class06:node获取数据
目录
一、node获取数据-爬虫
1. 问题分析
第三节中我们可以在自己的后端设置跨域而访问数据,如果我们要获取别人的数据呢?
比如我们打开baidu搜索图片:
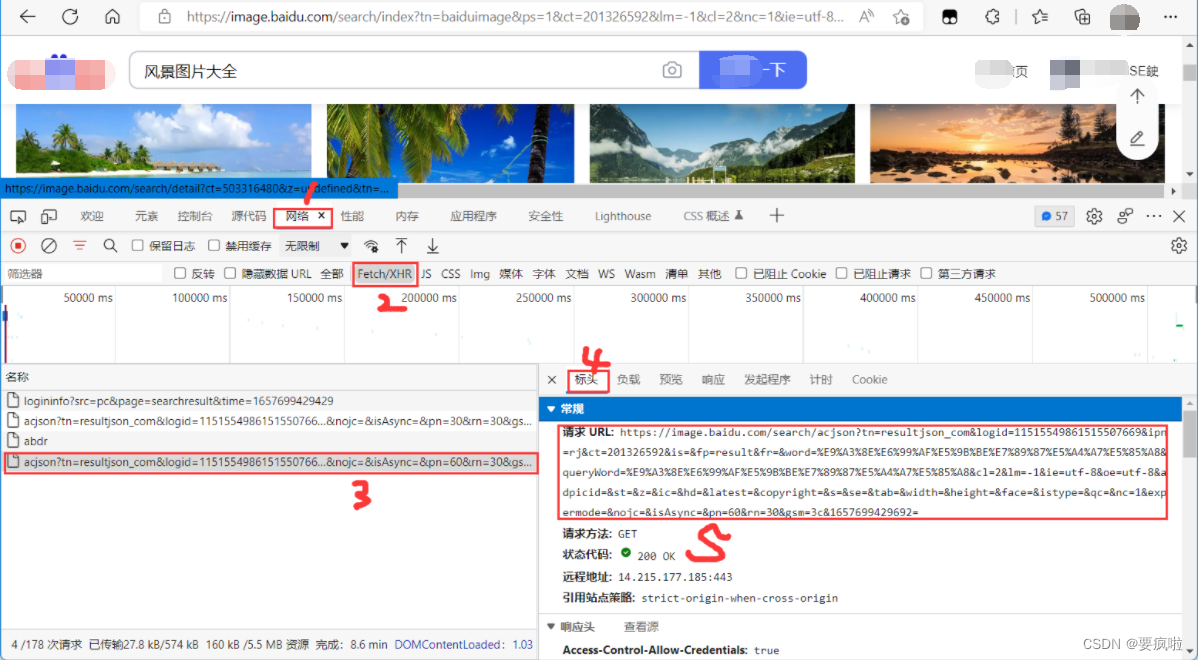
通过上图我们可以获得该页面图片的源码请求URL,复制粘贴该url到浏览器搜索得到源码:
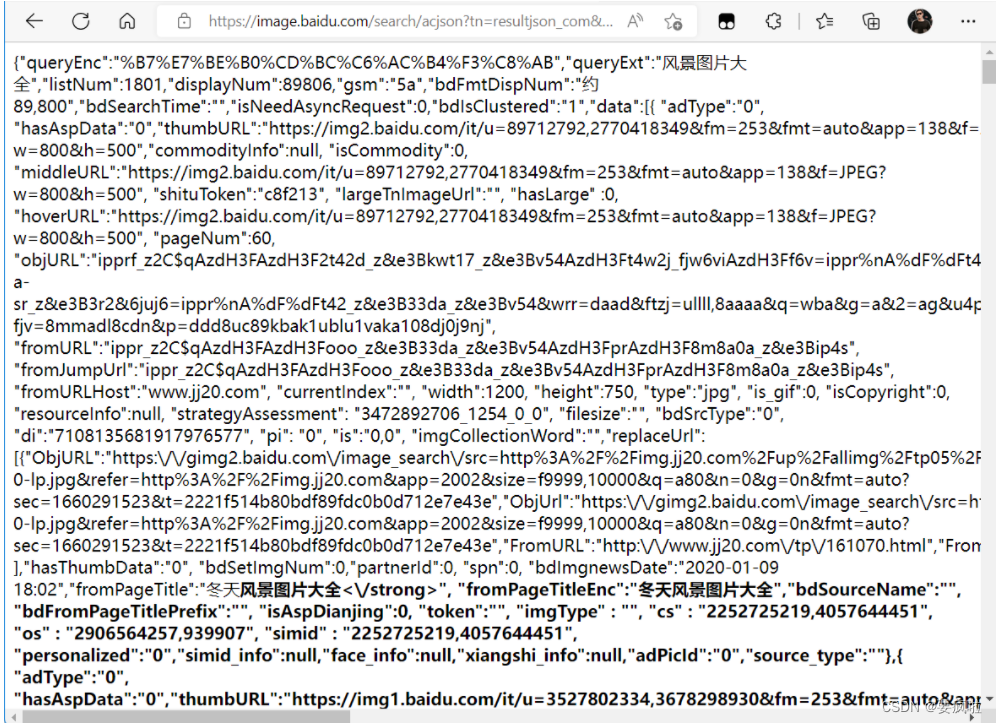
我们可以随便选择一张图片的地址,并复制该地址在浏览器中搜索查看:
图片地址在预览中的位置:data -> xx(数字下标) -> replaceUrl -> 0 -> ObjURL
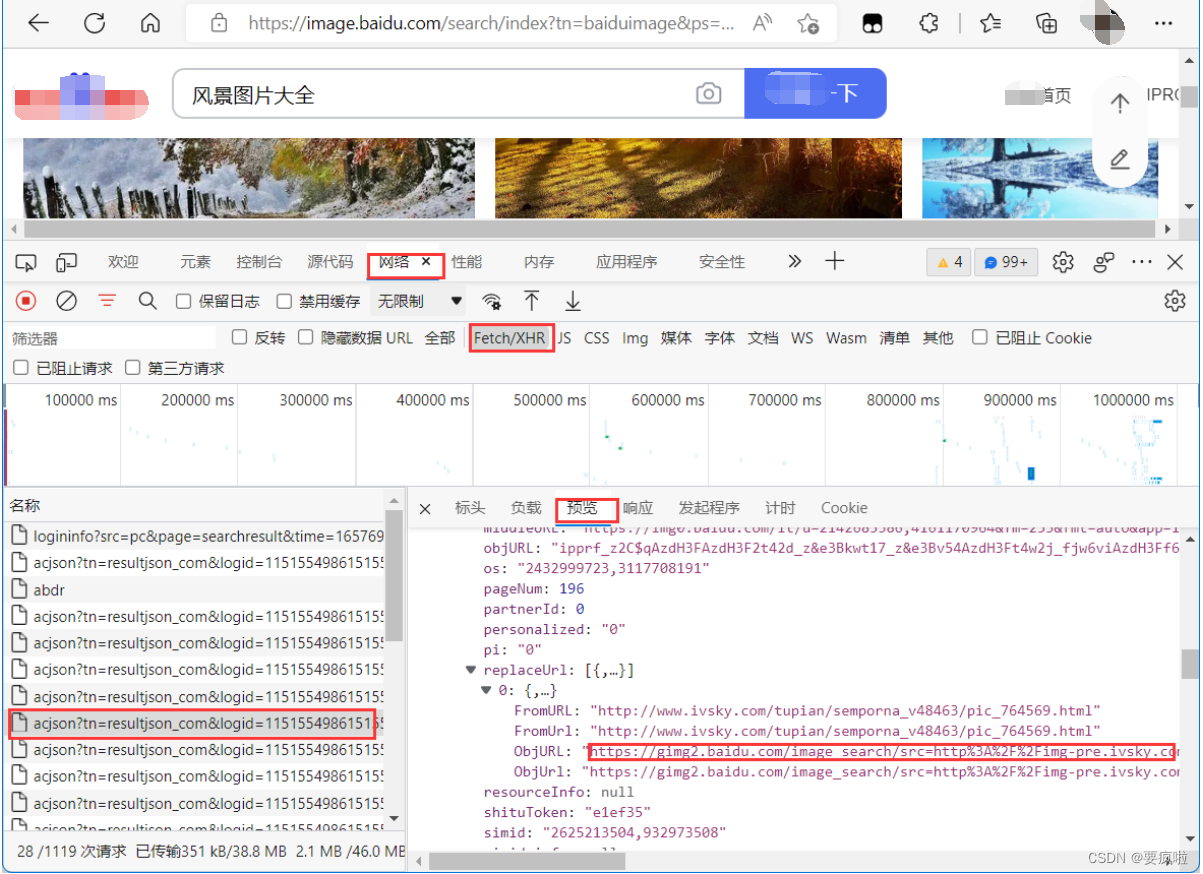
复制该地址在浏览器中搜索查看:
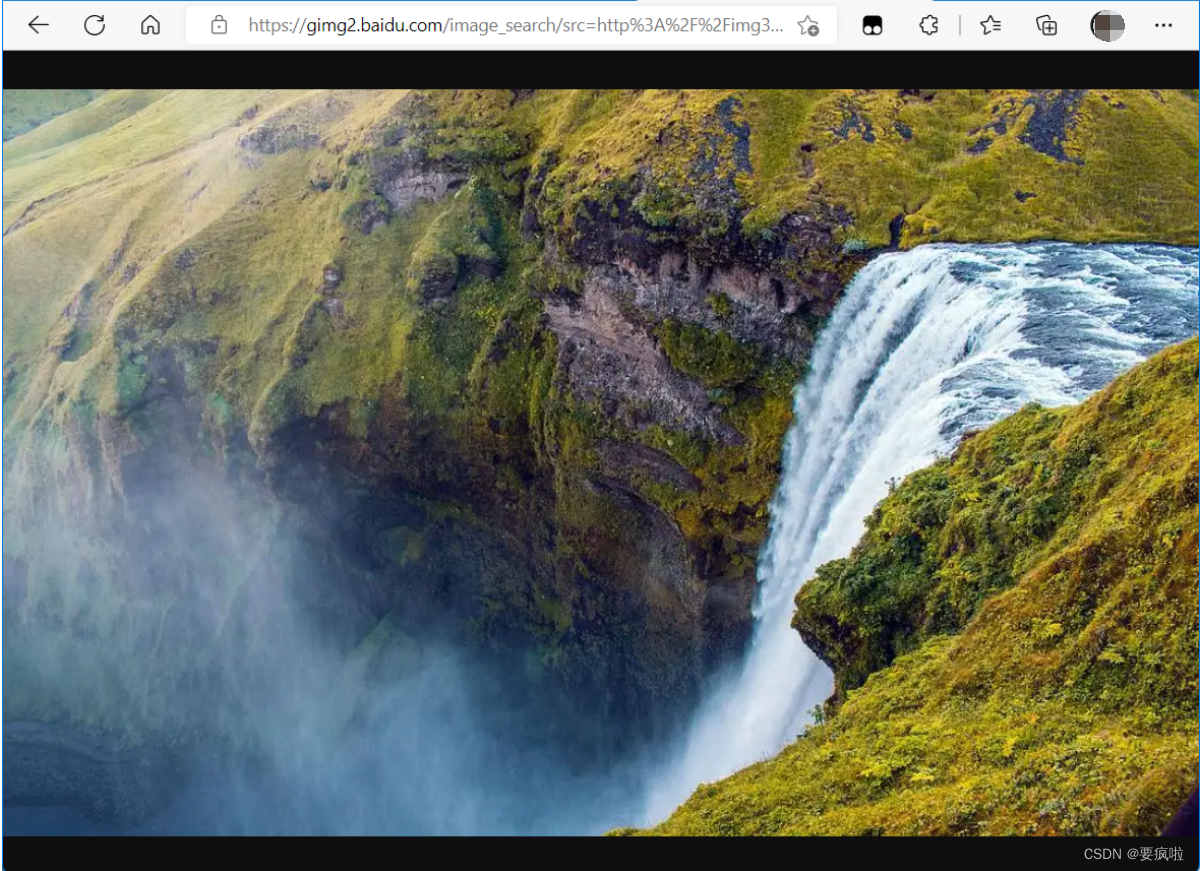
但是我们如果将该图片地址复制到我们写的html页面用axios发起请求可以获得这张图片吗?
答案是否定的,因为跨域问题。我们不可能去修改baidu的后端,那怎么解决呢?
解决方法:通过我们自己的后端去访问数据,因为后端是不存在跨域问题的。通过我们自己的后端模拟浏览器获取数据之后再返回给我们的前端。而我们知道axios可以作用于node和浏览器中,所以我们使用node通过axios获取数据。
2. 初始化
通过npm init -y 初始化生成json文件:
3. 安装axios
npm i axios -S
4. 后端引入axios
const axios = require("axios");
5. 模拟浏览器获取数据
模拟浏览器,即我们自己的后端通过响应头发送信息告诉baidu后端我们的node是一个浏览器(这里的浏览器相当于后端,没有跨域问题)。
找到baidu的请求标头中的User-Agent和请求标头Accept复制到后端node的header中:
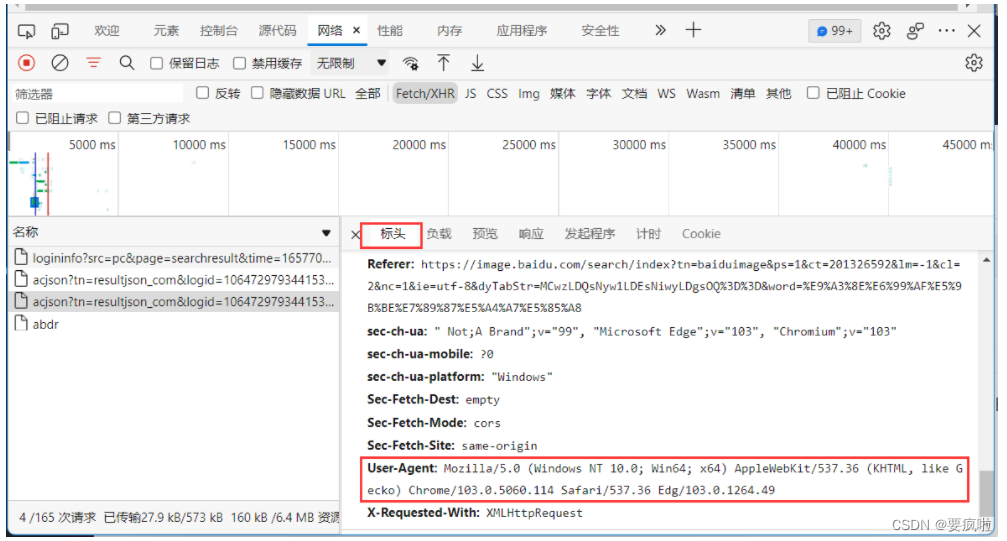
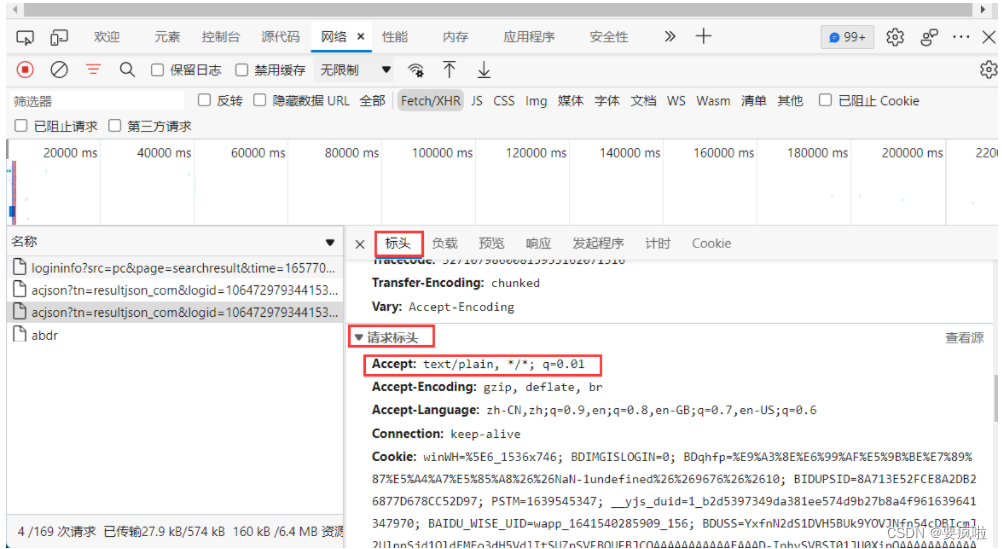
访问地址为标头中的请求URL:
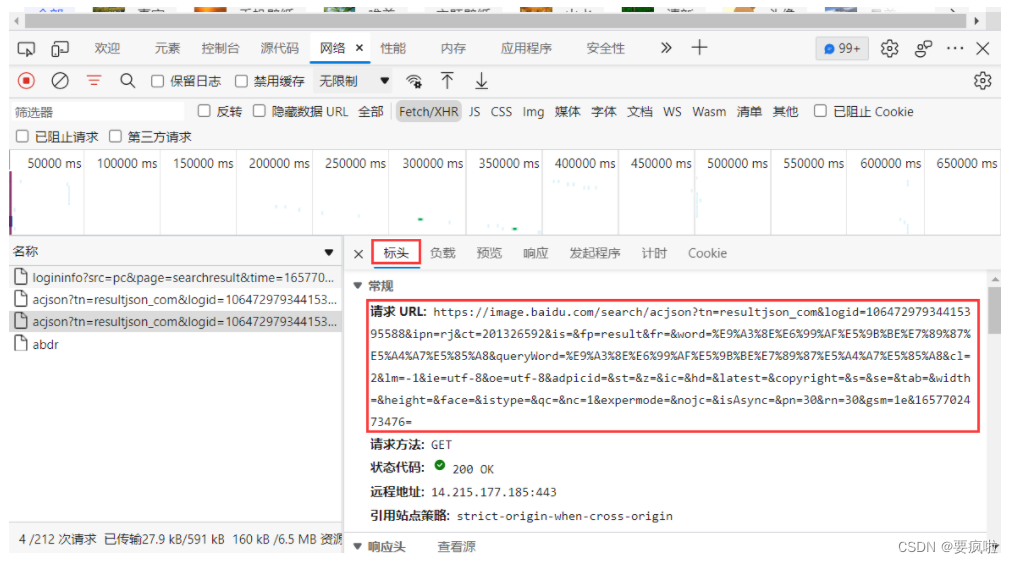
所以js文件代码为:
const axios = require("axios");
axios({
method: "get",
url: "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10647297934415395588&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&queryWord=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1657702473476=",
// 我node后端要告诉baidu的后端我是一个浏览器来请求数据---后端不会产生跨域问题
// headers 发送给baidu后端的信息
headers: {
// 模拟浏览器信息 告诉其他人后端我是一个浏览器
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49",
// 告诉其他后端 我接收的数据格式
"Accept": "text/plain, */*; q=0.01"
}
}).then(result => {
console.log(result.data)
});
执行js文件获取数据:
node app.js
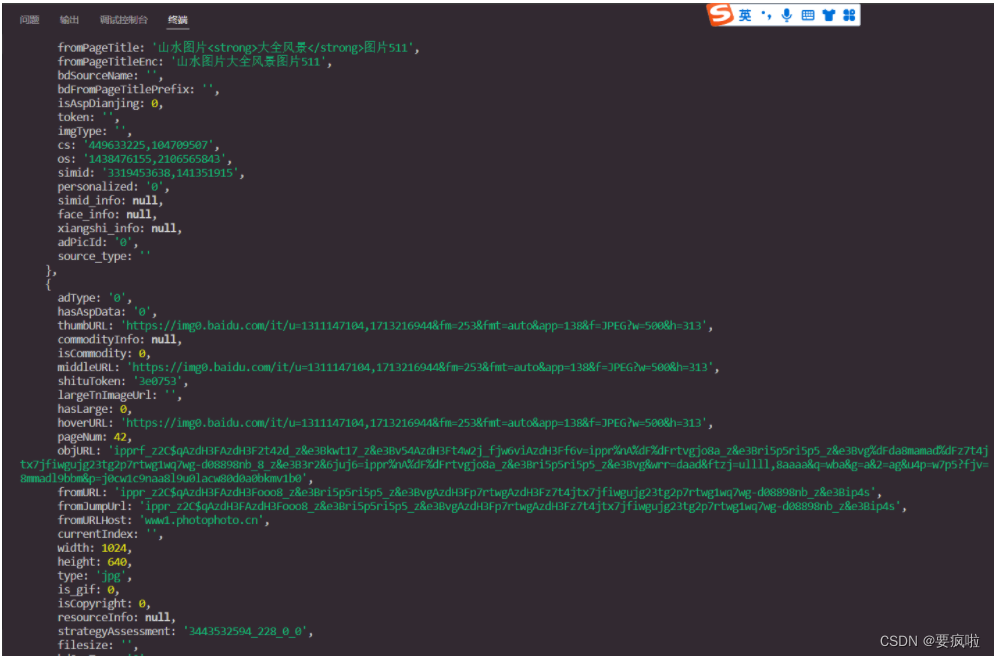
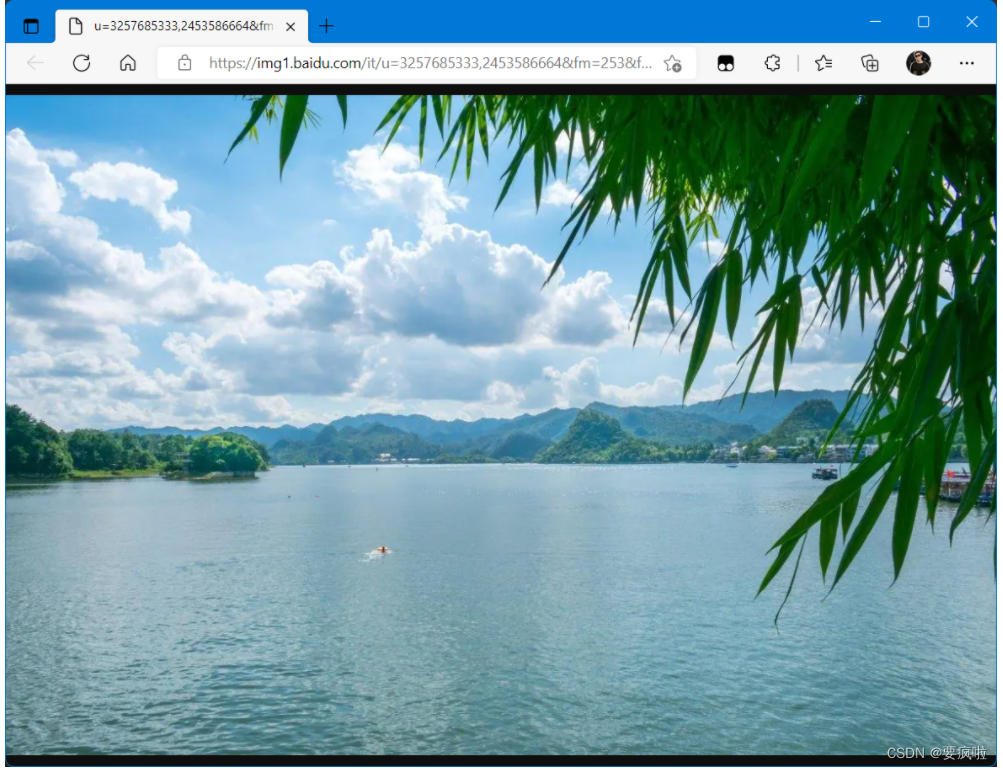
这样我们就获得了baidu图片的网页数据,可以通过"ctrl + 单击"终端的链接查看图片:
6. 返回数据到前端
在js文件中引入http模块,创建和开启http服务并设置跨域:
const http = require("http"); // 引入http模块 用于创建服务器应用
const axios =require("axios"); // 引入 axios 请求数据
let server = http.createServer((req,res)=>{
// 后端设置跨域 允许任何人 能够访问 并返回数据
res.setHeader("Access-Control-Allow-Origin","*");
});
server.listen("3000",()=>{
console.log("启动")
});
设置发起请求的地址,当请求该地址时通过axios获取baidu图片的数据(将之前的模拟浏览器的代码复制到条件语句中):
这里我设置的请求地址后缀为:/img_baidu
if(req.url == "/img_baidu"){
axios({
method: "get",
url: "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10647297934415395588&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&queryWord=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1657702473476=",
// 我node后端要告诉baidu的后端我是一个浏览器来请求数据 后端不会产生跨域问题
// headers 发送给baidu后端的信息
headers: {
// 模拟浏览器信息 告诉其他人后端我是一个浏览器
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49",
// 告诉其他人后端 我接收的数据格式
"Accept": "text/plain, */*; q=0.01"
}
}).then(result => {
console.log(result.data);
res.end(JSON.stringify(result.data))
});
}
注意:.then之后要将获取的数据返回前端,且要进行格式转换:
res.end(JSON.stringify(result.data))
前端html的代码:
<body>
<button id="test">get请求</button>
<script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script>
<script>
test.onclick = function () {
axios({
method: "get",
url: "http://localhost:3000/img_baidu",
}).then(result => {
console.log(result.data)
})
}
</script>
</body >
注意:前端代码中发起请求的地址url要与后端node我们自己设置的一致:/img_baidu;
alt + B 运行html文件,点击按钮获取数据:
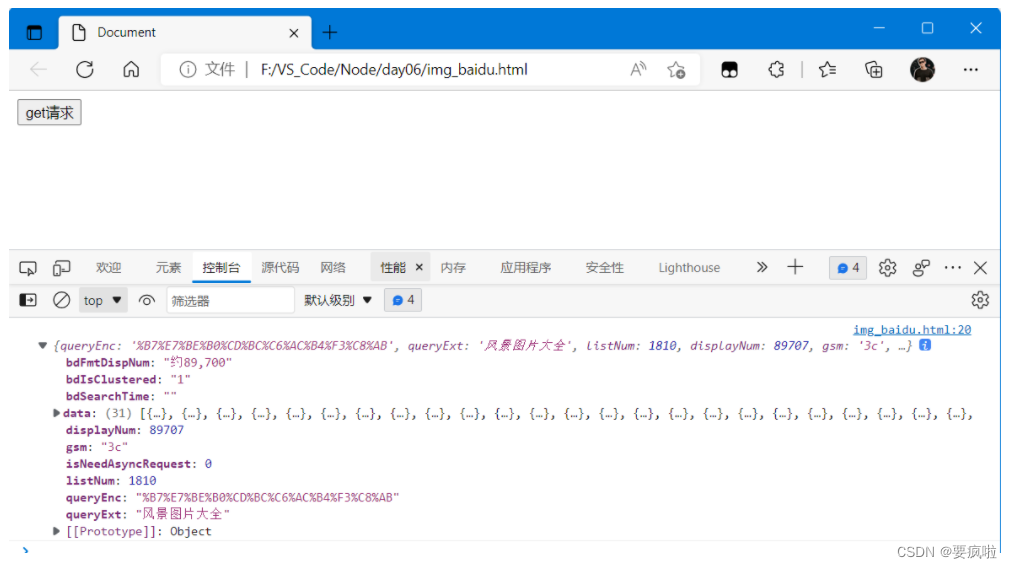
7. 将数据渲染到html页面
我们知道使用axios时页面中的img标签会自动发起请求,所以我们可以通过循环遍历将图片的链接地址赋值到img标签中的src上,而获得图片地址是通过数组中每一项数据的thumbURL获得的。在html页面.then的回调函数中:
<body>
<button id="test">get请求</button>
<h2>将我们获取的图片数据加载到页面中</h2>
<!-- 获取后端数据 渲染到前端页面中 渲染到wrap元素中 -->
<div id="wrap"></div>
<script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script>
<script>
test.onclick = function () {
axios({
method: "get",
url: "http://localhost:3000/img_baidu",
}).then( result => {
console.log(result.data.data);
let frg = document.createDocumentFragment(); // 创建frg文本仓库,否则会重复渲染
result.data.data.forEach(item => {
// 创建img标签,将地址赋值到img上,再将img 插入文本仓库
let img = document.createElement("img");
img.src = item.thumbURL;
frg.appendChild(img)
});
//插入元素
wrap.appendChild(frg)
})
}
</script>
</body>
注意:在接收到后端返回的数据时,我们要遍历的是数组中每一项的图片,是result.data.data;后端代码与上节一样,未做改变。
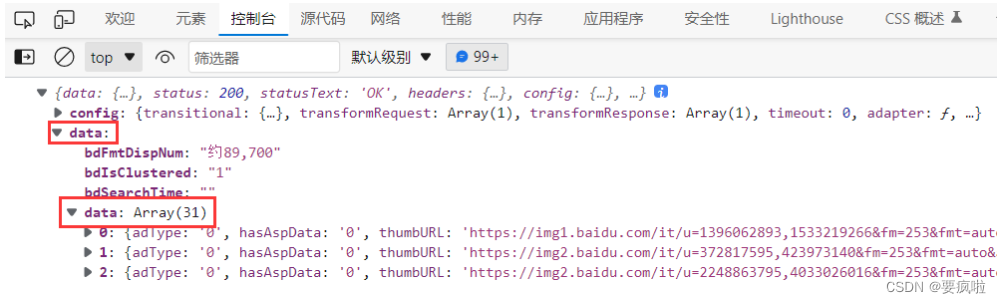
渲染结果部分截图:

终端输出:

该错误与数据有关,后续讲解。
8. 下载html页面的图片
在后端axios的.then函数中先通过结构赋值和.的方式获取到所有图片所在的data数组;然后通过循环遍历该数组获取每一项图片的链接地址thumbURL:
if (req.url == "/img_baidu") {
axios({
method: "get",
url: "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10647297934415395588&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&queryWord=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1657702473476=",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49",
"Accept": "text/plain, */*; q=0.01"
}
}).then(({ data }) => {
// data 第一个axios 获取到的数据,data.data是一个数组
// console.log(data.data);
data.data.forEach((item, index) => { // 数据遍历,获取到每个图片的地址
console.log(item.thumbURL); // 图片的地址
})
});
}
打印输出:
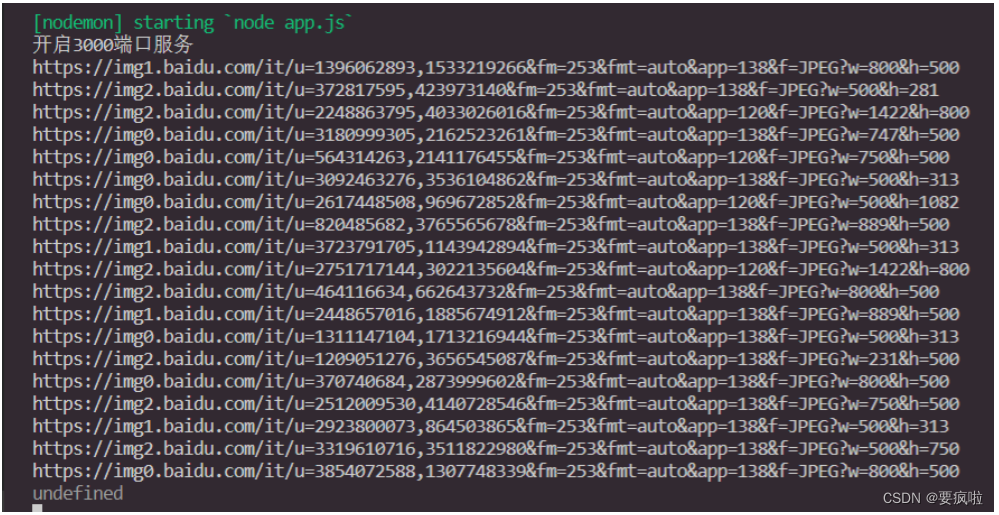
然后通过第二个axios请求获取每一张图片的二进制数据:
// 作用:避免 item.thumbURLios请求的地址为空,地址随意设置
let url = item.thumbURL || "https://img2.baidu.com/it/u=3507648251,3424133896&fm=26&fmt=auto";
axios({ // 第二个axios 请求图片的真正的数据
method: "get",
url: item.thumbURL,
}).then((result) => {
console.log(result)
})
注意:axios获取完整个数组之后会出现undefined的情况,我们可以在循环最后随意设置一个地址解决该情况。
打印输出:

得到二进制数据之后,我们可以将其存入同目录下的data文件夹中,需要引入fs模块:
const fs = require("fs");
但是axios请求将二进制转换成了utf-8格式,我们需要获取数据时要求对方后端以流的格式发送回来,然后通过管道向data文件夹写入数据。
responseType: "stream" //以流的格式发送回来
// 通过管道写入数据
result.data.pipe(fs.createWriteStream("./test/" + index + ".jpg"))
代码如下:
let url = item.thumbURL || "https://t7.baidu.com/it/u=2168645659,3174029352&fm=193&f=GIF"; // 默认自己随意设置的
axios({ // 第二个axios 请求图片的真正的数据
method: "get",
url: url,
responseType: "stream", // 告诉对方的后端将数据以流的格式发送回来
}).then((result) => {
console.log(result);
// 通过管道写入数据
result.data.pipe(fs.createWriteStream("./test/" + index + ".jpg"))
})
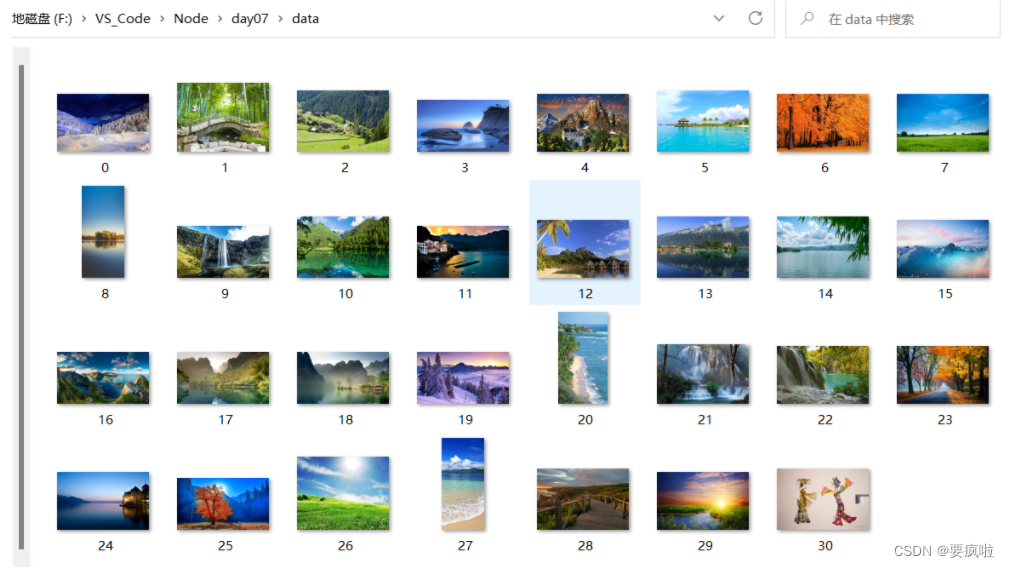
打开写入图片的文件夹,图片获取成功:
完整代码:
const http = require('http'); //引入http模块,用于创建服务器应用
const axios = require("axios");
const fs = require("fs");
// 创建服务器应用
let serve = http.createServer((req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
if (req.url == "/img_baidu") {
axios({
method: "get",
url: "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10647297934415395588&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&queryWord=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87%E5%A4%A7%E5%85%A8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1657702473476=",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49",
"Accept": "text/plain, */*; q=0.01"
}
}).then(({ data }) => {
// data 第一个axios 获取到的数据 data.data是一个数组
// console.log(data.data);
data.data.forEach((item, index) => { // 数据遍历 获取到每个图片的地址
// console.log(item.thumbURL); // 图片的地址
// 作用避免 axitem.thumbURLios请求的地址为空 地址随意设置
let url = item.thumbURL || "https://t7.baidu.com/it/u=2168645659,3174029352&fm=193&f=GIF"; // 默认自己随意设置的
axios({ // 第二个axios 请求图片的真正的数据
method: "get",
url: url,
// url: item.thumbURL,
responseType: "stream", // 告诉对方的后端将数据以流的格式发送回来
}).then((result) => {
// console.log(result);
// 通过管道写入数据
result.data.pipe(fs.createWriteStream("./data/" + index + ".jpg"))
})
})
});
}
});
// 启动监听端口号,我们应用运行的地址
serve.listen("3000", () => {
console.log("开启3000端口服务")
});
二、小说爬虫
1. 单个页面爬取
比如我们搜索biqvge,随便打开一本小说:
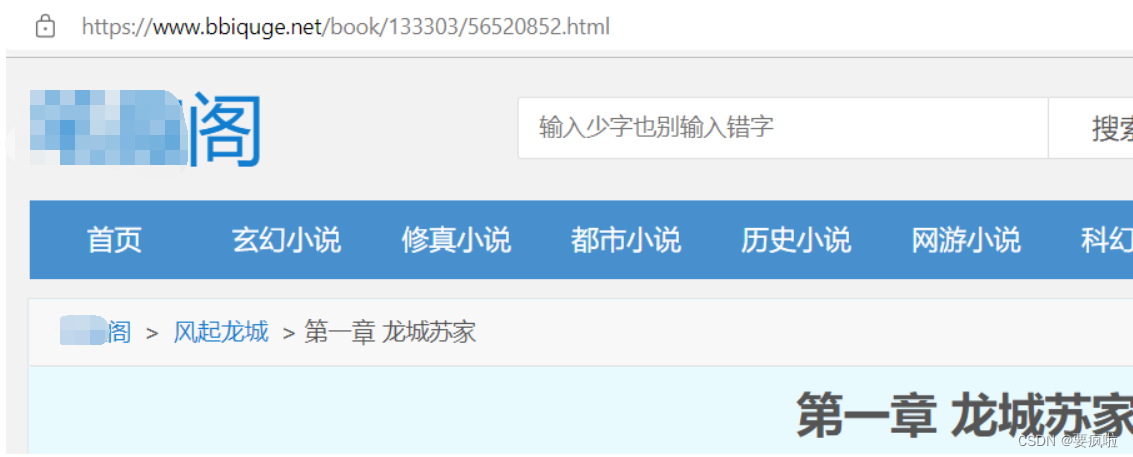
用网址通过axios发起请求:
const axios = require("axios");
const fs =require("fs");
axios({
method:"get",
url:"https://www.bbiquge.net/book/133303/56520852.html"
}).then(( {data} )=>{
console.log(data)
});
打印输出解构赋值后的data:
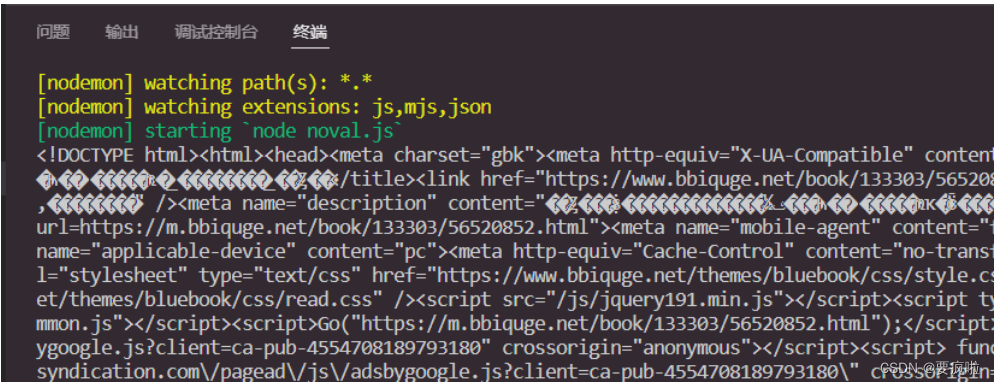
乱码是因为node不能解析gbk格式,解析gbk格式非常复杂,所以我们只能换小说。。。。爬取utf-8格式的网页。
找到啦找到啦:
https://www.17k.com/chapter/3006464/38107770.html
打印输出:

现在我们获取到整个页面,文字也是页面中的数据,只要把文字复制下来再写入就可以了。但是node是没有办法操作节点的,我们可以通过第三方包来获取 => jsdom => 用于node中操作dom节点
安装jsdom:
npm i jsdom -S
jsdom的使用说明可以在npm官网查看:jsdom - npm (npmjs.com)
引入jsdom:
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
使用jsdom:
向构造函数传递一个字符串。您将获得一个对象,该对象具有许多有用的属性;
通过new方式使用jsdom,参数是字符串(html整个页面相当于字符串):
通过对节点操作,我们可以获取到取出标签后的纯文字内容:
axios({
method: "get",
url: "https://www.17k.com/chapter/3006464/38107770.html"
}).then(({ data }) => {
const dom = new JSDOM(data); // 将后端具有标签字符串转换可以通过js方法获取节点或者内容
console.log(dom.window.document.querySelector(".p").textContent); // 获取节点 和 js的使用方法一样
});

注意: 代码.querySelector(“.p”)中的p指的是html页面中小说内容的class类的名称。
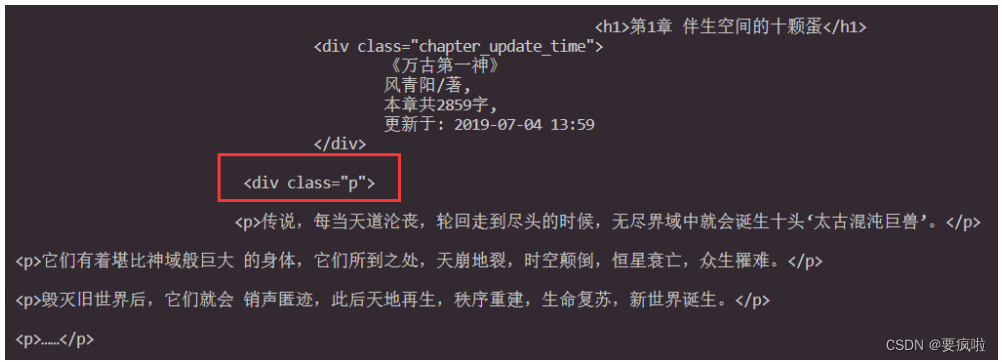
写入文本:
通过fs模块的writeFile方法将文本内容写入文档:
let value = dom.window.document.querySelector(".p").textContent.trim(); //trim()用于将文本格式从头写入
fs.writeFile("./text/01.txt", value, () => {
console.log("获取成功")
})
爬取结果:
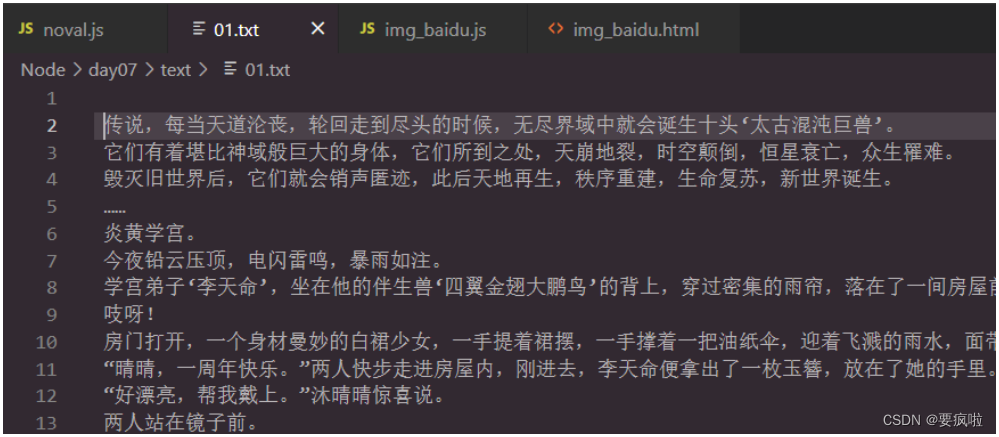
完整代码:
const axios = require("axios");
const fs = require("fs");
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
axios({
method: "get",
url: "https://www.17k.com/chapter/3006464/38107770.html"
}).then(({ data }) => {
// console.log(data)
// 向构造函数传递一个字符串。您将获得一个对象,该对象具有许多有用的属性
// 通过new方式使用jsdom,参数是字符串
const dom = new JSDOM(data);
// console.log(dom.window.document.querySelector(".p").textContent);
let value = dom.window.document.querySelector(".p").textContent; //trim()用于将文本格式从头写入
fs.writeFile("./text/01.txt", value, () => {
console.log("获取成功")
})
});
2. 整个小说爬取
要获取整个小说,我们可以先获取第一个页面,获取到里面的文字同时获取到下一章的跳转地址,再通过axios获取下一章页面的数据,再获取里面的文字,以此循环,就可以拿到整个小说 。
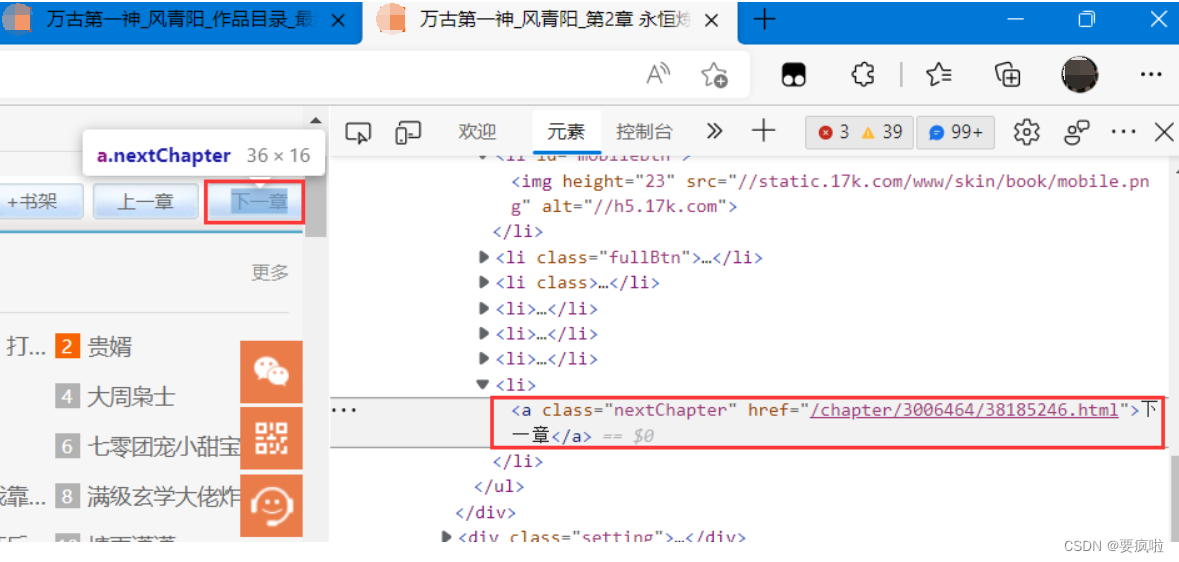
可以看到,html给的下一章的地址是不全的,前面还需要拼接https://www.17k.com/;
我们通过对节点操作获取属性值尝试获取类.nextChapter中的href下一章地址:
function fun(url) {
axios({
method: "get",
url: url
}).then(({ data }) => {
// 获取属性值:元素.getAttribute("属性名") 返回属性值
let nexturl = dom.window.document.querySelector(".nextChapter").getAttribute("href");
console.log(nexturl);
});
}
fun("https://www.17k.com/chapter/3006464/38107770.html"); // 函数执行
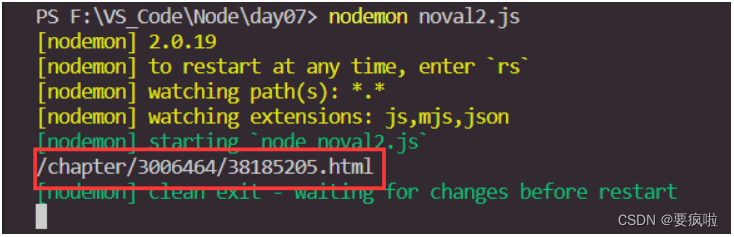
然后通过拼接得到完整地址,再将文本内容通过追加的方式 {flag:“a”} 写入文档:
写入之后,我们通过循环调用函数不断的读取下一章内容,使程序自动运行:
完整代码:
const axios = require("axios");
const fs = require("fs");
const { JSDOM } = require("jsdom");
function fun(url) {
axios({
method: "get",
url: url
}).then(({ data }) => {
const dom = new JSDOM(data);
let value = dom.window.document.querySelector(".p").textContent;
// 获取属性值:元素.getAttribute("属性名") 返回属性值
let nextUrl = dom.window.document.querySelector(".nextChapter").getAttribute("href");
// console.log(nextUrl);
// nextUrl是一空值,则打断程序运行
if (!nextUrl) return;
// 拼接地址
nextUrl = "https://www.17k.com" + nextUrl;
// 在一个文件内 追加写入内容
fs.writeFile("./text/02.txt", value, { flag: "a" }, () => {
console.log(nextUrl + "的上一章写入成功");
fun(nextUrl) // 函数循环调用,获取下一章内容
})
});
}
fun("https://www.17k.com/chapter/3006464/38107770.html"); // 函数执行,先获取第一章内容
爬取结果:
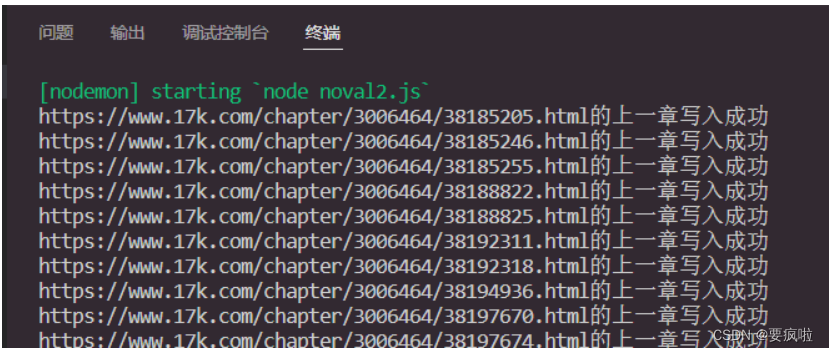

注意:在读取到第五十一章时报错了,复制该章链接到浏览器中搜索:
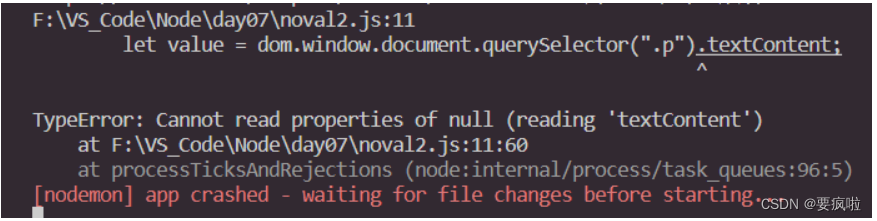
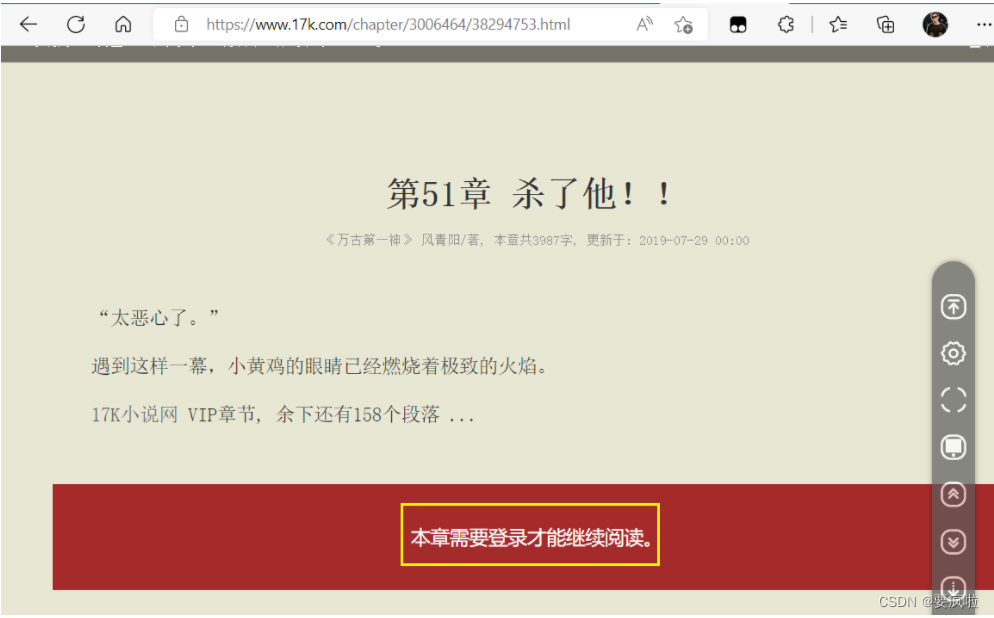
结果是需要登录才能阅读,所以获取不到网页的文本内容和下一章地址。。。