10个超级实用的Python模块,建议收藏!!
Python标准库有超过200个模块,程序员可以在他们的程序中导入和使用,虽然普通程序员对其中许多模块都有一些经验,但很可能有一些好用的模块他们仍然没有注意到。
今天小编就来给大家推荐几个特别好用的Python模块,其中有一部分是在Pandas当中的,方便大家使用了之后更加高效地来进行数据分析。
xmltodict
首先给大家介绍的第三方模块叫做xmltodict,我们从名字上就可以非常直观地看出,该模块的作用在于将xml格式的数据转换成字典,要是没有安装该模块的童鞋,可以通过pip命令来进行安装
pip install xmltodict假设有如下所示的xml格式的数据
<?xml version='1.0' encoding='utf-8'?>
<mydocument has="an attribute">
<and>
<many>elements</many>
<many>more elements</many>
</and>
<plus a="complex" b="hello">
element as well
</plus>
</mydocument>我们尝试来读取当中的数据,用到xmltodict模块,代码如下
xml_result = open('testdb.xml', 'r')
xml_dict = xmltodict.parse(xml_result.read())
print(type(xml_dict))
print(xml_dict)output
<class 'dict'>
{'mydocument': {'@has': 'an attribute', 'and': {'many': ['elements', 'more elements']}, 'plus': {'@a': 'complex', '@b': 'hello', '#text': 'element as well'}}}我们也可以尝试来读取当中的一些数据,代码如下
xml_dict.get("mydocument").get("and")output
{'many': ['elements', 'more elements']}当然我们还可以转换回去,转换成xml格式的数据,这里需要用到的是unparse()方法,代码如下
dict_xml = xmltodict.unparse(xml_dict, pretty=True)UltraJSON
ultrajson的底层是用C来编写的,因此作为一个超高速的json编码器和解码器,可以用作是其他大多数json解析器的替换,我们先用pip命令来将其安装
pip install ujson我们来尝试使用该模块来解析一下如下的数据,代码如下
import ujson
ujson.dumps([{"key1": "value1"}, {"key2": "value2"}])output
'[{"key1":"value1"},{"key2":"value2"}]'使用dumps()方法输出的数据就是以字符串的形式来展现的,与此同时呢还有loads()方法针对字符串格式的数据进行转换
ujson_result = ujson.loads("""[{"key1": "value1"}, {"key2": "value2"}]""")要是我们想要获取列表当中第一个元素的值,就可以这么来做了
ujson_result[0].get("key1")output
value1arrow
Arrow提供了一个友好而且非常易懂的方法,用于创建时间、计算时间、格式化时间,还可以对时间做转化、提取、兼容python datetime类型。根据其文档的描述,Arrow模块旨在帮助使用者用更少的代码来处理日期和时间
例如我们想要知道当前的时间,代码如下
import arrow
now = arrow.now()
print(now)output
2022-12-05T05:04:19.353774+08:00当然我们可以用format()方法来格式化日期和时间,具体代码如下
import arrow
now = arrow.now()
year = now.format('YYYY')
print("Year: {0}".format(year))
date = now.format('YYYY-MM-DD')
print("Date: {0}".format(date))
date_time = now.format('YYYY-MM-DD HH:mm:ss')
print("Date and time: {0}".format(date_time))
date_time_zone = now.format('YYYY-MM-DD HH:mm:ss ZZ')
print("Date and time and zone: {0}".format(date_time_zone))output
Year: 2022
Date: 2022-12-05
Date and time: 2022-12-05 10:41:01
Date and time and zone: 2022-12-05 10:41:01 +08:00与此同时,我们还能查看一下当下其他时区中的时间,代码如下
utc = arrow.now()
print(utc.to('US/Pacific').format('HH:mm:ss'))
print(utc.to('Europe/Paris').format('HH:mm:ss'))
print(utc.to('Europe/Moscow').format('HH:mm:ss'))output
18:48:14
03:48:14
05:48:14fire
目前Python的命令行模块有argparse(Python的标准库)、click等,但是这些库在使用上都比较麻烦,本文介绍的Fire模块用起来十分的方便,并且可用于任何Python对象自动生成命令行接口,我们来看下面这个例子
import fire
def hello(name="World"):
return "Hello %s!" % name
if __name__ == '__main__':
fire.Fire(hello)我们可以在命令行中运行python 文件名.py,得到结果Hello World!,或者我们可以添加上相应的参数
python 文件名.py --name=Tomoutput
Hello Tom!而当我们不知道怎么来添加这些参数的时候,就可以通过--help来进行查看,
python 文件名.py --helpoutput
INFO: Showing help with the command '文件名.py -- --help'.
NAME
文件名.py
SYNOPSIS
文件名.py <flags>
FLAGS
--name=NAME
Default: 'World'我们可以来写一个计算器对象来做一个输入数字的平方计算,代码如下
class Calculator(object):
"""A simple calculator class."""
def square(self, number):
return number ** 2
if __name__ == '__main__':
fire.Fire(Calculator)我们可以这样来尝试,代码如下
python 文件名.py square 10output
100或者是
python 文件名.py square --number=5output
25tinydb
tinydb是一个用纯Python编写的轻量级数据库,从名字上面我们就能够看出来它十分的轻便,它的由来就是为了降低小型Python应用程序使用数据库的难度,对于一些简单的程序而言与其是用SQL数据库,还不如就使用Tinydb,我们先用pip命令安装一下
pip install tinydb我们先初始化一个DB文件,代码如下
from tinydb import TinyDB
db = TinyDB('db.json')同时我们也可以往里面添加几条数据,调用的方法是insert()或者是insert_multiple(),代码如下
db.insert({'type': 'apple', 'count': 10})
db.insert({'type': 'banana', 'count': 20})
db.insert_multiple([
{'name': 'John', 'age': 22},
{'name': 'John', 'age': 37}])要是我们想要查看所有的数据,调用的就是all()方法了,代码如下
from tinydb import TinyDB
db = TinyDB('db.json')
db.all()output
[{'type': 'apple', 'count': 10}, {'type': 'banana', 'count': 20}, {'name': 'John', 'age': 30}, {'name': 'Tom', 'age': 45}]而当我们需要搜索指定的数据时,就需要用到Query()方法,代码如下
from tinydb import TinyDB, Query
db = TinyDB('db.json')
Fruit = Query()
db.search(Fruit.type == 'apple')output
[{'type': 'apple', 'count': 10}]或者是要更新数据的时候,就用到update()方法
db.update({'type': 'apple', 'count': 40})
Fruit = Query()
db.search(Fruit.type == 'apple')output
[{'type': 'apple', 'count': 40而要是清空整个数据库的话,调用的则是truncate()方法,代码如下
from tinydb import TinyDB
db = TinyDB('db.json')
db.truncate()
db.all()output
[]删除某条数据的话,调用的是remove()方法,
db.remove(Fruit.count < 15)
db.all()output
[{'type': 'banana', 'count': 20}]sidetable
sidetable是一种可用于数据分析和探索的工具模块,作为value_counts()和crosstab两者组合来使用的,它能够实现的用途对于Pandas模块而言也都能实现,但是步骤更加简便。
首先我们先通过pip命令来安装该模块
pip install sidetable紧接着我们读取本次教程需要用到的数据集,代码如下
import pandas as pd
import sidetable
sales = pd.read_csv(
"sales_data_with_stores.csv",
usecols = ["store", "product_group", "product_code", "cost",
"price", "last_week_sales"]
)
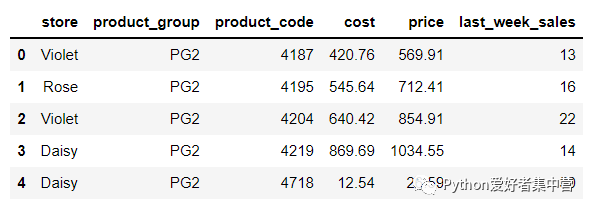
sales.head()output
初步分析
例如我们看到这个product_group这一栏,也就是产品组,要是我们想要知道总共有哪些产品组?每一组产品总共有多少?占到的比重又是多少,就可以调用其中freq()方法,这个就和Pandas当中的groupby方法十分地类似,代码如下
sales.stb.freq(["product_group"])output
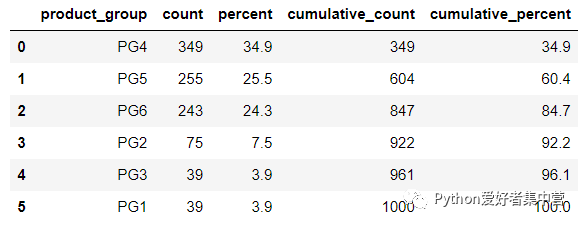
那么从上面的结果中我们可以看到,总共有6个产品组以及各自的占比情况如何和累积的占比情况。当然上述的结果本质上是基于表格当中各个产品的行数是多少,而当我们想要看一下各个产品的销量情况时,就需要用到last_week_sales字段了,代码如下
sales.stb.freq(["product_group"], value="last_week_sales")output
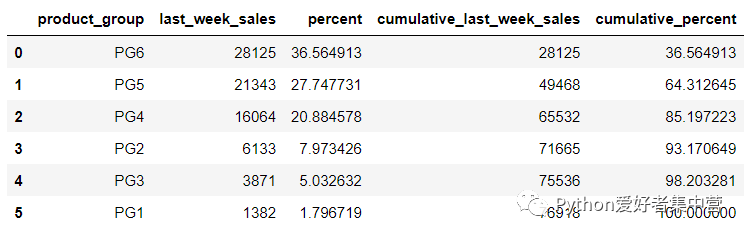
然后我们要是还想进一步深挖数据集当中的信息,例如想要看一下每一组产品在每一家门店中的销量情况,就需要用到store字段,代码如下
sales.stb.freq(["product_group", "store"], value="last_week_sales")output
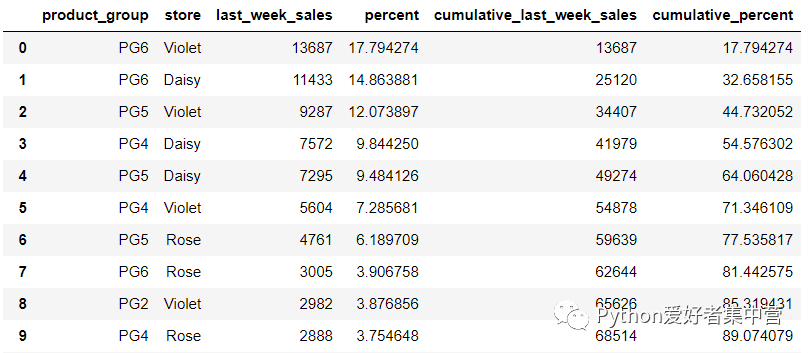
缺失值
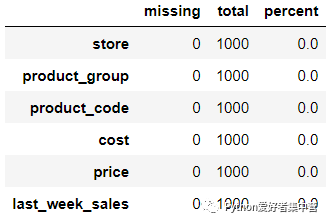
我们来看一下表格当中的缺失值的分布,代码如下
sales.stb.missing()output
subtotal计算
那么对于分组的结果而言,sidetable还可以计算得出每个分组的subtotal(小计),代码如下
sales_filtered = sales[sales["product_group"].isin(["PG1", "PG2"])]
sales_filtered.groupby(["store", "product_group"]).agg(
total_sales = ("last_week_sales", "sum")
)output
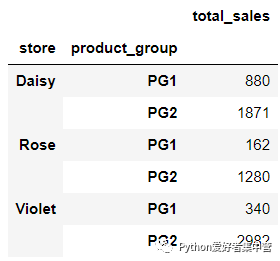
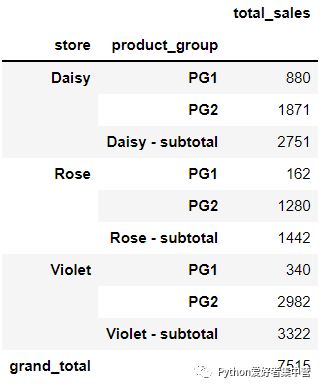
我们筛选出了一二两组在每家门店当中的销量情况,而对于sidetable而言还能够轻松的计算出每家门店销量的总和,代码如下
sales_filtered.groupby(["store", "product_group"]).agg(
total_sales = ("last_week_sales", "sum")
).stb.subtotal()output
eval()函数
Pandas提供了通过eval()进行表达式计算的功能,我们依次可以写出简洁、易读的代码,例如有下面这么一个数据集
df = pd.DataFrame({"animal": ["dog", "cat"], "age": [20, 30]})
dfoutput

我们可以调用pd.eval()方法来新建一列,代码如下
pd.eval("double_age = df.age * 2", target=df)output

该函数仅对列进行操作,而不对特定行或者元素进行操作。我们再来看几个示例,代码如下
df = pd.DataFrame(dict(a=range(5), b=range(5, 10)))
df.eval("c = a + b", inplace=True)
df.eval("d = a + b + c", inplace=True)
df.eval("a = 5", inplace=True)
dfoutput

因此,我们只需要传入需要计算的表达式字符串即可得到想要的结果。
exec()函数
Python内置的exec函数,用来执行一段Python代码,这段代码以字符串的形式传给exec函数执行,例如
exec('''
... for i in range(10):
... print(i)
... ''')output
0
1
2
3
4
5
6
7
8
9而该函数的第二个参数具体是用来控制exec函数内执行代码可以访问的全局变量资源,如下代码所示
exec('''
print(a)
print(b)
print(d)
c = 3
print(c)''', {'a':111,'b':222,'d':444})output
111
222
444
3exec()函数除了能执行复杂的代码片段,还可以执行py文件中的Python代码,例如有test.txt文件,内容如下
# !usr/bin/env python
# -*- coding:utf-8 _*-
# test.txt
def main():
x = 30
y = 40
print(x*y)
print("www.baidu.com")
if __name__ == "__main__":
main()然后使用内置函数exec()执行这个txt文件的Python代码:
with open('test.txt','r') as f:
exec(f.read())output
1200
www.baidu.comNO.1
往期推荐
Historical articles
Python办公利器:Python-docx,解放双手、事半功倍!!
【实用原创】20个Python自动化脚本,解放双手、事半功倍
分享、收藏、点赞、在看安排一下?



