mysql sharding proxy,sharding-proxy之操作
单库单表
第一步:修改conf/server.yaml
第二步:修改conf/config-sharding.yaml
解释::
actualDataNodes: ds_${0}.t_order_${0..1}:会在demo_ds_0这个数据库中创建二张表:t_order_0和t_order_1。
algorithmExpression: t_order_${order_id % 2}:分表,主要是把添加的数据放入到哪张表中。这里采用取模的方式进行分表。在这里要 注意一下 : order_id必须是整数,不能是字符串,如果是字符串的数字的话,可以通过如下进行转换:Integer.parseInt(order_id)
algorithmExpression: ds_${0} : 分库,因为这里是单库,所以这里不采用任何的方式进行分库。
第三步:启动sharding-proxy
windows系统下运行:bin/start.bat
linux系统执行:bin/start.sh
默认的端口是:3307
第四步:创建相应的表
sharding-proxy启动成功之后,进行cmd命令行界面,输入如下信息:
然后就是输入你在配置conf/server.yaml文件中的users中的root里的password密码了。
然后使用:show databases; 查看当前有什么逻辑库。
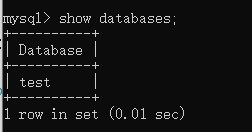
上图的逻辑库是:conf/server.yaml中的authorizedSchemas所对应的test。
然后再执行:use test;
你可以执行:show tables;查看当前库有没有表。
下面创建对应的表:
上面的表结构字段比较少,你可以根据自己的需求来进行添加。
最后一步:测试
往刚刚创建的表添加一些测试数据:
上面的数据会放入到t_order_0表还是t_order_1表呢?
在配置conf/config-sharding.yaml文件时,里面的分表结构是这样的:algorithmExpression: t_order_${order_id % 2},可以看出是通过添加数据的order_id取模 2 进行划分表的。那这样的话,上面添加的数据可以得出:order_id = 1 取模 2 之后是 1 ,所以上面添加的数据是放入到了t_order_1这张表中。
再来一次试一下:
这条order_id 取模 2 之后是 0,所以该数据放在t_order_0这张表中。
单库单表扩展
上面采用分表是分成两张表,假设我们有100万的数据量,如果你采用的mysql数据库的话,当数据表中数据量越大了,会影响到你查询出来的语句很慢。而我们上述分成了两张表,100万的数据量,每张表分得50万的数据。这样子总比一张表好是吧。
那怎么样分成更多的表呢?
分成十张表
分成十张表的规则就是:
修改conf/config-sharding.yaml:
这里主要是使用order_id的尾数进行划分表。
我目前能想到的就是十张表,你如果能使用单库划分十张以上的表的话,可以跟我说一下,谢谢。
多库单表
第一步:修改conf/server.yaml
第二步:修改conf/config-sharding.yaml
自行在3306端口的mysql中创建好demo_ds_0和demo_ds_1两个数据库。
第三步:启动sharding-proxy
windows系统下运行:bin/start.bat
linux系统执行:bin/start.sh
默认的端口是:3307
第四步:创建相应的表
sharding-proxy启动成功之后,进行cmd命令行界面,输入如下信息:
然后就是输入你在配置conf/server.yaml文件中的users中的root里的password密码了。
然后使用:show databases; 查看当前有什么逻辑库。
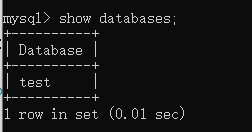
上图的逻辑库是:conf/server.yaml中的authorizedSchemas所对应的test。
然后再执行:use test;
你可以执行:show tables;查看当前库有没有表。
下面创建对应的表:
上面的表结构字段比较少,你可以根据自己的需求来进行添加。
最后一步:测试
往刚刚创建的表添加一些测试数据:
该数据存放在:demo_ds_1数据库中的tasklist_2数据表中。
介绍
上面的多库多表:双库双表,每个库中划分十张表。首先是根据sucaiid划分库,然后再根据id划分表。表的数据结构是一样的