01-09 16:20:00.336 9281-9281/com.moreunion.zhenghao E/AndroidRuntime: FATAL EXCEPTION: main Process: com.moreunion.zhenghao, PID: 9281 java.lang.IllegalArgumentException: reportSizeConfigurations: ActivityRecord not found for: Token{1883f1c null} at android.os.Parcel.readException(Parcel.java:1946) at android.os.Parcel.readException(Parcel.java:1888) at android.app.IActivityManager$Stub$Proxy.reportSizeConfigurations(IActivityManager.java:9299) at android.app.ActivityThread.reportSizeConfigurations(ActivityThread.java:2953) at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:2896) at android.app.ActivityThread.handleRelaunchActivity(ActivityThread.java:4754) at android.app.ActivityThread.-wrap18(Unknown Source:0) at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1599) at android.os.Handler.dispatchMessage(Handler.java:105) at android.os.Looper.loop(Looper.java:164) at android.app.ActivityThread.main(ActivityThread.java:6541) at java.lang.reflect.Method.invoke(Native Method) at com.android.internal.os.Zygote$MethodAndArgsCaller.run(Zygote.java:240) at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:767)
JSTL1.1函数标签库(functions)与 JSTL 自定义Function函数标签 学习要点 JSTL1.1函数标签库(functions) JSTL 自定义Function函数标签 JSTL1.1函数标签库(functions) 在jstl中的fn标签也是我们在网页设计中经常要用到的很关键的标签,在使用的时候要先加上头 <%@ taglib uri="http://java.sun.com/jsp/jstl/functions" prefix="fn"%>就可以使用fn标签了。 具体使用方法请参见下表:
函数描述fn:contains(string, substring)如果参数string中包含参数substring,返回truefn:containsIgnoreCase(string, substring)如果参数string中包含参数substring(忽略大小写),返回truefn:endsWith(string, suffix)如果参数 string 以参数suffix结尾,返回truefn:escapeXml(string)将有特殊意义的XML (和HTML)转换为对应的XML character entity code,并返回fn:indexOf(string, substring)返回参数substring在参数string中第一次出现的位置fn:join(array, separator)将一个给定的数组array用给定的间隔符separator串在一起,组成一个新的字符串并返回。fn:length(item)返回参数item中包含元素的数量。参数Item类型是数组、collection或者String。如果是String类型,返回值是String中的字符数。fn:replace(string, before, after)返回一个String对象。用参数after字符串替换参数string中所有出现参数before字符串的地方,并返回替换后的结果fn:split(string, separator)返回一个数组,以参数separator 为分割符分割参数string,分割后的每一部分就是数组的一个元素fn:startsWith(string, prefix)如果参数string以参数prefix开头,返回truefn:substring(string, begin, end)返回参数string部分字符串, 从参数begin开始到参数end位置,包括end位置的字符fn:substringAfter(string, substring)返回参数substring在参数string中后面的那一部分字符串fn:substringBefore(string, substring)返回参数substring在参数string中前面的那一部分字符串fn:toLowerCase(string)将参数string所有的字符变为小写,并将其返回fn:toUpperCase(string)将参数string所有的字符变为大写,并将其返回fn:trim(string)去除参数string 首尾的空格,并将其返回 JSTL 自定义Function函数标签 <function>标签可以做什么呢?它可以让我们在jsp用直接调用某个方法,根据自定义的方法返回指定的值,兼容jstl标签, 省去了在jsp中直接使用<%!%>来定义方法体再调用的繁琐.如果你用过el语言的话估计会很快上手,其实<function>标签就是一个拥有方法体的el语言.注意:function所定义的方法必须需要是静态的,如果不是静态的话jstl 是不能识别所定义的方法. java代码如下:
package org.lxh.taglib; import java.util.List; public class FunctionTag { public static String hello(String name) { return name; } public static Integer bbq(List list) { return list.size(); } } 方法必须静态,可以定义有返回值或者void类型的方法.
引用来自:http://www.cnblogs.com/tylerdonet/p/3520862.html
jquery中的ajax方法参数总是记不住,这里记录一下。
1.url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址。
2.type: 要求为String类型的参数,请求方式(post或get)默认为get。注意其他http请求方法,例如put和delete也可以使用,但仅部分浏览器支持。
3.timeout: 要求为Number类型的参数,设置请求超时时间(毫秒)。此设置将覆盖$.ajaxSetup()方法的全局设置。
4.async: 要求为Boolean类型的参数,默认设置为true,所有请求均为异步请求。如果需要发送同步请求,请将此选项设置为false。注意,同步请求将锁住浏览器,用户其他操作必须等待请求完成才可以执行。
5.cache: 要求为Boolean类型的参数,默认为true(当dataType为script时,默认为false),设置为false将不会从浏览器缓存中加载请求信息。
6.data: 要求为Object或String类型的参数,发送到服务器的数据。如果已经不是字符串,将自动转换为字符串格式。get请求中将附加在url后。防止这种自动转换,可以查看 processData选项。对象必须为key/value格式,例如{foo1:"bar1",foo2:"bar2"}转换为&foo1=bar1&foo2=bar2。如果是数组,JQuery将自动为不同值对应同一个名称。例如{foo:["bar1","bar2"]}转换为&foo=bar1&foo=bar2。
7.dataType: 要求为String类型的参数,预期服务器返回的数据类型。如果不指定,JQuery将自动根据http包mime信息返回responseXML或responseText,并作为回调函数参数传递。可用的类型如下: xml:返回XML文档,可用JQuery处理。 html:返回纯文本HTML信息;包含的script标签会在插入DOM时执行。 script:返回纯文本JavaScript代码。不会自动缓存结果。除非设置了cache参数。注意在远程请求时(不在同一个域下),所有post请求都将转为get请求。 json:返回JSON数据。 jsonp:JSONP格式。使用SONP形式调用函数时,例如myurl?callback=?,JQuery将自动替换后一个“?”为正确的函数名,以执行回调函数。 text:返回纯文本字符串。
8.beforeSend: 要求为Function类型的参数,发送请求前可以修改XMLHttpRequest对象的函数,例如添加自定义HTTP头。在beforeSend中如果返回false可以取消本次ajax请求。XMLHttpRequest对象是惟一的参数。 function(XMLHttpRequest){ this; //调用本次ajax请求时传递的options参数 } 9.complete: 要求为Function类型的参数,请求完成后调用的回调函数(请求成功或失败时均调用)。参数:XMLHttpRequest对象和一个描述成功请求类型的字符串。 function(XMLHttpRequest, textStatus){ this; //调用本次ajax请求时传递的options参数 }
10.success:要求为Function类型的参数,请求成功后调用的回调函数,有两个参数。 (1)由服务器返回,并根据dataType参数进行处理后的数据。 (2)描述状态的字符串。 function(data, textStatus){ //data可能是xmlDoc、jsonObj、html、text等等 this; //调用本次ajax请求时传递的options参数 }
11.error: 要求为Function类型的参数,请求失败时被调用的函数。该函数有3个参数,即XMLHttpRequest对象、错误信息、捕获的错误对象(可选)。ajax事件函数如下: function(XMLHttpRequest, textStatus, errorThrown){ //通常情况下textStatus和errorThrown只有其中一个包含信息 this; //调用本次ajax请求时传递的options参数 }
12.contentType: 要求为String类型的参数,当发送信息至服务器时,内容编码类型默认为"application/x-www-form-urlencoded"。该默认值适合大多数应用场合。
13.dataFilter: 要求为Function类型的参数,给Ajax返回的原始数据进行预处理的函数。提供data和type两个参数。data是Ajax返回的原始数据,type是调用jQuery.ajax时提供的dataType参数。函数返回的值将由jQuery进一步处理。 function(data, type){ //返回处理后的数据 return data; }
14.dataFilter: 要求为Function类型的参数,给Ajax返回的原始数据进行预处理的函数。提供data和type两个参数。data是Ajax返回的原始数据,type是调用jQuery.ajax时提供的dataType参数。函数返回的值将由jQuery进一步处理。 function(data, type){ //返回处理后的数据 return data; }
当前系统版本 10.13.2
最近mac版本升级后,安装MySQL-python一直失败 pip install mysql 会提示这个错误 上网找了很久,也尝试了很多次,没发现合适的答案,最后尝试到自己的xcode版本过低,于是从app store升级xcode,试玩之后还是这个错误。
ld: library not found for -lssl clang: error: linker command failed with exit code 1 (use -v to see invocation) error: command 'cc' failed with exit status 1 执行下面代码 安装 xcode select xcode-select --install 然后尝试安装 发现错误变化 ,用root权限安装 sudo pip install mysql 安装成功 网上的其他解决方案
安装mysql connect
brew install mysql-connector-c pip install mysql windows版本下载最新版本的mysql-python安装,在mac上尝试过后不行。
解决办法到下面地址下载新版本的MySQL-python-1.x.xwin-amd64-py2.7.exe:
智能手表连接电脑及adb测试,搞开发用,以huawei watch 2 为例: 1.usb连接手表与电脑
2.电脑端安装adb驱动
3.手表端打开开发者模式(点击版本号7次以上),打开adb调试
4.电脑端安装adb工具
5.cmd进入adb工具目录(cd d:\adb或d:-cd adb)进行测试
(1)查看连接是否正常 (adb devices),如连接正常会初恋会一长串序列号
(2)安装软件:
1)将要装的apk文件放在adb工具目录下 2)adb install 文件名称.apk,提示Success即成功。
(3)卸载软件:
1)查看包名 adb shell pm list packages,注意package:后面的才是应用包名称。
2)adb uninstall 包名,提示Success即成功。
或通过手机助手等软件连接后进行卸载
注意不同签名的同一个软件需要先卸载才能安装,无法直接覆盖安装。
概述 l 每一个接口文件对应一个.hal文件
l 保护接口文件不被轻易修改。如果修改,编译就会报错,同时会生成一个修改后hashing值
l 确保接口变化得到充分审查
布局 每一个包根目录下都有一个current.txt文件。例如android.hardware对应hardware/interfaces。
这个文件包含了发布的所有接口文件即.hal文件以及对应的hashing值。
Hashing产生 1. 手动添加hash到current.txt
.hal文件修改后,编译会报错同时生成修改后的hash值,可以手动添加到current.txt。
2. hidl-gen 注意:不要替换前一个已发布的接口hash值。如果修改的化,只需要在current.txt文件的末尾追加即可。
每一个接口都可以通过调用IBase::getHashChain 获取对应的hash。
hidl-gen在编译接口时,会在其对应的根目目录下检查current.txt
l 没有找到,接口不发布,编译跳过
l Hash不匹配,编译终止,修改current.txt
1. 对于ABI允许的修改,可以修改current.txt。
2. ABI不允许的修改,需要在接口的次版本号或主版本号更新中修改。
ABI stability ABI: Application Binary Interface 。包含了二级制链接、函数调用约定等。如果ABI/API变化,那基于标准接口编译的system.img,可能无法使用该接口功能。
接口版本化和ABI 稳定性是必要的:
l 通过VTS
l System 独立 OTA
l 作为OEM,提供一个容易使用和兼任的BSP版本
l 通过current.txt可以了解接口的发布历史记录
当在current.txt为一个存在的接口添加一个新的hash时,为了确保ABI stability,需要审查下面的修改类型:
对于已发布的接口,ABIstability列出了哪些修改允许哪些不允许,对于不允许的修改只能在接口的次版本号或主版本号更新中修改。
很多人都会遇到这个问题!一般情况先这个问题你百度就会有一大堆的答案,也许你运气好很快就能解决!虽然我这里讲述的可能会跟网上的部分教程有一样,因为我也是从他们那总结出来的!但是我这里是把大家可能遇到的情况都说清楚,包括网上没有答案的情况!下面都是我被坑了一天总结出来的!希望看到的朋友少踩坑!如果你遇到其它的奇葩问题,欢迎给我留言或者联系我个人QQ,因为很多坑我都踩过,希望能帮到你!
【新版解决方案】:一句命令解决 npm i node-sass --sass_binary_site=https://npm.taobao.org/mirrors/node-sass/
【旧版解决方案如下】:
①:例如很多人第一步就会这样做:
出现:Cannot download "https://github.com/sass/node-sass/releases/download/版本号/XXX_binding.nod情况,很多人第一反应就是下面的原因
原因是node-sass被墙掉了,那我们用淘宝镜像cnpm安装:
npm install -g cnpm --registry=https://registry.npm.taobao.org 按上面这么做确实没错,而且也是必须,但是当你再次去创建ionic项目时还是会提示同样的错误(如果不报错说明你运气好,那下面就不用看了),那么原因到底是为什么呢?那是因为你的确安装了sass而且也成功下载了相关文件了,只是你在执行时候可能是因为运气不好或者当前软件没设计好的原因没给你自动添加sass的环境变量,所以这是我们得自己手动添加一下系统的环境变量(怎么添加系统环境变量我这就不提了,因为我认为很多人应该都会的,这里我只提一下要加什么环境变量,大概路径),例如我的环境变量如下:(这里提醒一下配置的路径最好是根据你的实际情况,因为每个人安装nodejs的方式都不一样)
系统变量名称:SASS_BINARY_PATH
系统变量值:C:\Users\Administrator\AppData\Roaming\npm-cache\node-sass\4.7.2\win32-x64-59_binding.node
(看不清楚图片的可以右键复制图片地址在新窗口打开就能查看大图)
【另外补充】:估计你会看到网上有人说自己到对应的地址例如Cannot download "https://github.com/sass/node-sass/releases/download/binding.nod在浏览器打开就能直接下载一个win32-x64-59_binding.node文件然后再配置对应的路径到系统环境变量,但是我要告诉你的是,最好别这么做,因为你这样做很可能会导致版本问题而导致你在使用ionic命令的时候提示版本不同命令不可使用等问题!
【技术交流QQ群】:188386255
【技术交流论坛】:www.phper.video
将学生信息保存到文件中,格式为.txt
运行成功可以直接搜索studen.txt,直接打开
代码如下
学生类
public class student { private String name; private int age; private double grade; public student(String name,int age,double grade) { this.name=name; this.age=age; this.grade=grade; } public String getName() { return name; } public int getAge() { return age; } public double getGrade() { return grade; } } 班级类 import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class studentclass { private List<student>stuList; private int size; public studentclass() { size=0; stuList=null; } public void createclass() { String names[]= {"
使用管道操作符提高代码简洁性 在编写R语言代码时,有时候需要对一个变量进行一系列的运算,例如对于一个同时包含数值列和字符串列的数据框,如果要计算所有数值列之间的相关系数,一般要分两步,第一步首先筛选数据框中的数值列,第二步计算数值列之间的相关系数。
x=data.frame(x1=c(1,34,22),x2=c(4,6,29),x3=c('a','b','c')) 假设我们需要计算上数据框x中数值列的相关系数,通常有两种做法:
分步进行 x_num=x[,unlist(lapply(x,function(i){is.numeric(i)==TRUE}))] cor(x_num) ## x1 x2 ## x1 1.0000000 0.2262448 ## x2 0.2262448 1.0000000 在分步进行的方法中,我们需要保存每一步产生的中间结果,用于下一步的计算,对于包含多步骤连续运算的计算问题,分步进行将会变得非常繁琐。
嵌套函数 cor(x[,unlist(lapply(x,function(i){is.numeric(i)==TRUE}))]) ## x1 x2 ## x1 1.0000000 0.2262448 ## x2 0.2262448 1.0000000 以上展示了嵌套函数的写法,嵌套函数通过逐层向外扩充表示对数据进行从内到外的不断依次计算,通常对于一两步连续运算,嵌套函数的写法还可以接受,但是超过三步的运算,如果不断向外嵌套,对于他人阅读理解代码以及代码的整洁性是非常不理想的,此外,嵌套写法不利于代码的修改。
以上两种写法是初学者在学习R语言执行多步计算时经常采用的写法,一种更为简洁明了、便于维护的写作方式便是今天讲的管道操作符。如果有人之前用过 dplyr 这个程序包,想必已经对于管道操作符的高效有了一定的了解和掌握。事实上, dplyr 中管道符的实现是依赖于另一个函数包 magrittr ,此处主要讲解该软件包中对于管道操作符的一些常用用法。
magrittr 包含四种管道操作符”%>%”,”%T>%”,”%<>%”,”%$%”,其中最重要最常用的是第一个”%>%”操作符。管道操作符是通过一种流程式的书写方式来表达一系列依次进行的运算操作,逻辑清晰且书写简便,下面通过一系列实际例子讲解管道操作符”%>%”的使用。
管道操作符”%>%”的基本用法 library(magrittr) x[,unlist(lapply(x,function(i){is.numeric(i)==TRUE}))]%>%cor() ## x1 x2 ## x1 1.0000000 0.2262448 ## x2 0.2262448 1.0000000 注意到上式中管道操作符的写法”%>%cor()”,事实上,管道操作符的实质就是将左边表达式(前一步运算)返回的结果默认地传给后续要执行的函数,因此管道操作符的实质可以用如下表达式清晰地表示为:
管道操作符:x%>%f1()%>%f2() 嵌套表达式:f2(f1(x)) 分步书写: res_1=x res_2=f1(res_1) res_3=f2(res_2) 可以看出,使用管道操作符具有逻辑清晰,书写方便的优点,此外管道操作符的表达方式允许我们方便地增加或删除其中一步的运算。
管道操作符中‘.’号的用法 在使用管道操作符时,默认地实际上是将左边表达式的结果作为右边函数的第一个参数传入的,如果右边函数只有一个参数,那自然无需考虑,但对于右边函数有多个参数,我们并不希望表达式的结果作为第一个参数时,就需要考虑更换默认的参数位置了。如何更换呢?这就需要了解‘.’在管道操作符中的用法。‘.’表达的即是左边表达式返回的结果,请观察下例:
x[,unlist(lapply(x,function(i){is.numeric(i)==TRUE}))]%>%cor(.) ## x1 x2 ## x1 1.
这篇博文我准备长期维护下去,只有在Android开发过程中有所得就会将其写入在此博文中,仅限个人经验总结,若读者看后有益就吸收,无益的就略过.
一、技术提升
1.Android做久了,发现涵盖的技能点虽多,但普通的应用层面的开发技术,最主要的也无非是UI布局、内存优化、网络请求与响应、数据存储这几方面,所以抓住要点,集中精力去学习这其中某一方面的技术即可。
2.很多时候我们总在问自己,学些什么好,这个问题不仿将其具体化,以关键字的方式学习,平时做个有心人,诸如,RecyclerView水平滑动、画廊、约束布局、ORM数据库(Room、GreenDao)、蓝牙、RxJava2、Retrofit,内存优化专题.
3.不要忘记写技术博客,去总结记录工作中发自内心的感触.
4.不要将加班视为工作负担,你的每一分钟付出都是在为自己积累能量,一个公司花着钱培养自己的能力,自己只付出时间提升自己,这是很经济的投入。公司工作的时间也是自己创业的时间,不要简单的认为出了公司就是已经开始创业了。公司可以积累经验与创业资金。
/** * 将数据从一个通道复制到另一个通道或从一个文件复制到另一个文件 * @author Administrator * */ public class ChannelDemo { public static void main(String[] args) throws Exception { FileInputStream in = new FileInputStream("E://PAGE.txt"); ReadableByteChannel source = in.getChannel(); FileOutputStream out = new FileOutputStream("E://User.txt"); WritableByteChannel destination = out.getChannel(); copyData(source,destination); source.close(); destination.close(); System.out.println("success"); } private static void copyData(ReadableByteChannel source, WritableByteChannel destination) throws IOException { ByteBuffer buffer = ByteBuffer.allocateDirect(20*1024); while(source.read(buffer) != -1){ buffer.flip(); while(buffer.hasRemaining()){//剩余可用长度 destination.write(buffer); } buffer.clear(); } } }
时间一晃而过,转眼间到公司已经半年多了。这是我人生中弥足珍贵的一段经历。在这半年多的时间里,在领导和同事们的悉心关怀和指导下,通过自身的努力,各方面均取得了一定的进步,现将我的工作情况作如下汇报。 一、通过日常工作积累使我对 DFDMJYKJ(BJ)有限公司 和 基因医学 有了新的认识 和 一定了解。 二、Android开发技能的提升。写了一个App —— 健康90岁,分为平板版、手机版、手机循证版、手机精准版,也经历了 数次 功能微调 和 UI调整。熟悉了Android 本地数据库 大量数据下的增删改查,更加熟悉了 Android UI 的绘制机制。 三、Socket即时通讯 和 视频流SDK的了解。写了一个Demo —— 综合 即时通讯(不依赖第三方SDK,自己开发服务端Socket通讯)、视频推流SDK(调研了多款SDK,其中深入了解了国内一款小众的SDK、以及 阿里云推流SDK、腾讯云推流SDK、金山云推流SDK)、拉流SDK(调研了Bilibili公司的ijkplayer,金山云拉流SDK),其中还使用了Linux Ubuntu编译了so库,更加了解Linux 系统的操作。为2018年实现Android原生多人视频聊天打下了坚实的基础。 三、后端开发的技能。这半年,我不仅仅从事Android App开发,还尝试了服务端Java Socket 即时通讯、Java JDBC Mysql数据库 API接口的编写,这样也便于我横向对比 同样是 服务端开发语言的PHP,与Java 优劣势对比,这半年强化了我的 后端技能。 四、对流媒体服务器的了解。通过Android 视频流的推流拉流测试,发现了 nginx-rtmp 和 Flash Media Server 的稳定性 与 性能差异,经过几次的安装和配置、问题排查,对Flash Media Server 也有一定的了解。 五、对WEB前端的了解。利用业余时间,学了网页端开发语言,HTML、CSS、JavaScript,继续扩展了技术领域。 六、对Python的了解。2017年最火的就是Python,人工智能、机器学习、大数据分析,使用Python语言都可以实现,并且代码量少,开发周期短。Python的学习也开了个头。 七、坚持更新CSDN上的技术博客。写博客,既是对技术的分享,也是对自己学习的总结。 “业精于勤而荒于嬉”,在以后的工作中我要不断学习业务知识,通过多看、多问、多学、多练来不断的提高自己的各项业务技能。学无止境,时代的发展瞬息万变,各种学科知识日新月异。我将坚持不懈地努力学习各种知识,并用于指导实践。在今后工作中,要努力做好开发人员的本职工作,把自己的工作创造性做好做扎实,为项目的开发以及公司的发展贡献自己的力量。 DFDMJYKJ(BJ)有限公司 Android开发 —— 王航 2017.12.29
对异地打工的程序员来说,最迷茫的时候可能不是深夜下班后在出租车上打盹,而是一年结束,不清楚自己目前的阶段,在这个程序员还不被世人了解的社会上,究竟处于什么位置。
为了让大家可以看到其他同行这一年大概的经历,安卓进化论邀请了 10 位小伙伴进行 2017 总结,他们的文字有的文艺、有的淳朴,最关键的是,他们和你一样,都是在努力前进的安卓开发者。
建议打开文首音乐,体验更佳哦。
贤妻良母天的 2017 总结 2017 我换了工作算是一件大事,接手的APP下载量从几十万变成了几亿。
在新的地方写的代码,会有无数的机型和用户帮你验证程序的正确性。业务的不断变化和极速的迭代也对代码的编写和维护提出了更多的要求,也会面对市面几乎所有的Android系统版本和各种奇葩的机型,是种磨炼也是种提升。
也了解到一个庞大优秀的APP应该有什么,简单列一下:
插件化,热更新,推送系统,APP安全,代码检查,线上性能监控,崩溃统计分析,打包系统,RN,H5和原生技术的结合等。
展望 2018,如果我能摸透上述罗列的所有技术那么当 CTO 都可以了,但是那太难了,因为涉及领域太多了。
所以应该更多的让自己学会如何使用和管理这些技术,没错 code 是我的兴趣,我还要在提升编码能力的同时走向技术管理的道路。
共勉!
JX 的 2017 总结 做android开发已经有两年半的时间了,也经历了android市场的火爆到现在的饱和,在第一家公司待了一年半的时间,属于创业公司,期间做了三个项目,android一直是两个人,没有大神带,只能自己通过各种渠道学习,在这期间也认识了很多技术大牛,对我影响比较大的是stormzhang,关注他也快两年的时间了,从他那里学到了很多技术和学习方法,也开始用github和Google,技术和眼界也算是增加了不少,但是最后公司经营不下去倒闭了。
今年的目标首先是工资要过万,持续关注学习最新技术,每周看完android周刊,熟练使用最新的框架和技术,所以最后那个项目用了Mvp+RxJava+Retrofit,也用到了tinker热修复,今年6月份离职开始投简历找工作,面试明显比以前少了很多,找了大概一个月的时间吧,进了现在这家公司,也是创业公司,做直播项目,这家公司好的就是有android大牛带,工资也达到了自己的目标,最喜欢的一点就是公司旁边有个篮球场,从进入公司开始每天打球,坚持了到现在了,工作固然重要,但是身体才是革命的本钱。
这一年定的目标算是基本完成了吧,到目前为止一直坚持看完每周的android周刊,每天闲暇时间阅读技术公号文章,看完了三本技术书,新的技术也在学习研究,但是研究的没有那么深,自己的基础还是差的太多。
新的一年目标:
深入研究RxJava,Retrofit ,dagger2,热修复,组件化等技术框架的原理。
看一些重要的android源码。
跟着组织的兄弟们系统的学习java知识,稳固基础。
研究音视频技术。
搭建自己的博客,写一些技术文章。
看完至少三本技术书籍,三本其他书籍。
坚持锻炼,保持每周至少去三次健身房。
Struggle 的 2017 总结 转眼间一年又要过完了,想想自己也没干出点啥东西出来,庆幸的是报了一个自考本科、和一群小伙伴搞了一个学习计划,参与了包建强的二个开源项目。
这一年不管是技术还是带团队处理问题的能力都有一个很好的提升。
经历过大起大落在低谷时自己找各种书籍资料查看反思最终找到了一个明确的目标。经历了这么多最终还是决定自考一个本科。以前我一直是觉得有技术就行了,直到有一天我以前的老大叫我去他那里的时候就是因为学历不够,连机会都没有。
当然我现在是奔着BAT去的,目前这一段时候我需要大量的复习准备考本科,但是就在前一段时间一个偶然的机会让我入了币坑,有一段时间一直关注币,就没有怎么学习了。当然这样是不行的,我决定调整我的状态来迎接考试。区块链其实是趋势,所以我会花一点时间去学习一下。
明年争取本科能顺利考过,同时技术纵向提高架构能力,横向向全栈靠拢。
Cloud 的 2017 总结 在北京做了两年多的Android,从15年的火热,到17年风口退去,在技术方面提升始终没有达到预计目标吧。
17年目标 今年原本打算年后回来跳槽,回来也有在准备面试,不过自己准备的始终是不尽人意,投了一些简历也没有面试邀请,并没有持续的投下去。后来公司人事变动,加上自己也要结婚,就计划着在公司把婚假休完了再走,这么一拖就是10月份之后了。
到10月份又重新打算跳,后来领导给涨了一些薪水,加上马上年底,也就想领完年终奖然后年后再跳了。也是一波三折,原本今年跳槽的计划落空了,不过也休了婚假,给调薪也算有所安慰。
这一年的焦虑感,也是越来越强。
16年刚在公司稳定下来,空闲时间没有认真的学习,今年一直在恶补。
这一年的书单如下:《Android群英传》《Android开发艺术探索》《Android源码设计模式》《Android Gradle权威指南》《大话数据结构》《think in java 4》《图解Http》。
不过当时读完现在也忘得差不多了...也有在慕课网报了两个课程学习,不管自己学的快慢,总之也是在前进。程序员这个坑真是不进则退,如果不想进步,迟早都会被淘汰!加油吧!
18年目标: 工作:
计划年后必须要跳槽,因为现在公司的技术氛围,还有项目是在是太一般了,没有用户量,app也没有亮点的地方,时间长了技术栈就要被锁死了。而且在这家也已经2年多了是时候了。
技术:
努力向高级迈进!计划学习一下另外一门语言,Python等。也要扩展一下自己的技术范围。不能锁死在Android里面。
效果体验二维码 如果文章对你有帮助的话,请打开微信扫一下二维码,点击一下广告,支持一下作者!谢谢! DEMO下载
效果图 WXML <view class="tui-list-box"> <view class="tui-menu-list"> <text>状态:{{isChecked1}}</text> <switch class="tui-fr" checked="{{isChecked1}}" bindchange="changeSwitch1"/> </view> <view class="tui-menu-list"> <text>状态:{{isChecked2}}</text> <switch class="tui-fr" checked="{{isChecked2}}" bindchange="changeSwitch2"/> </view> <view class="tui-menu-list"> <text>状态:{{isChecked3}}</text> <switch class="tui-fr" color="#007aff" checked="{{isChecked3}}" bindchange="changeSwitch3"/> </view> <view class="tui-menu-list"> <text>状态:{{isChecked4}}</text> <switch class="tui-fr" color="#007aff" checked="{{isChecked4}}" bindchange="changeSwitch4"/> </view> <view class="tui-menu-list"> <text>状态:{{isChecked5}}</text> <switch class="tui-fr" type="checkbox" checked="{{isChecked5}}" bindchange="changeSwitch5"/> </view> <view class="tui-menu-list"> <text>状态:{{isChecked6}}</text> <switch class="tui-fr" type="checkbox" checked="{{isChecked6}}" bindchange="changeSwitch6"/> </view> </view> JS var pageObj = { data: { isChecked1: false, isChecked2: true, isChecked3: false, isChecked4: true, isChecked5: false, isChecked6: true } }; for (var i = 0; i < 7; ++i) { (function (i) { pageObj['changeSwitch' + i] = function (e) { var changedData = {}; changedData['isChecked' + i] = !
Sometimes,我们会有这样的需求,即:想对比出两个不同版本代码的区别。如何实现?
第 1 种:如果我们是从 SVN 检出的项目,并且想比较本地代码与从 SVN 检出时的代码相比都有那些区别,可以按如下步骤操作, 如上图所示,在代码编辑区,右键唤出功能菜单,然后选择Subversion,进而会展示出更多的可选项,例如:
Compare with the Same Repository Version,与 SVN 仓库相同版本做对比;Compare with Latest Repository Version,与 SVN 仓库最新版本做对比;Compare with...,点击后选择本分支的不同版本做对比;Compare with Branch,点击后需要先配置具体要对比的分支,然后与指定分支做比对;Show History,同Compare with...类似,只不过是先展示出此分支的版本历史。 通过上述方法,已经可以满足我们比较线上分支代码的需求啦!
第 2 种:比较本地两份代码的区别,可以按如下步骤操作, 首先,选中目标文件夹(图中选择src文件夹),右键唤出功能菜单,然后点击Compare With:
如上图所示,选中本地另一份想要与之对比的代码的相同目录,然后点击Open或者打开、确定按钮:
如上图所示,清晰明了的展示了两份代码的区别。
———— ☆☆☆ —— 返回 -> 史上最简单的 IntelliJ IDEA 教程 <- 目录 —— ☆☆☆ ————
private void btnlogin_Click(object sender, EventArgs e) { //登录按钮事件 try { //判断最后登录时间 是不是今天 string s5 = "select * from Users where UserName=@u"; SQLiteParameter p4 = new SQLiteParameter("@u",txtUserName.Text); DataTable d= SqliteHelper.ExecuteDatatable(s5, p4); if (Convert.ToDateTime(d.Rows[0]["LastLoginTime"]).ToString("yyyy-MM-dd")!=DateTime.Now.ToString("yyyy-MM-dd")) { string s4 = "update Users set LastLoginTime=datetime('now','localtime'), LoginCount=0,ErrorCount=0 where UserName=@u"; SqliteHelper.ExecuteNonQuery(s4, p4); } if (txtPwd.Text.Trim() != "" && txtUserName.Text.Trim() != "") { string s = "select count(*) from Users where UserName=@u and PassWord=@p"; SQLiteParameter[] p = { new SQLiteParameter("
一、JDBC概述 为什么要使用JDBC? JDBC:java database connectivity SUN公司提供的一套操作数据库的标准规范。 JDBC与数据库驱动的关系:接口与实现的关系。 JDBC规范(掌握四个核心对象): DriverManager:用于注册驱动 Connection: 表示与数据库创建的连接 Statement: 操作数据库sql语句的对象 ResultSet: 结果集或一张虚拟表 开发一个JDBC程序的准备工作: > JDBC规范在哪里: JDK中: java.sql.*; javax.sql.*; > 数据库厂商提供的驱动:jar文件 *.jar 一定变成奶瓶才可用~~~ 二、开发一个JDBC程序(重要) 实现查询数据库中的数据显示在java的控制台中 1、创建数据库表,并向表中添加测试数据 create database day06; use day06; create table users( id int primary key auto_increment, name varchar(40), password varchar(40), email varchar(60), birthday date )character set utf8 collate utf8_general_ci; insert into users(name,password,email,birthday) values('zs','123456','zs@sina.com','1980-12-04'); insert into users(name,password,email,birthday) values('lisi','123456','lisi@sina.com','1981-12-04'); insert into users(name,password,email,birthday) values('wangwu','123456','wangwu@sina.com','1979-12-04'); 2、创建java project项目,添加数据库驱动(*.jar)
3、实现JDBC操作 //1、注册驱动 //2、创建连接 //3、得到执行sql语句的Statement对象 //4、执行sql语句,并返回结果 //5、处理结果 //6 关闭资源 三、JDBC常用的类和接口详解 1、java.
最近公司要用到知识图谱,所以需要一个类似于流程图的UI来与后台交互,能够方便客户使用。 非常感谢懒得安分写的博客,给了我很大的帮助。 原文地址 http://www.cnblogs.com/landeanfen/p/7910530.html
为什么我要转载呢? 因为我怕哪天博主把帖子删了。。。。 写在前面:我只是为了记代码,所以建议你们去看原文。。。
一、初次接触 GoJS简介
GoJS是一个功能丰富的JS库,在Web浏览器和平台上可实现自定义交互图和复杂的可视化效果,它用自定义模板和布局组件简化了节点、链接和分组等复杂的JS图表,给用户交互提供了许多先进的功能,如拖拽、复制、粘贴、文本编辑、工具提示、上下文菜单、自动布局、模板、数据绑定和模型、事务状态和撤销管理、调色板、概述、事件处理程序、命令和自定义操作的扩展工具系统。无需切换服务器和插件,GoJS就能实现用户互动并在浏览器中完全运行,呈现HTML5 Canvas元素或SVG,也不用服务器端请求。 GoJS不依赖于任何JS库或框架(例如bootstrap、jquery等),可与任何HTML或JS框架配合工作,甚至可以不用框架。
使用入门
(1) 文件引用
<script src="gojs/go-debug_ok.js"></script> (2) 创建画布
<div id="myDiagramDiv" style="margin:auto;width:300px; height:300px; background-color:#ddd;"></div> 然后使用gojs的api初始化画布
//创建画布 var objGo = go.GraphObject.make; var myDiagram = objGo(go.Diagram, "myDiagramDiv", { //模型图的中心位置所在坐标 initialContentAlignment: go.Spot.Center, //允许用户操作图表的时候使用Ctrl-Z撤销和Ctrl-Y重做快捷键 "undoManager.isEnabled": true, //不运行用户改变图表的规模 allowZoom: false, //画布上面是否出现网格 "grid.visible": true, //允许在画布上面双击的时候创建节点 "clickCreatingTool.archetypeNodeData": { text: "Node" }, //允许使用ctrl+c、ctrl+v复制粘贴 "commandHandler.copiesTree": true, //允许使用delete键删除节点 "commandHandler.deletesTree": true, // dragging for both move and copy "draggingTool.dragsTree": true, }); (3) 创建模型数据(Model)
本文首发于Gitchat,原作者王晓雷,经作者同意授权转发。转载请联系作者或GitChat。
背景 很多人问,对话式交互系统就是语音交互么?当然不是。语音交互本身真的算不上新概念,大家可能都给银行打过电话,“普通话服务请按1,英文服务请按2……返回上一层请按0” 这也算对话式交互系统,我想大家都清楚这种交互带来的用户体验有多低效。那么对话式交互系统已经可以取代人类提供服务了么?也没有,图灵测试还没有过呢,着什么急啊。
不过,随着人工智能的发展,对话式交互穿着语音和文本的外衣,携手模糊搜索引擎,怀抱计算科学和语言学的内核,带着定制化推荐的花环,驾着深度学习和大数据的马车乘风破浪而来——我们就知道,大约是时候了。至少,我们已经可以在十分钟内创造自己的对话式客服了。今天的文章大致分为三部分:历史,今天(chatbot api)和未来(深度学习和智能问答)。
先定义一下交互系统,wiki给出的定义是
Interaction is a kind of action that occurs as two or more objects have an effect upon one another.
即双方或者多方相互影响的过程,那么在咱们的上下文中,我们不妨限定为人机交互。先来讲讲是什么,再来讲讲怎么做吧。
历史和现在 广义上的对话式交互实际上包括所有一问一答形式的人机交互,自始至终,我们都需要从机器拿到信息。在最早的时代用的是文本交互系统TUI,其实直到今天,我相信程序员们在Linux下面完成大部分操作时还是会选用Terminal,这种文本交互非常简洁高效,但是有一个缺点:不熟悉操作的人上手非常困难,需要记住大量的指令和规则,才可以有效的告诉机器想要它做什么——正如一个笑话:“问:如何生成一个随机的字符串? 答:让新手退出VIM”。
直观的,既然“以机器的交流方式告诉机器想要做什么”这件事情给人类带来了很差的用户体验,那我们可以让机器提供可能的选项来让人类选择。所以,人类用了几十年,把交互系统升级成了图形化交互GUI。大家今天看到的桌面系统就是特别典型的一个体现。包括后来的触摸屏幕和智能手机的发展,其实都是图形化交互的不同表现。
现在一切都好了么?并没有。虽然机器可以在瞬间呈现大量的信息,但是人类在同一时刻可注意到的信息却极为有限。心理学研究发现,人类的注意广度其实只有5-9个对象。想象一下上面那张图,如果我在桌面上放100个应用程序呢?1000个呢?随着数据量的发展。如何在大量的信息中,迅速呈现出有效的信息呢?
搜索系统,或者再具体一点——推荐系统,在选项过多的时候,承担起了给用户尽可能高效率的提供想要的信息的任务。如果我们做好了智能搜索,我们就能做好智能交互。本质上都是一样的:在浩瀚的已知数据里,基于一定模型和经验,总结出用户最想要的答案并及时的呈现出来。我问Google一个问题,Google将我想要的答案排在第一个位置返回给我,谁又能说这不是对话式交互呢?
当然,我们希望的对话式UI不仅是一问一答,我们希望对话系统能够有自己的知识数据库,希望它保有对上下文的记忆和理解,希望它具有逻辑推演能力,甚至,颇有争议的,希望它具有一定的感情色彩。
所以,我们有了今天的Conversational UI,对话式交互只是一个壳子。其中的本质是智能和定制化服务,在一段时间的训练之后,你拿起电话拨给银行,应答的智能客服和人类的交互方式是一样的。抛开繁琐的从1按到9的决策路径,直接告诉他你要做什么,银行会直接给你提供最符合你需求的服务。而完成这个任务,我们主要有两条路可以走,一条是专家系统,这里也会给大家介绍几个网络上的引擎,争取在十分钟之内让大家学会建立一个属于自己的智能客服系统。而另外一条,则是智能问答系统,需要一点机器学习和深度学习的知识——教机器理解规则,比教机器规则,要有趣的多。
输入和输出 前面都在讲输入,就是机器如何理解人类的指令。是因为输出这个问题,可以说已经被解决了很久了。文本、图像和语音三大交流方式中,语音被解决的最晚,但是20年前的技术就已经足够和人类进行交流了,虽然我们还是能很容易的听出来语料是不是电子合成的,但是这一点音色上的损失并不影响我们交流的目的。
而语音到文本的识别便要复杂得多。这类工作确切来说始于1952年。从读识数字从1到0,然后把数字的声音谱线打出来,识别说的是哪个数字开始。这个模型虽然达到了98%的精度,但是其实并不具有通用性:数据源空间和目标空间都实在是太小了。
我们都知道当下最著名或者说最好用的语音识别模型是深度学习模型。但是在此之前呢?举一个典型例子:开复老师的博士论文,隐马尔科夫模型,大约三十年前发表,如下图所示:
简单说就是一个时间序列模型。有时间状态,隐藏状态,然后有观测状态。比如我有两个色子,一个六面体色子,从1到6。一个四面体的,从1到4。两个色子之间进行转换的概率都是0.5。现在给出一段极端一点的序列 111122224441111555566666666,大家觉得哪一段是四面体色子、哪一段是六面体色子呢?同理,听到一个语音,我想知道后面隐藏起来的那句话,原理也是和扔色子一样的:根据观测到的状态(声音)来推理后面隐藏的状态(文本)。这类概率模型的效果相当不错,以至于今天还有许多人在用。
chatbot api 按照人工干预的多少,推理引擎的实现大致可以分为两类。一类是人工定义规则,一类是机器从数据里面自动学习规则。对于前者,我们都知道wit.ai和api.ai这两个著名的chatbot开放api, 分属于Facebook和Google两大巨头。先来看一下实现的效果:
(图片来自:http://t.cn/RS17j6U)
这里的+表示得分,机器准确的理解了人类的意图。o表示不得分,机器并没有理解。我们可以看到,其实表现并没有想象中的那么好,一些很简单的案例‘i would like to order pizza’ 都没有得分,离普通人类的智能还有些距离。
那么背后的逻辑是怎样的呢?举一个api.ai的例子,我们会定义不同的类型和变量,然后把他们和相关的值与回答链接起来。从而在和用户进行交互的时候,能够按照已知的(人类定义的)规则来存储相应的值,并调用相应的方法。
可能大家会觉得英文读起来比较慢,这里介绍一个中文版api.ai——yige.ai. 并不是广告,我了解这个平台还得益于我的朋友——有一天他跑来跟我说:夭寿啦!你知道吗,有个相亲网站,拿人工智能代替女性用户和人聊天!之后,官方辟谣说并不会这么做。但是yige.ai在新手入门方面的友善程度,实在是我见过中文chatbot API中数一数二好的。
(具体参见:http://t.cn/RcjU8w8)
但是也正如图中所示,我们依旧需要人工定义很多事情包括词库,场景,规则,动作,参数等等。在买鞋这样一个小的场景和确定范围的交互期待里面,这样做还是可以为大部分人群所接受的。毕竟简单而直观,精准的实现了“十分钟制作属于自己的chatbot”这一需求,更不需要强大的计算资源和数据量。但我们并不太可能在这样的系统里面,得到定义好的域以外的知识。如果我们的时间和人力足够多的话,能够有专门的一些领域专家来完善这个提问库,将会使得搜索的精度非常高。因为所有可能的提问都已经有了专业的答案。但是,当场景复杂之后,这样做的工作量就会变成很大的压力了。
所以,我们需要深度学习。
深度学习想要达到一个好的表现,需要有两个前提。一个是足量的计算资源,一个是大量的数据。
计算资源不用说,如果没有GPU,图片/语音这种非结构化的原始数据训练的时间基本需要以“周”来作单位。
数据集设计 关于大数据,一个很常见的问题就是,多大才算大,学术一点的说法是:大到包含区分目标值所需要的所有特征就可以了——我们都知道在实践中,这句话基本属于废话。那么举个例子,一般来说训练一个语音识别的模型,数据是以千小时为单位计算的。
而且很抱歉的是,很多商业公司的数据集基本是不公开的。那么对于小型的创业公司和自由研究者,数据从哪里来呢?笔者整理了一些可以用来做自然语言处理和智能问答的公开数据集,这里由于篇幅和主题所限,就不展开讲了。改天会专门开主题介绍免费可用的公开数据,以及在公开数据集上所得到的模型应该如何迁移到自己的问题域当中来。
图片来自:https://rajpurkar.github.io/SQuAD-explorer/
这里用斯坦福大学的著名问答数据集作为例子,SQuAD,可以被称为业内用于衡量问答系统的最棒最典型的数据集。我们可能在高中时代都做过阅读理解,一篇文章带有几个问题,答案来自于文章的信息。那么有了这样一个数据集,我们能做的事情是什么呢?这样一个数据集所训练出的模型可以解决什么样的问题?在各个问题中,人类的表现和机器的表现有什么样的差异?为什么?
我们很高兴的看到,在最新发表的一篇基于r-net的论文中,机器的表现已经可以和人类媲美了。人类在这个数据集所得到的EM得分约82.3,F1得分约91.2。而微软发表的框架EM得分高达82.1,和人类相差不足0.2%。
本章主要说明如何使用鼠标功能。
vim打开鼠标(临时设置)
:set mouse=a 长久设置,在~/.vimrc中添加
set mouse=a 关闭鼠标 :set mouse-=a mouse参数说明
// n 普通模式 // v 可视模式 // i 插入模式 // c 命令行模式 // h 在帮助文件里,以上所有模式 // a 以上所有模式 // r 跳过|lit-enter|提示 // A 在可是模式下自动选择
错误信息如下:
HTTP Status 500 – Internal Server Error...
的解决办法:
近期在安装与配置solr搜索服务器时,遇到的这个问题,但凭借经验一下就看出来问题所在了,记录下来方便别人查阅,错误内容如下图:
如上图错误内容所示,
注意:Could not load conf for core collection1: Error loading solr config from /home/www/solr/solr/home/collection1/conf/solrconfig.xml
大意为:不能加载用于核心集合的配置文件,我检查路径时发现 “ 路径 ” 写错了,导致访问solr服务时加载不到solr核心配置文件solrconfig.xml, 这个错误实在 《 Linux下Solr4.10.4搜索引擎的安装与部署 》中配置solr的启动需要加载配置文件路径时,配置文件的路径搞错了,少写了一层导致无法加载到核心配置文件,如下图:
修改路径正确后,就可以正常的访问了,如下图:
2017-12-27 记录导致同样问题的问题:
关于FieldType的name 在Solr中是唯一的,如果配置了两个或两个以上的FieldType相同的name,就会出现冲突,导致Solr服务内部错误, 系统中已存在一个FieldType的name为id,如果不小心再又创建一个同名FieldType节点的name为id,则会出现同样的问题,如下图:
模糊查询(LIKE) 如果你失忆了,希望你能想起曾经为了追求梦想的你。 QQ群:651080565(php/web 学习课堂) 模糊查询,常用在“搜索”,在这个平台,我想找到一篇文章,但是数据太多了,找不到,但只要你还记得他标题的一部分,就可以使用模糊查询来找到他。 在使用模糊(LIKE)查询之前,我们先普及一个知识:通配符! 引用:http://www.w3school.com.cn/sql/sql_wildcards.asp 可以这么理解:通配符就是搭配LIKE的,是模糊查询的辅助一样 数据表: 演示:SELECT * FROM cs_user WHERE username LIKE "张%" 图解: 通配符:“%” 意思是 “替代一个或多个字符”。效果也和很明显,我搜索“张%”,只要开头(第一个)是“张”的,就会全部搜索出来。 通配符:“_” 意思是 “替代一个字符,只是一个”:SELECT * FROM cs_user WHERE username LIKE "张_" 图解: 我们搜索“张”,后面跟了一个 “_” ,他就只会给出数据 “张加一个字符”。 搜索我们用到更多的,是这样的: SELECT * FROM cs_user WHERE username LIKE "%2%" 图解: 这里面用通配符,是可以多个使用的,你可以 "张__" 也可以 “____张”...更多更多! 说说我们这个:SELECT * FROM cs_user WHERE username LIKE "%2%" 之前说了,“%”的意思是,替代一个或多个字符,我们在前面用一个,在后面用一个,这样只要我们能记住你要搜索的文章,大致标题,就可以搜索出来的。 但这也并非完美,比如,你要搜索的文章标题是: 你就是太会给自己找理由了! 而你只记得:“你理由”。 如果你输入这三个字的话,会得不到 “你就是太会给自己找理由了!”这边文章的结果。因为,我们给出的条件是“%你理由%”,程序就只会去找,包含了“你理由”并且自动拼接前面的字符和后面的字符,而他是把“你理由”三个字靠在一起的,但我们搜索的原本标题,这三个字并非是靠在一起的。所以是得不出结果的
AND 和 OR
如果你失忆了,希望你能想起曾经为了追求梦想的你。 QQ群:651080565(php/web 学习课堂) 我们查询数据的时候,会使用条件来过滤数据,达到筛选效果,过滤不要的数据,获取我们需要的。 最基本的就是WHERE子句 查询:SELECT * FROM cs_user WHERE id = 10 这样,我们可以查询出 id = 10 的数据。这是一个单项选择题一样,只有一个条件过滤。 那么在一个表里: 我若,只要年龄(age) 在18-20之间的数据(包含18和20)。那么用上面的 WHERE 子句,单个条件,是难以获取到我们想要的效果的,这时候,and和or 就来了,英语即时是初级的同学都明白,and 和 or的意思吧。。 AND(and) 并且 OR(or) 或者 理解它不难,但是实际运用,刚开始学习,逻辑可能理不清楚,就很麻烦了。我们看一下: AND:SELECT * FROM cs_user WHERE age >= 18 AND age <= 20 图: 对比cs_user表内,大于等于18 并且 小于等于20 ,正好两条数据 OR:SELECT * FROM cs_user WHERE age >= 18 or age <= 20 看图: 对比 AND 和 OR: 1.写法无差异,他们最大的差异只有两点:1是一个是 and 一个是 or;2是本身的含义,and(并且)、or(或者) 2.
搜遍网上的解决方案都没什么效果,结果重置sogou和fcitx就好了
#!/bin/sh pidof fcitx | xargs kill pidof sogou-qimpanel | xargs kill nohup fcitx 1>/dev/null 2>/dev/null & nohup sogou-qimpanel 1>/dev/null 2>/dev/null &
删除数据(DELETE)
如果你失忆了,希望你能想起曾经为了追求梦想的你。 数据库存储数据,总会有一些垃圾数据,也会有一些不需要用的数据了,这些情况下,我们就可以删除这些数据,释放出一定的空间,给其他的数据使用 使用前需注意:删除(DELETE),是删除一(条)行数据,图1里,有4条(行)数据,换句话说,你要删除第四条 名字为“巴巴”的用户,那么关于他的 id、密码、性别、年龄都会被删除 删除前: 删除和修改都有一共共同点,需要 WHERE 过滤条件,否则,也会删除多条数据,所以说,使用的时候一定要检查 基本语句:DELETE FROM cs_user WHERE username = "巴巴" 详解: DELETE(delete) 删除语句 FROM(from) 指定表 cs_user 表名 WHERE(where) 过滤条件 username = "巴巴" ,字段名 = 数据 演示: 效果: 有同学还是会好奇,想着尝试一下,删除(DELETE) 后面不跟 WHERE 做过滤条件,是不是数据真的会全部被删除?同学们,我们先来一波推理吧,理论: 你给机器下达命令:给本大爷删除这个表里的“某个”数据,你想的是,删除某个数据,但是你没有给出条件,那么机器收到的命令则是:我去给大爷删除这个表的数据。 能理解吗? 换句话说,就是你下达指令,没有下达完全,没有指定目标,换个例子:正在打仗,战友正在运转跑车方向,还没对准敌人,你就来了句:开炮!虽然他们会迷惑为什么?但是长官下达的命令,又正在战场上,能不听吗?结果会如何,你懂滴。。。 所以说,我们是 修改数据、删除数据,都要找到,我们要删除谁?就要给出条件:我要删除这个被多个玩家举报开外挂的用户。但有时,不一定要做删除操作,像这里,就不是删除开外挂的用户了,而是冻结他的用户,1星期、1个月、一年什么的,就需要修改操作,修改他的状态。嘛,这里就不多说,会让初学同学搞不懂 说这么多,就为了一点:使用修改或是删除语句的时候,请注意,你要删除的对象是谁,要谨慎。除非是真的全部删除,否则一定要谨慎,以后你来操作公司数据库,N多个数据,被你 手抖一下 全删完了?那你的领导要跟你做做思想工作了。 我们不给过滤条件,来看看效果吧: 效果: 建议同学们,尽可能的去尝试一下,光懂理论还不行哟 SQL(sql) 最基础的:增删查改,就结束了,前几篇介绍了 增、查、改。那么后面我们会深入学习SQL
有时候在一个表中插入数据,(插入语句都正常,没有任何错误)但是插入报错,这时候可以查找一下是否这张表是否加了trigger(触发器),导致数据插入失败的。、
还有类似的删除操作也有可能出现这种情况。
假如正常的插入语句,但是表加了触发器,如下触发器:
假设当前的数据库是:数据库A
ALTER trigger [dbo].[tri_proc]
on [dbo].[表A]
after insert
as
begin
SET NOCOUNT ON
SET XACT_ABORT ON
DECLARE @CarNum numeric(10, 0), @SeqNum numeric(10, 0),@CompanyCode numeric(10, 0); SELECT @CarNum=CarNumber, @SeqNum=SeqNo FROM inserted;
INSERT 数据库B.dbo.表B(CarNum,SeqNum,CompanyCode)VALUES(@CarNum,@SeqNum,(Select top 1 CompanyCode from 某个表 where CarNumber = @CarNum));
END
上述的错误发生是:在数据库A上,插入了名为“tri_proc”的触发器,假如当前数据库服务器上不存在数据库B,那么在插入数据的时候,会报“数据库B.dbo.表B无效”,往表A插入数据的时候,里面的触发器会往数据库B的表B插入数据,而当前服务器上不存在这个数据库,所以会报错。
SQL Server 触发器 触发器是一种特殊类型的存储过程,它不同于之前的我们介绍的存储过程。触发器主要是通过事件进行触发被自动调用执行的。而存储过程可以通过存储过程的名称被调用。
Ø 什么是触发器
触发器对表进行插入、更新、删除的时候会自动执行的特殊存储过程。触发器一般用在check约束更加复杂的约束上面。触发器和普通的存储过程的区别是:触发器是当对某一个表进行操作。诸如:update、insert、delete这些操作的时候,系统会自动调用执行该表上对应的触发器。SQL Server 2005中触发器可以分为两类:DML触发器和DDL触发器,其中DDL触发器它们会影响多种数据定义语言语句而激发,这些语句有create、alter、drop语句。
DML触发器分为:
1、 after触发器(之后触发)
a、 insert触发器
b、 update触发器
c、 delete触发器
2、 instead of 触发器 (之前触发)
其中after触发器要求只有执行某一操作insert、update、delete之后触发器才被触发,且只能定义在表上。而instead of触发器表示并不执行其定义的操作(insert、update、delete)而仅是执行触发器本身。既可以在表上定义instead of触发器,也可以在视图上定义。
触发器有两个特殊的表:插入表(instered表)和删除表(deleted表)。这两张是逻辑表也是虚表。有系统在内存中创建者两张表,不会存储在数据库中。而且两张表的都是只读的,只能读取数据而不能修改数据。这两张表的结果总是与被改触发器应用的表的结构相同。当触发器完成工作后,这两张表就会被删除。Inserted表的数据是插入或是修改后的数据,而deleted表的数据是更新前的或是删除的数据。
对表的操作
Inserted逻辑表
Deleted逻辑表
增加记录(insert)
存放增加的记录
无
删除记录(delete)
无
存放被删除的记录
修改记录(update)
存放更新后的记录
存放更新前的记录
Update数据的时候就是先删除表记录,然后增加一条记录。这样在inserted和deleted表就都有update后的数据记录了。注意的是:触发器本身就是一个事务,所以在触发器里面可以对修改数据进行一些特殊的检查。如果不满足可以利用事务回滚,撤销操作。
Ø 创建触发器
语法
create trigger tgr_name on table_name with encrypion –加密触发器 for update... as Transact-SQL # 创建insert类型触发器
--创建insert插入类型触发器 if (object_id('tgr_classes_insert', 'tr') is not null) drop trigger tgr_classes_insert go create trigger tgr_classes_insert on classes for insert --插入触发 as --定义变量 declare @id int, @name varchar(20), @temp int; --在inserted表中查询已经插入记录信息 select @id = id, @name = name from inserted; set @name = @name + convert(varchar, @id); set @temp = @id / 2; insert into student values(@name, 18 + @id, @temp, @id); print '添加学生成功!'; go --插入数据 insert into classes values('5班', getDate()); --查询数据 select * from classes; select * from student order by id; insert触发器,会在inserted表中添加一条刚插入的记录。
修改数据(UPDATE)
如果你失忆了,希望你能想起曾经为了追求梦想的你。 我们玩QQ、微信、淘宝等等,都会有一个操作:修改信息 淘宝常用的嘛,新增了收货地址,也可以修改它,微信/QQ修改昵称、密码、签名等,这些数据都是保存在数据库里的,那么,需要操作数据库里的数据,修改它,就要用到:UPDATE(update) 控制上一篇文章留下的数据库、表及数据: 表数据: 第四条数据(id为4的),它没有 性别和年龄的数据,那么我们用 UPDATE来修改。注意:这里是修改,并非添加(INSERT INTO) 基本语句:UPDATE cs_user SET gender = '男' WHERE id = 4 看图: 修改后的效果: 使用UPDATE(update)需注意: 1.请使用 WHERE 进行过滤筛选,若没有筛选,它会把整个列(字段)全部改变,请看: 效果: 2.SET后面可以跟多个字段和新数据,以逗号隔开,实例:UPDATE cs_user SET age = 18 , gender = '女' WHERE id = 4 效果: 3.UPDATE(修改)和 INSERT INTO(新增) 不同,新增只需加数据,会一行一行的增加,而UPDATE修改,是需要条件过滤的,否则就会改动整个表的数据了。UPDATE不算是新增数据,即时刚开始 第四条数据,他没有 gender、age的数据,我加入进去了新数据,那也算是修改,并非添加,就是说:我把他空的数据,修改成了非空数据。 4.WHERE(过滤条件):条件,就好比你去某个班级,找男生帮忙搬东西,进去之后,发现男生太多了,你只需要10个男生,你就会给出条件:“来10个最强壮的”,那么这就是条件,过滤了剩下的男生,他们不会被选中。 这里用到的 等于(=), 还有更多的条件 大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、不等于(!=)....
在 (一) 初探 iOS 单元测试 一文中,我们简单提到了执行xcodebuild test可以启动工程的单元测试并输出测试结果,但手动执行此类命令意义是不大的。我们需要的是,把一些测试和lint等命令写在脚本文件里,在代码提交、合并及打包等行为实际发生前,自动执行脚本,以执行的结果决定是否打断上述操作,一定程度上达到控制代码质量的目的。 在多人协作开发中,我们可以在所有成员进行某些git操作(commit push merge rebase等)前进行代码的验证(Test、Lint等),防止逻辑错误或不合规范的代码更新到远端仓库中。当然,如果团队搭建了自己的git服务器,有Mac服务器,在server端进行git hooks是最好的解决方案,本地仓库也不用进行额外配置。此外,我们也可以做一些Client Hooks,来达到同样的效果。以下内容是笔者对git pre-push hook的一些实践。
手动添加pre-push文件 前往本地仓库,按下command+shift+.查看隐藏文件,目录如下。我们可以看到.git/hooks路径下有一些.sample的文件。 删除pre-push.sample文件的后缀名,用编辑器打开,写入: exit 1 复制代码 保存退出,仓库根目录下,执行:
git push 复制代码 可以看到push失败。下面我们在pre-push写入单元测试的命令,如果测试通过,pre-push程序正常退出,push成功;测试失败,出错并退出,push失败。写入: workspace_name() { workspace_file=`find . -maxdepth 2 -name *.xcworkspace -exec basename {} \;` echo ${workspace_file%.xcworkspace} } check_result() { if [ $? != 0 ]; then echo "$1 failed!!" echo "push will not execute" echo "$?" exit 1 else echo "$1 passed." echo "push will execute"
增加语句(数据) 如果你失忆了,希望你能想起曾经为了追求梦想的你。 前一节我们学习了查询语句 SELECT,这节课,我们学习增加 INSERT INTO **** VALUES ****,基本的语句 首先看看我们的数据库、表、字段: 数据库名: 表名: 字段: 我这里使用的工具是:Navicat for MySQL(同事都用这个,我也只好用咯,同学们若用的工具比较少,要记得扩展喔) 增加语句(第一种):INSERT INTO cs_user VALUES (null,'阿里','wodemima','男',22); 效果: 增加语句(第二种):INSERT INTO cs_user(username,password) VALUES ('巴巴','baba'); 效果: 解释: 第一种:这个表有5个字段,那么你就要写5个数据,并且数据的顺序要对应字段的顺序,id 是主键并自增长,所以在 VALUES 里写入 NULL 即刻,自动增加,每次+1,数字类型,可以直接写数字,字符串类型,比如带单引号或双引号(不能使用中文的) 第二种:在cs_user 表的后面加入了字段名(以逗号隔开),因为id是自动增长,所以我们可以不用写,这里我们写的字段是 username和password,所以添加数据,也只写入这两个就可以了,其他的字段,不需要理会 两种写法的差异: 1:表名后面有没有跟字段名; 2:第一种数据添加必须写全,第二种只写表名后面跟的字段(id自增属性 NULL都不用写); 3:第一种必须按照表字段的顺序,第二种可以把字段顺序打乱(比如:上面的username和password交换位置也没问题),但数据也必须对应写入字段的顺序; 4:第一种写全数据才能添加,否则失败,第二种只添加指定的字段,没有指定的字段则为空(NULL),或是为你的默认值(DEFAULT设置字段属性,默认某个值) 两种写法的共同点: 1:必须按字段的顺序添加数据,若添加的数据和字段属性不匹配,则会添加失败(比如:数字类型,不能写入字符串)
一、错误信息 添加httpclient与httpcore依赖后编译Maven报错。
错误信息如下:
Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:1.3.1:enforce (enforce-banned-dependencies) on project manager: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. 二、错误定位 根据错误信息,定位到pom.xml的enforce-banned-dependencies。可能发生的错误:Java编译版本问题、被禁止依赖冲突问题。排除Java编译版本问题,查看新添加依赖包maven文件,dependency内容如下:
<dependency> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> <scope>compile</scope> </dependency> 由此,基本确定问题所在。
三、错误解决 在项目pom.xml文件新添加dependency元素节点中,添加子元素排除依赖冲突:
<exclusions> <exclusion> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> </exclusion> </exclusions> 重新编译,错误解决。
转载于:https://www.cnblogs.com/fantastic-clouds/p/8064790.html
之前写了很多关于spring cloud的文章,今天我们对OAuth2.0的整合方式做一下笔记,首先我从网上找了一些关于OAuth2.0的一些基础知识点,帮助大家回顾一下知识点:
一、oauth中的角色 client:调用资源服务器API的应用 Oauth 2.0 Provider:包括Authorization Server和Resource Server (1)Authorization Server:认证服务器,进行认证和授权 (2)Resource Server:资源服务器,保护受保护的资源 user:资源的拥有者
二、下面详细介绍一下Oauth 2.0 Provider Authorization Server: (1)AuthorizationEndpoint:进行授权的服务,Default URL: /oauth/authorize (2)TokenEndpoint:获取token的服务,Default URL: /oauth/token
Resource Server: OAuth2AuthenticationProcessingFilter:给带有访问令牌的请求加载认证
三、下面再来详细介绍一下Authorization Server: 一般情况下,创建两个配置类,一个继承AuthorizationServerConfigurerAdapter,一个继承WebSecurityConfigurerAdapter,再去复写里面的方法。 主要出现的两种注解: 1、@EnableAuthorizationServer:声明一个认证服务器,当用此注解后,应用启动后将自动生成几个Endpoint:(注:其实实现一个认证服务器就是这么简单,加一个注解就搞定,当然真正用到生产环境还是要进行一些配置和复写工作的。) /oauth/authorize:验证 /oauth/token:获取token /oauth/confirm_access:用户授权 /oauth/error:认证失败 /oauth/check_token:资源服务器用来校验token /oauth/token_key:如果jwt模式则可以用此来从认证服务器获取公钥 以上这些endpoint都在源码里的endpoint包里面。
2、@Beans:需要实现AuthorizationServerConfigurer AuthorizationServerConfigurer包含三种配置: ClientDetailsServiceConfigurer:client客户端的信息配置,client信息包括:clientId、secret、scope、authorizedGrantTypes、authorities (1)scope:表示权限范围,可选项,用户授权页面时进行选择 (2)authorizedGrantTypes:有四种授权方式 Authorization Code:用验证获取code,再用code去获取token(用的最多的方式,也是最安全的方式) Implicit: 隐式授权模式 Client Credentials (用來取得 App Access Token) Resource Owner Password Credentials (3)authorities:授予client的权限
这里的具体实现有多种,in-memory、JdbcClientDetailsService、jwt等。 AuthorizationServerSecurityConfigurer:声明安全约束,哪些允许访问,哪些不允许访问 AuthorizationServerEndpointsConfigurer:声明授权和token的端点以及token的服务的一些配置信息,比如采用什么存储方式、token的有效期等
client的信息的读取:在ClientDetailsServiceConfigurer类里面进行配置,可以有in-memory、jdbc等多种读取方式。 jdbc需要调用JdbcClientDetailsService类,此类需要传入相应的DataSource.
下面再介绍一下如何管理token: AuthorizationServerTokenServices接口:声明必要的关于token的操作 (1)当token创建后,保存起来,以便之后的接受访问令牌的资源可以引用它。 (2)访问令牌用来加载认证 接口的实现也有多种,DefaultTokenServices是其默认实现,他使用了默认的InMemoryTokenStore,不会持久化token;
cv2.imread(filename, flags) 这个函数用来读取一副图像. 第一个参数(必须传)可以是图片的相对路径或者绝对路径(如果你第一个参数传错,程序不会报错,但是函数的返回值会是None). 第二个参数(可选)指定你要以何种方式读取图片,第二参数是个值它可以是: cv2.IMREAD_COLOR:加载一张彩色图片,忽略它的透明度,在不传第二个参数时,它也是默认值. cv2.IMREAD_GRAYSCALE:加载灰度图.cv2.IMREAD_UNCHANGED:加载一张图片包含它的alpha通道(透明度),就是原图像不做改变的加载. 可以简单的用1,0,-1分别代替三个值. # read in one image img = cv2.imread('1.jpg') 将图像文件以数组的形式读入到变量img中。
cv2.imshow(winname, mat) 这个函数用来在制定窗口中显示指定的图像,如果这个窗口不存在,将新建这个窗口. 第一个参数为窗口名称,需要加单引号,每个窗口名称不同. 第二个参数为存储要显示的图片的变量.
# display the image in the window image1 # the window's size is the size of image and can not be changed cv2.imshow('image1', img) 显示刚才读入的图像。
cv2.nameWindow(winname, flags) 用来新建一个窗口. 第一个参数为窗口名称. 第二个参数为窗口类型,具体可以使用的类型如下:
参数值作用cv2.WINDOW_NORMAL用户可以调整窗口的大小,也可以将一个窗口从全屏窗口切换到普通窗口cv2.WINDOW_AUTOSIZE用户不能改变窗口的大小,窗口的大小被所展示的图片所约束cv2.WINDOW_OPENGLopengl支持的窗口cv2.WINDOW_FULLSCREEN将窗口设置为全屏cv2.WINDOW_FREERATIO扩展图片不考虑图片的分辨率cv2.WINDOW_KEEPRATIO扩展图片但考虑图片的分辨率cv2.WINDOW_GUI_EXPANDED带进度条和工具条cv2.WINDOW_GUI_NORMAL旧方法 # open a new window ,the second parameter means ths size of the window can change cv2.
##简介
在实际应用中需要锁定某状态,排除程序“跑飞”,致看门狗复位而引起I/O状态的误动作。
##使用方法
如下图:
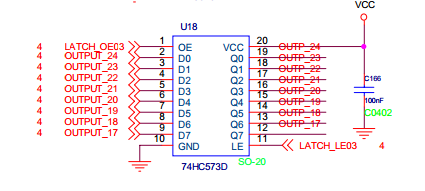 **1脚是输出使能** **11脚是锁存使能** **D是输入** **Q是输出** ##功能说明 - OE 接低电平,使芯片内部数据保持器输出端与芯片8位输出端之间连通; - LE 端的作用是通过高低电平控制8位输入与内部数据保持器输入端的连通与断; - 当 LE = 0 时,P0端口的8位数据线与74HC573内部数据保持器的输入端断开; - 当 LE = 1 时,P0端口的8位数据线与74HC573内部数据保持器的输入端连通。 文档链接:http://download.csdn.net/download/xiaogu0322/10174997
##Datasheet NOTE
74HCT573-Q100具有八进制D型透明锁存器,每个锁存器具有独立的D型输入,而面向总线的应用则具有三态真正的输出。 锁存使能(LE)输入和输出使能(OE)输入对于所有锁存器是公共的。
LE为高电平时,Dn输入端的数据进入锁存器。 在这种情况下,锁存器是透明的,即每当其对应的D输入改变时,锁存器输出就改变状态;当LE为低电平时,锁存器将存在于D输入端的信息存储在LE的高电平至低电平转换之前的建立时间;当OE为低电平时,8个锁存器的内容在输出端可用;当OE为高电平时,输出变为高阻态关闭状态。OE输入的操作不会影响锁存器的状态。 ##硬件设计注意事项
LE和OE拉低利于软件设计。
jQuery.ajaxSetup()函数用于设置AJAX的全局默认设置。
该函数用于更改jQuery中AJAX请求的默认设置选项。之后执行的所有AJAX请求,如果对应的选项参数没有设置,将使用更改后的默认设置。
该函数属于全局jQuery对象。
语法 jQuery 1.1 新增该静态函数。
[html] view plain copy jQuery.ajaxSetup( settings ) 参数 参数描述settingsObject类型一个对象,其中的每个属性表示需要更改默认设置的选项,属性值表示更改后的默认值。 关于settings参数可以识别的属性,请参考jQuery.ajax()中的settings参数说明。其中的所有选项参数都是可选设置的。
返回值 jQuery.ajaxSetup()函数没有返回值,或者说其返回值为undefined。
示例&说明 以下是与jQuery.ajaxSetup()函数相关的jQuery示例代码,以演示jQuery.ajaxSetup()函数的具体用法:
[html] view plain copy //设置AJAX的全局默认选项 $.ajaxSetup( { url: "/index.html" , // 默认URL aysnc: false , // 默认同步加载 type: "POST" , // 默认使用POST方式 data:{
"name":"limian" //默认添加额外参数
}
headers: { // 默认添加请求头 "Author": "CodePlayer" , "Powered-By": "CodePlayer" } , error: function(jqXHR, textStatus, errorMsg){ // 出错时默认的处理函数 // jqXHR 是经过jQuery封装的XMLHttpRequest对象 // textStatus 可能为: null、"
//判断是否全屏document.getElementById(id) function IsFull() { var fullscreenElement = SSOcx.fullscreenEnabled || SSOcx.mozFullscreenElement || SSOcx.webkitFullscreenElement; var fullscreenEnabled = SSOcx.fullscreenEnabled || SSOcx.mozFullscreenEnabled || SSOcx.webkitFullscreenEnabled; console.log(document.fullscreenElement); console.log(document.fullscreenEnabled); if (fullscreenElement == null) { return false; } else { return true; } } /** * [isFullscreen 判断浏览器是否全屏] * @return [全屏则返回当前调用全屏的元素,不全屏返回false] */ function isFullscreen(){ console.log(document.fullscreenElement); console.log(document.msFullscreenElement); console.log(document.mozFullScreenElement); console.log(document.webkitFullscreenElement); return document.fullscreenElement || document.msFullscreenElement || document.mozFullScreenElement || document.webkitFullscreenElement || false; }
1、在“报告”-->“板子信息”-->“报告”-->“最后一个“Routing Information””
"报告"“看到”“Routing completion”是否为100%边线
2、显示未连线步骤
在左下角“PCB”框中上方下拉菜单“Nets”
接下来选择“<All Nets>”
在下面看到“Un-Routed”不为0的就是未连接
在前面打勾即可看到
转载于:https://www.cnblogs.com/ldcb/p/8033225.html
1.基本命令 查看参数:$sqlldr
2.导入示例 用服务器创建导入数据的export.txt文件,示例如下:
编写MY_TEST_sqlldr_bak.ctl控制文件
OPTIONS(BINDSIZE=10485760,READSIZE=2097152,ERRORS=-1,ROWS=250000,skip=1)
LOAD DATA
CHARACTERSET AL32UTF8
APPEND INTO TABLEMY_TEST
FIELDS TERMINATED BY X'7c'TRAILING NULLCOLS
(
"ID" CHAR(11) NULLIF "ID"=BLANKS,
"NAME" CHAR(20) NULLIF "NAME"=BLANKS,
"AGE" CHAR(12) NULLIF "AGE"=BLANKS,
"ADDRDSS" CHAR(50) NULLIF "ADDRDSS"=BLANKS,
"HIRE_DATE" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF"HIRE_DATE"=BLANKS
)
ctl常见的一些参数解析:
characterset :字符集, 一般使用字符集 AL32UTF8,如果出现中文字符集乱码时,改成 ZHS16GBK。
fields terminated by 'string':文本列分隔符。当为tab键时,改成'\t',或者 X'09';空格分隔符 whitespace,换行分隔符 '\n' 或者 X'0A';回车分隔符'\r' 或者 X'0D';默认为'\t'。
optionally enclosed by 'char':字段包括符。当为 ' ' 时,不把字段包括在任何引号符号中;当为"'" 时,字段包括在单引号中;当为'"'时,字段在包括双引号中;默认不使用引用符。
fields escaped by 'char':转义字符,默认为'\'。
当我们使用vivado搭建好硬件设计后就要在SDK下进行程序编写了,在SDK中我们可以建立C/C++工程,所以就有很多的库函数可以调用,那么问题来了,如何查询我想要的API函数呢?或者是该API函数如何使用?
下面我将以GPIO的IPCore为例介绍如何查询API函数。
1.将vivado设计好的硬件设计导入到SDK中,就可以把SDK代码编辑区的变迁也让切换到system.mss页面,可以看到Target Information,operating system,peripheral drivers和libraries。
2.可以看到所有的外设都已被列出来,单击每类外设后面的"Documentation"超链接即可打开其相应的API函数说明页面。以及个人外设可以导入例程供你参考。
3.弹出库浏览页面,在PC上以网页形式给出。其中“overview”页面讲解的是这个外设的简单介绍;"Data Structures"页面列出了软件驱动所涉及的数据结构,对于GPIO来讲,有XGpio和XGpio_Config这两个结构体;"File list"页面显示了所有相关的头文件和源文件的超链接,可点击查看其版本信息和主要函数,是设计人员需要仔细查看的页面。
4.单击进入"file list"页面,即可列出GPIO外设的所有函数。单击某个函数后面的头文件超链接即可进入到详细说明页,会给出函数的功能、输入参数以及返回参数的含义。
使用Spring @DependsOn控制bean加载顺序 spring容器载入bean顺序是不确定的,spring框架没有约定特定顺序逻辑规范。但spring保证如果A依赖B(如beanA中有@Autowired B的变量),那么B将先于A被加载。但如果beanA不直接依赖B,我们如何让B仍先加载呢?
控制bean初始化顺序 可能有些场景中,bean A 间接依赖 bean B。如Bean B应该需要更新一些全局缓存,可能通过单例模式实现且没有在spring容器注册,bean A需要使用该缓存;因此,如果bean B没有准备好,bean A无法访问。 另一个场景中,bean A是事件发布者(或JMS发布者),bean B (或一些) 负责监听这些事件,典型的如观察者模式。我们不想B 错过任何事件,那么B需要首先被初始化。
简言之,有很多场景需要bean B应该被先于bean A被初始化,从而避免各种负面影响。我们可以在bean A上使用@DependsOn注解,告诉容器bean B应该先被初始化。下面通过示例来说明。
示例说明 示例通过事件机制说明,发布者和监听者,然后通过spring配置运行。为了方便说明,示例进行了简化。
EventManager.java 事件管理类,维护监听器列表,通过单例方法获取事件管理器,可以增加监听器或发布事件。
import java.util.ArrayList; import java.util.List; import java.util.function.Consumer; public class EventManager { private final List<Consumer<String>> listeners = new ArrayList<>(); private EventManager() { } private static class SingletonHolder { private static final EventManager INSTANCE = new EventManager(); } public static EventManager getInstance() { return SingletonHolder.
限制滚轮缩放范围 想要给jtopo的场景缩放加上限制,首先需要找到源代码中控制缩放的代码:
// 在源码里ctrl+F搜索 onmousewheel 就能找到以下代码 function l(a) { var b = d(a); // 原滚轮缩放 a.preventDefault(); n.dispatchEventToScenes("mousewheel", b); n.dispatchEvent("mousewheel", b), null != n.wheelZoom && (a.preventDefault ? a.preventDefault() : (a = a || window.event, a.returnValue = !1), 1 == n.eagleEye.visible && n.eagleEye.update()) // 鹰 } function m(b) { a.util.isIE || !window.addEventListener ? (b.onmouseout = f, b.onmouseover = e, b.onmousedown = g, b.onmouseup = h, b.onmousemove = i, b.onclick = j, b.
本篇是React Native开源小项目,目前完成了初始版本,至于后续会不会增加其他知识点,待定吧,数据来自gankio,页面跳转使用的react-navigation,一边学习一边写,下面是总体的效果,没有多么华丽的功能,各位看官自行查看吧!
一个react native开发的Android app
效果图: 使用到的库: react-navigationreact-native-image-zoom-viewerreact-native-vector-icons等等 首页使用TabNavigator,其余页面代码点击底部链接查看: import React, {Component} from 'react'; import { Image, Text } from 'react-native'; import { TabNavigator, StackNavigator, } from 'react-navigation'; import Home from './tabPage/Home'; import Type from './tabPage/Type'; import ShopCar from './tabPage/Message'; import Mine from './tabPage/Mine'; import Details from './tabPage/Details'; import WebViewPage from './page/WebViewPage'; import ImageZoom from './tabPage/img/ImageZoom'; import Setting from './tabPage/Setting'; import CardStackStyleInterpolator from 'react-navigation/src/views/CardStack/CardStackStyleInterpolator'; const Tab = TabNavigator({ //每一个页面的配置 Home: { screen: Home, navigationOptions: { //stackNavigator的属性 headerTitle: '首页', gestureResponseDistance: {horizontal: 300}, headerBackTitle: null, headerStyle: {backgroundColor: '#cf2ceb'},//导航栏的样式 headerTitleStyle: {//导航栏文字的样式 color: 'white', //设置标题的大小 fontSize: 16, //居中显示 alignSelf: 'center', }, //tab 的属性 tabBarLabel: '首页', tabBarIcon: ({tintColor}) => ( <Image source={require('.
本文示例环境:CentOS 7,远程服务器 可能的依赖:python; pip; python-devel; gcc; gcc-c++; 一、安装(命令行操作) 如果没有pip,要安装pip: 安装 setuptools
cd /tmp wget https://pypi.python.org/packages/69/56/f0f52281b5175e3d9ca8623dadbc3b684e66350ea9e0006736194b265e99/setuptools-38.2.4.zip#md5=e8e05d4f8162c9341e1089c80f742f64 # 具体下载地址可能变更,请参见官网:https://pypi.python.org/pypi/setuptools#downloads unzip setuptools-38.2.4.zip # 我下载的是 .zip 源码,所以用 unzip 解压 cd setuptools-38.2.4/ python setup.py install 再安装 pip
cd /tmp wget https://pypi.python.org/packages/11/b6/abcb525026a4be042b486df43905d6893fb04f05aac21c32c638e939e447/pip-9.0.1.tar.gz#md5=35f01da33009719497f01a4ba69d63c9 # 同样,具体下载地址参考:https://pypi.python.org/pypi/pip#downloads tar zxvf pip-9.0.1.tar.gz # 解压 cd pip-9.0.1/ python setup.py install 安装 jupyter notebook 如果想用 python2:
python -m pip install --upgrade pip python -m pip install jupyter 如果报错:
……………………………… error: command 'gcc' failed with exit status 1 试试:
如果是做Python或者其他语言的小伙伴,对于生成器应该不陌生。但很多PHP开发者或许都不知道生成器这个功能,可能是因为生成器是PHP 5.5.0才引入的功能,也可以是生成器作用不是很明显。但是,生成器功能的确非常有用。
优点 直接讲概念估计你听完还是一头雾水,所以我们先来说说优点,也许能勾起你的兴趣。那么生成器有哪些优点,如下:
生成器会对PHP应用的性能有非常大的影响PHP代码运行时节省大量的内存比较适合计算大量的数据 那么,这些神奇的功能究竟是如何做到的?我们先来举个例子。
概念引入 首先,放下生成器概念的包袱,来看一个简单的PHP函数:
function createRange($number){ $data = []; for($i=0;$i<$number;$i++){ $data[] = time(); } return $data; } 这是一个非常常见的PHP函数,我们在处理一些数组的时候经常会使用。这里的代码也非常简单:
我们创建一个函数。函数内包含一个for循环,我们循环的把当前时间放到$data里面 for循环执行完毕,把$data返回出去。 下面没完,我们继续。我们再写一个函数,把这个函数的返回值循环打印出来:
$result = createRange(10); // 这里调用上面我们创建的函数 foreach($result as $value){ sleep(1);//这里停顿1秒,我们后续有用 echo $value.'<br />'; } 我们在浏览器里面看一下运行结果:
这里非常完美,没有任何问题。(当然sleep(1)效果你们看不出来)
思考一个问题 我们注意到,在调用函数createRange的时候给$number的传值是10,一个很小的数字。假设,现在传递一个值10000000(1000万)。
那么,在函数createRange里面,for循环就需要执行1000万次。且有1000万个值被放到$data里面,而$data数组在是被放在内存内。所以,在调用函数时候会占用大量内存。
这里,生成器就可以大显身手了。
创建生成器 我们直接修改代码,你们注意观察:
function createRange($number){ for($i=0;$i<$number;$i++){ yield time(); } } 看下这段和刚刚很像的代码,我们删除了数组$data,而且也没有返回任何内容,而是在time()之前使用了一个关键字yield
使用生成器 我们再运行一下第二段代码:
$result = createRange(10); // 这里调用上面我们创建的函数 foreach($result as $value){ sleep(1); echo $value.'<br />'; } 我们奇迹般的发现了,输出的值和第一次没有使用生成器的不一样。这里的值(时间戳)中间间隔了1秒。
css中按钮有四种状态
1. 普通状态
2. hover 鼠标悬停状态
3. active 点击状态
4. focus 取得焦点状态
.btn:focus{outline:0;} 可以去除按钮或a标签点击后的蓝色边框
下面的例子中.btn1用focus按钮会按下,不弹起
.btn2用active按钮点击按下,会弹起
<button class="btn btn1">Save Settings</button> <button class="btn btn2">Submit</button> .btn{ appearance: none; background: #026aa7; color: #fff; font-size: 20px; padding: 0.65em 1em; border-radius: 4px; box-shadow: inset 0 -4px 0 0 rgba(0,0,0,0.2); margin-right: 1em; cursor: pointer; border:0; } .btn1:hover{ box-shadow: inset 0 -4px 0 0 rgba(0,0,0,0.6), 0 0 8px 0 rgba(0,0,0,0.5); } .btn1:focus{ position: relative; top: 4px; box-shadow: inset 0 3px 5px 0 rgba(0,0,0, 0.
使用find命令找到大于指定大小的文件:
find / -type f -size +10G 排除某个目录
find / -path "/media/xww" -type f -size +10G 修改Docker本地镜像与容器的存储位置的方法 方法一、软链接 默认情况下Docker的存放位置为:/var/lib/docker 可以通过下面命令查看具体位置:
sudo docker info | grep "Docker Root Dir" 解决这个问题,最直接的方法当然是挂载分区到这个目录,但是我的数据盘还有其他东西,这肯定不好管理,所以采用修改镜像和容器的存放路径的方式达到目的。
这个方法里将通过软连接来实现。
首先停掉Docker服务:
systemctl restart docker 或者 service docker stop 然后移动整个/var/lib/docker目录到目的路径:
mv /var/lib/docker /root/data/docker ln -s /root/data/docker /var/lib/docker 这时候启动Docker时发现存储目录依旧是/var/lib/docker,但是实际上是存储在数据盘的,你可以在数据盘上看到容量变化。
方法二、可扩展逻辑卷 默认情况下docker的存放位置为: /var/lib/docker 一般根下分区我们不会给太大。镜像和容器越存越多一般我们有两种解决方法 1、挂载大分区到/var/lib/docker: 一般选择建立逻辑分区lvm,方便后期扩展集体。
a.建立新分区,并格式化 PS: 以下操作建设你已经有现成的卷组,直接可以划逻辑卷。或者你可以自己创建逻辑卷,或者不适用逻辑卷直接使用分区 lvcreate -L 300G lv_docker vg_home mkfs.ext4 /dev/vg_home/lv__docker b.挂载新分区到临时挂载点 [plain] view plain copy mkdir /mnt/docker mount /dev/vg_home/lv_docker /mnt/docker/ c.
pycharm 导入自定义模块提示 no module named 参考链接 http://blog.csdn.net/pwc1996/article/details/52577148
问题描述 在 pycharm 的 terminal 界面执行某脚本的时候,提示:
ImportError: No module named '*******' 但是在 pycharm 直接运行文件是可以执行的,不会报错。
原因在于 pycharm 和 python3.5 默认的模块导入目录不一样。
系统默认的 path >>> import sys >>> sys.path ['', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python35.zip', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages'] 在 pycharm 中创建一个文件 test.py import sys print(sys.path) 输出结果:
['/Users/citizen_wang/Documents/PycharmProject/learnpython', '/Users/citizen_wang/Documents/PycharmProject/learnpython', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python35.zip', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages'] 比较两者的不同,会发现 PycharmProject 的默认路径,会包含 Project 目录,也就解释了为什么在 pycharm 里面可以执行,但是在 terminal 终端里面就会包 no module name 的错误。
解决方法 在 site-packages 文件中增加 Pycharm 文件路径。
很高兴在我的职业生涯中认识了译者张宇,在我进行信用风险评分卡开发工作中,给予我宝贵的指导和建议。消费金融行业的风控体系搭建,包括用户申请评分卡、催收评分卡在企业全业务流程运作中发挥的重大作用。并接触到NPV模型在小额贷款公司的应用,根据NPV模型进行风险定价,此为国内小额信贷行业成功开发并上线NPV模型的创新先例。这些精细化的数据运作成功践行了“数据驱动”的管理理念。
我大概花了一个周的时间仔细研读了张宇译作的《消费金融真经》,此书更像是一本个人贷款业务全流程指南,包含消费金融产品定位与设计、信用评分、获客、催收评分及策略。“数据驱动”是贯穿本书的核心理念,以及风险收益平衡原则、未雨绸缪的业务规划原则、通过概率进行管理原则、通过业务指标体系管理原则和权责清晰的风险管理原则“五大业务管理原则”。
全书读下来有一种置身业务场景并跟着作者思考困境的酣畅淋漓。书中提到的从获客、信用风险评分、催收评分、业务系统管理的各个阶段我都能在博达看到实际运作的身影。这让我对企业的整体风控体系搭建有了更清晰的理论支撑和更加深入的认识。这与张宇先生在担任博达信贷首席风控官期间为企业的数据驱动以及整套风控体系的推动落地息息相关。
特别本书对于逾期率(还账率)的理解和计算中提到的滞后效应:在快速增长的资产组合中,滞后坏账率与本期坏账率的结果通常会显著不同,而滞后坏账率更能真实的反映逾期和损失现状。许多急剧增长的业务经常会投机取巧地使用未经滞后的计算方法掩盖真相,但当增长停止时,游戏也就结束了!
这帮助我们解释了消费金融行业坏账披露的滞后效应以及为什么越来越多年轻的消费金融公司在初期一直拥有非常漂亮的账单数据,骤然间呈现爆发式的坏账增长,直至遭到毁灭性打击。这一点也是博达信贷的长达8年的风控周期里曾经经历过惨痛的教训,而如今从中吸取了宝贵的经验,可以在小额贷款颠沛流离的市场竞争中走得更高更稳的原因。
最后再次感谢张宇先生将本书翻译引进给国内消费金融的同行,以及博达这一拥有成熟金融风控体系的企业让我得到光速的成长并锻炼出愈加开阔的思考视野。
中国消费金融行业的未来,已经到来!
我的博客即将同步至腾讯云+社区,邀请大家一同入驻。
要求: 例如下面这个文件中的SQL文件,现在需要将这些SQL文件的内容合并到一个文件中 实现步骤: 1、打开命令提示符窗口(快捷键:win + r 然后在[运行]的输入框中输入 cmd,点击确定) 2、使用cd命令进入到待合并的文件所在的文件夹中 3、然后输入 "copy *.sql all.sql",此处根据要合并的文件类型自行灵活处理 结果: 注意: 1、合并后的文件,需要检查一下文件内容的头部和尾部,自行删除一下多余的内容(我的只多了一下下面的这个东西)
本文写于2017年,随着时间变化内容可能会有出入,仅供参考
一、下载安装unity
1.搜索进入unity——Download
2.点击选择Choose your Unity + download
3.选择个人版并下载
4.打钩并选择自己电脑系统
5.下载完成,按向导安装,到这里勾选Android Build Support
6.完成安装
二、开发环境配置
1.下载jdk,sdk推荐网址http://tools.android-studio.org/index.php/sdk/85-tools/109-android-tools-download
2.下载完成后,运行SDK Manager,勾选Tools文件夹下的以下三个,与调试机子API匹配的Android系统(通常用6.0),和Extras下的一个Google USB Driver安装完成后,右边显示Installed
3.环境配置过程推荐网址
1)、文档http://www.manew.com/thread-11109-1-1.html 2)、视频http://edu.manew.com/course/8中的课时7
三、发布游戏到手机
1.点击Edit-Preference出现下面界面,选择好JDK和SDK的目录
2.点击File-Build Settings打开如下界面,点击Add Open Scenes添加当前场景,点击Andriod切换平台,勾选右侧的Development Build,点击左下角Switch Platform,然后点击旁边Player Setings
3.在右边出现的Inspector界面中修改Company Name和Product Name
4.点击Build,生成apk文件,通过qq等方式将其发送到手机,安装并运行,完成调试。