Lostash同步Mysql数据到Elasticsearch(一)服务介绍及环境配置
1. Logstash介绍
Logstash是一个数据流引擎:
它是用于数据物流的开源流式ETL引擎,在几分钟内建立数据流管道,具有水平可扩展及韧性且具有自适应缓冲,不可知的数据源,具有200多个集成和处理器的插件生态系统,使用Elastic Stack监视和管理部署
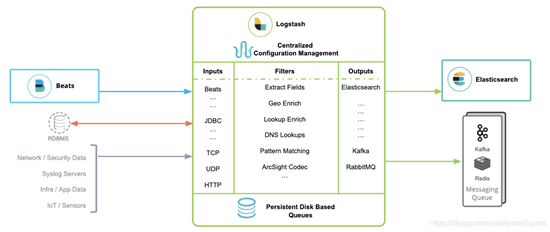
Logstash包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)。 inputs主要用来提供接收数据的规则,比如使用采集文件内容; filters主要是对传输的数据进行过滤,比如使用grok规则进行数据过滤; outputs主要是将接收的数据根据定义的输出模式来进行输出数据,比如输出到ElasticSearch中.
示例图:
2. Logstash安装使用
Logstash采用JRuby语言编写,运行在jvm中,因此安装Logstash前需要先安装JDK,Ruby。
Logstash需要以下版本之一:
- Java 8
- Java 11
- Java 14
版本选择
https://www.elastic.co/downloads/past-releases#logstash
7.1.1版本下载地址
https://artifacts.elastic.co/downloads/logstash/logstash-7.1.1.tar.gz
2.1部署服务
$ tar xf logstash-7.1.1.tar.gz -C /usr/local/src/ ln -s /usr/local/src/logstash-7.1.1 /usr/local/logstash
$ mkdir -p /data/logstash/{logs,data} 配置文件说明
logstash.yml
包含Logstash配置标志。您可以在此文件中设置标志,而不是在命令行中传递标志。您在命令行上设置的所有标志都将覆盖logstash.yml文件中的相应设置。有关更多信息,请参见logstash.yml。
pipelines.yml
包含用于在单个Logstash实例中运行多个管道的框架和说明。有关更多信息,请参见多管道。
jvm.options
包含JVM配置标志。使用此文件设置总堆空间的初始值和最大值。您也可以使用此文件设置Logstash的语言环境。在单独的行上指定每个标志。此文件中的所有其他设置都被视为专家设置。
log4j2.properties
包含log4j2库的默认设置。有关更多信息,请参见Log4j2配置。
startup.options (Linux)
包含使用的选项system-install在脚本中/usr/share/logstash/bin建立相应的启动脚本为您的系统。当您安装Logstash软件包时,该system-install脚本将在安装过程结束时执行,并使用中指定的设置startup.options来设置选项,例如用户,组,服务名称和服务描述。默认情况下,Logstash服务安装在用户下logstash。该startup.options文件使您可以更轻松地安装Logstash服务的多个实例。您可以复制文件并更改特定设置的值。请注意,startup.options启动时不会读取文件。如果要更改Logstash启动脚本(例如,要更改Logstash用户或从其他配置路径读取),则必须重新运行system-install脚本(以root用户身份)以传入新设置。
修改logstash配置
vim /usr/local/logstash/config/logstash.yml
| path.data: /data/logstash/data path.logs: /data/logstash/logs |
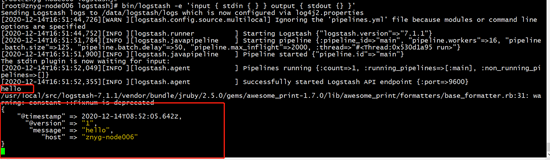
2.2测试服务
| #进入目录 $ cd /usr/local/logstash #启动测试 $ bin/logstash -e ‘input { stdin { } } output { stdout {} }’ |
| 输入hello,显示hello安装成功 |
2.3安装logstash-input-jdbc插件(建议最后安装,时间很久没有提示)
安装logstash是一件比较蛋疼的事,因为这东西适用ruby开发的,我对ruby这东西是一点也不懂,所以比较不好弄。 如果没有gem命令的话,需要先安装一下子(root用户才可以) yum install gem 替换ruby镜像库为国内的库,因为国外的库,国内是访问不到的,然后国内有两个库,两个库都是可以用的: 1、替换成ruby-china的库 gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/ 查看是否成功 gem sources -l 2、国内还有一个库,是淘宝的: gem sources --add https://ruby.taobao.org/ --remove https://rubygems.org/ 可以同样用gem sources -l查看是否替换成功。 替换完之后,进入logstash安装目录,修改Gemfile文件里面的数据源: vi Gemfile 修改成这个样子: source "https://gems.ruby-china.org" 如果用的用的是淘宝的库,就修改成这样 source "https://ruby.taobao.org"
进入到logstash的bin下
cd /usr/local/logstash/
./plugin install logstash-input-jdbc等待一整子,挺久的。
Validating logstash-input-jdbc
Installing logstash-input-jdbc
Installation successful 执行 bin/logstash-plugin list 查看情况。
查看插件版本命令
bin/logstash-plugin list –verbose logstash-input-kafka
同步过程中发现的坑爹问题:
可以使用mysql8.0驱动包,但是驱动还是显示版本问题,正常使用就行,有些文章上面让更新插件版本,但是更新后问题依然没有解决,而且出现了更扯淡的问题,分页参数没有了,此时会出现若数据量太大数据查询不处理,日志和进程直接卡死,一直在等待查询。 提供我的jdbc插件版本。

2.4安装其他版本的jdbc插件
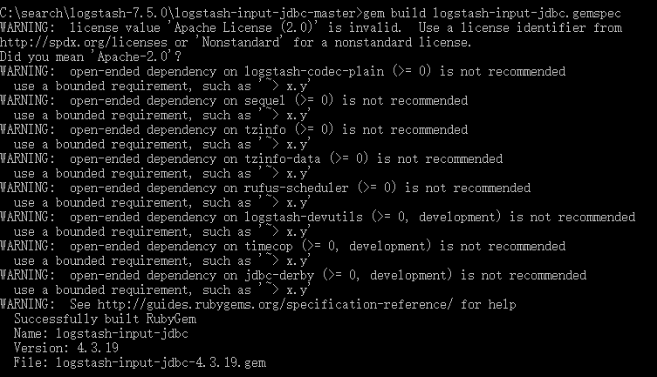
去github下载最新版(当前最新版本是4.3.19)zip包,下载后解压并在本地编译生成gem文件并安装。
运行gem build logstash-input-jdbc.gemspec,生成.gem文件:
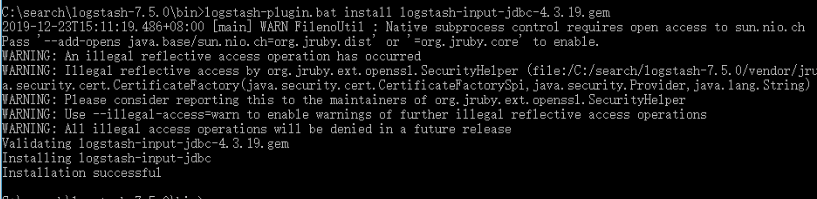
运行logstash-plugin.bat install logstash-input-jdbc-4.3.19.gem,在本地安装最新版本:
3. 环境配置及优化
3.1查看cpu核心数修改pipeline.workers
| grep ‘core id’ /proc/cpuinfo | sort -u | wc -l vim /usr/local/logstash/config/ logstash.yml |
3.2根据资源情况调整任务执行环境参数
设置JVM堆大小编辑
以下是调整JVM堆大小的一些提示:
- 建议的堆大小应不小于4GB,不超过8GB。
- 如果堆大小或太小,CPU利用率可能会不必要地增加,从而导致JVM不断地进行垃圾收集。您可以通过将堆大小加倍来检查此问题,以查看性能是否有所提高。
- 不要增加堆大小超过物理内存量。必须留下一些内存来运行操作系统和其他进程。作为大多数安装的一般指导原则,不要超过物理内存的50-75%。你有越多的内存,你可以使用的百分比就越高。
- 将最小(Xms)和最大(Xmx)堆分配大小设置为相同的值,以防止堆在运行时调整大小,这是一个非常昂贵的过程。
- 您可以使用
内存图命令行实用程序通过Java或使用VisualVM分发。有关更多信息,请参见分析堆.
设置JVM堆栈大小编辑
大型配置可能需要额外的JVM堆栈内存。 如果看到堆栈溢出错误,请尝试增大JVM堆栈大小。 在jvm.选项 设置文件:
-Xss 4M
请注意,默认堆栈大小因平台和操作系统风格而异。您可以通过运行以下命令找到默认值:
Java -XX:+PrintFlagsFinal-version | grep ThreadStackSize
根据默认堆栈大小,先乘以4x,然后乘以8x,再乘以16x,直到溢出错误得到解决。