【计算机视觉 | 目标检测】Open-Vocabulary DETR with Conditional Matching论文解读
文章目录
一、导读
论文题目:具有条件匹配的开放词汇表DETR

开放词汇对象检测是指在自然语言的引导下对新对象进行检测的问题,越来越受到社会的关注。理想情况下,我们希望扩展一个开放词汇表检测器,这样它就可以基于自然语言或范例图像形式的用户输入生成边界框预测。这为人机交互提供了极大的灵活性和用户体验。为此,我们提出了一种新的基于DETR的开放词汇检测器,因此命名为OV-DETR,一旦训练,它可以检测任何给定其类名或样本图像的对象。
将DETR转变为开放词汇检测器的最大挑战是,如果不访问新类的标记图像,就不可能计算新类的分类成本矩阵。为了克服这一挑战,我们将学习目标制定为输入查询(类名或示例图像)与相应对象之间的二进制匹配目标,从而学习有用的对应关系,以便在测试期间推广到未见过的查询。对于训练,我们选择将Transformer解码器设置在从预训练的视觉语言模型(如CLIP)获得的输入嵌入上,以便对文本和图像查询进行匹配。通过在LVIS和COCO数据集上的大量实验,我们证明了OV-DETR—第一个端到端基于变压器的开放词汇检测器——比目前的技术水平取得了重大改进。
在计算机视觉中,“binary matching”(二进制匹配)通常指的是一种图像特征匹配的方法,用于比较两幅图像之间的相似性。
具体来说,二进制匹配常用于描述二进制特征描述符,例如二进制局部二进制模式(Local Binary Patterns, LBP)或二进制描述子(Binary Descriptors)。这些特征描述符将图像中的局部区域编码为二进制形式,以表示该区域的纹理、形状或其他重要特征。
在二进制匹配的过程中,首先需要提取图像中的特征描述符,然后将其转换为二进制形式。对于每个描述符,会将其与其他描述符进行比较,以计算它们之间的相似性。通常使用一种距离度量(如汉明距离)来衡量两个二进制描述符之间的差异。如果二进制描述符之间的差异小于某个阈值,则认为它们匹配成功。
通过进行二进制匹配,可以在图像中找到相似的局部特征或对象,例如在目标检测、图像配准、物体识别和图像检索等领域中。二进制匹配方法通常具有计算效率高、鲁棒性好等特点,使其在实际应用中具有广泛的应用前景。
二、介绍
目标检测是一项基本的计算机视觉任务,旨在定位图像中具有紧密边界框的对象,由于深度学习的出现,在过去十年中取得了显著进展。然而,大多数目标检测算法在词汇量方面是不可扩展的,即它们仅限于检测数据集中定义的一组固定的目标类别。例如,在COCO上训练的对象检测器只能检测80个类,并且无法处理超出训练类的新类。
检测新类的一种直接方法是收集它们的训练图像并将其添加到原始数据集中,然后重新训练或微调检测模型。然而,由于数据收集和模型训练的巨大成本,这既不切实际又效率低下。
最近,开放词汇检测(open-vocabulary detection),一种利用大型预训练语言模型的新公式,越来越受到社区的关注。现有工作的中心思想是将检测器的特征与在CLIP等大规模图像-文本对上预训练的模型提供的嵌入对齐。通过这种方式,我们可以使用对齐的分类器仅从描述文本中识别新类。
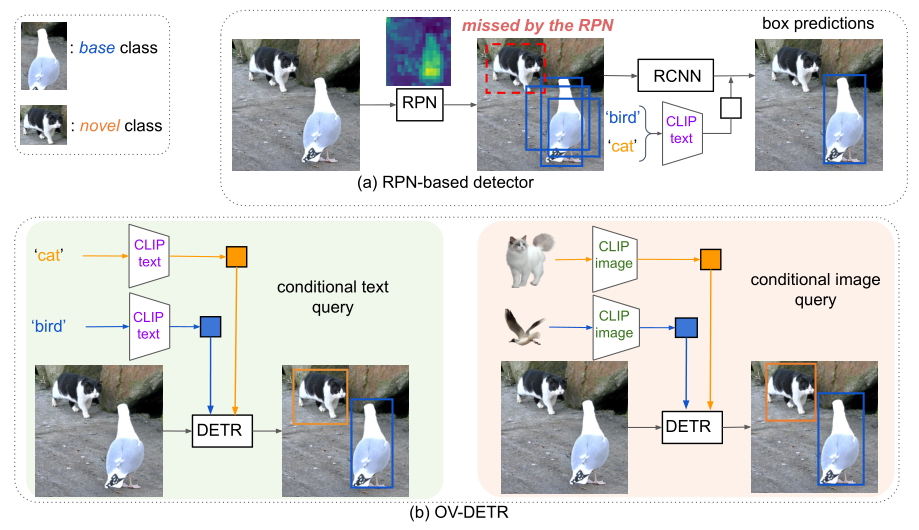
使用 conditional queries 的基于rpn的检测器和基于OpenVocabulary transformer的检测器(OV-DETR)之间的比较。在闭集对象类上训练的RPN很容易忽略新类(例如,“猫”区域接收到的响应很少)。因此,这个例子中的猫在很大程度上被忽略了,几乎没有建议。相比之下,我们的OV-DETR被训练来执行条件查询与其对应框之间的匹配,这有助于学习可以推广到来自未见类的查询的对应关系。注意,我们可以以文本(类名)或范例图像的形式接受输入查询,这为开放词汇表对象检测提供了更大的灵活性。
现有开放词汇检测器的一个主要问题是,它们依赖于region proposals,由于缺乏训练数据,通常不可靠地覆盖图像中的所有新类别,参见图1(A)。最近的一项研究也发现了这个问题,该研究表明,区域建议网络(RPN)的二值性很容易导致对已知类别的过拟合(从而无法推广到新的类别)。
在本文中,我们提出在Transformer框架下训练端到端的开放词汇检测器,目的是在不使用中间RPN的情况下,提高新类别的泛化能力。为此,我们提出了一种新的基于DETR的开放词汇检测器—因此被命名为OV-DETR—它被训练来检测给定类名或样本图像的任何对象。这将比仅从自然语言中进行传统的开放词汇检测提供更大的灵活性。
尽管端到端DETR训练很简单,但将其转换为开放词汇表检测器并非易事。最大的挑战是无法计算没有训练标签的新类的分类成本。为了克服这一挑战,我们将学习目标重新定义为输入查询(类名或样本图像)与相应对象之间的二元匹配。这种对不同训练对的匹配损失允许学习有用的对应关系,可以在测试期间推广到看不见的查询。对于训练,我们扩展了DETR的Transformer解码器以接受条件输入查询。
具体来说,我们根据预训练的视觉语言模型CLIP获得的查询嵌入来调整Transformer解码器,以便对文本或图像查询执行条件匹配。图1显示了这个高级思想,它在检测新类方面比基于rpn的闭集检测器更好。
我们在两个具有挑战性的开放词汇目标检测数据集上进行了全面的实验,并显示出性能的一致改进。具体而言,我们的OV-DETR方法在开放词汇LVIS数据集上实现了17.4个新类的mask mAP,在开放词汇COCO数据集上实现了29.4个新类的box mAP,分别比SOTA方法高出1.3 mAP和1.8 mAP。
三、Open-Vocabulary DETR
我们的目标是设计一个简单而有效的开放词汇对象检测器,它可以检测由任意文本输入或示例图像描述的对象。我们以DETR的成功为基础,将对象检测作为端到端集合匹配问题(在封闭类之间),从而消除了对锚生成和非最大值抑制等手工组件的需求。这个管道使其成为构建端到端开放词汇表对象检测器的合适框架。
然而,将具有闭集匹配的标准DETR改造为开放词汇表检测器(需要对未见过的类进行匹配)是非常重要的。对于这种开集匹配,一种直观的方法是学习一个与类别无关的模块(例如,ViLD)来处理所有的类。但是,这仍然无法匹配那些没有标记图像的开放词汇表类。
引导我们将固定的集合匹配目标重新表述为条件输入(文本或图像查询)和检测输出之间的条件二进制匹配目标。
我们的开放词汇表DETR概述如下图所示。在高层次上,DETR首先将 query embeddings (文本或图像)作为从预训练的CLIP模型中获得的条件输入,然后对检测结果施加二值匹配损失来衡量它们的匹配性。
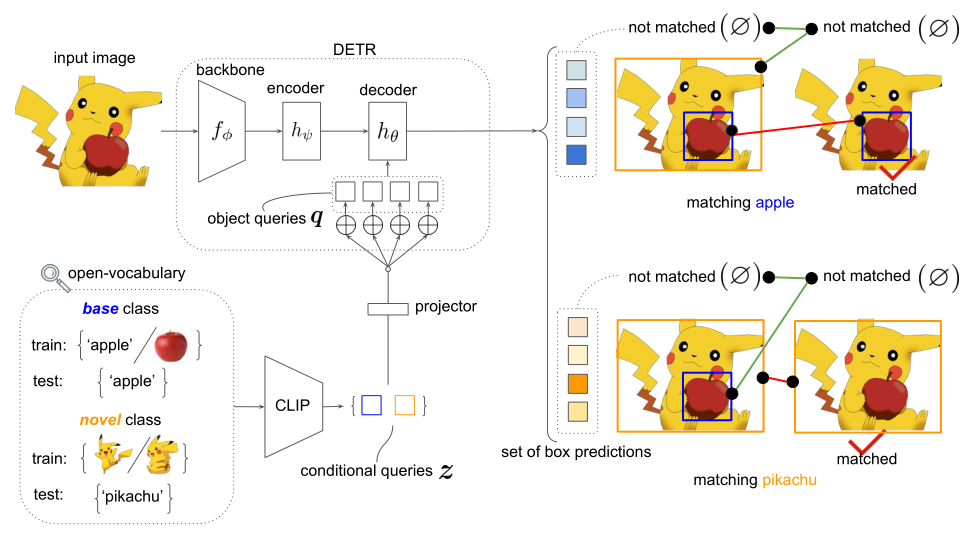
OV-DETR概述。与标准的DETR不同,我们的方法不会为一组封闭的类分离“对象”和“非对象”。相反,OV-DETR通过测量一些条件输入(来自CLIP的文本或示例图像嵌入)与检测结果之间的匹配性(“匹配”与“不匹配”)来执行开放词汇检测。我们展示了这种管道可以灵活地检测具有任意文本或图像输入的开放词汇表类。
3.1 重新审视DETR中的闭集匹配
对于输入图像 x x x,一个标准的 DETR 推断出 N N N 个对象预测 y y y,其中 N N N 由作为可学习位置编码的 object queries q q q 的固定大小决定。DETR 管道的单次传递由两个主要步骤组成:(i)集预测,(ii)最优二部匹配。
Set Prediction:
给定输入图像
x
x
x,全局上下文表示
c
c
c 首先由 CNN 主干
f
ϕ
f_{\phi}
fϕ 提取,然后由 Transformer 编码器
h
Φ
h_{\Phi}
hΦ 提取:
c
=
h
Φ
(
f
ϕ
(
x
)
)
c = h_{\Phi}(f_{\phi}(x))
c=hΦ(fϕ(x))
其中,输出
c
c
c 表示
q
q
q 的特征嵌入序列。将上下文特征
c
c
c 和对象查询q作为输入,Transformer解码器
h
θ
h_{\theta}
hθ (带有预测头)然后产生集合预测:
y
^
=
{
y
i
^
}
i
=
1
N
\hat{y} = \{\hat{y_i}\}_{i=1}^N
y^={yi^}i=1N
y ^ = h θ ( c , q ) \hat{y} = h_{\theta}(c, q) y^=hθ(c,q)
其中, y ^ \hat{y} y^ 包含封闭训练类集的边界框预测值 b ^ \hat{b} b^ 和类预测值 p ^ \hat{p} p^。
3.2 最优二部匹配
最优二部匹配(Optimal Bipartite Matching)是寻找 N N N 个预测集合 y ^ \hat{y} y^ 与基础真对象集合 y = { y i } i = 1 M y = \{y_i\}_{i=1}^M y={yi}i=1M (不包括对象 ∅ )之间的最佳匹配。具体来说,需要搜索N个元素 σ∈ S n S_n Sn的一个匹配代价最低的排列:
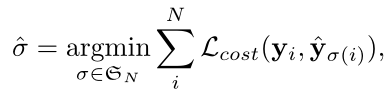
注意
L
c
o
s
t
L_{cost}
Lcost 由类预测
L
c
l
s
(
p
,
p
^
)
L_{cls} (p, \hat{p})
Lcls(p,p^) 和边界盒定位
L
b
o
x
(
b
,
b
^
)
L_{box}(b, \hat{b})
Lbox(b,b^) 的损失组成。整个二部匹配过程产生一对一的标签分配,其中每个预测
y
i
y_i
yi 被分配给一个基真注释
y
j
y_j
yj 或 ∅ (无对象)。匈牙利算法可以有效地找到最优分配。
如上所述,二分匹配方法不能直接应用于包含基类和新类的开放词汇表设置。原因是计算上式中的匹配代价需要访问标签信息,这对于新类是不可用的。我们可以遵循以前的工作来生成可能涵盖新类的类别不可知论对象建议,但我们不知道这些建议的真实分类标签。因此,由于缺乏训练标签,对 N 个对象查询的预测不能推广到新的类。如下图所示,只能对具有可用训练标签的基类进行二部匹配。
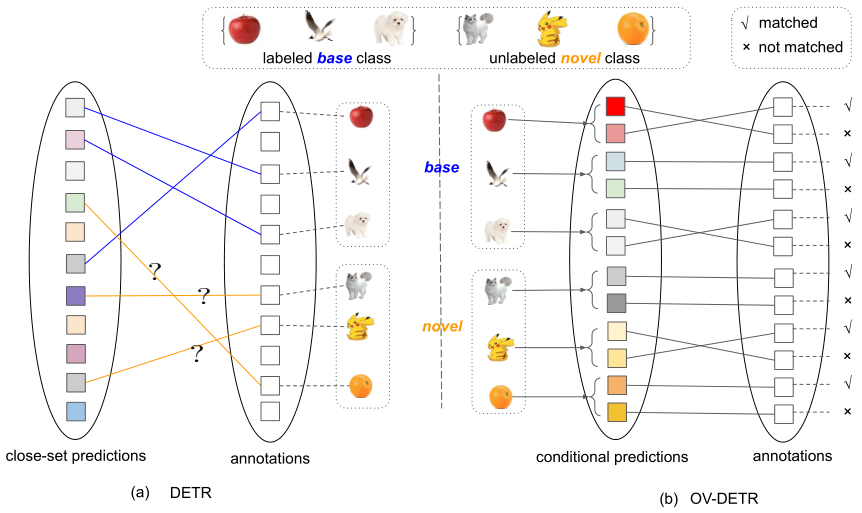
比较DETR和OV-DETR的标签分配机制。
(a)在原始的DETR中,集合到集合的预测是通过预测与闭集注释的二部匹配进行的,其中有一个关于查询和类别的代价矩阵。由于缺乏新类的类标签注释,计算这种特定于类的成本矩阵是不可能的。
(b)相反,我们的OV-DETR将开放词汇检测转换为条件匹配过程,并制定了一个二元匹配问题,该问题计算条件输入的类别不可知匹配成本矩阵。
四、Conditional Matching for Open-Vocabulary Detection
为了使DETR超越闭集分类并执行开放词汇检测,我们为Transformer解码器配备了条件输入,并将学习目标重新表述为二进制匹配问题。
4.1 Conditional Inputs
给定一个具有所有训练(基)类的标准注释的对象检测数据集,我们需要将这些注释转换为条件输入,以促进我们的新训练范式。具体来说,对于每一个边界框为 b i b_i bi,类标签名为 y i c l a s s y_i^{class} yiclass 的真值标注,我们使用CLIP模型生成它们对应的图像嵌入 z i i m a g e z_i^{image} ziimage 和文本嵌入 z i t e x t z_i^{text} zitext:
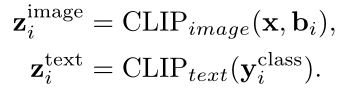
这样的图像和文本嵌入已经被CLIP模型很好地对齐了。
因此,我们可以选择它们中的任何一个作为输入 queries 来约束 DETR 的解码器并训练以匹配相应的对象。一旦训练完成,我们就可以在测试期间使用任意输入查询来执行开放词汇表检测。为了确保图像和文本查询条件下的训练相等,我们随机选择概率为 ξ = 0.5 的 z i t e x t z_i^{text} zitext 或 z i i m a g e z_i^{image} ziimage 作为条件输入。
此外,我们遵循先前的工作,为新类生成额外的对象建议,以丰富我们的训练数据。我们只提取图像嵌入zimage i作为条件输入的新类建议,因为它们的类名无法提取文本嵌入。
4.2 Conditional Matching
我们的核心训练目标是衡量条件输入嵌入和检测结果之间的匹配度。为了执行这样的条件匹配,我们从一个全连接层 F p r o j F_{proj} Fproj 开始,将条件输入嵌入( z i t e x t z_i^{text} zitext 或 z i i m a g e z_i^{image} ziimage)投影为与 q q q 具有相同的维度。然后,对DETR解码器的输入q ’ 给出:
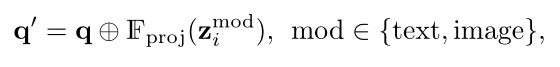
其中,我们使用一个简单的加法操作⊕将类无关的对象查询q转换为由
F
p
r
o
j
(
z
i
m
o
d
)
F_{proj}(z_i^{mod})
Fproj(zimod) 通知的类特定的q '。
在实践中,将条件输入嵌入 z z z 仅添加到一个 object query 中,将导致对可能在图像中出现多次的目标对象的覆盖非常有限。事实上,在现有的目标检测数据集中,每个图像中通常有来自相同或不同类别的多个对象实例。丰富的训练信号条件匹配,我们为对象查询 q q q 复制 R R R 次,和条件输入( z i t e x t z_i^{text} zitext 或 z i i m a g e z_i^{image} ziimage ) N 次执行调节在上面的等式。因此,我们一共获得 N × R N \times R N×R queries 匹配在每个传球前进,如下图所示(b):
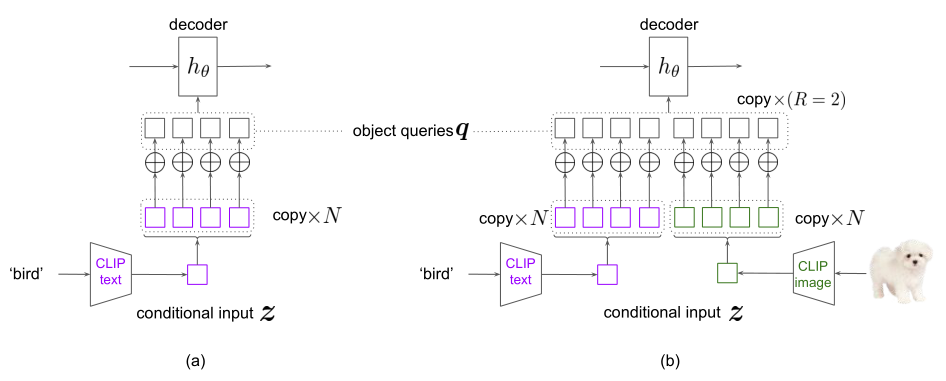
具有(a)单个条件输入或(b)多个条件并行输入的DETR解码器。
给定条件查询特征q ',我们的标签分配的二值匹配损失为:
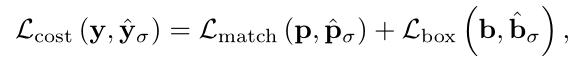
其中
L
m
a
t
c
h
(
p
,
p
σ
^
)
L_{match} (p, \hat{p_{\sigma}})
Lmatch(p,pσ^) 表示替换分类损失
L
c
l
s
(
p
,
p
σ
^
)
L_{cls} (p, \hat{p_{\sigma}})
Lcls(p,pσ^) 的新匹配损失。在我们的例子中,
p
p
p 是一个一维 sigmoid 型概率向量,表征匹配性(“匹配”与“不匹配”),
L
m
a
t
c
h
L_{match}
Lmatch 简单地通过预测的
p
σ
^
\hat{p_{\sigma}}
pσ^ 与GT值
p
p
p 之间的 Focal loss
L
F
o
c
a
l
L_{Focal}
LFocal 来实现。例如,使用“bird”查询作为输入,我们的匹配损失应该允许我们匹配一张图像中的所有鸟类实例。同时将来自其他类的实例标记为“不匹配”。
五、Inference
在测试过程中,对于每张图像,我们将所有基类 + 新颖类的文本嵌入 z t e x t z^{text} ztext 发送给模型,并通过选择预测得分最高的前 k 个预测来合并结果。我们遵循先前的工作,对COCO数据集使用 k = 100,对LVIS数据集使用 k = 300。为了获得上下文表示 c,我们通过CNN主干 f φ f_φ fφ和变压器编码器 h ψ h_ψ hψ 转发输入图像。注意c只计算一次,并且为了效率起见,所有条件输入都是共享的。然后,来自不同类的条件对象查询被并行发送到Transformer解码器。在实践中,我们复制对象查询R次,如图4 (b)所示。
六、实验
数据集。我们分别在由 LVIS 和 COCO 修改的两个标准开放词汇检测基准上对我们的方法进行了评估。LVIS 包含100K个图像,1203个分类。根据训练图像的数量将类分为三组,即频繁类、常见类和罕见类。
根据ViLD,我们将337个罕见的课程作为新课程,只使用频繁和常见的课程进行培训。COCO 数据集是一个广泛使用的对象检测基准,它由80个类组成。根据OVR-CNN,我们将COCO中的类划分为48个基本类别和17个新类别,同时在WordNet层次结构中删除了15个没有同义词集的类别。训练集与完整的COCO相同,但只使用包含至少一个基类的图像。我们将这两个基准分别称为OV-L VIS和OV-COCO。
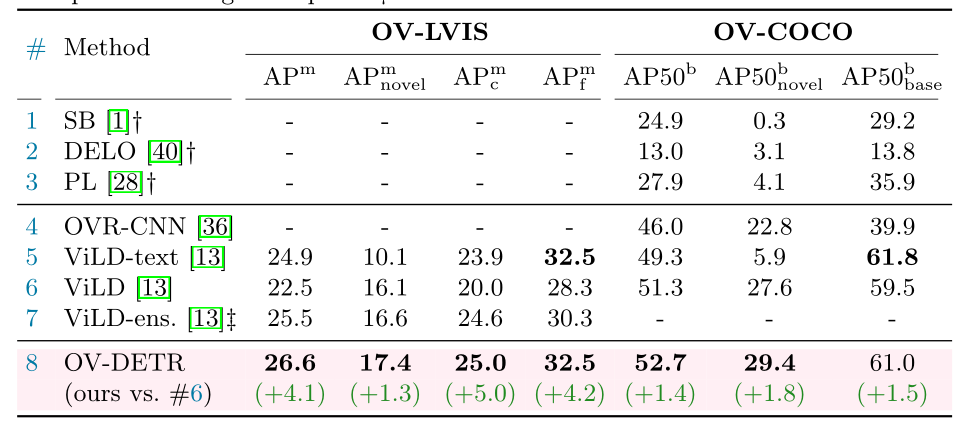
现在我们将DETR的默认闭集标记赋值替换为我们建议的条件二进制匹配。表第2-3行与表的比较结果表明,我们的二元匹配策略可以更好地利用来自对象建议的知识,并将APmnovel从9.5提高到17.4。如此大的改进表明,在将der系列检测器应用于开放词汇表设置时,所提出的条件匹配是必不可少的。