) {
return ctx_redirect(ctx, ifindex, 0);
} else {
...
return ctx_redirect_peer(ctx, ifindex, 0);
}
}