大模型实战营第二期——1. 书生·浦语大模型全链路开源开放体系
1. 实战营介绍
- github链接:https://github.com/internLM/tutorial
- InternLM:https://github.com/InternLM
- 书生浦语官网:https://intern-ai.org.cn/home
2. 书生·浦语大模型介绍
- 视频链接:B站-书生·浦语大模型全链路开源体系
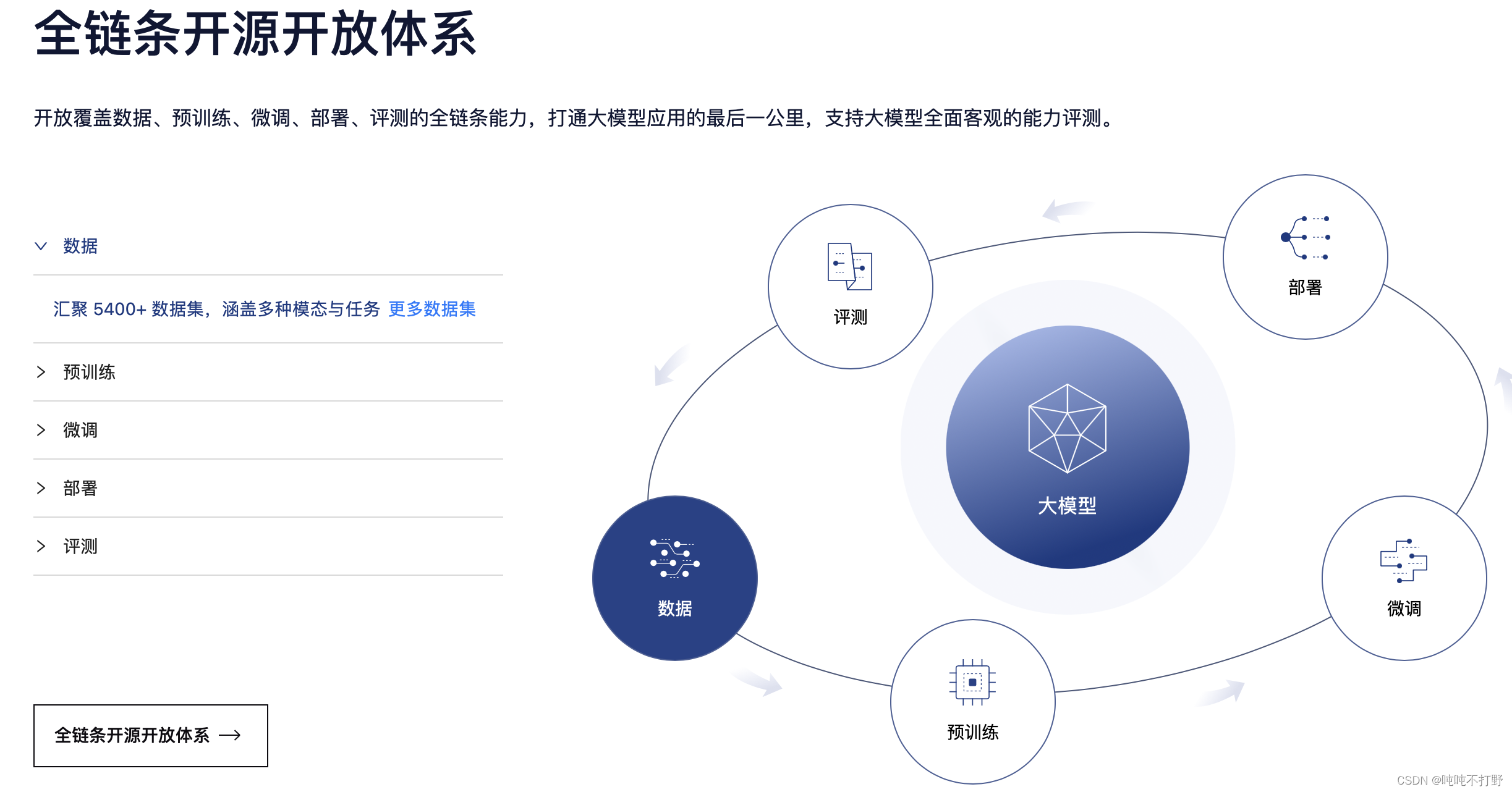
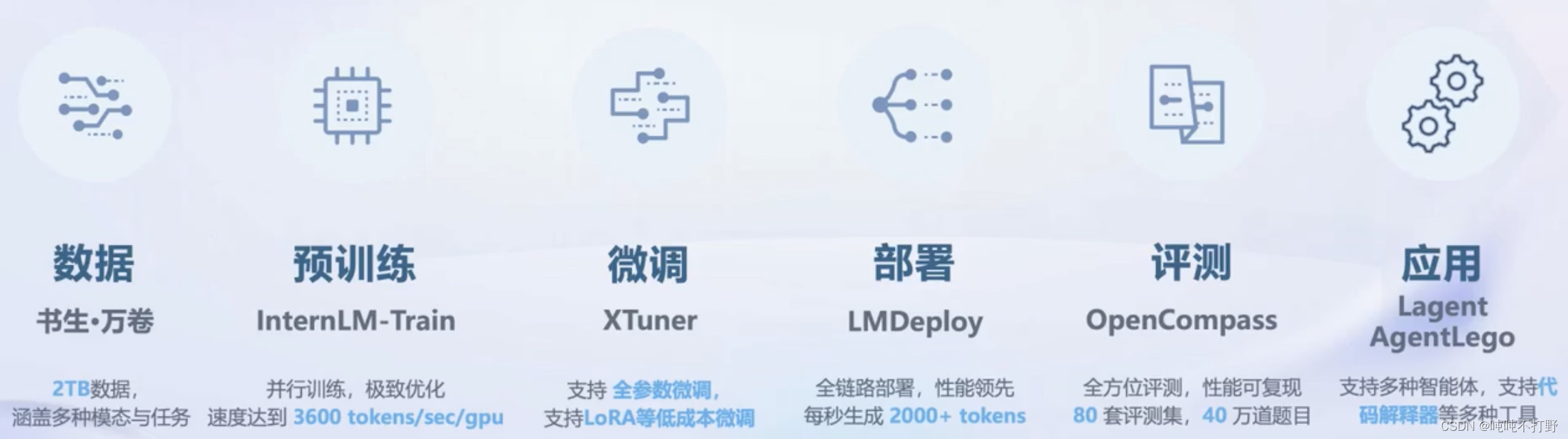
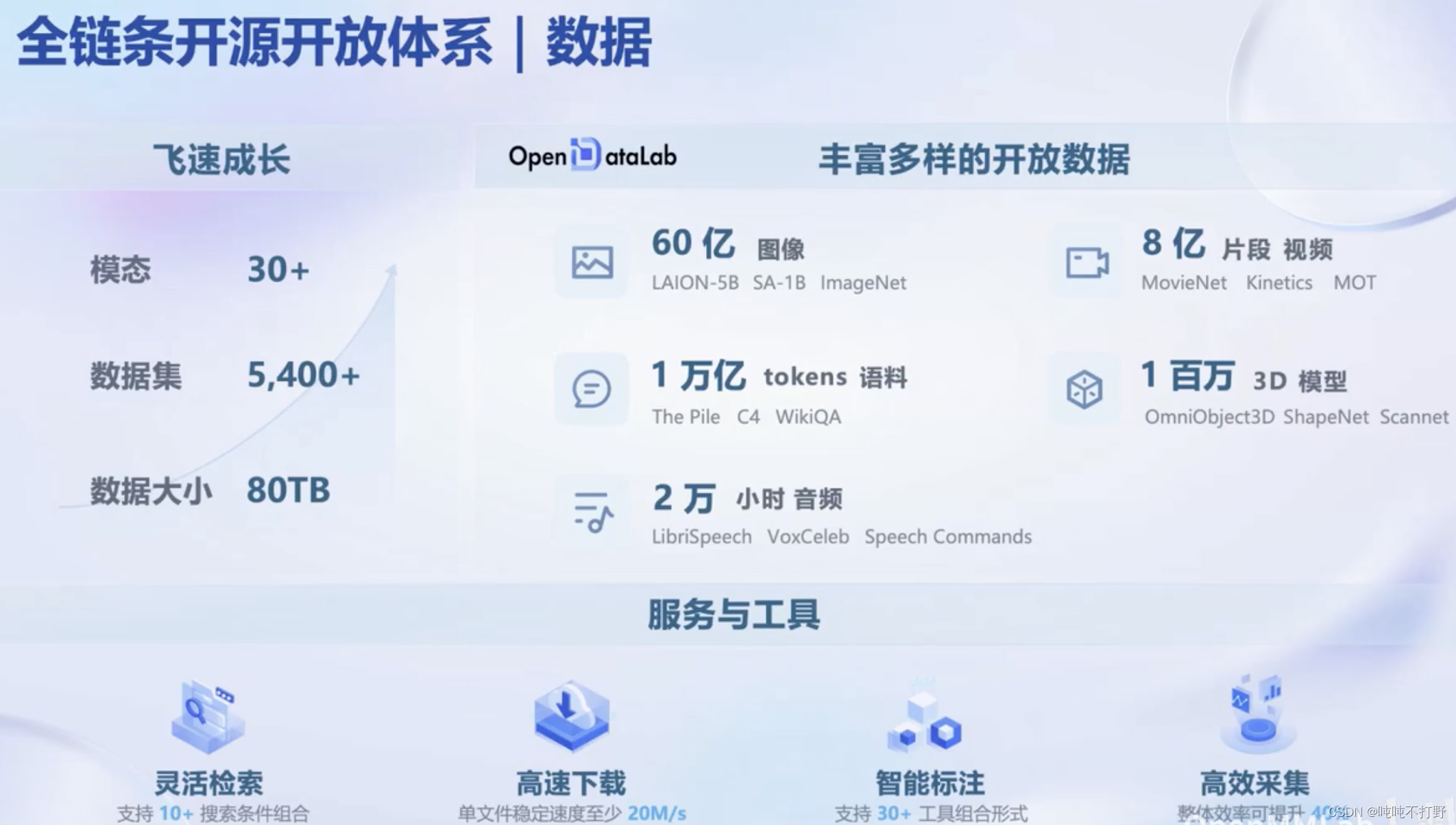
- 数据:汇聚 5400+ 数据集,涵盖多种模态与任务,更多数据集
- 预训练:并行训练,极致优化,速度达到 3600 tokens/sec/gpu
- 微调:全面的微调能力,支持SFT,RLHF和通用工具调用
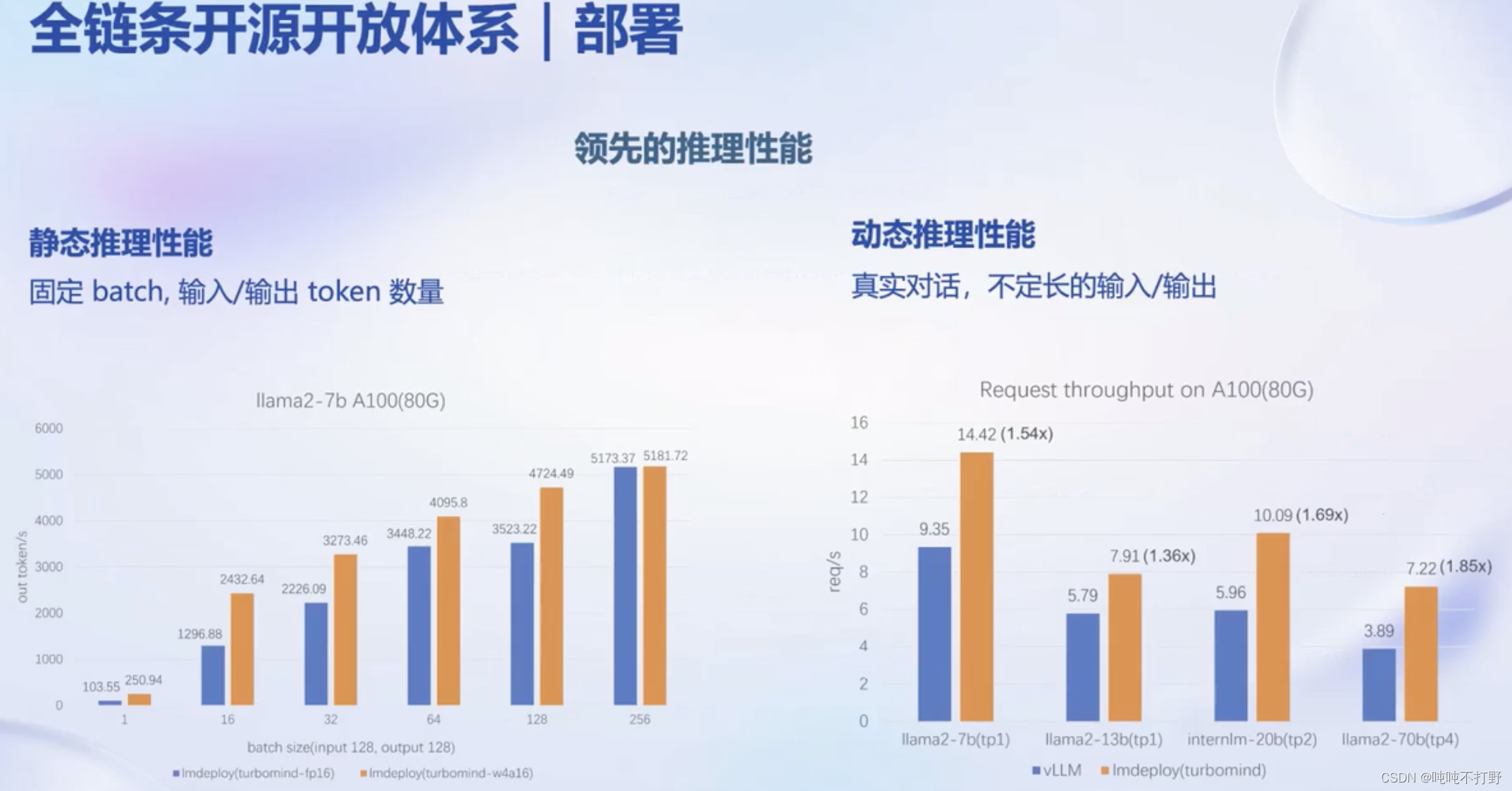
- 部署:全链路部署,性能领先,每秒生成 2000+ tokens
- 评测:全方位评测,性能可复现,50 套评测集,30 万道题目
2.1 数据

OpenDataLab的知乎文章:多模态语料库 “书生·万卷” 1.0 详细解读 | 附下载地址
也是来自论文的
2.2 预训练

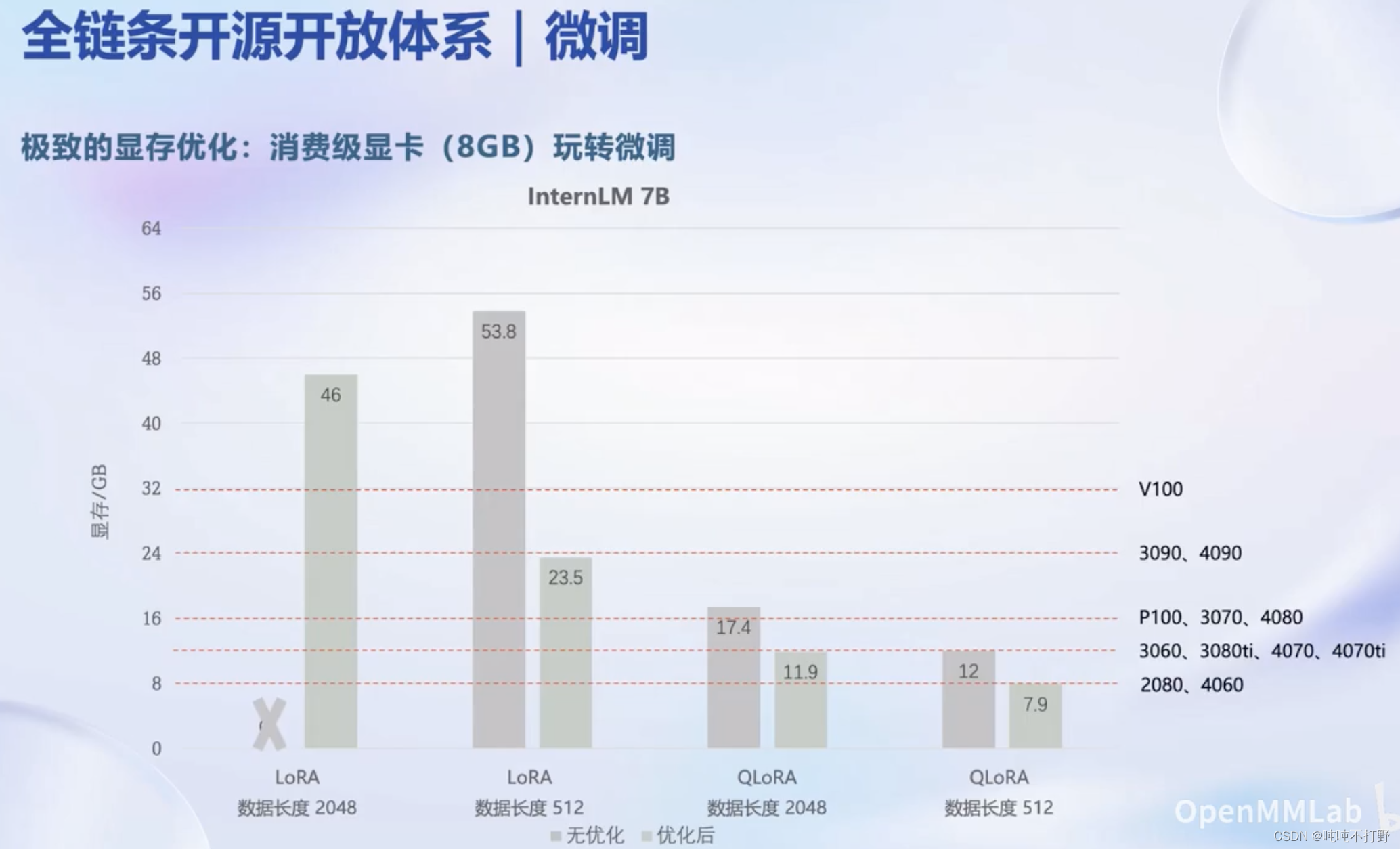
2.3 微调

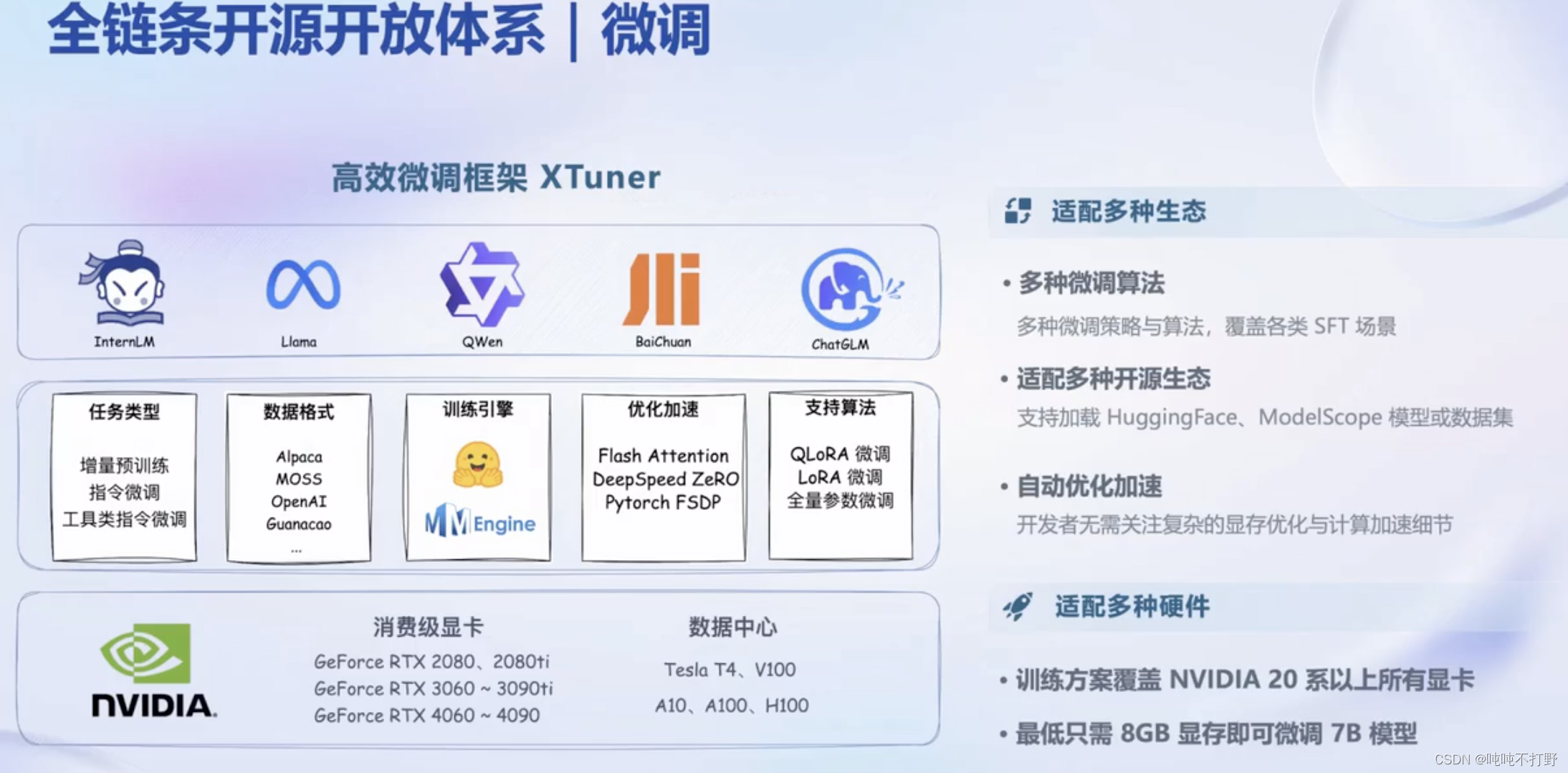
SFT(ScalableFine-Tuning) 是一种用于自然语言处理的技术,它通过对预训练的语言模型进行微调,使其适应特定任务
https://github.com/InternLM/xtuner
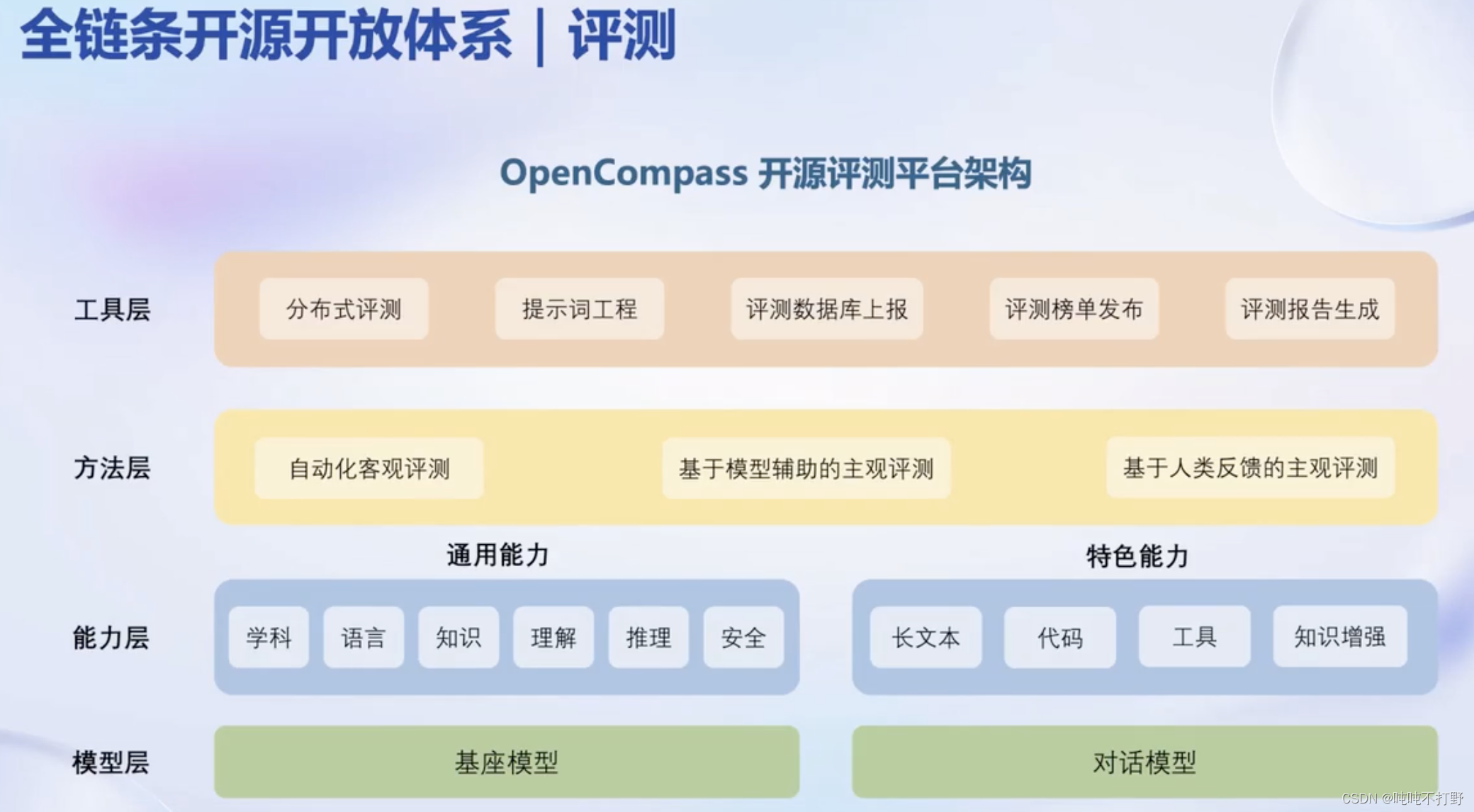
2.4 评测

- https://crfm.stanford.edu/helm/lite/latest/#/leaderboard
- https://github.com/stanford-crfm/helm
- https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- https://llm-leaderboard.streamlit.app/
- https://github.com/terryyz/llm-benchmark

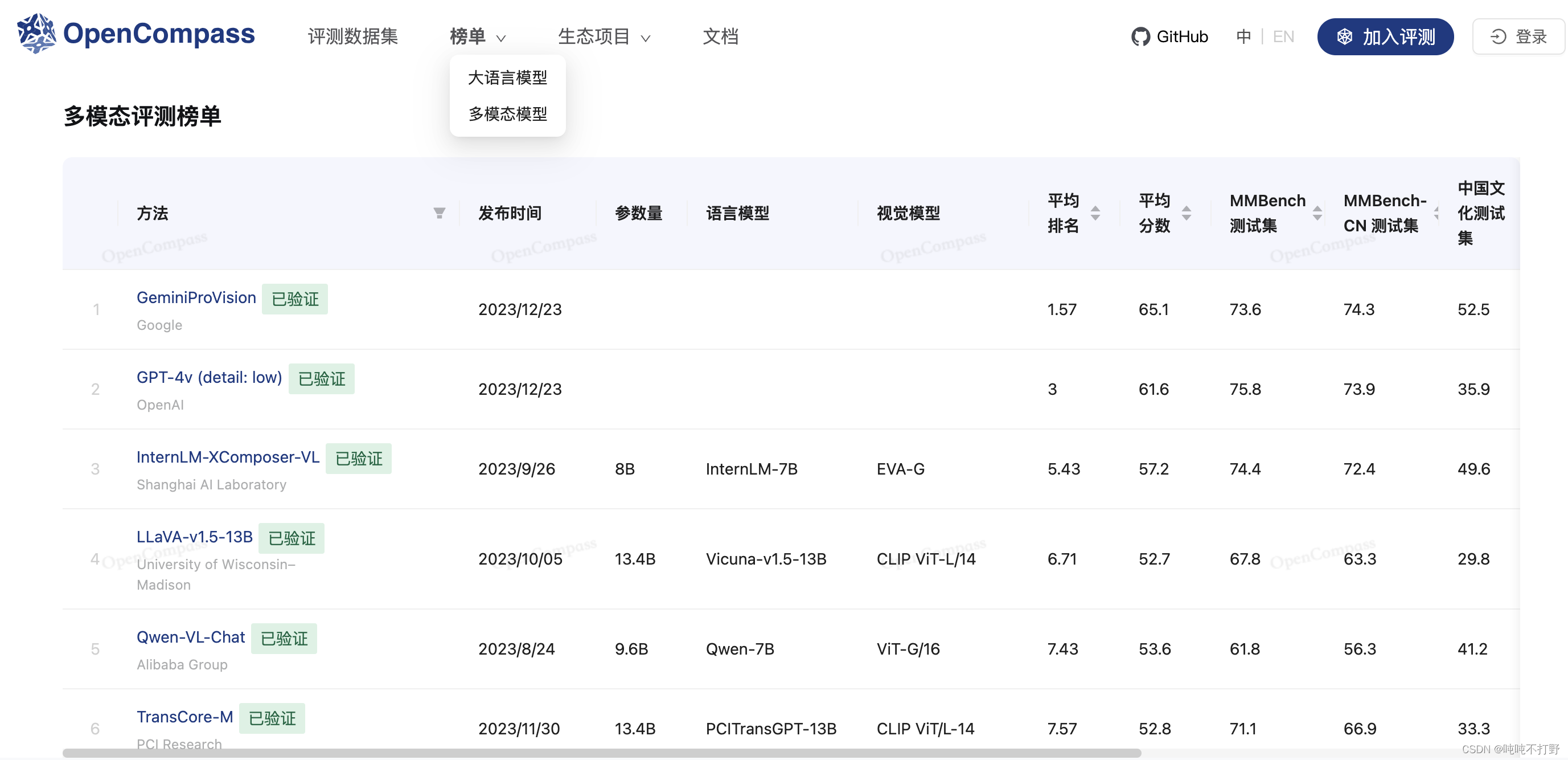
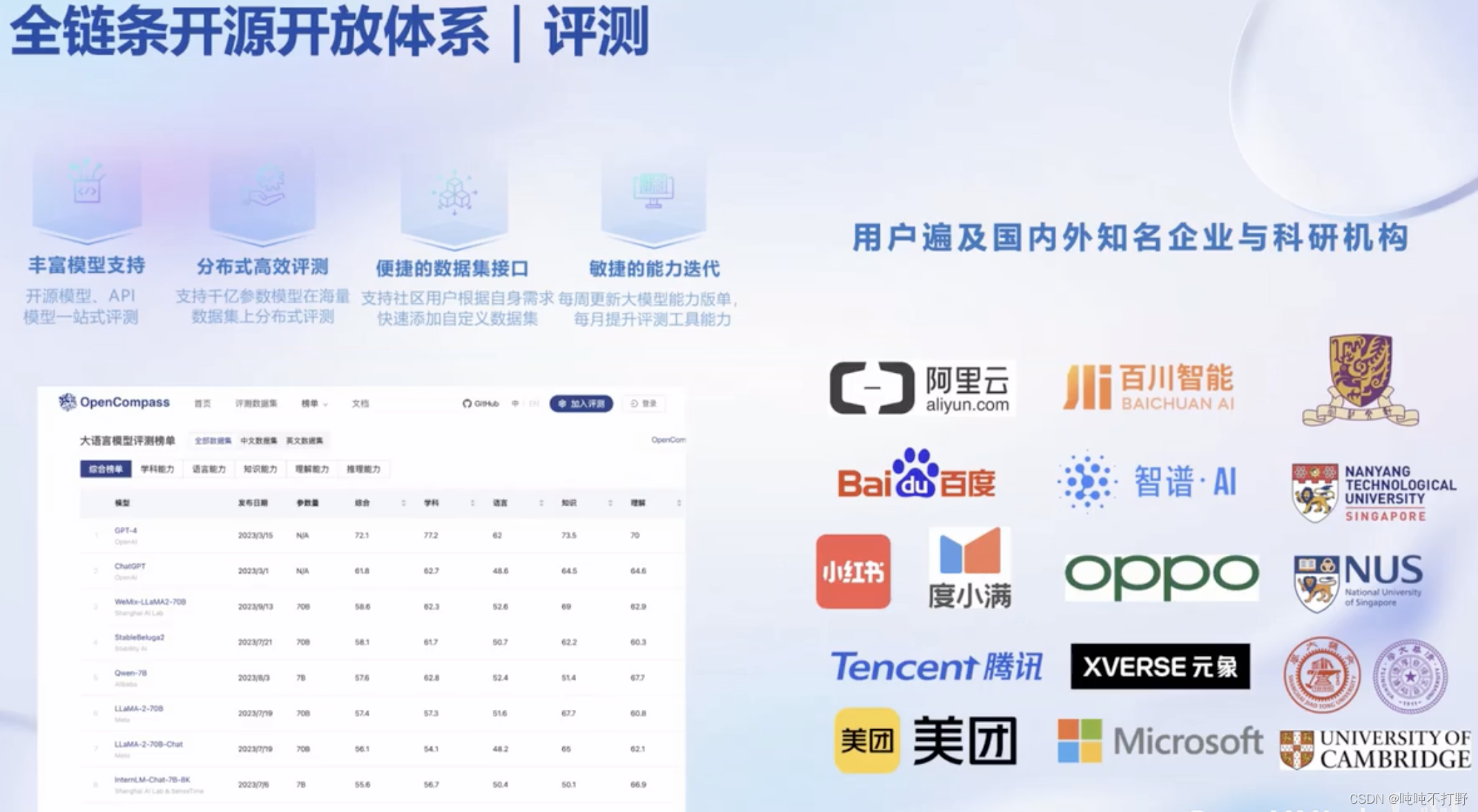

2.5 部署


https://github.com/InternLM/lmdeploy
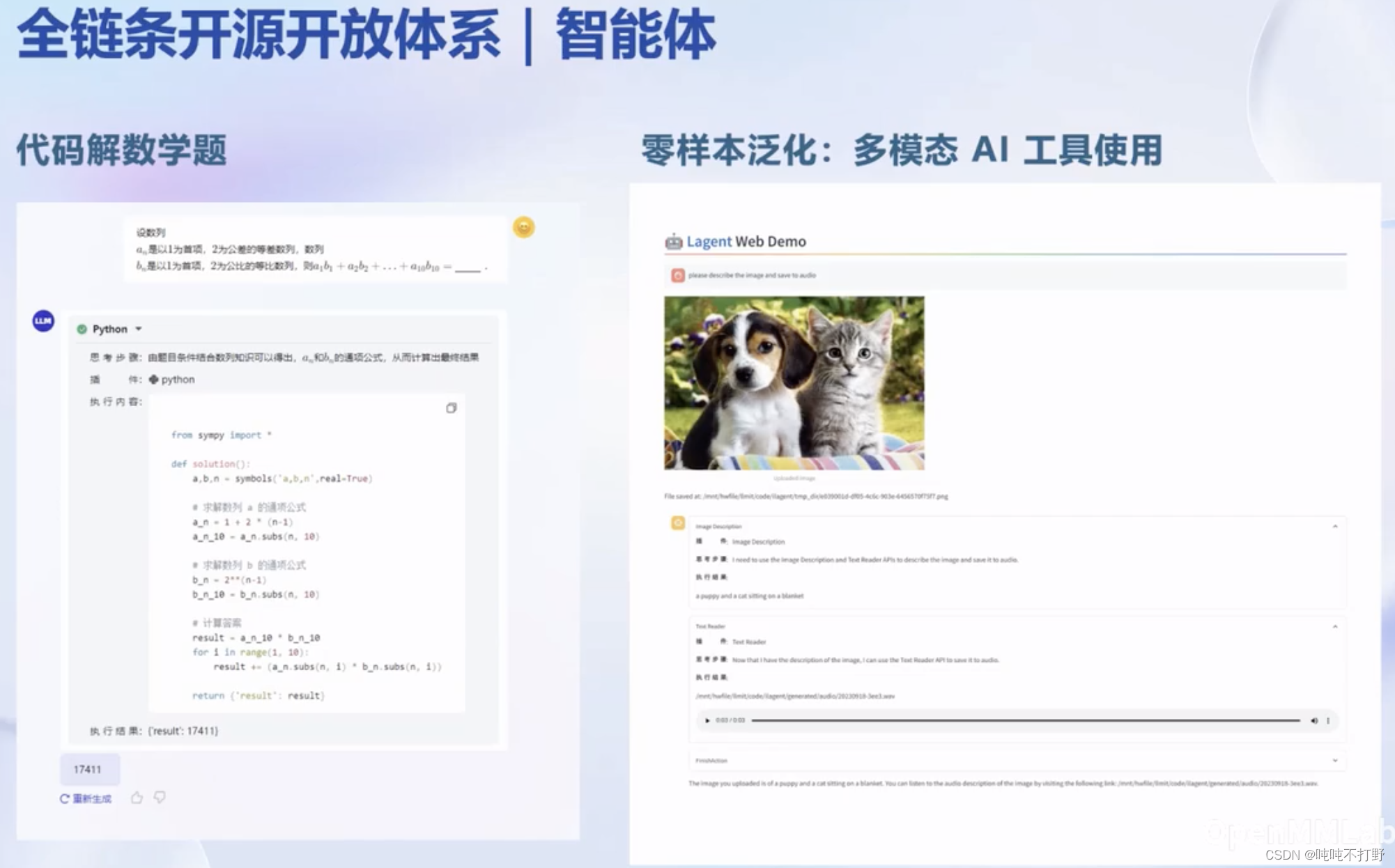
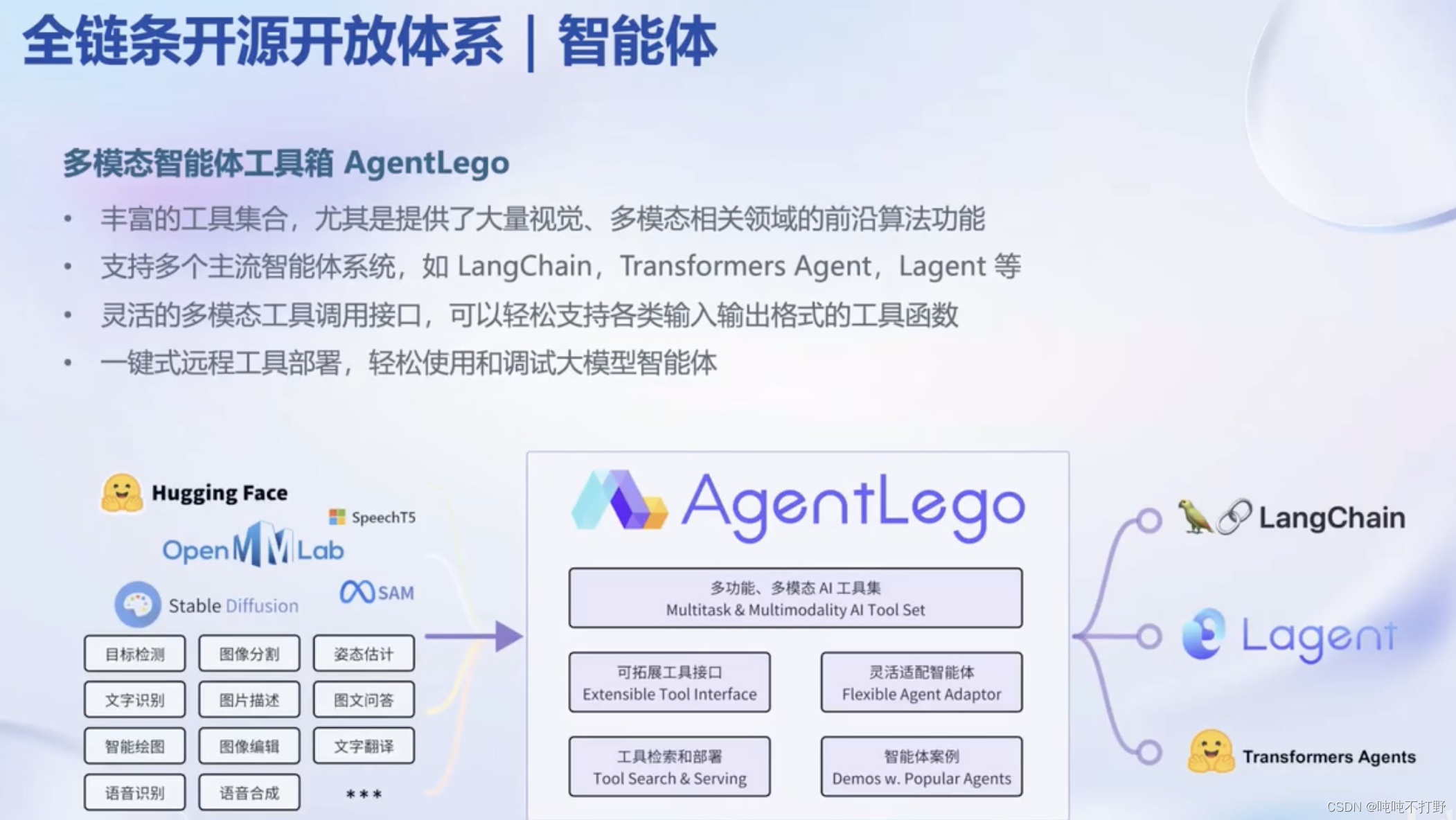
2.6 智能体(应用)
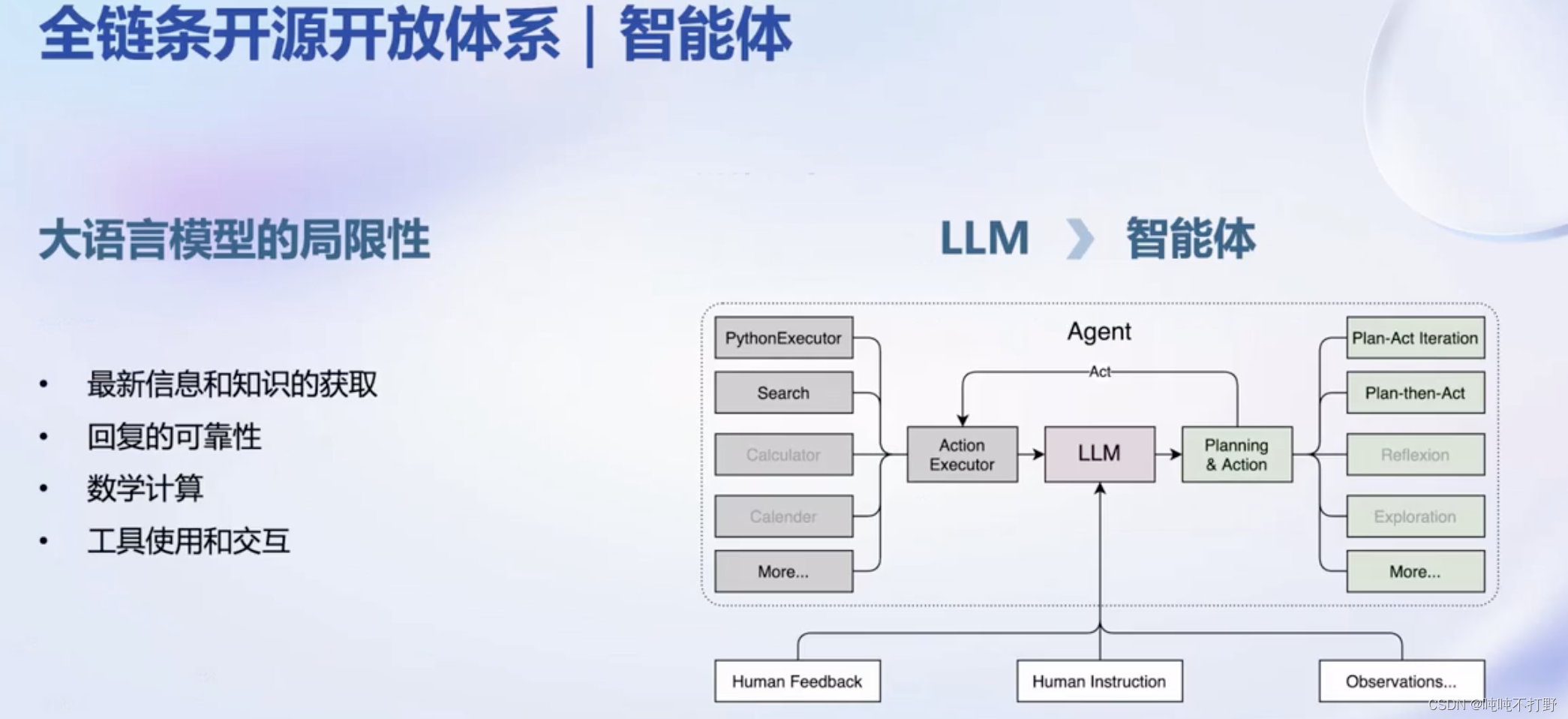

https://github.com/InternLM/lagent