一、建表并插入数据 1、创建一个people表
DROP TABLE IF EXISTS `people`; CREATE TABLE `people` ( `id` int NOT NULL COMMENT '主键', `name` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '姓名', `sex` tinyint NOT NULL COMMENT '性别', `age` int NOT NULL COMMENT '年龄', `phone` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '联系方式', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; 2、向people表添加数据
Swin Transformer: Hierarchical ViT using Shifted Windows 论文信息概述核心思想整体结构名词解释与vit区别 模型处理过程概括Patch EmbeddingBasicLayerPatch MergingSwin Transform BlockWindow AttentionShifted Window Attention小结 模型使用及代码模型使用环境配置SwinT 代码Patch EmbeddingPatch MergingMask 论文信息 论文全名:Swin transformer: Hierarchical vision transformer using shifted windows发表期刊/会议:Proceedings of the IEEE/CVF international conference on computer vision论文链接:https://arxiv.org/abs/2103.14030引用:Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows.Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10012-10022. 概述 1.SwinTransformer想设计一个可以作为密集预测任务的Transformer Backbone,其采用PatchMerging的策略,构建了层次化的特征,使得其可以作为密集预测任务的Backbone。
2.同时考虑到密集预测任务中,tokens数目太多导致计算量过大的问题,其采用一种在local window内部计算Self-Attention的机制去降低计算复杂度,使得整体计算复杂度由O(N^2)降低至O(N)水平。
3.为了弥补Local Self-Attention带来了远程依赖关系缺失的问题,其创新性地采用了Shift Window操作,引入了不同window之间的关系,并且在精度以及速度上都超越了简单的Sliding Window的方法。
Ambari-2.7.5在麒麟V10操作系统中的集群部署(一) 注意:
本次搭建只是尝试,检查是否有其他兼容性问题。
本篇文章主要描述:下载到部署成功,能够打开页面即可。服务相关的操作问题将后续完成发布。
系统环境Kylin Linux Advanced Server release V10 (Tercel)CPUHygon C86 5285 16-core Processor (海光)架构:x86_64Ambari版本2.7.5HDP版本3.1.5.0 0、准备工作 关于安装包的下载和前期服务器准备工作,可以参考另一位博主的文章:http://t.csdn.cn/Yj6Ub 第一章第一节安装包准备。
本人之前的文章也有相关说明:
麒麟操作系统-01-java环境说明和安装:http://t.csdn.cn/tN1ju
麒麟操作系统-02-hosts域名映射、ssh免密等:http://t.csdn.cn/1eSZh
MySQL数据库的安装(tar.gz包):http://t.csdn.cn/7mpJL (rpm包可以自行百度)
1、制作yum本地源 安装ambari-server和ambari-agent之前,我们需要制作本地的yum源,这样可以使用yum install PackageName进行自动安装,十分方便。
1.1安装httpd服务 每台服务器都要安装httpd
yum -y install httpd #开启httpd服务 systemctl start httpd #设置开机自启 systemctl enable httpd 注意:若是遇到yum无法下载的情况,请自行百度更换yum源,网络上有很多教程。如有需要,可以留言,我会总结一篇。一般情况下centos不会有这种问题,我只在麒麟V10上遇到过。修改测试完成后再执行上述命令。
1.2上传下载的安装包 创建文件夹并上传安装包
mkdir -p /opt/software/ambari #使用工具上传 解压 mysql-connector-java-5.1.40.tar.gz
tar -zxvf mysql-connector-java-5.1.40.tar.gz #将解压后目录中的 mysql-connector-java-5.1.40-bin.jar 复制到/usr/share/java/下 mv mysql-connector-java-5.1.40-bin.jar /usr/share/java/mysql-connector-java.jar 1.3制作本地yum源 mkdir /var/www/html/libtrpc mv libtirpc-0.2.4-0.16.el7.x86_64.rpm /var/www/html/libtrpc mv libtirpc-devel-0.
let date1 = new Date(new Date(new Date().toLocaleDateString()).getTime()); let day = this.timeFormat(date1) //今天 23:59:59 let date2 = new Date(new Date(new Date().toLocaleDateString()).getTime() + 24 * 60 * 60 * 1000 - 1); var day_end = this.timeFormat(date2) //一周前 let date3 = new Date(new Date(new Date().toLocaleDateString()).getTime() - 3600 * 1000 * 24 * 7); let dat_week = this.timeFormat(date3) //昨天 2023-7-3 let date4 = time.getFullYear() + '-' + (time.getMonth() + 1) + '-' + (time.
在电脑或编程领域中,有时候我们需要对用户的输入进行限制,以确保数据的准确性和安全性。其中一种常见的限制方式就是将输入框设置为不可编辑,即用户无法直接修改输入框中的内容。
不可编辑的输入框在很多场景中都有应用。比如,在一个表单中,我们可能需要展示用户之前提交的数据,但又不希望用户能够修改这些数据。将输入框设置为不可编辑就可以很好地实现这一目的。
在编程中,我们可以通过HTML的"readonly"属性或者JavaScript来实现输入框的不可编辑。下面是一个示例代码:
<input type="text" value="这是不可编辑的文本" readonly /> 上述代码中,通过将输入框的"readonly"属性设置为true,就可以将输入框设置为不可编辑。用户将无法修改输入框中的内容,只能进行查看操作。
不可编辑的输入框还可以用于展示一些只读信息,比如展示计算结果、显示系统配置等。通过将输入框设置为不可编辑,可以避免用户误操作或者不必要的修改。
需要注意的是,虽然不可编辑的输入框可以防止用户直接修改内容,但并不能完全阻止用户修改数据。因为用户可以通过其他手段,例如通过浏览器的开发者工具,来修改输入框中的内容。在关键数据的保护上,还需要进行后端验证和安全措施。
不可编辑的输入框是一种常见的限制用户输入的方式,可以在很多场景中发挥作用。通过设置输入框的"readonly"属性或者使用JavaScript来实现,可以有效地保护数据的准确性和安全性。
本文转摘自:input不可编辑原因分析 - 电脑知识 - 麦折网络 在电脑或编程领域中,有时候我们需要对用户的输入进行限制,以确保数据的准确性和安全性。其中一种常见的限制方式就是将输入框设置为不可编辑,即用户无法直接修改输入框中的内容https://www.baizhemai.com/best/b6/1687097199840.html
不管学习哪门语言都希望能做出实际的东西来,这个实际的东西当然就是项目啦,不用多说大家都知道学编程语言一定要做项目才行。
这里整理了前端实战项目列表,你可以从中选择自己想做的项目进行参考学习练手,你也可以从中寻找灵感去做自己的项目。 1、【网易云音乐首页制作】
2、【实战项目之今日头条】
3、【实战项目之拉勾网】
4、【ReactNative项目之美食APP】
5、【uni-APP项目实战教程】
6、【React项目管理后台系统】
7、【React项目教程(企业级实战开发)】
8、【NodeJS+Express+MongoDB实战项目】
9、【毕设论文辅导-React美食网】
10、【仿小米电商网站】
11、【仿网易云音乐】
12、【React全家桶-新闻发布管理系统】
13、【简书后台管理系统】
14、【移动端网站布局-打造自己的“手机APP”】
15、【Web支付开发(支付宝和微信支付)】
16、【贪吃蛇小游戏】
17、【Vue实战项目之喵喵电影】
18、【植物大战僵尸网页版】
19、【智慧学成数据展示平台】
……
35、【node图书管理系统】
36、【uniAPP实战仿糗事百科APP】
37、【uniAPP悦读前后端实战】
38、【uniAPP商业级应用】
39、【小程序全栈开发之喵喵交友】
40、【植株健康检测系统】
感谢阅读资料已经为大家准备好了,需要的可以看去下方 希望拿到后对你们有帮助!!!!!
2-3 混合式 App 开发框架 介绍 Hybrid App的兴起是现阶段移动互联网产业的一种偶然。
**原因:**移动互联网的热潮刮起后,众多公司前赴后继的进入。但是很快发现移动应用的开发人员太少,所以导致疯狂的人才争夺。市场机制下移动应用开发人才的待遇扶摇直上,最终变成众多企业无法负担养一个具备跨平台开发能力的专业移动应用开发团队。
背景:而HTML5的出现让Web App露出曙光,HTML5开发移动应用的跨平台和廉价优势让众多想进入移动互联网领域的公司开始心动。可是当下基于HTML5的Web App更是雾里看花,在用户入口习惯、分发渠道和应用体验这三个核心问题没解决之前,Web App也很难得以爆发。
**爆发:**正是在这样是机缘巧合下,基于HTML5低成本跨平台开发优势又兼具Native App特质的Hybrid App技术杀入混战,并且很快吸引了众人的目光。大幅的降低了移动应用的开发成本,可以通过现有应用商店模式发行,在用户桌面形成独立入口等等这些,让Hybrid App成为解决移动应用开发困境不错的选择,也成为现阶段Web App的代言人。Hybrid App像刺客一样,在Native App和Web App混战之时,偶然间的在移动应用开发领域占有了一席之地。
在本节课,我们要介绍关于混合式App开发的相关框架,及它们的特点。
什么是混合式App?
Hybrid App(混合模式移动应用)是指介于web-app、native-app这两者之间的app,兼具“Native App良好用户交互体验的优势”和“Web App跨平台开发的优势”。
为什么要学习/了解混合式App?
拓展前端应用/拓宽视野/增加工作应用面快应用效率开发,与原生配合了解机理,以便在特定的应用场景下进行使用 学习目标:
理解混合式App与Native App/WebApp的区别能够有基础判断,是否应用是由Native App开发或者是混合式开发什么样的场景或者业务,可以使用混合式开发学习ionic/Cordova/Phonegap,并了解其工作原理 主要内容:
混合式App简介Cordova打包工具介绍Phonegap的基础使用及与Cordova的关系Ionic框架的使用与介绍 学习准备:
IDE编辑器:vscode,webstormNodejs LTS版本一部iOS手机或者Android手机mac上需要下载Xcode,windows上需要下 Android Studio如果需要发布,需要开发者身份(AppStore 99美元/年,Android 各大应用商店不一样) 混合式App的工作原理 混合式App(Hybrid App) 什么是混合式App?
混合应用程序:混合应用程序是一种移动应用程序,以浏览器支持的语言和计算机语言编码。 它们可以通过苹果的App Store,Google Play等应用程序分发平台获得。通常,它们可以从平台下载到目标设备,如iPhone,Android手机或Windows Phone。 用户需要安装才能运行它们。
Hybrid App:Hybrid App is a mobile application that is coded in both browser-supported language and computer language. They are available through application distribution platforms such as the Apple App Store, Google Play etc.
为什么只显示一个条目的高度 当然这个问题 16年的时候,是可以在网上搜索出答案,那个时候也并不太了解为什么,而网上的答案也是你抄我我抄你,最后就到了下面答案 当然答案是正确的 但有些表述是错误的。
首先布局是 scrollview+listView
<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <ScrollView android:layout_width="match_parent" android:layout_height="wrap_content"> <com.rq.framelayoutin.MyListView android:id="@+id/lv" android:layout_width="match_parent" android:layout_height="wrap_content"></com.rq.framelayoutin.MyListView> </ScrollView> </FrameLayout> 这里定义MyListView就是为了解决只显示一个条目的问题
我们先不重写onMeasure 看一个效果
public class MyListView extends ListView { public MyListView(Context context) { super(context); } public MyListView(Context context, AttributeSet attrs) { super(context, attrs); } public MyListView(Context context, AttributeSet attrs, int defStyleAttr) { super(context, attrs, defStyleAttr); } @Override protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) { // heightMeasureSpec = MeasureSpec.
总算又想起密码了, 自从用了语雀后, 其他平台基本都不再使用了
csdn 真的**, c h a t g p t 是禁词(已经改为了AGI, 通用型人工智能), 你倒是说清楚啊,直接来一句违反社区规定, 莫名其妙, 得靠猜…服了 今天来补上一篇利用AGI生成的js去广告脚本 前置知识(不看也问题不大) 转发与重定向
转发页面的URL不会改变,而重定向地址会改变
301与302
页面广告生成原理(也是使用AGI) 网页上的广告实现主要依赖于两个技术:Cookie和JavaScript。
Cookie是一种存储在用户计算机上的小型文本文件,它可以记录用户的浏览历史、兴趣偏好等信息。当用户访问网站时,网站会将Cookie存储在用户计算机上。广告平台可以通过读取Cookie中的信息,了解用户的兴趣偏好,从而向用户投放相关的广告。
JavaScript是一种脚本语言,它可以在网页中实现动态效果和交互功能。广告平台通常会将JavaScript代码嵌入到网页中,当用户访问网页时,JavaScript代码会向广告平台发送请求,请求广告内容。广告平台会根据请求的参数,选择合适的广告内容返回给JavaScript代码,然后JavaScript代码将广告内容插入到网页中。
综上所述,网页上的广告实现主要依赖于Cookie和JavaScript技术,通过收集用户信息和动态插入广告内容来实现。
痛点-调研-明确需求-技术选型-编码实现 发现痛点: 经常观看的动漫网站(正经人看的正经网站, 我就不说了, 主打的就是一个吊胃口)有一个很顽固的广告(移动端)
调研: 网上没有相关移动端网站去广告的脚本, 在网上找找相关解决文案需求: 写一个脚本, 能力是去广告技术选型: 使用JavaScript实现: 很多移动端浏览器不支持插件脚本,使用的是火狐浏览器可以使用油猴插件(油猴插件是可以运行脚本, via浏览器可以直接运行脚本) 使用HttpCanary(小黄鸟)抓 包发现广告请求的状态码是301(永久重定向), 然后让gpt帮我写一个脚本测试:分别使用两个浏览器进行测试, 如未达预期跳转到第4步, 成功则发布发布:发布到Greasy Fork脚本网站
进行微调, 处理边界条件, 尝试进行优化: 黑白名单, 防误触, 长按加入黑名单,禁止重定向
最终生成最强1.9版本 // ==UserScript== // @name Advertising Plus // @namespace http://your-namespace-here // @version 1.9 // @description Disable 301 redirects on web pages and block potential ads.
引言 NT架构(New Technology Architecture)是一种面向大规模系统设计的架构模式,旨在构建高性能、可扩展、可维护的系统。作为一名技术专家,我们需要深入理解NT架构的核心原则和设计思想,并学会如何应用它来建立出色的系统。本篇博客将详细介绍NT架构,包括其基本概念、关键组件以及实际案例。
1. NT架构概述 NT架构是一种分层架构模式,将系统划分为多个层次,每个层次都有特定的职责和功能。这种模式使得系统更易于开发、测试和维护,并提供了高度的灵活性和可扩展性。
2. NT架构的核心组件 2.1 数据访问层 数据访问层负责与数据库进行交互,提供数据的读取和写入功能。这一层通常包含了ORM(对象关系映射)工具,用于实现对象与数据库记录之间的映射关系。
class UserRepository: def get_user(self, user_id): # 从数据库中读取用户信息 pass def save_user(self, user): # 将用户信息保存到数据库 pass 2.2 业务逻辑层 业务逻辑层负责实现系统的核心业务逻辑,对外提供服务接口。该层处理来自用户界面或其他系统的请求,协调不同的组件进行业务处理。
class UserService: def register_user(self, user_data): # 处理用户注册逻辑 pass def delete_user(self, user_id): # 处理用户删除逻辑 pass 2.3 用户界面层 用户界面层负责与用户进行交互,接收用户的输入,并将结果展示给用户。该层可以是Web界面、移动应用界面或者命令行界面。
class WebController: def register_user(self, request): # 处理用户注册请求 pass def delete_user(self, request): # 处理用户删除请求 pass 2.4 其他组件 除了上述核心组件之外,NT架构还可以包含其他组件,如缓存、消息队列、日志系统等,用于提高系统的性能和可靠性。
3. NT架构的优势和实际应用 NT架构具有以下优势:
可扩展性:通过分层架构和组件化设计,系统可以轻松地扩展和添加新功能。可维护性:每个层次的职责清晰,使得系统更易于理解、测试和维护。高性能:通过优化关键组件,如数据访问层和缓存,系统可以实现高性能的数据处理和响应能力。
NT架构在实际应用中广泛使用,例如电子商务系统、大规模分布式系统、企业级应用等。以下是一个简单的示例: class EcommerceSystem: def __init__(self): self.
在项目开发中往往需要使用到数据的导入和导出,导入就是从Excel中导入到DB中,而导出就是从DB中查询数据然后使用POI写到Excel上。所以今天就为大家带来一款基于阿里EasyExcel的导入导出功能,开放了一个demo,以下是gitee地址,有兴趣的可以去看看:EasyExcelDemo:基于EasyExcel实现导入导出的简易demo
该demo以及我下面所要分享的都是使用的mongodb来做的,使用mysql的小伙伴大同小异,自己改造一下,后续如果有时间的话我会在gitee以及这里更新mysql的方式
===================================================================================================
2023/07/03 更新:
百忙之中抽空更新了mysql的导入导出方式,代码已提交,放在gitee公开项目上,感兴趣的去拉取下来观看、改造、直接使用都可以,mysql的方式和mongo的方式都大同小异,就不在文章下面更新代码和使用方式了
====================================================================================================
1.引入依赖 <!--easyexcel--> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>3.0.5</version> </dependency> <!-- 随机数据生成 --> <dependency> <groupId>com.apifan.common</groupId> <artifactId>common-random</artifactId> <version>1.0.16</version> </dependency> 2.测试数据制造 可以看到,在上面的maven中,我提到了一个随机数据生成的依赖,这个依赖是我在网上找到的,简直就是解放了我们的双手(当时我是打算通过手敲方法,调用方法来生成的,下载了demo的可以在工具类中看到,我已经写了不少了手动封装数据的方法);详细的使用方式步骤,更多的数据生成方式可以参考这篇博客:Java-随机数据生成器
调用数据生成方法:
/** * 随机生成一条用户数据 * * @return */ public static Map createUserdata() { //生成1个随机中文人名(性别随机) String userName = PersonInfoSource.getInstance().randomChineseName(); //生成1个随机中国大陆手机号 String phone = PersonInfoSource.getInstance().randomChineseMobile(); //生成1个随机QQ号 String qqNumber = PersonInfoSource.getInstance().randomQQAccount(); //生成1个随机邮箱地址,后缀为163.com,邮箱用户名最大长度为10 String email = InternetSource.getInstance().randomEmail(10, "163.com"); //生成1个2000年的随机日期,日期格式为yyyy-MM-dd String borthday = DateTimeSource.getInstance().randomDate(2000, "yyyy-MM-dd"); //生成过去36000秒范围内的随机时间 LocalDateTime lastLogintime = DateTimeSource.getInstance().randomPastTime(LocalDateTime.now(), 36000); //生成1个随机强密码,长度为16,无特殊字符 String pwd = PersonInfoSource.
使用navicat访问服务器mysql时的权限配置 在MySQL的user表中,host列表示允许访问MySQL服务器的主机地址或主机名。该列指定了允许连接到MySQL服务器的来源。例如,localhost表示只允许本地主机连接,而%表示允许来自任何主机的连接。所以修改user表中的host列为%,即可远程访问服务器mysql。 1.在服务器上运行mysql mysql -u root -p 2.进入其中的mysql数据库
use mysql; 3.查看数据库的user和host表中的权限信息
select user from user; select host from user; 4.修改”localhost“为“%”
我们要修改的是user列为root所对应的host列中的localhost,可输入以下代码进行修改。
update user set host = '%' where user ='root'; 5.刷新mysql
flush privileges; 6.navicat连接服务器mysql
现在便可以通过navicat成功连接服务器mysql了。
vue项目打包后,页面加载错误,报错"Uncaught SyntaxError:Unexpected token <" - 简书
简介 基于统计的方法是经典的时间序列预测模型,也是财务时间序列预测的主要方法。他们假设时间序列是由随机冲击的线性集合产生的。一种有代表性的方法是ARMA模型,它是AR和MA模型的组合。它被扩展到非平稳时间序列预测,称为自回归综合移动平均(ARIMA),它结合了差分技术来消除数据中趋势分量的影响,并且由于其巨大的灵活性而成为最受欢迎的线性模型之一。然而,这种方法最初仅限于线性单变量时间序列,并且不能很好地适应多变量设置。为了应对多变量时间序列预测,ARIMA的扩展模型VARMA被提出,该模型通过允许多个进化变量来推广基于单变量ARIMA的模型。
ARIMA模型有三个参数:p、d和q。参数p是模型中滞后观测的数量,也称为滞后阶数。参数d是原始观测值被差分的次数;也称为差异程度。参数q是移动平均窗口的大小,也称为移动平均的阶数。
步骤 确定平稳性:ARIMA模型是一种统计模型,用于基于历史数据中存在的自相关来预测未来值。它假设未来趋势将遵循与历史趋势相同的模式,并要求时间序列是固定的。非平稳性会导致预测误差和参数估计不稳定,从而降低预测结果的可靠性。因此,确定时间序列是否稳定非常重要。数据预处理:应用ADF测试来测试原始数据的平稳性。如果测试结果表明数据是非平稳的,则将对数据进行差分,直到达到平稳状态。数据规范化:数据规范化是一种预处理技术,用于将数据调整到一个通用的规模或范围。当处理表现出显著数值幅度的数据时,有必要对数据进行归一化,以促进有效的训练。我在Python中使用了MinMaxScaler函数,并在0和1之间分别转换了每个特性。确定参数:使用AIC准则以及观察自相关图(ACF)和偏自相关图(PACF)。 代码构建 首先导入需要用到的Python包:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from statsmodels.tsa.stattools import adfuller from statsmodels.tsa.arima.model import ARIMA from sklearn.preprocessing import MinMaxScaler from statsmodels.graphics.tsaplots import plot_acf, plot_pacf from statsmodels.stats.diagnostic import acorr_ljungbox 然后读取.csv文件的时序数据,这里使用了英国的GDP数据
# 1. 读取csv时序数据 data = pd.read_csv('datasets/UK_GDP.csv')[["GDP"]] data_origin = data.copy() 接着使用adf测试判断稳定性
# 2. 使用adf测试数据是否稳定,如果不稳定进行一阶差分,并打印差分前和差分后的数据图。 result = adfuller(data) print("Test Statistic: %f" % result[0]) print("p-value: %f" % result[1]) print("No. of lags used: %f"
目录
一、程序控制
①输入输出
Ⅰ.cin&cout
Ⅱ.scanf&printf
②运算与符号
Ⅰ常用数学函数#include
Ⅱ.数据类型转换
③控制结构
④函数
Ⅰ.函数定义
Ⅱ函数使用
二、数据结构
①一维数组
排序与查找
②多维数组
③指针
Ⅰ字符,指针运算
Ⅱ字符串函数#include
Ⅲ指针参数与动态内存
④结构:struct
⑤链表
三、文件操作
Ⅰ基本文件输入输出
Ⅱ文件指针
四、类和对象
①类的创建和使用
②静态成员
③构造函数
④类的复合
⑤This指针
⑥友元
Ⅰ友元函数
Ⅱ友元类
五、运算符重载
①原理
②方式
Ⅰ成员函数重载
Ⅱ友元函数重载
③单目与双目运算符重载
Ⅰ单目(目表示操作数)
Ⅱ流插入和流提取运算符的重载
Ⅲ双目
Ⅳ类型转化
六、继承派生多态
①继承
Ⅰ成员函数的重定义
Ⅱ类指针
②多态
Ⅰ虚函数
Ⅱ抽象基类与纯虚函数
Ⅲ虚析构函数
③STL
Ⅰ动态学生信息管理https://www.educoder.net/tasks/p4imnbvy/887783/ok8rac4vzhbx?coursesId=p4imnbvy
Ⅱ还原键盘输入https://www.educoder.net/tasks/p4imnbvy/887783/yf2swgkio7ma?coursesId=p4imnbvy
一、程序控制 ①输入输出 Ⅰ.cin&cout 流操作算子 #include<iomanip>
setbase(n),进制,n=8,10,16
setprecision(n),浮点数精度设置为n
setw(n),域宽n,小于n空位填充,大于n输出所有
setiosflags(long),long,流格式状态标志
#include <iostream> #include<iomanip> #include<string> using namespace std; int main() { //setbase(n),进制,n=8,10,16 int a = 1000; cout << "
一,博主环境:CentOS7 第一步:wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm 第二步:yum -y install epel-release 第三步:rpm -Uvh erlang-solutions-1.0-1.noarch.rpm 第四步:sudo yum install erlang 第五步(验证是否安装成功):erl 第六步(查看安装位置)whereis erlang
1.在设置开机自启动前,需要测试ok的可进行执行的sh脚本,比如 /home/user/myscript.sh, 切记sh脚本中给出可执行的路径文件 2、给该脚本文件赋予可执行权限,命令如下: sudo chmod +x /home/user/myscript.sh 1. 方法 一 ubuntu上找到session and Startup或者Startup Application,这是在设置当中,如果是中文,则是 启动应用程序,
如果是ubuntu老版本或者镜像版本,直接搜Startup
点击添加add,在名称中输入自定义名称,在命令command中输入sh脚本的位置,注释可以不填,然后点击保存 然后reboot进行重启,可开机自启
2. 方法二 方法2是使用的是ubuntu18.04以上版本存在的systemd 服务,注意低版本的ubuntu可能不支持该服务
1. 在/etc/systemd/system 目录下创建一个新的 service 文件,命名为 myscript.service:
sudo vim /etc/systemd/system/myscript.service 2. 在该文件中输入以下内容:
[Unit] Description=My Script Service After=network.target [Service] User=user ExecStart=/home/user/myscript.sh [Install] WantedBy=multi-user.target 各参数解释:
【Description】 对本服务的描述【After】字段不是必须的,服务依赖的其他服务,本例中需要在 network.target 服务启动后才能启动本服务。可以省略。如果省略该字段,则 systemd 将默认将当前服务的启动顺序设置为与其他服务无关,即在启动过程中没有任何依赖性关系,服务的启动顺序由系统自行决定。然而,在某些情况下,如果服务依赖于其他服务,可以使用 After 字段来明确指定其依赖关系,以确保服务的启动顺序正确。【User】字段不是必须的,如果省略该字段,服务将使用 root 用户来运行脚本。【ExecStart】 关键字段,服务启动命令,指定服务启动时需要执行的命令或脚本【WantedBy】用于指定服务的自动启动级别,在 Linux 系统中,多用户模式是指允许多个用户同时登录并使用系统资源的模式,与之相对的是单用户模式,只有一个用户可以登录并使用系统资源。多用户模式是 Linux 系统最常用的模式之一,因此 multi-user.target 是系统默认的运行级别。
3. 保存并关闭该文件,然后启动该服务并将其设置为开机自启:
sudo systemctl daemon-reload sudo systemctl start myscript.
ORM 把类映射成数据库中的表,把类的一个实例对象映射成数据库中的数据行,把类的属性映射成表中的字段,通过对象的操作对应到数据库表的操作,实现了对象到SQL、SQL到对象的转换过程。
下面以一个商品库存明细表 myfirstapp_sku(包含商品编号、货号、颜色、尺码、库存属性字段),分别用ORM和sql语句对该表进行增删改查操作:
1. 创建表 ORM class Sku(models.Model): # 模型类要继承models.Model sku = models.IntegerField(max_length=20, verbose_name="商品编号") goods_no = models.IntegerField(max_length=20, verbose_name="货号") co_val = models.CharField(max_length=20, verbose_name="颜色") si_val = models.CharField(max_length=20, verbose_name="尺码") sale_stock = models.IntegerField(max_length=20, verbose_name="库存") MySQL CREATE TABLE `myfirstapp_sku` ( `id` bigint NOT NULL AUTO_INCREMENT, `sku` int unsigned NOT NULL AUTO_INCREMENT COMMENT '商品编号', `goods_no` int unsigned NOT NULL DEFAULT '0' COMMENT '货号', `co_val` varchar(50) NOT NULL DEFAULT '' COMMENT '颜色', `si_val` varchar(50) NOT NULL DEFAULT '' COMMENT '尺码', `sale_stock ` smallint unsigned NOT NULL DEFAULT '0' COMMENT '库存', PRIMARY KEY (`id`)) ; 2.
1、需求:需要知道当前app或者当前app的指定页面是被谁启动的,被哪个第三方app启动的,来判断是否允许对方启动,如果不被允许的第三方,则不启动app或者不启动app的指定页面。
2、直接上代码。
第一种方式:
// 结果: android-app://com.google.a getReferrer(); 第二种方式:
/** * 通过反射获取referrer. * @return : com.google.a */ private String reflectGetReferrer() { try { Field referrerField = Activity.class.getDeclaredField("mReferrer"); referrerField.setAccessible(true); return (String) referrerField.get(this); } catch (NoSuchFieldException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } return ""; } 调用方式:
public class OpenActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); // setContentView(R.layout.open_activity); // TextView test = findViewById(R.id.test_open); // test.setText("第二页面"); // getReferrer(): android-app://com.
作为Java开发者,我们很清楚IDEA是一款功能强大、开箱即用的集成开发环境。不过,如果能够采用各种类型的IDEA插件来扩展IDEA的功能,进一步提升我们的开发效率,将是非常有价值的。在本文中,我们将分享一些适合各种类型开发者使用的IDEA插件,并探究它们如何提高我们的工作效率。
安装插件教程
在这里直接搜索就行了
1强烈推荐的插件 Presentation Assistant 快捷键展示 录屏或者共享的时候,效果极佳
Codota— 代码智能提示 还可以搜索相关代码的示例
Codota还包含一个网站:https://www.codota.com/code
Alibaba Java Code Guidelines— 阿里巴巴 Java 代码规范 可以切换中英文
有什么不符合阿里巴巴Java开发手册的都会显示出来
Translation - 必备的翻译插件 快捷键
command+ctrl+i(mac)
ctrl + shift + o(win/linux)
SequenceDiagram —— 调用链路自动生成时序图 右键 --> Sequence Diagaram 即可调出。
双击顶部的类名可以跳转到对应类的源码中,双击调用的函数名可以直接调入某个函数的源码。
Rainbow Brackets ——让你的括号变成不一样的颜色,防止错乱括号 HighlightBracketPair —— 括号开始结尾 高亮显示。 Grep Console 控制台日志 高亮 google-java-format —— 代码自动格式化 这个插件的优点在于不需要手动快捷键去格式化代码
Key promoter X —— 会有这个操作的快捷键在界面的右下角进行告知。 CodeGlance —— 缩略图 这个插件可以向查看缩略图一样,帮助我们快速切换到所要的代码区域,而不用疯狂地拖拽一遍去找。
Leetcode Editor 可以在IDEA中在线刷题。 上班摸鱼属实方便,表面上我在干活,实际上我在刷算法题。
2装饰类 Material Theme UI ——IDEA主题插件 Power Mode II —— 打字效果 Background Image Plus + —— 更换IDEA背景 3较便利插件 RoboPOJOGenerator—JSON (GsonFormat也可以,但是好久没更新过了) Statistic— 项目信息统计 可以非常直观地看到你的项目中所有类型的文件的信息
目录
前言
1、String工具类
2、File工具类
3、接口资源扫描工具类
4、SQL脚本格式化工具类
5、ip地址工具类
6、文件上传工具类
7、获取用户登录信息的工具类
前言 我们在进行项目开发的时候可能会经常用到一些字符串相关的操作,然后可能产生大量冗余的代码,这时候可以把我们用到的操作提取出来,放到一个单独的工具类里,比如命名为StringUtils,这个工具类里的方法几乎可以涵盖我们日常所需,接下来,我将个人的几个工具类分享给大家。
1、String工具类 import org.springframework.web.multipart.MultipartFile; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; /** * String工具类 * @author heyunlin * @version 1.0 */ public class StringUtils { /** * 判断字符串是否为null或"" * 字符串为""或null返回true,否则返回false * @param str 要判断的字符串 * @return boolean */ public static boolean isEmpty(String str) { return isNullOrEmpty(str); } /** * 判断字符串是否为""或null * 字符串为""或null返回false,否则返回true * @param str 要判断的字符串 * @return boolean */ public static boolean isNotEmpty(String str) { return !
实现目标: 偶然间看到一个色弱小测试,就想着用自己的方式去实现一下。
如图:
主体实现思路: 这里主要说中间的色块如何实现,操作中可以看出从2X2逐步变成8X8的正方形,每次仅点击一个点。
需要一个变量用于表示边有多少个数。
需要选择的方块用横纵两个变量表示。
初步思路有了开始实际操作。
主要实现代码: // 结构 <view v-if="gameType == 1" class="gameBox"> <text class="beginTitle">色弱小测试</text> <view class="headbox"> <text>时间:{{gameTime}}</text> <text>得分:{{gameScore}}</text> </view> <view class="box"> <view v-for="(item,indexOne) in baseCount" class="hengBox"> <view @click="selDiv(indexOne,indexTwo)" v-for="(item,indexTwo) in baseCount" :style="{'height':ceshiWith}" class="smellBox"> <view v-if="indexOne == selOne && indexTwo == selTwo" class="bcgColor" :style="{'background':selColor}"></view> <view v-else class="bcgColor" :style="{'background':defColor}"></view> </view> </view> </view> </view> // 需要的变量 data() { return { gameType: 0, // 0准备,1游戏中 baseCount: 2, // 边个数 selOne: 1, // 高亮竖边 selTwo: 0, // 高亮横边 selColor: 'hsl(200,90%,50%)', // 高亮颜色 defColor: 'hsl(200,60%,50%)', // 其他方块颜色 ceshiWith: '', // 每个小方块的高度 gameTime: 60, // 游戏时间 gameScore: 0, // 游戏得分 gameType: 0, // 0准备,1游戏中 } } // 方法 methods: { // 判断是否点击的是高亮方块 selDiv(one, two) { if (one == this.
随着现在混合开发的火热,React Native和Weex的兴起,越来越多的人学习混合开发,下面就github上一篇React Native的资料合集。
React-Native学习指南 目录 教程
React Native
React.js
ES6
系列教程
开源APP
图书
组件
工具
资源网站
业界讨论
教程 React Native 构建 Facebook F8 2016 App / React Native 开发指南 http://f8-app.liaohuqiu.net/
React-Native入门指南 https://github.com/vczero/react-native-lesson
30天学习React Native教程 https://github.com/fangwei716/30-days-of-react-native
React-Native视频教程(部分免费) https://egghead.io/technologies/react
React Native 开发培训视频教程(中文|免费) https://www.gitbook.com/book/unbug/react-native-training/details
react-native 官方api文档 http://facebook.github.io/react-native/docs/getting-started.html
react-native中文文档(极客学院) http://wiki.jikexueyuan.com/project/react-native/
react-native中文文档(react native中文网,人工翻译,官网完全同步) http://react-native.cn/docs/getting-started.html
react-native第一课 http://html-js.com/article/2783
深入浅出 React Native:使用 JavaScript 构建原生应用 http://zhuanlan.zhihu.com/FrontendMagazine/19996445
React Native通信机制详解 http://blog.cnbang.net/tech/2698/
React Native布局篇 https://segmentfault.com/a/1190000002658374
React Native 基础练习指北(一) https://segmentfault.com/a/1190000002645929
React Native 基础练习指北(二) https://segmentfault.
今天重装系统发现下载低版本的1.8很难找到下载地址,有些就是要积分。 这里免费找到了Oracle官网的下载地址,大家可以免费尽情下载。具体地址如下:
https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html
一、项目简介 股票预测是金融领域中的重要问题,通过对历史股票数据的分析和建模,我们可以尝试预测未来股票的价格趋势,为投资决策提供参考。本项目是基于PyTorch深度学习框架实现一个使用2D卷积神经网络和LSTM预测网络(2DCNN+LSTM)来进行股票收盘价预测的项目,该网络可以有效地处理时间序列数据,通过卷积层和LSTM层提取输入序列中的特征,并通过全连接层进行预测。网络的输入是历史股票开盘价、收盘价、最高价、最低价、成交量指标、百分比变化量(多特征),输出是预测下一天的股票收盘价。【本项目的代码文件分模块整理,包含模型构建、数据划分、训练过程等模块都清晰分明】
二、实验数据集 实验采用的是深沪300数据集sh300.csv(后文有源码和数据集获取方式),这是公开的数据集,百度一下应该也可以找得到,数据集展示如下(所展示的数据是本人删掉某些列的数据,即sh300_test.csv),实验只使用了红框中的数据特征作为输入特征进行预测。
数据划分:以滑窗的方式进行数据划分,滑窗大小为20,输入特征为6,每次滑窗的第21天的收盘价为预测的标签值。
三、实验环境 平台:Window 11;语言:python3.9;编译器:Pycharm;框架:Pytorch:1.13.1
四、实验内容及部分代码展示 1、model_2DCNN_LSTM.py 模型构建 model_2DCNN_LSTM.py定义了项目用到的网络模型,本项目用到的模型是三层的一维卷积网络,使用relu激活,最后使用两层全连接层输出预测结果。
2、train.py 训练通用模板 训练过程集成到fit函数里面,包含测试集训练过程和验证集计算过程,是项目训练过程的通用代码,其他项目也可以在它的基础上修改后使用。
3、Config.py 参数定义 config中定义了项目所有需要的参数,可以在里面修改训练参数。其中可以看到三个卷积层的输出通道为[16,32,64]。根据实现效果调试[16,32,64]的训练效果比[32,64,128]要好很多,原因可能是数据集比较简单,通道数设置少一些就可以提取出不错的特征。
4、DataSplit.py 数据划分 DataSplit.py 是实现数据划分的函数,通过滑动窗口,将每个窗口大小的六个特征数据作为训练数据,将滑窗后面一个收盘价的数据作为预测结果并制作成标签,最后再进行划分训练数据和标签,最后分成训练集和验证集。
5、test_stock_2dcnnLSTM_run.py 训练文件 该py文件实现整体训练流程并做绘图操作。依次实现加载数据、数据标准化、取出WIND数据、划分训练集测试集、数据转化为Tensor、形成数据更迭器、载入模型、定义损失、定义优化器、开始训练、损失可视化、显示预测结果。
6、test_pth.py 模型训练后的测试文件 采用模型训练完成后产生的的pth参数文件对测试数据进行预测,可以展示模型预测效果,前面的处理过程类似test_stock_2dcnnLSTM_run.py所示。
7、loss_draw.py 模型训练后的测试文件 将训练产生并收集的loss.csv展示出来,也就是损失图,红框处可调展示范围。 五、实验结果及分析 1、损失图 ①训练了200个epoch的损失图:
②训练了200个epoch的损失图(局部0-0.0001):
2、预测效果展示 ①训练epoch=200后的股票收盘价预测效果如下(使用pth文件进行预测):其中,蓝色为预测曲线,红色为真实曲线,显然,预测基本相近。
② 局部展示(展示前两百天的预测效果):局部展示的效果也算是不错的
六、总结及资源 若有朋友需要可运行的源码和数据集,可以guan注【科研小条】公众号,回复【股票预测2DLS】,即可获得。
目录 1.如何查看项目中使用的版本?1)通过代码进行查看2)通过 pom.xml 进行查看3)通过 mvn 命令进行查看 2.Spring Boot 和 Spring 版本对应关系1)根据官网判断2)根据官方文档判断2.1)查看具体版本的官方文档2.2)查看大版本的官方文档 3)根据 Maven 仓库判断3)根据官方文档整理的版本对应信息【核心】 3.Spring Cloud 和 Spring Boot 版本对应关系补充:1.通过 Spring Initializr 下载的包构建报错:类文件具有错误的版本 61.0, 应为 52.0 Spring 官网地址: https://spring.io/
Spring Boot 官网地址: https://spring.io/projects/spring-boot
Spring Cloud 官网地址: https://spring.io/projects/spring-cloud
Spring Initializr 官网地址: https://start.spring.io/
Spring Boot 官方文档: https://docs.spring.io/spring-boot/docs/
Spring Boot 官方各版本文档: https://docs.spring.io/spring-boot/docs/{版本号}/reference/htmlsingle/
1.如何查看项目中使用的版本? 以下提供了三种查看项目所使用的 Spring 版本的方法:
1.通过代码进行查看:可以查看 Spring、Spring Boot 版本;2.通过 pom.xml 进行查看:可以查看 Spring Boot、Spring Cloud 版本;3.通过 mvn 命令进行查看:可以查看 Spring、Spring Boot、Spring Cloud 版本。 下面我们就看下这三种方法的具体使用:
题目描述 小sun上课的时候非常喜欢玩扫雷。他现小sun有一个初始的雷矩阵,他希望你帮他生成一个扫雷矩阵。 扫雷矩阵的每一行每一列都是一个数字,每个数字的含义是与当前位置相邻的8个方向中,有多少个雷(在下图中,雷用表示);如果当前位置就是雷的话,仍输出一个。
比如初始的雷矩阵如下:
.... ..** *.*. .*.* 对应的数字矩阵为:
0122 13** *4*4 2*3* 输入描述: 第一行两个整数n,m,代表矩阵有n行m列 接下来共n行,每行m个字符 输出描述: 输出共n行m列,为扫雷矩阵。 示例1
输入 复制
4 4 .... ..** *.*. .*.* 输出 复制
0122 13** *4*4 2*3* 示例2
输入 复制
3 4 .... *..* .*.* 输出 复制
1111 *23* 2*3* 代码 public class Main { public static void main(String[] args) { Scanner in = new Scanner(System.in); int m = in.
实验信息 Kali:192.168.10.106
WestWild:192.168.104
实验过程 通过arp-scan查找目标主机,确定目标主机IP192.168.10.104
sudo arp-scan --interface eth0 192.168.10.0/24 探测靶机开放的端口
sudo nmap -sT --min-rate 10000 -p- 192.168.10.104 -oA nmap/result 对刚刚扫出来的端口进行详细的扫描+脚本扫描
sudo nmap -sT -sC -sV -O -p22,80,139,445 192.168.10.104 -oA nmap/detail sudo nmap --script=vuln -p 22,80,139,445 192.168.10.104 -oA nmap/vuln 同时也进行UDP扫描,万一TCP端口没有进展可以尝试UDP端口
sudo nmap -sU --top-ports 20 192.168.10.104 -oA nmap/udp 先从80端口开始
尝试下常见的文件,并没有存在
http://192.168.10.106/readme.txt http://192.168.10.106/robots.txt 用gobuster来爆破
网页源码什么都没什么有用信息,网页上有一张图片下载来看有没有隐写一些信息
80端口没有什么可用信息,只能转头试试看smb服务
sudo smbmap -H 192.168.10.104 wave目录是可读的,看看有没有可用的信息
sudo smbmap -H 192.168.10.104 prompt get message_from_aveng.txt get message_from_aveng.txt exit FLAG1.
QTextEdit设置显示的最大行数 Qt版本 5.12.9
代码 ui->textEdit->document()->setMaximumBlockCount(100); 效果 设置了之后,使用apend函数追加一行,当到达最大的行数时,QTextEdit会自动删除最开始位置的一行,保持行数不变
二分查找 1. 什么是二分查找2. 原理3. 例子3.1 当数组长度为奇数3.1 当数组长度为偶数3.3 实现过程 4. 顺序查找与二分查找的区别结束语 1. 什么是二分查找 二分查找也称折半查找,是在一组有序(升序/降序)的数据中查找一个元素,它是一种效率较高的查找方法。
2. 原理 查找的目标数据元素必须是有序的。没有顺序的数据,二分法就失去意义。数据元素通常是数值型,可以比较大小。将目标元素和查找范围的中间值做比较(如果目标元素=中间值,查找结束),将目标元素分到较大/或者较小的一组。通过分组,可以将查找范围缩小一半。重复第三步,直到目标元素=新的范围的中间值,查找结束。 3. 例子 (本文以升序为例进行讲解,降序方法类似)
3.1 当数组长度为奇数 假设有一组数据{1,2,3,4,5,6,7}
是奇数的情况很简单,指向中间的数字也很容易理解
如果要查找的数字是6,因为6大于中间的数字(4),所以舍去左边的数据。
3.1 当数组长度为偶数 当取中间元素,遇到两边数据个数不同时,并不影响我们查找元素,只需要规定是向上或向下取整。
所以数组长度是偶数还是奇数这个并不重要,也不影响怎么排除的问题,无非是多排除一个数字或者少排除一个数字。
3.3 实现过程 在 {1,2,3,4,5,6,7,8,9,10} 中查找元素9。
第一步要找到中间元素,设置两个变量low、high,分别指向数组第一个元素下标和最后一个元素下标,从而控制数组的范围,再根据low和high确定中间元素的下标mid
根据mid锁定的元素,和查找的元素(9)比较,确定新的查找范围、low 和high
此时,mid=8,arr[mid]=9,与要查找的元素相同,即已经找到了,并返回其下标。
如果数组中没有要查找的元素,会出现什么情况呢?
假设我们上面要查找的元素是:11
此时low=high=mid=9,arr[mid]=10不等于11,查找了整个数组都没有找到。
根据上述过程编写代码:
定义所需变量:
int arr[10] = {1,2,3,4,5,6,7,8,9,10};//定义一个初始数组 int n;//被查找的数 printf("请输入你要查找的数:"); scanf("%d", &n);//输入 int len = sizeof(arr)/sizeof(arr[0]);//计算数组长度 int low = 0; int high=len-1;//数组最后一个元素的下标 int mid=(low+high)/2;//中间元素的下标 查找过程中,low一直在high的左边,即low<high,当low=high时还没有找到,就说明该数组中没有要查找的数。
我们用while循环语句控制查找过程
while语句的用法
while (low <= high)//循环结束条件 { //确定数组范围 mid = (low + high) / 2; if (arr[mid] == n) { printf("
论文 attention计算公式如下
传统实现需要将S和P都存到HBM,需要占用 O ( N 2 ) O(N^{2}) O(N2)内存,计算流程为
因此前向HBM访存为 O ( N d + N 2 ) O(Nd + N^2) O(Nd+N2),通常N远大于d,GPT2中N=1024,d=64。HBM带宽较小,因此访存会成为瓶颈。
该论文主要出发点就是考虑到IO的影响,降低内存占用和访问,主要贡献点为:
重新设计了计算流程,使用softmax tiling的方法执行block粒度的计算不需要存储矩阵P,只存储归一化因子,再反向的时候可以快速的recompute softmax tiling的整体流程如下图,外层第j次循环拿到K矩阵的第j个block k j kj kj,内层第i次循环拿到Q矩阵的第i个block Q i Qi Qi,计算得到S和P,然后再和 V j Vj Vj相乘得到 O i Oi Oi
然后看下如何计算出softmax。考虑数值稳定性的softmax的传统计算流程如下,需要减去当前行的最大值
这里的max和sum都需要一行的完整结果。
而flash attention的流程基于递推实现block粒度的计算:
单看S的一行,假设 m ( x ) m(x) m(x)为执行到第i个block即 S ( i ) S(i) S(i)的最大值,现在执行第i + 1个block S ( i + 1 ) S(i + 1) S(i+1),那么新的 m ( x ) = m a x ( m ( x ) , m ( S ( i + 1 ) ) ) m(x) = max(m(x), m(S(i + 1))) m(x)=max(m(x),m(S(i+1))),由于最大值发生了变化,因此之前i个block对应的f(x)要进行修正,之前减去的是 m ( x ( 1 ) ) m(x^{(1)}) m(x(1)),因此要将他加回来,再减去新的 m ( x ) m(x) m(x),即 e m ( x ( 1 ) − m ( x ) ) f ( x ( 1 ) ) e^{m({x^{(1)} - m(x))}} f(x^{(1)}) em(x(1)−m(x))f(x(1)),同理对于sum,最后就可以得到softmax,完整流程如下
原因:后端token字符写成了header 与前端保持一致
目录
1.VGG的简单介绍 1.2结构图
3.参考代码
VGGNet-16 架构:完整指南 |卡格尔 (kaggle.com) 1.VGG的简单介绍 经典卷积神经网络的基本组成部分是下面的这个序列:
带填充以保持分辨率的卷积层;
非线性激活函数,如ReLU;
汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中 (Simonyan and Zisserman, 2014),作者使用了带有3×3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2×2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。
VGG的全称是视觉几何小组,隶属于牛津大学科学与工程系。它发布了一系列从VGG开始的卷积网络模型,可以应用于人脸识别和图像分类,从VGG16到VGG19。VGG研究卷积网络深度的初衷是了解卷积网络的深度如何影响大规模图像分类和识别的准确性和准确性-Deep-16CNN),为了加深网络层数并避免参数过多,在所有层中都使用了一个小的3x3卷积核。
1.2结构图 VGG的输入被设置为大小为224x244的RGB图像。为训练集图像上的所有图像计算平均RGB值,然后将该图像作为输入输入到VGG卷积网络。使用3x3或1x1滤波器,并且卷积步骤是固定的。有3个VGG全连接层,根据卷积层+全连接层的总数,可以从VGG11到VGG19变化。最小VGG11具有8个卷积层和3个完全连接层。最大VGG19具有16个卷积层+3个完全连接的层。此外,VGG网络后面没有每个卷积层后面的池化层,也没有分布在不同卷积层下的总共5个池化层。下图为VGG结构图:
关于架构图:
VGG16包含16层,VGG19包含19层。在最后三个完全连接的层中,一系列VGG完全相同。整体结构包括5组卷积层,后面是一个MaxPool。不同之处在于,在五组卷积层中包括了越来越多的级联卷积层。
3.参考代码 VGGNet-16 架构:完整指南 |卡格尔 (kaggle.com) 在这里讲述了一个比较完整的代码记录,本文参考李沐老师所写
import torch from torch import nn from d2l import torch as d2l def vgg_block(num_convs, in_channels, out_channels): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) layers.append(nn.ReLU()) in_channels = out_channels layers.append(nn.MaxPool2d(kernel_size=2,stride=2)) return nn.Sequential(*layers) conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) def vgg(conv_arch): conv_blks = [] in_channels = 1 # 卷积层部分 for (num_convs, out_channels) in conv_arch: conv_blks.
找不到EFI目录:grub-install问题 1.设置启动分区
hd为硬盘,gpt为硬盘分区,逐一尝试搜索系统
参考:【Ubuntu】Ubuntu更新到2020.04后开机只能进入grub界面解决方案_安装ubuntu进入grub界面_uling94的博客-CSDN博客
但后续步骤一直提示 找不到EFI目录
2.使用引导软件修复成功,再次重启电脑不需要手动设置启动分区
参考:技术|Linux下修改引导器的工具:Boot-Repair
终端输入以上命令,耐心等待一段时间 。ok~
更多关于西门子S7-200PLC内容请查看:西门子200系列PLC学习课程大纲
创建西门子200PLC程序分五步:1.打开Micro/WIN软件;2.新建工程;3.打开程序编辑器;4.输入程序指令;5.保存程序。
我们以下图程序为例讲解西门子200PLC程序建立过程: 一.打开Micro/WIN软件 点击程序即可运行Micro/WIN软件,如下图所示 二.新建程序工程 点击图示文件->新建 ,即可创建下图工程,一般打开程序会默认创建一个工程 三.打开程序编辑器 点击程序块1,打开程序编辑器2,可以看到有三个程序块,分别为主程序,SBR_0子程序,INT_0中断程序。
四.输入程序指令 1,创建第一个程序段网络,即网络1,分为五个步骤,即下面的(1),(2),(3),(4),(5); (1)如下图,将常开触点指令1或者2拖拽到网络1的区域3处;
(2)拖拽完成或者输入完成后如下图,点击?号区域,输入M0.0(此处应该是常闭触点);
(3)输入M0.0后如下图1所示,这时候点击定时器2,将其拖入程序网络1的区域3处(此处M0.0应该是常闭触点);
(4)完成(3)步骤后如下图示,分别在两个?处输入,上面输入T33表示定时器编号,左边?输入100表示定时时间(此处M0.0应该是常闭触点);
(5)完成(4)步骤后,结果如下图所示,完成第一个程序段网络1(此处M0.0应该是常闭触点).
2.安按照1的五个步骤输入其他程序段网络2和网络3,输入完成结果如下 五.保存程序 如下图所示,点击文件->另存为即可保存
def get_out(input): # 加载模型 model = onnx.load('weights/truck-cls.onnx') # 模型推理 ori_output = copy.deepcopy(model .graph.output) # 输出模型每层的输出 for node in model.graph.node: for output in node.output: model.graph.output.extend([onnx.ValueInfoProto(name=output)]) ort_session = onnxruntime.InferenceSession(model.SerializeToString()) ort_inputs = {ort_session.get_inputs()[0].name: input} ort_outs = ort_session.run(None, ort_inputs) #获取所有节点输出 outputs = [x.name for x in ort_session.get_outputs()] # 生成字典,便于查找层对应输出 ort_outs = OrderedDict(zip(outputs, ort_outs)) print("Mul_106") print(ort_outs["173"]) input 为输出图片
该文章已同步收录到我的博客网站,欢迎浏览我的博客网站,xhang’s blog 1.Dubbo和OpenFeign的简介 Dubbo一个高性能rpc框架,用于构建分布式微服务架构,它提供了服务注册与发现,负载均衡,容错机制等功能。Dubbo具有高性能和低延迟的特点,适合于大规模的分布式系统。OpenFeign一个基于Java的声明式HTTP客户端框架,它简化了编写远程调用代码的过程。OpenFeign允许开发人员通过编写接口的方式定义对远程服务的访问,然后通过注解来配置请求参数、路径等信息。OpenFeign会根据接口的定义自动生成具体的实现代码。它还提供了负载均衡、错误处理等功能,可以与Spring Cloud等微服务框架无缝集成。 2.Dubbo和OpenFeign的区别 协议支持:Dubbo支持多种协议,包括Dubbo协议、HTTP协议、RMI等。OpenFeign主要使用HTTP协议进行通信。使用方式:Dubbo更加底层,需要显式定义接口和实现类,并配置各种参数。OpenFeign则更加注重于声明式的编程模型,通过定义接口和注解来实现远程调用,减少了手动编写具体实现的工作。生态系统:Dubbo是一个独立的RPC框架,它提供了完整的分布式服务治理的解决方案。OpenFeign则是Spring Cloud生态系统中的一部分,与其他Spring Cloud组件(如Eureka、Ribbon、Hystrix等)紧密集成,提供了更全面的微服务开发解决方案。功能特性:Dubbo提供了更多的功能特性,如负载均衡、容错机制、服务注册与发现等,适合于大规模的分布式系统。OpenFeign则更加关注于RESTful风格的接口调用,适用于构建轻量级的微服务。 3.SpringCloud集成Dubbo 添加pom <!--dubbo--> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <version>2.7.15</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-registry-nacos --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-registry-nacos</artifactId> <version>2.7.15</version> </dependency> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-metadata-definition-protobuf</artifactId> <version>2.7.15</version> </dependency> 服务端和消费端配置 dubbo: application: name: vector-member # 与服务名一致即可 logger: slf4j # 元数据中心 local 本地 remote 远程 这里使用远程便于其他服务获取 # 注意 这里不能使用 本地 local 会读取不到元数据 metadataType: remote protocol: # 设置为 tri 即可使用 Triple 3.0 新协议 # 性能对比 dubbo 协议并没有提升 但基于 http2 用于多语言异构等 http 交互场景 # 使用 dubbo 协议通信 name: dubbo # dubbo 协议端口(-1表示自增端口,从20880开始) port: -1 serialization: hessian2 registry: address: nacos://localhost:8848?
1.每个任务最终会进入 RanToCompletion, Canceled, Faulted 三个状态其中之一,任务遇到了什么会情况会进入 Canceled 或 Faulted 状态.
答:(1)任务进入"Canceled"状态的情况通常包括:
1. 显式取消:任务的Cancel方法被调用,或者使用取消令牌进行取消。
2. 超时:任务在规定的时间内未能完成,超过了预定的等待时间。
3. 父任务取消:如果任务是作为另一个任务的子任务运行的,而父任务被取消了,子任务也会被取消。
4. 等待取消:任务在等待某个操作(如等待另一个任务完成或等待资源)时被取消。
(2)任务进入"Faulted"状态的情况通常包括:
1. 未处理异常:任务执行过程中抛出了未被处理的异常,导致任务进入故障状态。
2. 线程中止:任务所在的线程因为某种原因(如操作系统异常、内存溢出等)而中止,导致任务进入故障状态。
3. 内部错误:任务内部发生了错误,导致任务无法正常完成。
需要注意的是,任务的取消和故障状态不一定是由任务本身的代码问题引起的,还可能受到外部因素的影响,
如网络错误、资源不足等。因此,在编写任务时,应该考虑到可能出现的异常情况,并适当处理异常以避免任务进入故障状态.
任务进入Canceled状态是因为任务被取消了。这可以通过调用任务的Cancel方法来实现,或者通过传递一个取消标记给任务的执行方法来取消任务。
任务进入Faulted状态是因为任务执行过程中发生了异常。这可能是由于任务内部抛出了一个异常,或者由于任务的执行方法本身抛出了一个异常。
任务进入"Canceled"状态是在任务被取消时发生的。任务可以被取消,是由于调用了任务的Cancel方法或者是通过取消令牌进行取消。当任务被取消时,
它的状态会从"Running"(运行中)转变为"Canceled"(已取消)。在这种情况下,任务将立即停止执行并进入取消状态。
任务进入"Faulted"状态是在任务发生异常时发生的。当任务执行过程中抛出了异常并未被处理时,任务的状态将从"Running"(运行中)转变为"Faulted"(故障)。
在这种情况下,任务会停止执行并将异常信息传递给任务的调用者。任务的调用者可以通过检查任务的异常属性来获取异常信息。
常见的引发任务进入故障状态的情况包括:未处理异常、线程中止、内存溢出等。
2.简述如何处理 AggregateException 类型的异常
答:AggregateException是一个异常集合,因为Task中可能抛出异常,所以我们需要新的类型来收集异常对象,处理异常时可采用AggregateException.Handle()方法,
为AggregateException中的每个异常都指定一个要执行的表达式,Handle()方法的重要特点在于它是一个断言,针对Handle()委托成功处理的任何异常,断言应返回True,
任何异常处理调用若为一个异常返回False,Handle()方法将返回新的AggregateException,其中包含了由这种异常构成的列表。
本文链接:https://blog.csdn.net/qq_38139402/article/details/110730505http://xn--https-bl8jz2ih7dl86lg05k//blog.csdn.net/qq_38139402/article/details/110730505
AggregateException是一个包装了一个或多个内部异常的异常。当使用多个任务并行执行,并且其中一个或多个任务发生了异常时,就会抛出AggregateException。
处理AagregateException的一种常见方法是使用其InnerExceptions属性来访问内部异常的集合。可以使用foreach循环遍历InnerExceptions属性,对每个内部异常进行处理。
另一种方法是使用AggregateException的Handle方法,该方法接受一个委托,可以对每个内部异常进行处理。
在处理AggregateException时,可以根据具体的需求选择适当的处理方式,例如记录日志、重试任务或向用户显示错误信息。
处理AggregateException类型的异常时,可以按照以下步骤进行:
1. 使用try-catch块捕获AggregateException。
2. 使用InnerExceptions属性获取AggregateException中包含的所有异常。
3. 遍历内部异常,并根据需要处理每个异常。
4. 可以选择重新抛出其中一个内部异常,或将所有内部异常汇总为一个更有意义的异常。
需要注意的是,要根据具体情况处理每个内部异常,并确保记录和处理异常的细节,以便更好地理解和调试代码中的问题。
1.构造一个例子既允许在任务执行前取消任务,又允许在任务执行中取消任务,取消任务后得体的继续操作
//5.构造一个例子既允许在任务执行前取消任务,又允许在任务执行中取消任务,取消任务后得体的继续操作 Console.WriteLine("是否取消任务?Y/N"); string chars = Console.ReadLine(); CancellationTokenSource cts = new CancellationTokenSource(); if (chars.ToUpper() == "
如何把Python文件变成可执行文件 Python是一种高级编程语言,它被广泛应用于各种领域,如数据科学、机器学习、Web开发等。Python是一种解释性语言,这意味着Python代码必须由解释器解释才能运行。如果你想在不安装Python解释器的情况下在其他计算机上执行Python代码,那么你需要将Python文件转换成可执行文件。在本文中,我们将介绍如何将Python文件转换成可执行文件。
什么是可执行文件 在计算机领域中,可执行文件是一种二进制文件,它包含计算机程序的指令。可执行文件是可以直接在操作系统中运行的程序,无需任何其他文件或程序。通常,可执行文件采用不同的格式,如Windows中的.exe文件、Linux中的ELF文件等。
为什么需要把Python文件变成可执行文件 在某些情况下,您可能想要把Python脚本转换成可执行文件。这可能是因为你需要在没有安装Python解释器的机器上运行脚本,或者你需要在其他人处理代码时保护代码。转换Python脚本成可执行文件可以使你可以轻松地将脚本发送给其他人,并使它们对Python的环境没有依赖性。
如何把Python文件编译成可执行文件 Python提供了几种方法来将Python文件转换成可执行文件。下面介绍其中两种方法。
1. 使用PyInstaller PyInstaller是一个跨平台的Python应用程序打包器,它可以将Python应用程序打包成单个可执行文件。它支持多个操作系统,包括Windows、Linux和Mac OS X。PyInstaller可以处理Python脚本和依赖项,并将它们打包成一个单独的可执行文件。
要使用PyInstaller,您需要遵循以下步骤:
安装PyInstaller 您可以在命令行终端上使用以下命令来安装PyInstaller:
pip install pyinstaller 打包你的代码 在命令行终端中导航到存放代码的文件夹,并使用以下命令将代码打包成可执行文件:
pyinstaller yourscript.py 上述命令将生成一个包含可执行文件的dist文件夹。
2. 使用cx_Freeze cx_Freeze是Python的另一个打包器,它可以将Python应用程序打包成可执行文件。它支持多个操作系统,包括Windows、Linux和Mac OS X。
要使用cx_Freeze,您需要遵循以下步骤:
安装cx_Freeze 您可以在命令行终端上使用以下命令来安装cx_Freeze:
pip install cx_Freeze 创建setup文件 创建一个名为setup.py的文件,添加以下代码:
from cx_Freeze import setup, Executable setup( name="yourscript", version="0.1", description="My Script", executables=[Executable("yourscript.py")] ) 在上面的代码中,name是应用程序的名称,version是版本号,description是应用程序的描述,而executable则是应用程序的可执行文件。
打包你的代码 在命令行终端中导航到存放代码的文件夹,并使用以下命令将代码打包成可执行文件:
python setup.py build 上述命令将生成build文件夹,其中包含可执行文件。
结论 将Python文件转换成可执行文件可以使你可以轻松地将脚本发送给其他人,并使它们对Python的环境没有任何依赖性。本文介绍了两种将Python文件转换成可执行文件的方法,即使用PyInstaller和cx_Freeze。这些工具都非常容易使用,并提供了跨平台支持。
最后的最后 本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具
🚀 优质教程分享 🚀 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦! 学习路线指引(点击解锁)知识定位人群定位🧡 AI职场汇报智能办公文案写作效率提升教程 🧡进阶级本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率💛Python量化交易实战 💛入门级手把手带你打造一个易扩展、更安全、效率更高的量化交易系统🧡 Python实战微信订餐小程序 🧡进阶级本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。
前言 今天来教大家如何使用Fiddler抓包工具,获取公众号(PC客户端)的数据。
Fiddler是位于客户端和服务器端的HTTP代理,是目前最常用的http抓包工具之一。
开发环境 python 3.8 运行代码pycharm 2021.2 辅助敲代码requests 第三方模块Fiddler 汉化版 抓包的工具微信PC端0 如何抓包 配置Fiddler环境 先打开Fiddler,选择工具,再选选项
在选项窗口里点击HTTPS,把勾选框都勾选上
在选项窗口里点击链接,把勾选框都勾选上,然后点击确定即可
我们还需要在客户端把网络代理开启
地址:127.0.0.1
端口:888
抓包 先登录,然后清空Fiddler里的数据,在选到你想要的公众号内容
出现数据包后,点开,再选择Raw,里面的就是请求的具体信息
先访问到列表页,获取所有的详情页链接 请求头
headers = { 'Host': 'mp.weixin.qq.com', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090016)', 'X-Requested-With': 'XMLHttpRequest', 'Accept': '*/*', 'Cookie': 'wxuin=2408215323; lang=zh_CN; devicetype=android-29; version=28002037; pass_ticket=f85UL5Wi11mqpsvuWgLUECYkDoL2apJ045mJw9lzhCjUteAxd4jM8PtaJCM0nBXrQEGU9D7ulLGrXpSummoA==; wap_sid2=CJvmqfwIEooBeV9IR29XUTB2eERtakNSbzVvSkhaRHdMak9UMS1MRmg4TGlaMjhjbTkwcks1Q2E2bWZ1cndhUmdITUZUZ0pwU2VJcU51ZWRDLWpZbml2VkF5WkhaU0NNaDQyQ1RDVS1GZ05mellFR0R5UVY2X215bXZhUUV0NVlJMVRPbXFfZGQ1ZnVvMFNBQUF+MPz0/50GOA1AlU4=', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=Mzg3Nzc2OTQzOA==&uin=MjQwODIxNTMyMw%3D%3D&key=2ed1dc903dceac3d9a380beec8d46a84995a555d7c7eb7b793a3cc4c0d32bc588e1b6df9da9fa1a258cb0db4251dd36eda6029ad4831c4d57f6033928bb9c64c12b8e759cf0649f65e4ef30753ff3092a2a4146a008df311c110d0b6f867ab173792368baa9aaf28a514230946431480cc6b171071a9f9a1cd52f7c07a751925&devicetype=Windows+10+x64&version=63090016&lang=zh_CN&a8scene=7&session_us=gh_676b5a39fe6e&acctmode=0&pass_ticket=f85UL5Wi11%2BmqpsvuW%2BgLUECYkDoL2apJ045mJw9lzhCjUteAxd4jM8PtaJCM0nBXrQEGU9D7ulLGrXpSummoA%3D%3D&wx_header=1&fontgear=2', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.
文章目录
前言
一、Toast是什么?
二、使用步骤
一、Toast是什么? Toast是Android中用于在屏幕上显示简短的提示消息的一种方式。
二、使用步骤 下面是使用Toast的详细步骤:
导入Toast类: 在Java文件中,首先需要导入android.widget.Toast类,可以在文件的开头
import android.widget.Toast; 创建Toast对象: 使用Toast.makeText()方法创建一个Toast对象,并设置要显示的文本内容和显示时长。
Toast toast = Toast.makeText(context, "Hello, Toast!", Toast.LENGTH_SHORT); //context:上下文对象,一般为当前Activity或Application的实例。 //"Hello, Toast!":要显示的文本内容。 //Toast.LENGTH_SHORT:Toast的显示时长,可以选择Toast.LENGTH_SHORT(短时)或Toast.LENGTH_LONG(长时)。 设置Toast的位置(可选): 可以使用setGravity()方法设置Toast显示的位置。默认情况下,Toast会显示在屏幕底部居中位置。
toast.setGravity(Gravity.TOP|Gravity.START, xOffset, yOffset); Gravity.TOP|Gravity.START:Toast显示的位置,这里表示在屏幕顶部的起始位置。xOffset和yOffset:显示位置的偏移量,可以根据需要进行调整。 显示Toast: 调用toast.show()方法来显示Toast。
toast.show(); 注意:在调用show()之前,确保已设置好要显示的文本和其他属性。
完整示例:
import android.widget.Toast; public class MainActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); // 创建Toast对象 Toast toast = Toast.makeText(getApplicationContext(), "Hello, Toast!", Toast.LENGTH_SHORT); // 设置Toast的位置(可选) toast.setGravity(Gravity.TOP | Gravity.START, xOffset, yOffset); // 显示Toast toast.
BACnet标准是针对采暖、通风、空调、制冷控制设备设计的,同时也是为其他楼宇控制系统(例如照明,安保,消防等系统)的集成提供一个基本原则。
本文主要讲述了BACnet网关采集Modbus RTU设备(M140T),将Modbus RTU协议转为BACnet IP协议的操作步骤:
首先将将BL103的RS485跟M140T的RS485对接上
打开BL103的配置软件 COM通过Modbus RTU采集M140T的数据,COM口配置如下:
(1)双击“COM1”,弹出COM属性配置框。(2)模式选择:采集。(3)因通过RS485 COM口采集M140T设备,使用Modbus RTU协议,设备品牌:Modbus,设备型号:Modbus RTU。按钮里面,轮询周期和通讯超时设置默认,根据需求设置。(4)波特率、停止位、数据位、校验根据M140T RS485口的参数进行配置,与其保持一致。(5)点击“确定”。
注:点击“写入配置”网关设备将自动重启,重启后COM口的配置才会生效。
添加COM口设备M140 (1)点击“COM1”,点击鼠标右键,点击“添加”,弹出设备配置框。(2)设备名称任意填写,如:填写M140T。(3)从站ID根据采集设备的Modbus ID填写,如:M140T的Modbus ID是“1”,因此,填写“1”。(4)根据要采集的数据选择数据类型,示例是采集M140T的DI和DO,都是布尔类型没有采集数值类型的寄存器,故默认即可。(5)写功能码:默认,M140T支持写多个寄存器。(6)点击“确定”,添加M140T设备。
注:点击确定后会在COM1下显示添加的设备见上图显示出来M140T,如果想添加多个设备,重复(1)--(6)步骤即可。
注:点击“写入配置”网关设备将自动重启,重启后添加COM口的M140T设备才添加成功。
添加M140T的数据点 (1)点击“M140T”,鼠标光标移动到方框内,鼠标右键,点击“添加”弹出数据点设置框。(2)变量名称:命名数据点的名字,如:DO1。(3)数据点的MQTT标识符,可以任意填写。标识符不能重复,如:DO1数据点的MQTT标识填写为DO1。(4)根据需求选择采集地址按什么数据格式填写输入网关,OCT/DEC/HEX分别是八进制/十进制/十六进制。采集Modbus协议地址按十进制输入,故示例选择十进制。(5)地址类型:根据采集的数据点支持的功能码选择,如采集M140T的DO是支持“01”功能码,故选择“01 Coil Status”,DI是支持“02”功能码,故选择“02 Input Status”。(6)地址:采集数据点的寄存器地址,如:数据点DO1在M140T里面是“0”寄存器地址,故填写“0”。(7)数据类型:根据数据点选择,如:M140T的DI和DO都是线圈类型故选择“bool”。(8)添加数量:如果是采集连续地址,同一功能码可以多个采集。(9)读写类型:根据“地址类型”的选项选择自动识别。(10)映射地址:填写采集到的数据点存储到BL103网关设备的地址,可以随意填写。映射地址不能重复。范围:0-2000。如:采集DO1的数据存储到BL103网关“0”寄存器地址。配置软件上映射地址外面表示Modbus地址,括号里面M.XXX表示PLC Modbus地址。(11)变量单位:根据需求任意填写。(12)点击“确定”。
BL103网关作为BACnet/IP服务器对外提供数据。因为各种协议的数据属性不同,统一以AV和BV两种对象属性为当前值对外提供数据。对象实例是配置软件上数据点页面映射地址项的Modbus地址。
BACnet/IP的配置
功能
说明
启用
是否启用BACnet/IP,默认关闭,点击按钮启用。灰色表示:不启用,绿色表示:启用。
网口选择
从“WAN”、“LAN”中选择。
端口
填写服务器端口,端口必须要填写。默认:47808。
生产商名称
默认“BeiLai”,可任意填写。
生产商ID
默认“555”,可任意填写。
设备名称
默认“BeiLai Gateway”,可任意填写。
设备ID
默认“555”,设备对象实例,如果下行也采有BACnet设备,注意不能冲突。
设备描述
默认“BACnet Server”,可任意填写。
位置
默认“CN”,可任意填写。
确定
确定BACnet/IP的配置
取消
取消BACnet/IP的配置
至此采集Modbus转BACnet协议操作结束
大家好!我是程序员一矾,感谢您阅读本文,欢迎一键三连哦。
python195框架的课堂投票系统演示
🎀 当前专栏:基于Python的毕业设计
精彩专栏推荐👇🏻👇🏻👇🏻
💞微信小程序毕业设计
🎀 安卓app毕业设计
🌎Java毕业设计
源码及文档下载地址: https://download.csdn.net/download/m0_46388260/87961474
目录 源码及文档下载地址:一、项目简介二、系统设计2.1软件功能模块设计2.2数据库设计 三、系统项目部分截图3.1学生角色功能实现注册登录界面3.2个人中心3.3投票列表3.4 我的投票投票分析 管理员角色功实现账号管理信息管理发布投票投票列表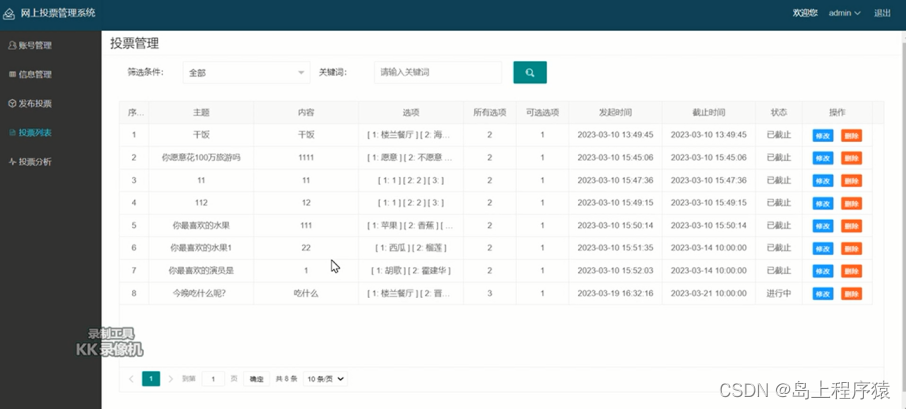### 投票分析 四、论文目录五、部分核心代码 一、项目简介 本文介绍了一款基于Django框架开发的课堂投票系统,该系统能够为老师提供一个简单易用的平台来发布投票主题,并允许学生使用电脑参与投票。通过使用系统,老师可以更好地了解学生的认知,及时调整课程内容和教学方法。而对于学生而言,该系统提供了一个互动式的课堂环境,增强了他们的学习兴趣和参与性。此外,该系统还支持对投票结果进行实时的统计和分析,从而为学生和老师提供更多的参考意见。
该课堂投票系统还采用了Python编程语言和MySQL数据库技术,Python语言优秀的代码可读性和高效的开发速度,使得系统的开发更加快捷、便捷。而使用MySQL数据库技术,使系统得以实现数据的高效查询和存储,保证了系统的数据安全性和稳定性。通过集成这些技术,该系统具备了更加优越的性能和更加完善的功能,实现了教师与学生之间的快速互动和信息交流,为教育教学工作提供了更加全面的支持和服务。
二、系统设计 2.1软件功能模块设计 系统模块设计是指在软件开发中,针对系统中不同的功能需求,将不同的模块进行划分和设计的过程。它主要包括对不同功能模块的设计、实现、测试以及维护等环节。在整个软件开发过程中,模块设计是非常重要的一环,合理的模块设计可以提高软件开发效率,降低软件开发的复杂度,保证软件质量和稳定性。根据前期所做需求分析结果,本次系统主要功能模块设计如下:
(1)系统管理员(教师)模块
账号管理:管理员可以在此模块中,对系统内完成注册的管理员或用户角色,进行修改或删除操作。
信息管理:管理员在信息管理模块,可以查看注册用户的个人信息,并对信息进行校对,不符合要求的可直接进行删除操作。
发布投票:管理员可输入投票的主题、内容等详细信息,编辑选项文本,输入完成后即可发布投票。
投票列表:管理员可在此处查看历史投票发布记录,选择任意投票主题进行修改或删除操作。
投票统计:管理员可在投票分析模块,查看不同投票主题的票数分析结果,包括不限于投票男女比例、区域分布等。
另外,由于Django框架的课题投票系统中的管理员角色具有较高的权限和责任,需要特别关注系统的安全性和稳定性,充分利用框架提供的各类安全特性,防止系统受到恶意攻击。同时,需要考虑管理员主观因素和人为失误等问题,设置各种操作记录和日志记录,以便对系统操作情况进行监控和追踪,防止误操作造成的损失。
(2)学生用户模块
个人中心:在个人中心模块,用户可进一步完善个人信息、重置系统密码。
投票列表:学生可在投票列表模块中,浏览系统发布的历史投票记录,并可参与正在进行的投票主题。
我的投票:学生可在我的投票模块中,查询本人已参加过的投票信息,并可查看对应投票主题详情。
投票设计:学生可在投票分析模块,查看不同投票主题的票数分析结果,包括不限于投票男女比例、区域分布等。
2.2数据库设计 三、系统项目部分截图 3.1学生角色功能实现 注册登录界面 此处输入账号并设置登录密码,填写用户名、性别、生源地等相关信息即可完成注册登录。
3.2个人中心 在个人中心模块,用户可进一步完善个人信息、重置系统密码。如图4.1.2:
3.3投票列表 学生可在投票列表模块中,浏览系统发布的历史投票记录,并可参与正在进行的投票主题,模块上方的搜索框可供用户直接针对关键字进行搜索。
3.4 我的投票 学生可在我的投票模块中,查询本人已参加过的投票信息,并可查看对应投票主题详情,同样支持关键字搜索。
投票分析 学生可在投票分析模块,查看不同投票主题的票数分析结果,包括不限于投票男女比例、区域分布等。
管理员角色功实现 账号管理 管理员可以在此模块中,对系统内完成注册的管理员或用户角色,进行修改或删除操作。
信息管理 管理员在信息管理模块,可以查看注册用户的个人信息,并对信息进行校对,不符合要求的可直接进行删除操作。
发布投票 投票列表### 投票分析 管理员可在投票分析模块,查看不同投票主题的票数分析结果,包括不限于投票男女比例、区域分布等。
四、论文目录 摘 要 2
Abstract 3
基于Django框架的课题投票系统的设计与实现 3
第1章 引言 3
今天给大家分享的又是一篇实战文章,也是最近私活里遇到的,万能的互联网给了我办法,分享一下。
背景 最近接到一个新的需求,需要上传2G左右的视频文件,用测试环境的OSS试了一下,上传需要十几分钟,再考虑到公司的资源问题,果断放弃该方案。
一提到大文件上传,我最先想到的就是各种网盘了,现在大家都喜欢将自己收藏的**「小电影」**上传到网盘进行保存。网盘一般都支持断点续传和文件秒传功能,减少了网络波动和网络带宽对文件的限制,大大提高了用户体验,让人爱不释手。
说到这,大家先来了解一下这几个概念:
「文件分块」:将大文件拆分成小文件,将小文件上传\下载,最后再将小文件组装成大文件;「断点续传」:在文件分块的基础上,将每个小文件采用单独的线程进行上传\下载,如果碰到网络故障,可以从已经上传\下载的部分开始继续上传\下载未完成的部分,而没有必要从头开始上传\下载;「文件秒传」:资源服务器中已经存在该文件,其他人上传时直接返回该文件的URI。 RandomAccessFile 平时我们都会使用FileInputStream,FileOutputStream,FileReader以及FileWriter等IO流来读取文件,今天我们来了解一下RandomAccessFile。
它是一个直接继承Object的独立的类,底层实现中它实现的是DataInput和DataOutput接口。该类支持随机读取文件,随机访问文件类似于文件系统中存储的大字节数组。
它的实现基于**「文件指针」**(一种游标或者指向隐含数组的索引),文件指针可以通过getFilePointer方法读取,也可以通过seek方法设置。
输入时从文件指针开始读取字节,并使文件指针超过读取的字节,如果写入超过隐含数组当前结尾的输出操作会导致扩展数组。该类有四种模式可供选择:
r: 以只读方式打开文件,如果执行写入操作会抛出IOException;rw: 以读、写方式打开文件,如果文件不存在,则尝试创建文件;rws: 以读、写方式打开文件,要求对文件内容或元数据的每次更新都同步写入底层存储设备;rwd: 以读、写方式打开文件,要求对文件内容的每次更新都同步写入底层存储设备; 在rw模式下,默认是使用buffer的,只有cache满的或者使用RandomAccessFile.close()关闭流的时候才真正的写到文件。
API 1、void seek(long pos):设置下一次读取或写入时的文件指针偏移量,通俗点说就是指定下次读文件数据的位置。
偏移量可以设置在文件末尾之外,只有在偏移量设置超出文件末尾后,才能通过写入更改文件长度;
2、native long getFilePointer():返回当前文件的光标位置;
3、native long length():返回当前文件的长度;
4、「写」方法
5、readFully(byte[] b):这个方法的作用就是将文本中的内容填满这个缓冲区b。如果缓冲b不能被填满,那么读取流的过程将被阻塞,如果发现是流的结尾,那么会抛出异常;
6、FileChannel getChannel():返回与此文件关联的唯一FileChannel对象;
7、int skipBytes(int n):试图跳过n个字节的输入,丢弃跳过的字节;
8、RandomAccessFile的绝大多数功能,已经被JDK1.4的NIO的**「内存映射」**文件取代了,即把文件映射到内存后再操作,省去了频繁磁盘io。
实操 文件分块 文件分块需要在前端进行处理,可以利用强大的js库或者现成的组件进行分块处理。需要确定分块的大小和分块的数量,然后为每一个分块指定一个索引值。
为了防止上传文件的分块与其它文件混淆,采用文件的md5值来进行区分,该值也可以用来校验服务器上是否存在该文件以及文件的上传状态。
如果文件存在,直接返回文件地址;如果文件不存在,但是有上传状态,即部分分块上传成功,则返回未上传的分块索引数组;如果文件不存在,且上传状态为空,则所有分块均需要上传。 fileRederInstance.readAsBinaryString(file); fileRederInstance.addEventListener("load", (e) => { let fileBolb = e.target.result; fileMD5 = md5(fileBolb); const formData = new FormData(); formData.append("md5", fileMD5); axios .post(http + "/fileUpload/checkFileMd5", formData) .then((res) => { if (res.
多协议转换网关是一种重要的设备,它可以实现不同协议之间的互联互通。在工业自动化领域,常常会遇到不同厂家的设备使用不同的通信协议,这给系统集成和数据交互带来了一定的挑战。多协议转换网关的出现,解决了这个问题,使得设备之间可以方便地进行数据交换和共享。
多协议转换网关支持各种常见的协议,如PLC协议、Modbus RTU Master、Modbus TCP Master、DL/T645、IEC101、IEC104、BACnet IP、BACnet MS/TP等。这些协议涵盖了工业自动化领域中常见的通信协议,能够满足不同设备之间的通信需求。
在下行方向,多协议转换网关支持将不同协议的数据转换为统一的协议进行传输。例如,可以将Modbus RTU Master协议的数据转换为MQTT协议进行传输。这样,不同协议的设备就可以通过多协议转换网关进行数据交互,实现设备之间的互联互通。
在上行方向,多协议转换网关支持将统一的协议的数据转换为不同的协议进行传输。例如,可以将Modbus TCP协议的数据转换为华为云IoT、阿里云IoT、AWS IoT等协议进行传输。这样,设备的数据可以方便地上传到云平台,实现远程监控和管理。
多协议转换网关的出现,极大地简化了设备之间的通信和数据交互。它不仅提高了系统集成的效率,还为工业自动化系统的远程监控和管理提供了便利。多协议转换网关的应用范围广泛,可以在工业控制系统、楼宇自动化系统、能源管理系统等领域发挥重要作用。
总之,多协议转换网关是一种重要的设备,它通过支持多种通信协议,实现了不同设备之间的互联互通。它在工业自动化领域具有广泛的应用前景,将为工业控制系统的集成和远程管理带来更多便利。
HttpClient的主要特点 支持同步和异步请求:HttpClient可以发送同步和异步的HTTP请求。同步请求会阻塞当前线程,直到收到响应或发生超时。异步请求则不会阻塞线程,可以通过回调函数或Future对象来处理响应。连接管理:HttpClient可以自动管理HTTP连接的生命周期,包括连接的建立、重用和释放。它支持连接池,可以重用已经建立的连接,减少连接的建立和关闭的开销。请求和响应拦截器:HttpClient提供了拦截器机制,可以在发送请求和处理响应的过程中进行自定义操作。拦截器可以用于添加认证信息、修改请求头、处理响应等。支持HTTPS:HttpClient可以与使用SSL/TLS协议保护的HTTPS服务器进行通信。它支持证书验证、主机名验证和安全协议的选择。支持代理:HttpClient可以通过代理服务器发送请求,支持HTTP和SOCKS代理。支持重定向:HttpClient可以自动处理HTTP重定向,包括301和302状态码的重定向。支持Cookie管理:HttpClient可以自动处理HTTP Cookie,包括发送和接收Cookie,以及保存和管理Cookie。支持连接超时和读取超时设置:HttpClient可以设置连接超时和读取超时,以防止请求长时间无响应。 需要手动关闭吗 Java 11(8需要手动)的HttpClient中,不需要手动关闭HttpClient。HttpClient内部使用的是非阻塞的IO,不持有任何需要显式关闭的资源,比如Socket或者文件句柄。这是一个很大的改进,因为它意味着你不再需要在finally块中关闭资源,这样可以使代码更简洁,更易于阅读和维护。
性能问题 **HttpClient的实例是重量级的对象,它的创建和配置都需要消耗一定的系统资源。一般来说,为了提高效率,应该尽可能重用HttpClient实例,而不是为每个请求都新建一个。尤其是在处理大量请求的情况下,重用HttpClient**实例可以显著提高性能。
线程问题 HttpClient实例可以被多个线程共享,但HttpRequest和HttpResponse实例是不可变的,且不应被多个线程共享。所以每个请求要创建新的HttpRequest和HttpResponse实例。
代码实现: 使用HttpClient发送GET请求的示例代码 import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.HttpClientBuilder; import org.apache.http.HttpResponse; import org.apache.http.util.EntityUtils; public class HttpClientExample { public static void main(String[] args) { HttpClient httpClient = HttpClientBuilder.create().build(); HttpGet httpGet = new HttpGet("https://api.example.com/data"); try { HttpResponse response = httpClient.execute(httpGet); String responseBody = EntityUtils.toString(response.getEntity()); System.out.println("Response Code: " + response.getStatusLine().getStatusCode()); System.out.println("Response Body: " + responseBody); } catch (Exception e) { e.printStackTrace(); } } } 使用HttpClient设置重定向请求的示例代码 import java.
CopyOnWriteArrayList 适合写多读少
介绍 JUC包中的并发List只有CopyOnWriteArrayList。CopyOnWriteArrayList是一个线程安全的ArrayList,使用了写时复制策略,对其进行的修改操作都是在底层的一个复制的数组上进行的。
CopyOnWriteList 实现的接口和 ArrayList 完全相同,所以 ArrayList 提供的 api ,CopyOnWriteArrayList 也提供
其实说白了就是每次要增、删、改的时候,会创建一个新的 array,并把旧的 array 全部复制过来,操作完后再让 array 指向这个新创建的 array,所以也不存在什么扩容问题,因为每次 add 都要扩容
CopyOnWriteArrayList类图中
每个CopyOnWriteArrayList对象有一个array数组存放具体元素ReentrantLock独占锁用来保证只有一个线程对array进行修改。 属性 /** The lock protecting all mutators */ final transient ReentrantLock lock = new ReentrantLock(); /** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array; // 存放具体元素 final void setArray(Object[] a) { array = a; } final Object[] getArray() { return array; } 构造函数 CopyOnWriteArrayList 内部包含一个array存放具体元素:
CountDownLatch 日常开发中经常遇到一个线程需要等待一些线程都结束后才能继续向下运行的场景,在CountDownLatch出现之前通常使用join方法来实现,但join方法不够灵活,所以开发了CountDownLatch。场景:一个等其他多个线程,或者多个等其他多个的场景
CountDownLatch比join方法来实现线程同步更加灵活。
CountDownLatch是使用AQS实现的,使用AQS的状态变量存放计数器的值。
初始化CountDownLatch时设置状态值(计数器的值)多个线程调用countdown方法是原子性递减AQS状态值当线程调用await方法后线程会被放入AQS的阻塞队列等待计数器为0再返回,其他线程调用countdown方法让计数器值-1,当计数器值变为0时,当前线程要调用doReleaseShared方法激活由于await()方法而被阻塞的线程。 示例
// 创建一个CountDownLatch实例 CountDownLatch countDownLatch = new CountDownLatch(2);//两个子线程 所以new2 public static void main(String[] args) throws InterruptedException { // 线程池去操作线程 ExecutorService executorService = Executors.newFixedThreadPool(2); // 将线程池A添加到线程池 executorService.submit(new Runnable() { @Override public void run() { try { // 模拟运行时间 Thread.sleep(1000); System.out.println("thread one over..."); } catch (InterruptedException e) { e.printStackTrace(); }finally { // 递减计数器 countDownLatch.countDown(); } } }); // 将线程池b添加到线程池 executorService.submit(new Runnable() { @Override public void run() { try { Thread.
目录 1.非类型模板参数2.模板的特化2.1概念2.2 函数模板特化2.3 类模板特化2.3.1 全特化2.3.2 偏特化2.3.3 应用 3.模板分离编译4.模板总结 1.非类型模板参数 模板参数可分为类型形参和非类型形参
类型形参:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
C++中的array就是利用非类型模板参数来实现的,类似于C语言中的静态数组。array会对越界访问进行检查,比静态数组更严格。
template<class T, size_t N = 10> class Array { public: T& operator[](size_t index) { return _array[index]; } const T& operator[](size_t index)const { return _array[index]; } size_t size()const { return _size; } bool empty()const { return 0 == _size; } private: T _array[N]; size_t _size; }; 2.模板的特化 2.1概念 通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板。
template<class T> bool Less(T left, T right) { return left < right; } int main() { cout << Less(1, 2) << endl; // 可以比较,结果正确 Date d1(2022, 7, 7); Date d2(2022, 7, 8); cout << Less(d1, d2) << endl; // 可以比较,结果正确 Date* p1 = &d1; Date* p2 = &d2; cout << Less(p1, p2) << endl; // 可以比较,结果错误 return 0; } 可以看到,Less绝对多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指
JUC包中有AtomicInteger、AtomicLong和AtomicBoolean等原子性操作类,它们原理类似,下面以AtomicLong为例进行讲解。
AtomicLong 底层的操作自增自减都用Unsafe类中的getAndAddLong方法(获取本类内存偏移值)实现的,getAndAddLong底层用Unsafe类中的CAS方法,大量线程竞争只有一个线程成功,会导致大量的自旋尝试。
public class AtomicLong extends Number implements java.io.Serializable { private static final long serialVersionUID = 1927816293512124184L; // 获取Unsafe实例:AtomicLong类是通过BootStarp类加载器加载的所以可以拿到Unsafe类的实例 private static final Unsafe unsafe = Unsafe.getUnsafe(); // 存放变量value的偏移量 private static final long valueOffset; // 判断JVM是否支持Long类型的无锁CAS static final boolean VM_SUPPORTS_LONG_CAS = VMSupportsCS8(); private static native boolean VMSupportsCS8(); static { try { // 获取value在AtomicLong类中的偏移量 valueOffset = unsafe.objectFieldOffset (AtomicLong.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } } // 实际变量值 volatile是为了多线程下保证内存的可见性 private volatile long value; public AtomicLong(long initialValue) { value = initialValue; } .