目标检测-One Stage-YOLOv1
前言
前文目标检测-Two Stage-Mask RCNN提到了Two Stage算法的局限性:
- 速度上并不能满足实时的要求
因此出现了新的One Stage算法簇,YOLOv1是目标检测中One Stage方法的开山之作,不同于Two Stage需要先通过RPN网络得到候选区域的方法,YOLOv1将检测建模为一个回归问题,直接在整张图的特征图(Feature Map)上进行目标的定位和分类,因此速度比当时正红的Fast R-CNN快很多。而且,也正是因为YOLOv1看的是全局的信息,把背景误判成目标的错误率比只看候选区的Fast R-CNN低很多,但整体的准确率还是Fast R-CNN高。
提示:以下是本篇文章正文内容,下面内容可供参考
一、YOLOv1的网络结构和流程
- 首先将输入图像划分成7 * 7的网格
- 使用ImageNet数据集(224大小)对前20层卷积网络进行预训练
- 使用PASCAL VOC数据集(448大小)对完整的网络进行对象识别和定位的训练
- 对于每个网格都预测2个边框(bounding box),即预测98(7 * 7 * 2)个目标窗口,输出7 * 7 * 2 * 30 的张量。
ps:最后一维为30,包含每个预测框的分类与位置信息:20个类别的概率+2个边框的置信度+2*4(2个边框的位置,每个边框4个参数:x_center, y_center, width, height)
- 根据上一步预测出98个目标窗口,使用非极大值抑制NMS去除冗余窗口
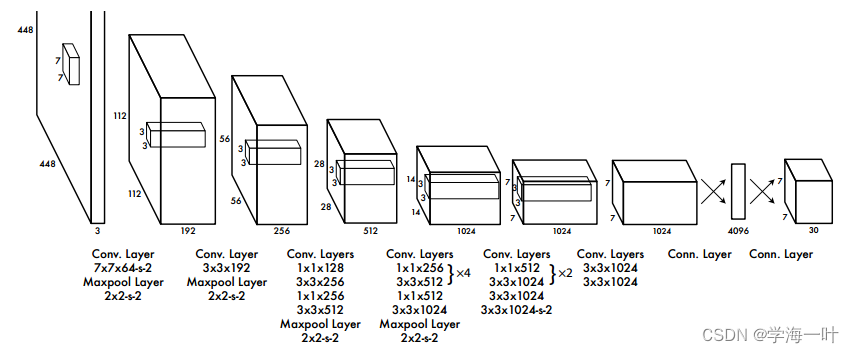
ps:YOLOv1的最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了drop out和数据增强(data augmentation)来防止过拟合。
二、YOLOv1的损失函数
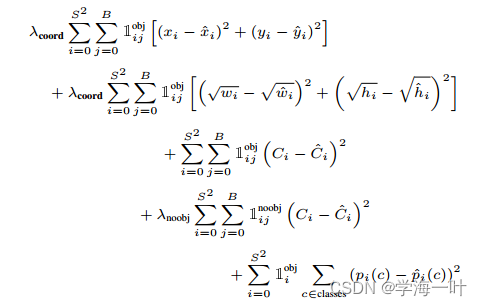
可看出由5个部分组成:(真阳样本的中心定位误差、宽高误差、confidence误差),负样本confidence误差,正样本类别误差
- 可以看到宽高误差先取了平方根,这样可以降低大小对象对差值敏感度的差异
- 超参数 λ c o o r d = 5 , λ n o o b j = 0.5 \lambda_{coord}=5,\lambda_{noobj}=0.5 λcoord=5,λnoobj=0.5,可看出真阳样本位置误差的权重较高,负样本置信度误差权重低
三、YOLOv1的创新点
- 去除候选区模块,直接将目标检测任务转换成一个简单的回归问题,大大加快了检测的速度(45fps-155fps)
- 由于每个网络预测目标窗口时使用的是全图信息(图片的全局特征),使得false positive比例大幅降低(充分的上下文信息),precision较高
总结
尽管YOLOv1速度提升很多,但是精度较低:
- 每个格子只能预测一个物体,且仅利用了单尺度特征图,对较小对象和密集型的物体检测不友好
- 7 * 7的粗糙网格内对目标框不加限制的回归预测,使得定位不够精准
- 预训练时与实际训练时输入大小不一致,模型需要去适应这种分辨率的转换,会影响最终精度