ubuntu硬盘变成只读的正确解决办法 #今天进入ubuntu后,发现挂载的硬盘无法写入,每个文件夹和文件都显示一把锁的图标,变成了只读状态。如图:
尝试了网上能够查到的N种方法,诸如:fsck /dev/sda1命令、mount /dev/sda1 / -o rw,remount、等等,反正就是解决不了。后来看到有人通过进入windows修复磁盘解决问题,就想到一个方法,结果完美解决,而且非常简单。方法共享如下:
一、打开ubuntu中自带的“磁盘”程序(你可通过搜索程序“磁盘”来找到,也可通过菜单栏找到,还可以终端运行:gnome-disks)
二、找到并单击选中想要修复的磁盘,然后点击左下方齿轮状的按钮,并单击运行“check filesystem”和“Repair filesystem”命令
三、出现提示单击“确定”继续,完成修复。
四、挂载硬盘后你会发现,锁的图标不见了,修复成功!!这是我目前发现最简单的解决方法,希望能够帮到大家。
在rules中代码如下
rules: { phone: [ { required: true, message: "请输入手机号码", trigger: "blur" }, { min: 11, max: 11, message: "请输入11位手机号码", trigger: "blur" }, { pattern: /^(13[0-9]|14[579]|15[0-3,5-9]|16[6]|17[0135678]|18[0-9]|19[89])\d{8}$/, message: "请输入正确的手机号码" } ], }
问题由来 function fn () { console.log(this.user); } var obj = { fn: fn, user: 'objZY' }; var user = 'zy'; fn(); // zy obj.fn(); // objZY 上面代码中,虽然obj.fn和fn指向同一个函数,但是执行结果不一样。这种差异的原因,就在于函数体内部使用了this关键字。
js中的this指的是函数运行时所在的环境(即调用的对象)。也就是说 this 既不是指向函数自身也不指向函数的作用域,this 实际上是在函数被调用时才发生绑定,它指向什么地方完全取决于函数在哪里被调用。
默认绑定 在 js中 ,最常用的函数调用类型就是独立函数调用。
function a(){ console.log(this.user); //zy console.log(this); //Window } var user = "zy"; a(); 如果在调用函数的时候,函数不带任何修饰,也就是“光秃秃”的调用,那就会应用默认绑定规则, 默认绑定的指向的是全局作用域。
隐式绑定 当函数在调用时,如果函数有所谓的“落脚点”,即有上下文对象(即调用时.前面有对象)时,隐式绑定规则会把函数中的 this 绑定到这个上下文对象。
var user = 'zy1'; var obj = { user:"zy", fn:function(){ console.log(this.user); //zy } }; obj.fn(); 在上面这段代码中,obj 就是所谓的 fn 函数的落脚点,专业一点的说法就是上下文对象,当给函数指定了这个上下文对象时,函数内部的this 自然指向了这个上下文对象。这也是很常见的一种函数调用模式。
UPDATE语句的基本语法
1.改变表中数据的UPDATE语句:
UPDATE <表名>
SET <列名> = <表达式>;
2将更新对象的列和更新后的值都记述在 SET 子句中.
指定条件的UPDATE语句
1.更新部分数据行的搜索型UPDATE:
UPDATE <表名>
SET <列名> = <表达式>
WHERE <条件>;
2.。SET 子句中赋值表达式的右边不仅可以是单纯的值,还可以是包含列的表达式。
使用NULL进行更新
1.和 INSERT 语句一样,UPDATE 语句也可以将 NULL 作为一个值来使用。但是,只有未设置 NOT NULL 约束和主键约束的列才可以清空为NULL。如果将设置了上述约束的列更新为 NULL,就会出错,这点与INSERT 语句相同。
2.使用UPDATE语句可以将值清空为NULL(但只限于未设置NOT NULL约束的列)
多列更新
1.UPDATE Product
SET <列名> = <表达式>;
<列名> = <表达式>;
WHERE 表达式’;
2.SET 子句中的列不仅可以是两列,还可以是三列或者更多
获取更多资讯,赶快关注上面的公众号吧!
文章目录 第十九章 遗传算法-史上最全选择策略19.1 轮盘赌选择(Roulette-wheel selection)19.2 锦标赛选择(Tournament selection)19.3 截断选择(Truncation selection)19.4 蒙特卡洛选择(Monte Carlo selection)19.5 概率选择(Probability selection)19.6 线性排序选择(Linear-rank selection)19.7 指数排序选择(Exponential-rank selection)19.8 玻尔兹曼选择(Boltzmann selection)19.9 随机遍历选择(Stochastic-universal selection)19.10 精英选择(Elite selection) 第十九章 遗传算法-史上最全选择策略 从群体中选择优胜的个体,淘汰劣质个体的操作叫选择。选择算子有时又称为再生算子(reproduction operator)。选择的目的是把优化的个体(或解)直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的,目前常用的选择算子有以下几种:轮盘赌、锦标赛、截断选择、蒙特卡洛选择、概率选择、线性排序、指数排序、玻尔兹曼、随机遍历、精英选择等,接下来作详细介绍。
19.1 轮盘赌选择(Roulette-wheel selection) 轮盘赌选择法是依据个体的适应度值计算每个个体在子代中出现的概率,并按照此概率随机选择个体构成子代种群,因此该方法也被称为适应度比例法。轮盘赌选择策略的出发点是适应度值越好的个体被选择的概率越大。因此,在求解最大化问题的时候,我们可以直接采用适应度值来进行选择。但是在求解最小化问题的时候,我们必须首先将问题的适应度函数进行转换(如采用倒数或相反数),以将问题转化为最大化问题。
为了计算选择概率P(i),需要用到每个个体i的适应度值fi:
P ( i ) = f i ∑ j = 0 N − 1 f j (1) P\left( i \right) = \frac{{{f_i}}}{{\sum\nolimits_{j = 0}^{N - 1} {{f_j}} }}\tag 1 P(i)=∑j=0N−1fjfi(1)
从给定种群中选出M个个体就等价于旋转M次轮盘,在选择个体前实际上不必对种群中的个体进行排序。注意式(1)中默认假定所有适应度值为正值,且适应度值之和不为0。为了能够处理负的适应度值,可以采用一种改进的公式来计算选择概率。
P ′ ( i ) = f i − f min ∑ j = 0 N − 1 ( f j − f min ) (2) P^{\prime}(i)=\frac{f_{i}-f_{\min }}{\sum_{j=0}^{N-1}\left(f_{j}-f_{\min }\right)}\tag 2 P′(i)=∑j=0N−1(fj−fmin)fi−fmin(2)
参考原文 https://blog.csdn.net/magicbaby810/article/details/79848425
android studio 3.4.1 classpath 'com.android.tools.build:gradle:3.4.1'
distributionUrl=https\://services.gradle.org/distributions/gradle-5.1.1-all.zip
compileSdkVersion 27 targetSdkVersion 27 buildToolsVersion '27.0.3'
1. File - Other Setting - Default Setting, 不勾选Offline work
2.File - Setting ,勾选Enable embedded Maven repository
3. 如下图,红色注释;
4.如下图,修改maven ;
5.选择性参考,告辞
gradle下载:http://services.gradle.org/distributions/ (C:\Users\Zian\.gradle\wrapper\dists)
实用链接
————————————————
版权声明:本文为CSDN博主「请叫我公子」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_30837235/article/details/83008216
AndriodStudio集成 FFmpeg环境,报错:java.lang.UnsatisfiedLinkError: dalvik.system.PathClassLoader[DexPathList[[zip file "/data/app/com.example.player-Bhalv81bWdaEyxPpDfXPvg==/base.apk"],nativeLibraryDirectories=[/data/app/com.example.player-Bhalv81bWdaEyxPpDfXPvg==/lib/arm64, /system/lib64, /product/lib64]]] couldn't find "libplayer.so"
我的CMakeList文件配置
cmake_minimum_required(VERSION 3.4.1) # 目录下所有的`.cpp`文件都需要被编译,并保存到全局变量`SOURCE`中。 file(GLOB SOURCE *.cpp) # 将SOURCE变量中的源文件编译到 player动态库中 add_library( player SHARED ${SOURCE}) find_library( log-lib log) #设置头文件的目录。 #编译的时候需要用到的头文件,编译后头文件不会打包到目标库中。这样的话,在native-lib中可以直接引用头文件。 include_directories(include) # 标志位, clang这个编译期来构建 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -L${CMAKE_SOURCE_DIR}/../../../libs/${CMAKE_ANDROID_ARCH_ABI}") # 将armeabi-v7a目录下的静态库文件,链接到动态库`player`中。 # 将会去编译环境目录去找 avfilter avformat ...等静态库,所以需要配置编译环境路径 target_link_libraries( player avfilter avformat avcodec avutil swresample swscale ${log-lib}) app的build.gradle文件
android { compileSdkVersion 29 buildToolsVersion "29.0.2" defaultConfig { applicationId "com.example.player" minSdkVersion 21 targetSdkVersion 29 versionCode 1 versionName "
IntelliJ IDEA 简称 IDEA,被业界公认为最好的 Java 集成开发工具,尤其在智能代码助手、代码自动提示、代码重构、代码版本管理(Git、SVN、Maven)、单元测试、代码分析等方面有着亮眼的发挥。IDEA 产于捷克,开发人员以严谨著称的东欧程序员为主。IDEA 分为社区版和付费版两个版本。
我呢,一直是 Eclipse 的忠实粉丝,差不多十年的老用户了。很早就接触到了 IDEA,但一直用不习惯 IDEA,不过为了与时俱进,最近开始下定决心——硬面刚。
01、下载 IDEA 我建议大家从官网上下载软件,免得被某些软件园捆绑恶意插件,烦不胜烦。IntelliJ IDEA 的官方下载地址为:https://www.jetbrains.com/idea/download/
UItimate 为付费版,可以免费试用,主要针对的是 Web 和企业开发用户;Community 为免费版,可以免费使用,主要针对的是 Java 初学者和安卓开发用户。
功能上的差别如下图所示。
本篇教程主要针对的是 Java 初学者,所以选择免费版为例,点击「Download」进行下载。
稍等一分钟时间,大概 580M。
02、安装 IDEA 双击运行 IDEA 安装程序,一步步傻瓜式的下一步就行了。
为了方便启动 IDEA,可以勾选【64-bit launcher】复选框。为了关联 Java 源文件,可以勾选【.java】复选框。
点击【Install】后,需要静静地等待一会,大概一分钟的时间,趁机休息一下眼睛。
安装完成后的界面如下图所示。
03、启动 IDEA 回到桌面,双击运行 IDEA 的快捷方式,启动 IDEA。
假装阅读完条款后,勾选同意复选框,点击【Continue】
如果想要帮助 IDEA 收集改进信息,可以点击【Send Usage Statistics】;否则点击【Don’t send】。
点击【Create New Project】,创建一个新的项目。
我电脑上默认安装的是 JDK 1.8。
给项目起一个英文名字,点击【Finish】。
启动成功后的界面如下图所示。
点开 cmower 节点,可以查看项目创建成功后的目录结构图。
1).idea 目录里有一些 xml 文件,包含了项目的历史记录和版本控制信息。
问题:python 之input 报错 NameError: name 'PAT' is not defined
产生原因:python2不支持直接输入字符串
解决:用python3即可,配置路径:File -> Settings... ->Project:xxx ->Project Interpreter
javascript中对一个对象: var obj = {}
进行存储操作:
// 前面为key值, 后面为value值 obj[key] = value; 进行取出操作:
// 打印的key为key值, obj[key]为该key对应的value值 for(var key in obj){ console.log('key is ' + key +' and value is' + obj[key]); } 样例:
实验目的 通过模拟实现请求页式存储管理的几种基本页面置换算法,了解虚拟存储技术的特点,掌握虚拟存储请求页式存储管理中几种基本页面置换算法的基本思想和实现过程,并比较它们的效率。
实验内容 设计一个虚拟存储区和内存工作区,并使用下述算法计算访问命中率。
1、最佳淘汰算法(OPT)
2、先进先出的算法(FIFO)
3、最近最久未使用算法(LRU)
4、最不经常使用算法(LFU)
5、最近未使用算法(NUR)
命中率=1-页面失效次数/页地址流长度
实验准备 本实验的程序设计基本上按照实验内容进行。即首先用srand( )和rand( )函数定义和产生指令序列,然后将指令序列变换成相应的页地址流,并针对不同的算法计算出相应的命中率。
(1)通过随机数产生一个指令序列,共320条指令。指令的地址按下述原则生成:
A:50%的指令是顺序执行的
B:25%的指令是均匀分布在前地址部分
C:25%的指令是均匀分布在后地址部分
具体的实施方法是:
A:在[0,319]的指令地址之间随机选取一起点m
B:顺序执行一条指令,即执行地址为m+1的指令
C:在前地址[0,m+1]中随机选取一条指令并执行,该指令的地址为m’
D:顺序执行一条指令,其地址为m’+1
E:在后地址[m’+2,319]中随机选取一条指令并执行
F:重复步骤A-E,直到320次指令
(2)将指令序列变换为页地址流
设:页面大小为1K;
用户内存容量4页到32页;
用户虚存容量为32K。
在用户虚存中,按每K存放10条指令排列虚存地址,即320条指令在虚存中的存放方式为:
第 0 条-第 9 条指令为第0页(对应虚存地址为[0,9])
第10条-第19条指令为第1页(对应虚存地址为[10,19])
………………………………
第310条-第319条指令为第31页(对应虚存地址为[310,319])
按以上方式,用户指令可组成32页。
实验指导 一、虚拟存储系统
UNIX中,为了提高内存利用率,提供了内外存进程对换机制;内存空间的分配和回收均以页为单位进行;一个进程只需将其一部分(段或页)调入内存便可运行;还支持请求调页的存储管理方式。
当进程在运行中需要访问某部分程序和数据时,发现其所在页面不在内存,就立即提出请求(向CPU发出缺中断),由系统将其所需页面调入内存。这种页面调入方式叫请求调页。
为实现请求调页,核心配置了四种数据结构:页表、页框号、访问位、修改位、有效位、保护位等。
二、页面置换算法
当CPU接收到缺页中断信号,中断处理程序先保存现场,分析中断原因,转入缺页中断处理程序。该程序通过查找页表,得到该页所在外存的物理块号。如果此时内存未满,能容纳新页,则启动磁盘I/O将所缺之页调入内存,然后修改页表。如果内存已满,则须按某种置换算法从内存中选出一页准备换出,是否重新写盘由页表的修改位决定,然后将缺页调入,修改页表。利用修改后的页表,去形成所要访问数据的物理地址,再去访问内存数据。整个页面的调入过程对用户是透明的。
常用的页面置换算法有
1、最佳置换算法(Optimal)
2、先进先出法(Fisrt In First Out)
3、最近最久未使用(Least Recently Used)
4、最不经常使用法(Least Frequently Used)
5、最近未使用法(No Used Recently)
代码 #include <iostream> #include <ctime> #include <random> using namespace std; #define TRUE 1 #define FALSE 0 #define INVALID -1 #define NULL 0 #define total_instruction 320 //指令数量 #define total_vp 32 //页表数量 #define clear_period 50 //清0周期 struct pl_type { /*页表结构*/ int pn, pfn, counter, time; }; pl_type pl[total_vp]; //页表数组 struct pfc_type { /*内存表结构*/ int pn, pfn; pfc_type *next; }; pfc_type pfc[total_vp], *freepf_head, *busypf_head, *busypf_tail; int diseffect; // 未命中次数 int a[total_instruction]; // 存储320条指令 int page[total_instruction]; // 每条指令对应的页表号 int offset[total_instruction]; int initialize(int); int FIFO(int); int LRU(int); int NUR(int); int LFU(int); int OPT(int); int main(){ int s; srand(unsigned(time(0))); for (int i = 0; i < total_instruction; i += 4) { /*产生指令队列*/ s = rand() % 320; a[i] = s + 1; //顺序执行一条指令 a[i + 1] = rand() % (a[i] + 1); //执行前地址指令m' a[i + 2] = a[i + 1] + 1; //顺序执行一条指令 a[i + 3] = rand() % (319 - a[i + 2]) + (a[i + 2] + 1); // 执行后地址指令 if (a[i] > 319 || a[i + 1] > 319 || a[i + 2] > 319 || a[i+3] > 319) { i -= 4; } } for (int i = 0; i < total_instruction; i++) { /*将指令序列变换成页表地址流*/ page[i] = a[i] / 10; offset[i] = a[i] % 10; } for (int i = 4; i <= 32; i++) { /*用户内存工作区从4个页面到32个页面*/ printf("
我们在项目开发过程中,经常会用到导出word表单的功能,在这分享一个导出word的速成方法:
开发步骤:
1.需要准备一个要导出的以.doc结尾的word格式模块,中间最好有填入的数据(我在这就以简单的数字作为填充)。
2.右键将word另存为html格式的文件,用编辑工具将html格式的文件打开。
3.在项目中创建jsp,将html中的代码粘贴到jsp的页面上,方便操作将jsp中的代码格式化,这样jsp的样式就生成了。在这注意,我们在jsp里面引入了页面基本的js和工具包,方法使用el表达式和系统封装的取值方法,将通用的样式代码也一起放入jsp中,并在页面里面写入word的名称和生成word的通用代码
<% String fileName ="导出word测试.doc"; byte[] bt =fileName.getBytes("GB2312"); String unicoStr = new String(bt, "ISO-8859-1"); response.setHeader("Content-disposition","attachment; filename=" +unicoStr); %> <meta http-equiv=Content-Type content="text/html; charset=gb2312"> <meta name=Generator content="Microsoft Word 15 (filtered)"> 4.在页面上找到需要导出word按钮,写一个点击方法,拼写一个url进入我们的后台controller方法中,使用window.open()方法打开。
5.后台返回到指定的jsp,后台方法中可以查询数据,放到resultMap中,返回到页面,在页面用el表达式取值,这样在页面就可以看到响应的值也就是将word模板对应位置的值显示出来,就达到了导出word的功能。
效用:
直方图是多种空域处理技术的基础,直方图操作能有效地用于图像增强。
原理:
对图像进行非线性拉伸,使得变换后的图像直方图分布均匀。
计算步骤:
1)计算原图像的直方图
2)根据直方图计算各灰度出现的概率
3)计算原图象的关于各个灰度级的累积分布函数
4)根据公式求取像素映射关系
5)灰度映射
代码 1:
//不支持OpenCV的ROI void GetHistogram(const Mat &image, int *histogram) { memset(histogram, 0, 256 * sizeof(int)); //计算直方图 int pixelCount = image.cols*image.rows; uchar *imageData = image.data; for (int i = 0; i <= pixelCount - 1; ++i) { int gray = imageData[i]; histogram[gray]++; } } void EqualizeHistogram(const Mat &srcImage, Mat &dstImage) { CV_Assert(srcImage.type() == CV_8UC1); dstImage.create(srcImage.size(), srcImage.type()); // 计算直方图 int histogram[256]; GetHistogram(srcImage, histogram); // 计算分布函数(也就是变换函数f(x)) int numberOfPixel = srcImage.
1.正确用法
无需子类化线程类,通过信号启动定时器。
TestClass::TestClass(QWidget *parent) QWidget(parent) { m_pThread = new QThread(this); m_pTimer = new QTimer(); m_pTimer->moveToThread(m_pThread); m_pTimer->setInterval(1000); connect(m_pThread, SIGNAL(started()), m_pTimer, SLOT(start())); connect(m_pTimer, &QTimer::timeout, this, &ThreadTest::timeOutSlot, Qt::DirectConnection); } 通过moveToThread()方法改变定时器所处的线程,不要给定时器设置父类,否则该函数将不会生效。 在信号槽连接时,我们增加了一个参数——连接类型,先看看该参数可以有哪些值:
Qt::AutoConnection:默认值。如果接收者处于发出信号的线程中,则使用Qt::DirectConnection,否则使用Qt::QueuedConnection,连接类型由发出的信号决定。
Qt::DirectConnection:信号发出后立即调用槽函数,槽函数在发出信号的线程中执行。
Qt::QueuedConnection:当控制权返还给接收者信号的事件循环中时,开始调用槽函数。槽函数在接收者的线程中执行。
代码如下
Jlabel jlabel=new new JLabel(“杨文正”);
jlabel.setVerticalTextPosition(JLabel.TOP);//文字垂直对齐方式向上
jlabel.setHorizontalTextPosition(JLabel.CENTER);//文字水平对齐方式居中
jlabel .setIcon(icon);
目标链接:http://www.pbc.gov.cn/zhengcehuobisi/125207/125213/125440/3876551/index.html
笔者查阅很多资料,大部分人说这样子需要模拟浏览器访问,根本原因是因为cookie不是动态生成的或者不是有效的,方法:
1、chrome-php(一款php模拟chrome或chrome浏览器的插件),注意需要php7
2、直接复制浏览器的cookie
因为笔者用的php5,上述方法1不适用,方法2,还没找到很多办法生成,所以衍生第三种方法,看下图,有没有看出来什么
看到这这个图,然后对比第一张图 的人估计有心中有数了吧,没错就是post请求,用其他请求可以绕过这个坑,估计也是他们的漏洞
Debian小技巧1--常用软件服务配置方法 最近,由于需要开始使用debian系统了,在使用过程会碰见一些经典的配置和操作方法,因此和往常一样记录下自己操作过程,后续将持续更新、优化,一方面以便于自己查阅,另一方面分享给有需要的人学习!
1 娱乐办公 1.1 安装中文输入法
sudo apt update sudo apt install fcitx
sudo apt install fcitx-googlepinyin fcitx-pinyin fcitx-sunpinyin
安装成功后重启机器,系统上可以看到对应输入法,也可以在搜狗上下载对应安装包,dpkg安装后apt install -f重启即可使用搜狗输入法;
后续也可以在System-》Control Center-》COther-》Fcitx Configuration中增删输入法
1.2 install skype download skype https://go.skype.com/skypeforlinux-64.deb
dpkg -i skypeforlinux-64.deb
apt install -f
1.3 install teamviewer
download linux teamviewer https://www.teamviewer.com/en/download/linux/
dpkg -i xxx.deb
apt install -f
1.4 网易云音乐
[云音乐下载网址](https://music.163.com/#/download)
dpkg -i netease-cloud-music_1.2.1_amd64_ubuntu_20190428.deb
注意:最新版本云音乐在debian9上启动会出现缺少插件,导致无法正常启动,但升级到debian10后可以正常启动云音乐。
1.5 安装wechat
目前鹅厂没有提供linux版本wechat,但是可使用开源版本electronic-wechat,解压后即可使用。也可以使用网页版本。
[electronic-wechat github网址](https://github.com/geeeeeeeeek/electronic-wechat)
若运行出现: error while loading shared libraries: libgconf-2.so.4,则apt install libgconf-2-4 即可解决问题。
下载vue-element-admin后,根据官网说明,执行npm install ,报如下错误,执行了三次,都是报下面这样的错误:
npm ERR! Error while executing: npm ERR! C:\Program Files\Git\cmd\git.EXE ls-remote -h -t ssh://git@github.com/s eonim-ryu/Squire.git npm ERR! npm ERR! undefined npm ERR! exited with error code: 128 npm ERR! A complete log of this run can be found in: npm ERR! C:\Users\10190340\AppData\Roaming\npm-cache\_logs\2019-11-21T08_22_ 08_820Z-debug.log 百度了一下,执行:
git config --global url."https://".insteadOf git:// 然后再去npm install 就正常了
分析原因:
因为当你想去克隆一个别人github上的repository时,发现系统不让你动,提示你防火墙禁止对git://的访问,这时候就只能用https://来访问repository。
执行 git config --global url."https://".insteadOf git:// 后,你会发现在你的文件 .gitconfig中会多出一行
1 [url "https://"] 2 insteadOf = git:// 这个时候,你就可以以后不管你在终端进行clone,使用git://,或者http://去访问别人的repository,两种方式都会默认变成http://的形式进行连接并正常的工作了。
前言:
如果CDH集群搭载的是Hadoop3,支持单节点内磁盘的数据均衡,那给集群节点增加磁盘是可行的。若搭载的是Hadoop2.x版本,请注意,2.x版本的Hadoop没有单节点内磁盘均衡的功能,增加的新磁盘可能只会写入很少的数据,不能实际解决集群磁盘空间不足的问题,谨记!
正文:
数据仓库的其中一个作用是保存公司完整的业务或其他数据,在RDB如mysql/Oracle中,数据太多可以进行归档,但数仓不可以.这就导致了数仓中的磁盘占用率越来越高,终归有一天,磁盘不足,那给CDH集群增加磁盘就不能避免.
以下是我实际工作中一次增加磁盘的记录.分享出来希望可以帮到有缘人.
分为以下三个部分描述
1-磁盘热插拔的注意事项
2-具体操作步骤
3-增加磁盘后的效果
注意事项
热插拔只能添加具有空数据目录的磁盘。卸下磁盘不会将数据移出磁盘,这可能会导致数据丢失。不要同时在多个主机上执行热交换。每次更改单独机器的HDFS配置信息,不要更改角色组的信息,即便是统一每台机器都增加同样数量的磁盘且磁盘mount路径都相同 因此次我们是操作增加磁盘,所以注意事项第二条可以忽略掉.
操作步骤
准备阶段:
准备阶段主要是磁盘硬件添加和挂载,这些工作都是IT部门同事帮忙做的,最终给一台机器增加10块磁盘,分别挂载在/u06和/u07 ..../u15目录下.
a-登录CDH主界面,点击HDFS角色
b-点击"实例"选项卡
此时我们可以看到所有DataNode节点的列表,选择要添加磁盘的机器,点击它对应的DATA NODE
点进去后,我们看到的就是这台机器单独的界面,点击配置.
绿色框部分为该机器现有的磁盘挂载目录.只需要点击加号按钮添加磁盘路径即可.添加后截图如下
更改完毕,点击保存更改.此时DN处于使用过期配置的情况,更新配置界面如下
勾选上这两个选项,只重新启动单台DN,对集群影响降低到最小.不会影响正在运行的各种服务.重启过程如下
增加后的效果
重启后,在CDH界面查看该机器信息,发现磁盘容量从4T+变为了25T+,此时登录服务器导磁盘挂载目录下,发现创建好了对应的dfs数据文件夹.
扩容完成.其他应用没有受到影响
以上,为CDH机器增加磁盘的过程,请注意,不要一次性操作多台机器.感谢耐心阅读.
2019-12-06=================================================
在集群页面找到了一个直接更新数据目录的按钮.截图如下
也就是说,在添加完数据存储目录的时候,直接在右上角找到操作->刷新数据目录即可完成数据目录的更改和添加,该步骤执行结果如下
Python题目:学生信息管理系统-高级版(图形界面+MySQL数据库) 使用图形界面显示,选用list、tuple、dictionary或map等数据结构,操作数据库存储X个学生的三门课的成绩(机器学习、Python程序设计、研究生英语),并实现以下功能:
1.添加学生信息
2.修改学生信息
3.删除学生
4.添加学生的成绩
5.修改学生成绩
6.按姓名或者学号查找学生,显示学生信息及三门课的成绩,以及排名
7.学生成绩统计(每门课的平均分、最高分、最低分)
代码里的注释很清楚了,这里不做讲解了,有任何问题可以评论提问。 注意: 数据表不存在则创建表,但自动创建的表是空白的,管理员用户名和密码需要自己在数据库中添加一个(也可以运行文章最后的sql语句),为什么会出现这个问题,因为这是个课堂作业,当时没有设计好,现在懒得再改代码了╮(╯﹏╰)╭.......数据库在代码中(代码里有两处需要修改数据库 用户名、密码 的地方,第66行和第490行),配置为: # 打开数据库连接 连接测试 db = pymysql.connect("localhost", "root", "root", "student") 分别表示 主机名:localhost,用户名:root,密码:root,数据库名:student 下面是界面的截图 管理员操作界面,拥有增删改查功能,甚至拥有排序功能φ(>ω<*) ,快点击标签栏试试
代码: #!/usr/bin/python3 import pymysql from tkinter import ttk import tkinter as tk import tkinter.font as tkFont from tkinter import * # 图形界面库 import tkinter.messagebox as messagebox # 弹窗 class StartPage: def __init__(self, parent_window): parent_window.destroy() # 销毁子界面 self.window = tk.Tk() # 初始框的声明 self.
在下面这个地方设置
<Form.Item> {getFieldDecorator('username', { //这个地方 initialValue:'Tom', rules: [{ required: true, message: '请输入你的用户名!'}], })( <Input prefix={<Icon type="user" style={{ color: 'rgba(0,0,0,.25)' }} />} placeholder="Username" />, )} </Form.Item> 注意antd表单设置默认值位置
方法二setFieldsValue
设置一组输入控件的值(注意:不要在 componentWillReceiveProps 内使用,否则会导致死循环,原因)
(https://github.com/ant-design/ant-design/issues/2985)
this.props.form.setFieldsValue({ username:"我是初始值" });
转载:https://blog.csdn.net/aiwusheng/article/details/103125117
Android Q 适配指南
官方文档:
https://developer.android.com/about/versions/10
在Android 10开始版本中,官方的改动较大,相应的开发者适配成本还是很高的。
这里按照2019.11.11 google android q workshop流程,大概说明一下Android Q适配需要注意的内容。虽然是大概介绍,但应该是目前最全的适配攻略了…
非SDK 接口
设备ID
外部存储
权限
新功能——夜间模式
一、非SDK接口
官方文档:针对非 SDK 接口的限制
官方从 Android 9(API 级别 28)开始,对应用使用的非 SDK 接口实施了限制。
如果你的APP通过引用非 SDK 接口或尝试使用反射或 JNI 来获取句柄,这些限制就会起作用。官方给出的解释是为了提升用户体验、降低应用崩溃风险。
1.1、非SDK接口检测工具
官方给出了一个检测工具,下载地址:veridex
veridex使用方法:
appcompat.sh --dex-file=apk.apk
1
1.2、blacklist、greylist、greylist-max-o、greylist-max-p含义
以上截图中,blacklist、greylist、greylist-max-o、greylist-max-p含义如下:
blacklist 黑名单:禁止使用的非SDK接口,运行时直接Crash(因此必须解决)
greylist 灰名单:即当前版本仍能使用的非SDK接口,但在下一版本中可能变成被限制的非SDK接口
greylist-max-o: 在targetSDK<=O中能使用,但是在targetSDK>=P中被禁止使用的非SDK接口
greylist-max-p: 在targetSDK<=P中能使用,但是在targetSDK>=Q中被禁止使用的非SDK接口
如果觉得我没有说清楚,可以看以下 2019.11.11 google android q workshop PPT 截图
1.3、Android Q 加固 与 热修复
关于加固与热修复,官方也提供了相应的API
加固
热修复
注:
sudo apt-get update出现解析错误,如下
fkuner@data3:~$ sudo apt-get update Err:1 https://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic InRelease Temporary failure resolving 'mirrors.tuna.tsinghua.edu.cn' 0% [Working]^C 解决方案:
fkuner@data3:~$ service networking restart ==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units === Authentication is required to restart 'networking.service'. Authenticating as: Fan Kun (fkuner) Password: ==== AUTHENTICATION COMPLETE === fkuner@data3:~$ sudo apt-get clean fkuner@data3:~$ sudo apt-get upgrade Reading package lists... Done Building dependency tree Reading state information... Done Calculating upgrade... Done 0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
一、算法介绍 关于本算法的原理介绍在之前的博客中已经提到过了,这边就不细说了。详情请点击此处 计算智能-遗传算法.
上一博客中讲述的遗传算法是求tsp问题的最短路径,但是在上一种解法,我们是对函数进行优化,属于局部的优化,该算法找到的哈密顿回路很可能是局部的最优解,本次遗传算法要进行的是一种全局优化,尽可能的找到符合条件的哈密顿回路。
二、算法主要代码 1、cross.m function [A,B]=cross(A,B) L=length(A); if L<10 W=L; elseif ((L/10)-floor(L/10))>=rand&&L>10 W=ceil(L/10)+8; else W=floor(L/10)+8; end %%W为需要交叉的位数 p=unidrnd(L-W+1);%随机产生一个交叉位置 %fprintf('p=%d ',p);%交叉位置 for i=1:W x=find(A==B(1,p+i-1)); y=find(B==A(1,p+i-1)); [A(1,p+i-1),B(1,p+i-1)]=exchange(A(1,p+i-1),B(1,p+i-1)); [A(1,x),B(1,y)]=exchange(A(1,x),B(1,y)); end end 该函数进行交叉位置的判断,交换城市时,观察城市序列中是否会包含重复城市;若重复了,则增加一个交换操作。
2、exchange.m %对调函数 exchange.m function [x,y]=exchange(x,y) temp=x; x=y; y=temp; end 该函数实现了两个城市的坐标互换
3、fit.m function fitness=fit(len,m,maxlen,minlen) fitness=len; for i=1:length(len) fitness(i,1)=(1-(len(i,1)-minlen)/(maxlen-minlen+0.0001)).^m; end 该函数为适应度函数,每次迭代都要计算每个染色体在本种群内部的优先级别,类似归一化参数。越大越好!
4、Mutation.m function a=Mutation(A) index1=0;index2=0; nnper=randperm(size(A,2)); index1=nnper(1); index2=nnper(2); %fprintf('index1=%d ',index1); %fprintf('index2=%d ',index2); temp=0; temp=A(index1); A(index1)=A(index2); A(index2)=temp; a=A; end 该函数为变异函数
5、 mylength.
出错是因为没有找到入口类main() 修改pom.xml文件夹
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>cn.urbanwall.start.startThread</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin>
欢迎关注”生信修炼手册”!
LDSC分析基于已有的GWAS结果,即gwas summary数据,可以评估性状的遗传力,分析两个性状间的遗传相似度。相比GREML, 其运算速度快,更适用于处理大样本量的数据。
LD hub是一个网页版的工具,可以进行LDSC分析。同时也从各种开源数据库中收集整理了gwas summmary数据,分析了多种性状的遗传力和遗传相似度,对应的文献发表在Bioinformatics上,链接如下
https://academic.oup.com/bioinformatics/article/33/2/272/2525718
官网如下
http://ldsc.broadinstitute.org/
这个网站需要登录谷歌账号才可以使用,包含了一下3大功能模块
1. Test Center 这个模块用于上传自己的gwas结果,进行LDSC分析。首先上传数据
然后选择进行遗传相似度分析的性状
最后提交即可。
2. Lookup Center 检索数据库中已有的分析结果,包含了以下两种结果
SNP Heritability results
Genetic correlation results
单一性状SNP遗传力分析的结果示意如下
H2表示SNP遗传力,SE_H2表示SNP遗传力的标准误,Chi2表示平均的卡方值,Intercept表示回归方程的截距。
两两性状间遗传相似度的分析结果示意如下
rg表示遗传相似度genetic correlation,se表示遗传相似度的标准误。
3. GWAShare Center 该模块有以下两个功能
查看已有的GWAS分析结果
共享自己的GWAS分析结果
通过该网站,可以方便地进行LDSC的分析。
·end·
—如果喜欢,快分享给你的朋友们吧—
往期精彩
自己动手进行逻辑回归,你也可以!
GWAS大家都知道,Gene-Based GWAS你了解吗?
3步搞定GWAS中的Gene Set Analysis
你听说过Epistasis吗?
GWAS中的Gene-Gene Interactions如何分析?看这里
终于搞清楚了Lasso回归和Ridge回归的区别
odd ratio置信区间的计算,你学会了吗?
多元回归分析存在多重共线性了怎么办?
基因型与表型的交互作用如何分析,多元回归来搞定
曼哈顿图就够了吗?你还需要LocusZoom
GWAS做完了,下一步做什么?
GWAS meta分析
GWAS样本量不够怎么办,meta分析了解一下
你没看错,搞定GWAS meta分析只需一行代码!
meta分析的森林图不会画?看这里
GWAMA:GWAS meta-analysis的又一利器
点击鼠标即可完成GWAS meta分析,任何人都可以!
用R进行gwas meta分析,原来如此简单
什么是重定向? 举个例子来说,重定向就是一个客户向客服打电话咨询某某技术问题应该怎么处理,但客服也不会,于是告诉了客户一个号码,说,你打这个电话,我们技术部的人会专门给你解答,然后客户打了技术部电话,这就是重定向。
故事解说:
客服人员:先生,你好!这里是某某公司,请问,有什么能帮助你的嘛?
客户:哦,对,对对,,,,我前几天在你们买了一个叫某某产品,它怎么有一个功能无法操作呢
客服人员:好的,先生,,,,,
客户和客服聊了好一会,客服人员:先生,是这样的,你的这个问题我无法解决,我给你一个电话号码1717771,这是我们公司技术人员的电话,他会专门为你解答和解决这个技术问题
然后客户挂断客服电话后,拨打了1717771,说:你好!我我前几天在你们买了一个叫某某产品,它怎么有一个功能无法操作呢
技术人员:是这样,你一下某某键,,,,,
这个里面的客户首先给客服打了个电话,然后给技术人员又打了个电话,这就重定向
图片解说:
完善日期:2021/11/25 ,如下:
什么是转发 这里小编还是理解上面的解说方式来给大家解说!!!!!
看完上面你理解了什么是重定向,你会发现**转发**比**重定向**更好理解
举一个事例来说明:
转发就是用户向客服打电话,咨询某某东西该怎么弄,但客服不会,客服将通话转接给了技术客服,这个过程就叫做“转发”。
故事解说:
客服人员:先生,你好!这里是某某客服中心,请问,有什么能帮助你的嘛?
客户:我前几天在你们买了一个叫某某产品,它怎么有一个功能无法操作呢
客服人员:好的,先生,我给你转接我们的技术人员(客服无法解决,转给了技术客服)
客户:好的
客服人员:请稍等
转接成功
技术客服:你好!先生,我是你的技术客服,有什么能帮你的嘛
客户:我前几天在你们买了一个叫某某产品,它怎么有一个功能无法操作呢
技术客服:好的,是这样,你先按一下某某键,,,,,然后,,,,,
,,,,,
客户:好了,谢谢
这个里面的客户只打了一个电话给客服,而客服将电话转给技术客服,这个过程叫做“转发”。
图片解说
1、在当前要跳转的地方加<router-link></router-link>。其中:to中的'name'参数是在路由注册的页面。 <router-link :to="{name:'outdata',params:{classifyId: item.id}}">{{item.name}}</router-link> 2、在跳转页面接收参数(注意:使用this.classify接收参数前,要在dataForm中先声明)
//在created钩子函数中进行接收 created () { this.classify = this.$route.params.classifyId },
本次案例是通过ArcGIS Pro提供的时空立方体展示地理位置相关的事件。利用时空立方体的工具把空间和时间维度展示不同数据在不同的角度展示热点信息。
第一步,加载ViolentCrime2014到ArcGIS Pro中,然后在分析面板中调出工具箱—在时空模式挖掘工具箱下---通过聚合点创建时空立方体
利用工具生成nc文件。
计算趋势。
以三维的形式显示。生成的三维时空立方体加载到地图中,并切换二维地图到三位场景模式。
在VisualizeSpaceTimeCube3D图层中右键—属性中,在时间和范围属性属性选项卡中开启范围和时间进度条。如图
这样就可以通过时间维度或者是数值范围来筛选时空立方体显示内容
不同时期的土地利用矢量数据,分析其图形及属性变化
调出工具箱。
使用GP工具联合Union。
图层右键打开属性表,新建一个短整型字段。
双击字段类型,即可选择。
然后点击保存。
使用字段计算器,比较两个字段的内容。如果属性没变,就赋值为1,如果属性变化了就赋值为0。
Python代码如下:
Pre-Logic Script Code中写:
def isSame(x, y):
fieldA = str(x)
fieldB = str(y)
if fieldA == fieldB:
return 1
else:
return 0
变化中写:(比较的是Class_Name和Class_Name1两个字段)
isSame( !Class_Name! , !Class_Name_1! )
结果如下:
如果想知道变化的图斑是从什么类型转为什么类型,可以新建一个文本型字段,将土地利用类型的两个字段赋值过去。
表达式:!Class_Name! + '->' + !Class_Name_1!
2、如何统计不同土地利用类型的面积?
结果是一张统计表,如下:
3、如何统计不同区域各类土地利用类型的面积?
可以使用GP工具Tabulate Intersection(交集制表)进行统计。
结果如下:
4、如何将行政区划的信息追加到土地利用数据中?
有一份行政区划矢量数据,希望知道每个图斑隶属于哪个行政区划。数据可以是行政区域,也可以是坡度及其他数据。
一个图斑可能会跨区域,如果图斑需要切分,一部分属于行政区划A,另一部分属于B,可以使用GP工具Intersect(相交),参数中的JoinAttribute,选择All。结果如下:
如果不希望图斑被切分,在属性表中记录属于A、B、C区,可以使用GP工具Spatial Join(空间连接)。选择区域名字段,合并规则选择Join,连接符可以设置逗号,其他设置默认就可以了。
结果如下:
5、布局出图
先符号化1990年数据,再对2000年数据设置相同的渲染:
插入布局:
插入地图,选择后,在布局上绘制:
插入图例、指北针、比例尺、图名。
修改图例:
1)设置显示内容。不显示图层名、标题。
2)设置图例中的文字、符号大小
3)设置不显示All other Value。到地图中,不勾选第一项。
4)添加图例标题。
如果要调整地图的大小,需要先锁定MapFrame,可以使用鼠标进行缩放。
调整后,再关闭锁定。
三维数据浏览 浏览倾斜摄影I3S数据,点击添加数据,找到“demo.slpk”,点击确定 视线、视域分析 分析菜单中交互式分析
选择视线分析
选择视域分析
案例十二:三维服务发布 打包工具上传slpk数据包 发布数据服务
前言 以前制作一个Python窗体界面,我都是用GUI窗口视窗设计的模块Tkinter一点一点敲出来的,今天朋友问我有没有Python窗体的设计工具,“用鼠标拖拖”就能完成窗体设计,我查了查相关资料,果然有一款好用的工具——Qt Designer。
1.安装Qt Designer 这里需要安装两个东西:PyQt5和PyQt5-tools:
安装PyQt5:打开CMD或者PowerShell,在命令窗中输入 pip install PyQt5 执行结果如下:
安装PyQt5-tools:打开CMD或者PowerShell,在命令窗中输入 pip install PyQt5-tools 执行结果如下:
2.配置开发工具 安装完Qt Designer后,我们利用PyCharm进行界面开发,下面进行Qt开发工具的配置。
在PyCharm中依次打开:File→Settings 弹出Settings对话框,如下图
然后按下图的4个步骤,打开Create Tools对话窗:
这里需要配置两个:
(1)配置QTDesigner,用来打开QT可视化开发工具
如下图,分别在Name、Program、Working dirctory填入如下信息:
Name:QTDesignerProgram:D:\ProgramSoftware\Anaconda3\Lib\site-packages\pyqt5_tools\Qt\bin\designer.exe
注意:该路径为你Python安装路径下Lib\site-packages\pyqt5_tools文件夹里Working dirctory:$FileDir$ (2)配置PyUIC,用来将Qt Designer开发工具生成的.ui文件转换为.py文件
如下图,分别在Name、Program、Arguments、Working dirctory填入如下信息:
Name:PyUICProgram:D:\ProgramSoftware\Anaconda3\Scripts\pyuic5.exe
注意:该路径为你Python安装路径下Scripts文件夹里Arguments:$FileName$ -o $FileNameWithoutExtension$.pyWorking dirctory:$FileDir$ 至此,安装和配置过程全部结束,下面介绍简单的使用教程。
3.使用Qt Designer设计界面 在PyCharm中创建一个项目,然后点击“Tools”--“External Tools”--“QTDesinger”打开QT Desinger,如下图: 在New Form对话框里选择Widget模板,然后点击创建: 然后就会出现Qt Designer主界面,向Form中分别拖入一个“Push Button”和一个“Text Edit”,如下图: 指定点击事件及其响应函数
在工具栏点击 这个图标 ,然后光标移动到“PushButton”按钮上,鼠标左键 点击 “PushButton”按钮 不要松开,拖动光标 到 按钮旁边的任一位置后 再松开鼠标左键 随后就出现了如下界面,在对话框左侧选中“clicked()”,右侧点击“Edit” 然后点击绿色“+”按钮,指定click事件的响应函数,名称随意,比如我这里命名为“pushButton_click()”
(我们这里只是指定事件与响应函数的关联关系,函数是还没实现的,后边我们自行实现) 最后,将设计的界面保存。 4.使用PyUIC将文件转成python代码 关闭QT Designer回到PyCharm,查看项目,可以看到只有刚才保存的PyQT_Form.ui文件而且该文件在PyCharm是打不开的,我们需要将这个文件转成.py代码才能使用。
选中“PyQT_Form”,在其上点击鼠标右键,到“External Tools”中点击“PyUIC” 之后再看项目文件,就可以看到多了一个“PyQT_Form.
导读:在开始使用TensorFlow之前,必须了解它背后的理念。该库很大程度上基于计算图的概念,除非了解它们是如何工作的,否则无法理解如何使用该库。本文将简要介绍计算图,并展示如何使用TensorFlow实现简单计算。
作者:翁贝托·米凯卢奇(Umberto Michelucci)
来源:大数据DT(ID:bigdatadt)
01 计算图
要了解TensorFlow的工作原理,必须了解计算图是什么。计算图是一幅图,其中每个节点对应于一个操作或一个变量。变量可以将其值输入操作,操作可以将其结果输入其他操作。
通常,节点被绘制为圆圈,其内部包含变量名或操作,当一个节点的值是另一个节点的输入时,箭头从一个节点指向另一个节点。可以存在的最简单的图是只有单个节点的图,节点中只有一个变量。(请记住,节点可以是变量或操作。)图1-16中的图只是计算变量x的值。
▲图1-16 我们可以构建的最简单的图,它表示一个简单的变量
现在让我们考虑稍微复杂的图,例如两个变量x和y之和(z=x+y),如图1-17所示。
▲图1-17 两个变量之和的基本计算图
图1-17左侧的节点(圈里有x和y的节点)是变量,而较大的节点表示两个变量之和。箭头表示两个变量x和y是第三个节点的输入。应该以拓扑顺序读取(和计算)图,这意味着你应该按照箭头指示的顺序来计算不同的节点。箭头还会告诉你节点之间的依赖关系。要计算z,首先必须计算x和y。也可以说执行求和的节点依赖于输入节点。
要理解的一个重要方面是,这样的图仅定义了对两个输入值(在这里为x和y)执行什么操作(在这里为求和)以获得结果(在这里为z)。它基本上定义了“如何”。你必须为x和y这两个输入都赋值,才能执行求和以获得z。只有在计算了所有的节点后,图才会显示结果。
注释:在本书中,图的“构造”阶段是指在定义每个节点正在做什么时,“计算”阶段是指当我们实际计算相关操作时。
这是需要了解的一个非常重要的方面。请注意,输入变量不一定是实数,它们可以是矩阵、向量等。(本书中主要使用矩阵。)在图1-18中可以找到稍微复杂的示例,即给定三个输入量x、y和A,使用图计算A(x+y)的值。
▲图1-18 给定三个输入量x、y和A,计算A(x+y)的值的计算图
可以通过为输入节点(在本例中为x、y和A)赋值来计算此图,并通过图计算节点。例如,如果采用图1-18中的图并赋值x=1、y=3和A=5,将得到结果b=20(如图1-19所示)。
▲图1-19 要计算图1-18中的图,必须为输入节点x、y和A赋值,然后通过图计算节点
神经网络基本上是一个非常复杂的计算图,其中每个神经元由图中的几个节点组成,这些节点将它们的输出馈送到一定数量的其他神经元,直到到达某个输出。
TensorFlow可以帮助你非常轻松地构建非常复杂的计算图。通过构造,可以将评估计算与构造进行分离。(请记住,要计算结果,必须赋值并计算所有节点。)
注释:请记住,TensorFlow首先构建一个计算图(在所谓的构造阶段),但不会自动计算它。该库将两个步骤分开,以便使用不同的输入多次计算图形。
02 张量
TensorFlow处理的基本数据单元是张量(Tensor),它包含在TensorFlow这个单词中。张量仅仅是一个形为n维数组的基本类型(例如,浮点数)的集合。以下是张量的一些示例(包括相关的Python定义):
1→一个纯量
[1,2,3]→一个向量
[[1,2,3], [4,5,6]]→一个矩阵或二维数组
张量具有静态类型和动态维度。在计算它时,不能更改其类型,但可以在计算之前动态更改维度。(基本上,声明张量时可以不指定维度,TensorFlow将根据输入值推断维度。)通常,用张量的阶(rank)来表示张量的维度数(纯量的阶可以认为是0)。表1-1可以帮助理解张量的不同阶。
阶
数学实体
Python例子
0
纯量(例如,长度或重量)
L=30
1
张量(例如,二维平面中物体的速度)
S=[10.2,12.6]
2
矩阵
M=[[23.2,44.2],[12.2,55.6]]
3
3D矩阵(带有三个维度)
C=[[[1],[2]],[[3],[4]],[[5],[6]]]
▲表1-1 阶为0、1、2和3的张量示例
假设你使用语句import TensorFlow as tf导入TensorFlow,则基本对象(张量)是类tf.tensor。tf.tensor有两个属性:
数据类型 (例如,float32)
形状(例如,[2,3]表示这是一个2行3列的张量)
一个重要的方面是张量的每个元素总是具有相同的数据类型,而形状不需要在声明时定义。主要张量类型(还有更多)有:
tf.Variable
tf.constant
tf.placeholder
tf.constant和tf.placeholder值在单个会话运行期间(稍后会详细介绍)是不可变的。一旦它们有了值,就不会改变。例如,tf.placeholder可以包含要用于训练神经网络的数据集,一旦赋值,它就不会在计算阶段发生变化。
tf.Variable可以包含神经网络的权重,它们会在训练期间改变,以便为特定问题找到最佳值。最后,tf.constant永远不会改变。我将在下一节展示如何使用这三种不同类型的张量,以及在开发模型时应该考虑哪些方面。
03 创建和运行计算图
下面开始使用TensorFlow来创建计算图。
注释:请记住,我们始终将构建阶段(定义图应该做什么)与它的计算阶段(执行计算)分开。TensorFlow遵循相同的理念:首先构建一个图形,然后进行计算。
考虑非常简单的事情:对两个张量求和,即
x1+x2
前言 文章标识 (?)标识为未更新详细信息或未了解具体使用的内容
(?+文字)标识为对于使用存在疑问的部分
动画系统 Animation动画界面(更新中) 编辑器基本设置 【左窗口】 [Preview] 预览
(红色圆点)录制按钮,开启录制模式时根据修改自动添加关键帧
[Animations] 动画切换
[Samples] 关键帧
(Add Keyframe)添加关键帧
(Add Event)添加事件
[Dopesheet] 关键帧模式
[Curves] 曲线模式,可以控制动画播放中物件属性的变化速度
(1)曲线类型选择
-Clamped Auto 根据key生成平滑曲线的默认切线类型
-Auto 旧版本默认切线类型
-Free Smooth 可手动调节key两侧切线斜率(为保证两侧曲线平滑衔接,左右两侧切线固定共线)
-Flat 出入切线水平
-Broken左右两侧切线不共线(设置Broken后可单独设置两侧切线类型)
(2)Tangent选项
(可以调节左右切线或一起调节)
-Free 自由切线(会开启Broken)
-Linear 线性曲线(?)
-Constant 瞬间变化
-Weighted (?)
【右窗口】 【Inspector窗口】
[Loop Time] 循环播放控制,勾选并开始游戏后,动画效果将循环播放
[Loop Pose] 循环姿势(?)
[Cycle Offset](?)
Animator动画状态机(更新中) 常规: 【Inspector界面】 [Controller] 指定一个动画状态机给该游戏对象
[Avatar] 选定游戏对象的骨骼映射
[Apply Root Motion] (?)
[Updata Mode] (?)
据最新统计数据显示,2019年 NB-IoT用户数已经突破6000万,其中NB-IoT智能水表用户数均超过1000万大关,月增量已经超过2G。 随着物联网的发展,我国在大力推进智慧城市的建设。智慧水务作为智慧城市的重要组成部分,已成为中国水务物联升级的重要方向。根据《水表行业"十三五"发展规划纲要》显示,预计"十三五"期间我国将新增智能水表超过1.5亿台,对应产业规模超过400亿元。 可见,NB-IoT智能水表前景可期,并将在工业互联网市场中占据重要的地位。 我国城市水务有什么问题? 供水建设中漏损现象严重:在城市供水建设中,最常见的问题就是漏损现象,每年损失在百亿级别。由于管网漏损导致的供水事故,水量损失,水质破坏等是管网系统运行的重要难点。 人工抄表效率低:截至目前,大多数城市还是以使用传统水表为主。人工入户抄表存在成功率低,误差较大,用户投诉多的问题,也给供水部门带来很大的经济负担。 内涝不断,排水系统不完善:针对城市内涝的问题,早在2012年我们就提出了"海绵城市"的水资源管理策略和方法,虽然取得了一些成效,但"海绵城市" 的建设和效果都不够理想。我们城市的排水系统管理平台依旧不够系统和科学化。 NB-IoT智能水表的技术优势 随着NB-IoT窄带物联网技术的出现,将能从根本上改变这一局面。NB-IoT具有高安全性、广覆盖、大连接、低功耗和低成本等特点,拥有众多优势:  基于紫光展锐NB-loT解决方案的智能水表 降低抄表成本,提高抄表准确率:NB-IoT智能水表可以大大提高抄表的准确性和成功率,不仅为水务部门大范围降低人力物力成本,提高效率及管理能力,也提高了用户体验。 实时信息回传,合理阶梯计价:NB-IoT智能水表可以实时收集数据并回传到服务平台,平台会基于数据的收集和分析,做出相应的预测然后进行合理水资源调配。也有助于阶梯计价的精准实施。 科学表务管理,及时告知异常用量:除基本信息读取外,NB-IoT智能水表还可以基于收集到的数据,进行进一步分析,得出不同群体的用水习惯,在发现用水异常情况的时候,及时通知到用户,促进用水效率、节约用水。 可拓展更广水务业务:NB-IoT的技术在满足智能水表业务的同时,也可拓展到更多的水务业务中去,如管网监测,漏损监测,水质、水压、温度监测等相关业务。 展锐的NB-IoT解决方案,拥有独特的优势,率先集成蓝牙功能。通过蓝牙+NB-IoT的双物联通道,确保智能水表实现更快更稳定的连接,即使在信号差的情况下,仍可以保障正常运行。 功耗更低:ePSM 唤醒发送耗时小,弱信号下小于 4s 集成蓝牙:方便本地抄表、维护,减少设备拆装故障 支持MOTA :方便远程维护 MCU 程序,降低现场维护成本 内置eSIM :内置 SIM 卡,可节省 SIM 卡座,减少 PCB 尺寸,降低整体成本 更小尺寸:帮助客户减小PCB 尺寸,设计可以更紧凑,产品更小巧、轻便 快速响应:可以快速实现客户定制化需求 网络优选:内部集成网络优选功能,如果基站饱和,可以自动切换基站,网络适应性更强 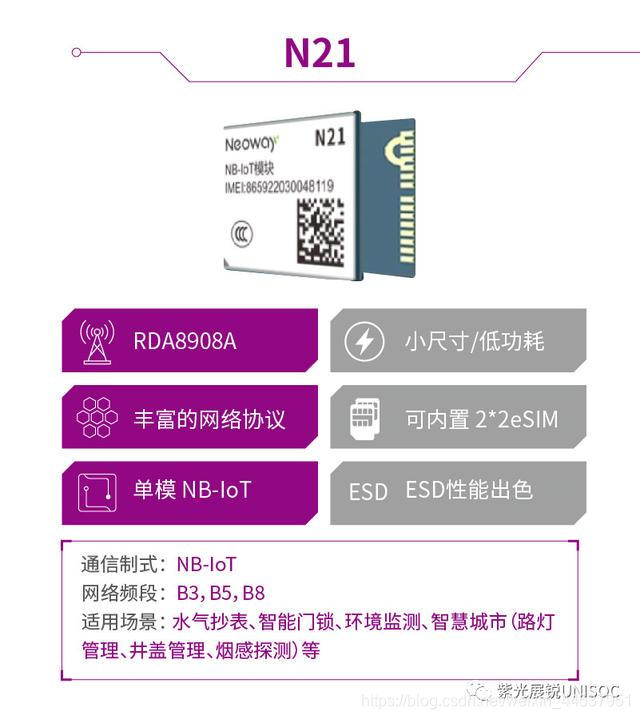 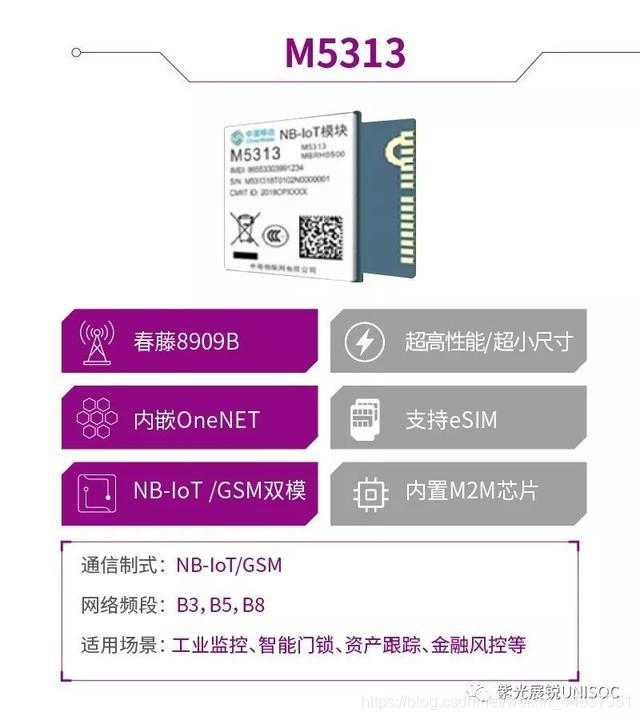 目前搭载展锐NB-IoT解决方案的智能水表已落地天津。2019年,天津市政府、天津水务集团、天津燃气集团联手开展了物联网表计改造项目,预计将在2年内将数百万传统水燃表改造为NB-IoT智能表,是目前智慧抄表行业中的标杆物联网项目。目前已落地的NB-IoT智能表计中有多款搭载展锐芯的NB-IoT模组,如有方的N21、中移物联M5313. 截止第三季度,改造项目已针对天津8个居民小区进行NB网络覆盖和表计功能排查工作,使智能水表上线率提升至98%。 紫光展锐NB-IoT解决方案
春藤8908A是一款超低功耗、超大容量、超强覆盖的NB-IoT芯片解决方案,采用40nm工艺,在定点场景和移动场景下的业务成功率、业务时延、功耗等关键性能上表现优异。春藤8908A已在海外获得了欧洲最大电信运营商德国电信及南非最大电信运营商MTN的全球认证。 春藤8909B是业界第一款集成NB-IoT+GSM双模物联网单芯片解决方案,拥有卓越的性能,在静止状态业务时延更低、业务响应速度更快,低速移动状态业务稳定性更强,以及高速移动状态的业务成功率更高,各项指标上均明显高于同类产品。
002、Java代码到底是如何运行起来的?
为了跟上快速变化的技术,软件的演化是不可避免的,也是至关重要的。根据Github最新的Octoverse报告,在过去的一年中,有1000万新开发人员加入了这个社区,为超过4400万个代码库做出了贡献,开发人员社区出现了迅猛的增长。
在本文中,我们按Github上的贡献者列出了10个增长最快的开源项目,名单按字母顺序排列。
1. ASP.NET Core
ASP.NET Core是一个开源的跨平台。NET框架,用于构建现代化的基于云的、互联网连接的应用程序,如web应用程序、物联网应用程序和移动后端。这个框架的增长速度处于首位,比前几年增长了346%。
该框架由微软开发,实现了服务器和客户端之间的双向实时通信。借助于ASP.NET Core,用户可以构建web应用和服务、物联网应用和移动后端,使用Windows、macOS和Linux上的开发工具,部署到云端或内部。ASP.NET通过工具和库扩展了.NET平台,如网页模板语法、常用web模式库、认证系统,以及更多的可用于构建web应用程序的东西。
2. AWS Amplify
AWS Amplify是一个JavaScript库,用于前端和移动开发人员构建支持云的应用程序。这个库的增长率为188%,并在Octoverse报告中获得了第五的位置。它提供了一个声明性的、易于使用的接口,可以跨不同类别的云操作,与任何基于JavaScript的前端工作流都很好地配合,并为移动开发人员提供了React Native。
3. Cypress
Cypress是为现代web构建的下一代前端测试工具。此工具允许用户编写端到端测试、集成测试和单元测试。Cypress由一个免费的、开源的、本地安装的测试运行程序和一个用于记录测试的仪表板服务组成。它还包括许多功能,如自动等待命令、验证和控制函数、服务器的行为、直接从熟悉的开发人员工具进行调试等。
4. Flutter
Flutter是谷歌开发的软件开发工具包(SDK),用于从单个代码库中为移动、web和桌面快速构建直观的用户体验。它于去年12月发布,并在Github的Octoverse报告中占据第二位的位置。它主要是针对在Android和iOS上运行的2D移动应用程序而优化的。这个便携式UI工具包加速了移动应用程序的开发,降低了跨平台的应用程序生产的成本和复杂性。
5. Gatsby
Gatsby是一个基于React的免费开源框架。这是一个现代的网络框架,帮助开发人员快速建立直观的网站和应用程序。Gatsby自动化了代码拆分、图像优化、关键样式内联、延迟加载、预取资源等,以确保网站快速运行。在这个框架的帮助下,开发人员可以创建高质量的、动态的web应用程序,从博客到电子商务网站到用户仪表盘,构建统一的工作流,以及其他类似的功能。
6. Helm Charts
Helm是一个管理Charts的工具,其中Charts是预先配置的Kubernetes资源包。在Github贡献者增长最快的开源项目中,该代码库以184%的增长率稳居第六位。GitHub代码库包含在Chart代码库中发布的打包和版本化charts的源。此代码库的目的是提供一个维护和贡献正式Charts的地方,并提供用于管理将Chart发布到Chart Repository中的CI流程。
7. Istio
Istio是一个开放平台,它提供了一种统一的方式来集成微服务、管理跨微服务的流量、实施策略和聚合遥测数据。该平台以194%的增长率稳居第四位,目前支持基于Kubernetes和Consul的环境。
它由六个组件组成:envoy(每个微服务的sidecar代理处理集群中的服务和服务到外部服务之间的入口/出口业务)、mixer(由代理和微服务所使用的中心组件)、pilot(负责在运行时配置代理的组件)、citadel(负责证书颁发和轮换的中心化组件)、citadel agent(负责证书颁发和轮换的每个节点都有的组件)和galley(用于在Istio中验证、摄取、聚合、转换和分发配置的中心组件)。
8. Microsoft Open Source Code of Conduct
Microsoft Open Source Code of Conduct增长了264%,并成为Github贡献者增长最快的开源项目的第三位。这个代码库基本上是微软官方Azure DevOps文档的所在地。
9. Proton
Proton是一个兼容基于Wine的Steam Play和其他附件组件的工具。这个工具在增长最快的开源项目中排第七,并与Steam客户端一起使用——允许Windows独有的游戏在Linux操作系统上运行。
10. Storybook
Storybook是一个开源工具,用于开发独立于React、Vue和Angular的UI组件。它是一个面向UI组件的开发环境,允许用户浏览组件库,查看每个组件的不同状态,并交互式地开发和测试组件。Github的Octoverse报告显示,该工具增长了178%。
原文链接:
https://analyticsindiamag.com/top-10-fastest-growing-open-source-projects-by-github-contributors/
获取更多开源云技术资讯&大咖交流&免费活动,欢迎添加开源云中文社区小助手,备注开源云!
(长按识别二维码添加)
一、limit用法 SELECT * FROM t LIMIT 10,10;
第一个参数指定第一个返回记录行的偏移量第二个参数指定返回记录行的最大数目如果只给定一个参数:它表示返回最大的记录行数目第二个参数为 -1 表示检索从某一个偏移量到记录集的结束所有的记录行初始记录行的偏移量是 0(而不是 1) 所以上面SQL的含义是查询数据库第10条到第20条数据
对于小的偏移量,直接使用limit来查询没有什么问题,但随着数据量的增大,越往后分页,limit语句的偏移量就会越大,速度也会明显变慢
二、limit在大数据量下的表现 参考网上一个案例:
表说明:
表名:order,订单表字段情况:该表一共37个字段,不包含text等大型数据,最大为varchar(500),id字段为索引,且为递增数据量:5709294 select * from order_table where userId = 3 order by id limit 10000,10;
三次查询时间分别为:
3040 ms3063 ms3018 ms 针对这种查询方式,下面测试查询记录量对时间的影响:
select * from order_table where userId = 3 order by id limit 10000,1;
select * from order_table where userId = 3 order by id limit 10000,10;
select * from order_table where userId = 3 order by id limit 10000,100;
下列所有的符号中,如果没有特殊说明,则n表示集合中所有元素的个数、r表示所取的元素个数,k表示种类数。
第一章:
绪论,介绍了为什么要研究组合数学,以及组合数学的三个研究内容。
第二章:
鸽巢原理:把N+1个鸽子放到N个巢里面,则至少有一个巢里面有两只鸽子。
推论:如果把N个物体放到K个盒子当中,则至少有一个盒子里面有N/k取上界个物体。
例子:Ramsey数
第三章:
1、集合的排列:P(n,r)、集合的循环排列:P(n,r)/r、集合的组合:C(n,r)
2、多重集合的排列:1、每个元素有无限多个,取r个:K^r——有K种元素,也就是说每个位置有K种选择,取r个。
2、每个元素是有限个,全排列数:N!/N1!N2!...Nk!。
3、每个元素是有限个,取r个的排列数:用后面章节的生成函数(指数生成函数)求解
3、多重集合的组合:1、每个元素有无限多个:C(r+k-1,r)
2、每个元素是有限个:用后面章节的容斥原理来求,用容斥原理将有限个转换成无限多个(最多取多少个转换成至少取多少个)。
第四章:
1、活动数:给数标一个方向,如果这个数比他所指方向的那个数大,那么这个数就叫做活动数。
2、生成排列(全排列):活动数法,1、找到一个最大的活动数,2、将这个数与他所指方向的那个数互换位置,3、将所有比他大的数的方向转换。重复这三步,直到所有的数都不是活动数。
3、逆序数:给定一个数的序列,如果Xi>Xj且i<j。则称这两个数为一个逆序对,用ai表示数字i的逆序对的个数,也叫逆序数。
算法1:通过相对位置和从大的数到小的数的逆序数来确定具体序列:i前面有ai个逆序对。
算法2:通过从小的数到大的数逆序数来直接确定具体序列:i直接放在第ai+1个空位上。
4、生成组合:通过2进制的+1来生成所有的组合。
5、生成r-组合:按字典序来排序,的直接后继是.直接前驱是。其中后继的不与原序列任何一个数重复,前驱的也是如此。
6、生成r-排列:先生成r-组合,然后对每个组合进行全排列。
第六章:
1、容斥原理:S中不具有P1,P2...Pn任何一个属性的元素有如下多个:
具备任何一种属性中的其中一种的元素有如下多个:
2、错位排列:给定n个数,从1到n,将这n个数排列起来,若任何一个数都不在他的自然位置上,则称这个排列是一个错位排列。例如312,因为1不在第一个位置,2不在第二个位置,3不在第三个位置,所以这是一个错位排列。
我们定义为n个数的错位排列数,则根据容斥原理可得为:
3、带禁止位置的排列:给定N个位置和N个集合,每个位置对应一个集合,带禁止位置的排列就是指,该位置对应的集合中的元素不能在该位置上。当对应的集合中的元素就只有该位置时,带禁止位置的排列就等价于错位排列。
求带禁止位置的排列的时候,当禁止位置的数量不多时,可采用容斥原理来解,但是当禁止位置数量很多时,用容斥原理求解起来很麻烦,因为禁止位置多的时候,求解反问题和原问题复杂度是相同的,因此需要换一种思路来求解这个问题。
4、棋盘多项式:带禁止位置的排列可看成在一个NXN的棋盘上放置N个带禁止位置的非攻击性車(这些車相互之间是有区别的),则在该棋盘上放置N个車的排列数为:
其中是k个非攻击性車放在相对应的禁止位置上的方法数,现在问题就转换成了如何求解。
下面我们用棋盘多项式来求解,定义在为棋盘C上放K个非攻击性車的方法数。如:
进一步,我们定义:
,
其中是做位置保持的,对于来说,有以下两条性质:
(1) .也就是说,我们可以选定一个方格,然后原棋盘多项式就等于x乘以去掉该方格所在的行和列的棋盘多项式,再加上只去掉这个方格的棋盘多项式,来对一个很大的棋盘进行分解。例如:
(2),其中和是相互独立的两部分。也就是说,如果一个棋盘可以分解成两个相互独立的部分,则原棋盘多项式就等于这两个独立棋盘多项式的乘积。
由以上两条性质,我们可知求解棋盘多项式时,我们应该尽可能挑选那些让棋盘分成两个独立部分的方格,来一步步使原问题变成一个个可直接求解的子问题。例如:
第七章:递推关系式和生成函数
1、线性齐次递推关系式
存在,以及,使得:则称这个数列满足K阶线性递推关系式。
进一步,如果,都为常数,且=0,我们称该递推关系式为线性齐次递推关系式。针对线性齐次递推关系式,我们可用以下方法求解:
为:
用替换,替换,依次类推,即得到如下关系式:
第一种情况:如果该方程有k个互异的根,则可以表示为:,为的一般表达式,即非递推表达式。(其中等根据已知的值代入求解)例如:
代入的值即可求出.
第二种情况:该方程有个重根,如果是该方程的重根,那么,其中例如:
2、生成函数:无穷级数是无穷数列的生成函数,其中是位置保持,是的系数。生成函数的系数即是我们所求解问题的解。
3、用生成函数求解线性齐次递推关系式的。求解时会用到牛顿二项式定理,先在这里说明一下,
下面给个例子:
4、一个例子
求凸多边形的三角划分:设是有n+1条边的凸多边形,则根据该问题可得:
进一步可得:(后面会知道,这是一个特殊计数序列Catalan数)
5、指数生成函数
将生成函数中的换成即为指数生成函数,即每一项都除以自身幂次的阶乘,具体的形式为:
该生成函数用来做位置保持,刚好对应于排列,因此指数生成函数是用来求解排列问题的。
下面给个例子;
总结:这章介绍了如何用生成函数来求解递归定义的数列,其中生成函数用来求组合问题(与容斥原理不同点在于生成函数通常是求带有要求的无限多个元素的组合问题,例如取偶数个,取奇数个),指数生成函数用来求排列问题。
第八章:特殊计数序列
1、Catalan数
该数的实际意义是:将n个-1和n个1这2n个数排成一个序列,从中任取前k个数,这k个数的和大于等于零的排列数。
2、差分序列
给定一个数的序列,差分.二阶差分,依此类推,可以得到三阶差分、四阶差分。这些差分所构成的表称为差分表。且如果是多项式,则差分表不会无限循环下去,若是p阶多项式,则第P+1阶差分一定为0.
当是p阶多项式时,可由差分表的第0条对角线确定。
,其中是第0条对角线上的K阶差分。例如:
且有该序列的前n项和为:
3、Stirling数(这里介绍的是第二类Stirling)
需求:单选文件上传,每次只允许一个文件上传,当已选择了文件再次点击选择其他的文件时,需要覆盖上次选择的文件。但是看了看el-upload的开发文档,好像不支持这个需求,选择新的文件后无法替代旧的。研究了下源码找到了实现方法。
解决方案 思路 利用el-upload的on-exceed,该方法是文件超出个数限制时的钩子,当把上传文件数最大设置为1的时候再次选择新文件时会触发这个方法,利用这个对文件进行重新赋值即可。
on-exceed的回调函数有两个参数function(files, fileList),files为当前选择的文件,fileList已经选择后的文件(上次选择的),可以对fileList进行赋值来修改上传时的文件。但是只修改fileList是不够的,还需要修改el-upload里的uploadFiles,保持数据同步,不然上传后的回调函数里的字段会报错。
实例代码 HTML部分 <el-upload class="col-md-6 col-lg-6 col-xs-12" ref="rebateUpload" :multiple="false" :action="config.interfaceIP+'xxx'" :headers=" {'X-CSRF-TOKEN':this.config.csrfToken}" :data="{type:uploadType}" :before-upload="()=>{$loading({lock: true,text: '上传中...',spinner: 'el-icon-loading', background: 'rgba(0, 0, 0, 0.7)'});}" :on-success="uploadRequest" :limit="1" :on-exceed="uploadExceed" :auto-upload="false"> <el-button slot="trigger" type="primary">选取文件</el-button> <el-button style="margin-left: 10px;" type="success" @click="()=>{$refs['rebateUpload'].submit()}"> 上传 </el-button> </el-upload> 注:该上传为手动上传
JS部分 uploadExceed(files, fileList) { this.$set(fileList[0], 'raw', files[0]); this.$set(fileList[0], 'name', files[0].name); this.$refs['rebateUpload'].clearFiles();//清除文件 this.$refs['rebateUpload'].handleStart(files[0]);//选择文件后的赋值方法 }, 总结 因为单选所以只要覆盖第一个值就可以了,fileList[0], '里的raw', 为选中的文件,同时替换掉文件的文件名name,再清除文件为el-upload里的uploadFiles重新赋值。
今年11.11大促期间,各大电商平台都使出了浑身解数,吸引剁手族买买买。个推作为大促期间的消息推送服务商,为蘑菇街等电商APP在消息的稳定下发环节提供着强大支撑和保障。今年的11.11个推全球消息下发总量再创新高,超过274亿条。而2017年和2018年11.11当天个推推送的总下发量分别是超过110亿条和232亿条。
那么个推是如何在11.11期间支撑起数百亿级别的推送量,且使消息推送稳定率达到了99.9%的呢?这背后离不开个推强大智能的技术服务。而Applink 在推送中也发挥了一定的做用。它使消息不再局限于手机通知栏。开发者可以通过AppLink技术,让用户在点击短信、信息流或Banner后,直接跳转到APP指定页面,在打造流畅用户体验的同时实现了高效的转化,提升了消息推送的到达率与点击率。本文将着重分析一下个推Applink的技术原理和使用方式。
简介
通过 Link这个单词我们可以看出这是一种链接,使用此链接可以直接跳转到 APP。Applink常用于应用拉活、跨应用启动、推送通知启动等场景。
流程
在AS 上其实已经有详细的使用步骤解析了,这里给大家普及下 。
快速点击 shift 两次,输入 APPLink 即可找到 AS 提供的集成教程。详细教程可参加AS,总共分为 4 步:
add URL intent filters
创建一个 URL 或者也可以点击 “How it works” 按钮
Add logic to handle the intent
选择通过 applink 启动的入口 activity。点击完成后,AS 会自动在两个地方进行修改,详情如下:
(一)
<activity android:name=".TestActivity"> <intent-filter> <action android:name="android.intent.action.VIEW" /> <category android:name="android.intent.category.DEFAULT" /> <category android:name="android.intent.category.BROWSABLE" /> <data android:scheme="http" android:host="geyan.getui.com" /> </intent-filter> </activity> 此处多了一个 data,看到这个 data 标签,我们可以大胆的猜测,这个 applink可能是一种隐式的APP启动方式。
(二)
protected void onCreate(@Nullable Bundle savedInstanceState) { super.
文章目录 前言SSH连接查看设备引脚信息查看L4T, Ubuntu, Kernel, CUDA版本号tegrastats风扇微信公众号 前言 Nvidia Jetson AGX Xavier 硬件相关
NVIDIA Xavier 环境搭建
第一篇整理了硬件相关的东西, 第二篇罗列了通过JetPack进行主机环境搭建, Xavier的系统安装和环境搭建的方法. 本篇整理下一些命令, 操作 或链接供备忘.
SSH连接 可以用网线连接到同一局域网, 也可以用USB Type-C线连接Xavier到主机, 会虚拟一个IP配置为192.168.55.x的网卡, Xavier的IP默认192.168.55.1, 如果Xavier的用户名Xavier, 就可以用ssh命令登录:
ssh xavier@192.168.55.1 输入密码就能登录了.
查看设备引脚信息 xavier@xavier-c:~$ sudo cat /sys/kernel/debug/gpio [sudo] password for xavier: gpiochip2: GPIOs 240-247, parent: platform/max77620-gpio, max77620-gpio, can sleep: gpio-246 ( |gpio_default ) out hi gpio-247 ( |gpio_default ) out hi gpiochip1: GPIOs 248-287, parent: platform/c2f0000.gpio, tegra-gpio-aon: gpio-253 ( |pex-refclk-sel-low ) out lo gpio-284 ( |power-key ) in hi gpiochip0: GPIOs 288-511, parent: platform/2200000.
1、首先在https://dev.mysql.com/downloads/mysql/地址中下载mysql,然后选择系统和系统版本,如下图所示:
2、然后找到对应的版本信息,如下图所示:
3、下载好之后通过tar -xzvf mysql-8.0.18-el7-x86_64.tar.gz 解压,如下图所示:
4、然后通过mv src/mysql-8.0.18-el7-x86_64 ./mysql将解压的目录移动到/usr/local/目录中,如下图所示:
5、首先通过groupadd mysql新建一个用户组,如下图所示:
6、然后在通过useradd -r -g mysql mysql新建一个用户,其中useradd -r 参数表示mysql用户是系统用户,不可用于登录系统
,useradd -g 参数表示把mysql用户添加到mysql用户组中,如下图所示:
7、进入mysql,并新建data、tmp、log三个目录,如下图所示:
8、然后通过chown -R mysql:mysql /usr/local/mysql修改mysql的属主,如下图所示:
9、然后配置环境变量,通过vim /etc/profile命令修改,添加mysql的目录,添加如下:
export MYSQL_HOME=/usr/local/mysql export PATH=$MYSQL_HOME/bin:$MYSQL_HOME/support-files:$PATH 如下图所示:
10、然后执行source /etc/profile命令使之生效。
11、然后执行mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data,成功之后会给出root的密码
mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data 或,以下命令是空密码 mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --pid-file=/usr/local/mysql/data --tmpdir=/usr/local/mysql/tmp 注释:
--user 启动mysql的用户
--basedir mysql安装目录
--datadir mysql数据仓库目录
如下图所示:
12、然后通过mysql.server start来启动mysql,如下图所示:
13、然后输入mysql -u root -p命令,会提示输入密码,需要将T,E&&,D>t0hY密码输入进去,然后回车即可进入mysql中,如下图所示:
14、修改加密规则,输入:ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER; ,如下图所示:
ubuntu-18.04 设置开机启动脚本 ubuntu-18.04 设置开机启动脚本
参阅下列链接
https://askubuntu.com/questions/886620/how-can-i-execute-command-on-startup-rc-local-alternative-on-ubuntu-16-10
ubuntu-18.04不能像ubuntu14一样通过编辑rc.local来设置开机启动脚本,通过下列简单设置后,可以使rc.local重新发挥作用。
1、建立rc-local.service文件
1
sudo vi /etc/systemd/system/rc-local.service
2、将下列内容复制进rc-local.service文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[Unit]
Description=/etc/rc.local Compatibility
ConditionPathExists=/etc/rc.local
[Service]
Type=forking
ExecStart=/etc/rc.local start
TimeoutSec=0
StandardOutput=tty
RemainAfterExit=yes
SysVStartPriority=99
[Install]
WantedBy=multi-user.target
3、创建文件rc.local 1
sudo vi /etc/rc.local
4、将下列内容复制进rc.local文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
// 引入crypto-js包 import CryptoJS from 'crypto-js' /** * AES加密 * @param {any} word 加密数据 */ export const cryptoEncrypt = (word) => { var key = CryptoJS.enc.Utf8.parse('填写密钥'); var iv = CryptoJS.enc.Utf8.parse('填写偏移量'); var encrypted = ''; if (typeof(word) == 'string') { var srcs = CryptoJS.enc.Utf8.parse(word); encrypted = CryptoJS.AES.encrypt(srcs, key, { iv: iv, mode: CryptoJS.mode.CBC, padding: CryptoJS.pad.Pkcs7 }); } else if (typeof(word) == 'object') {//对象格式的转成json字符串 data = JSON.stringify(word); var srcs = CryptoJS.enc.Utf8.parse(data); encrypted = CryptoJS.
类似用户登录app获取用户是什么手机。运营人员在各大应用商店运营APP,我们负责给他们各个应用商店的渠道包。这里我介绍一下我用到的友盟 。
注册友盟账号新建应用这里就不多说了。这里都有详细的接入文档,记录方便日后所需。
1、在AndroidManifest.xml 的application中添加
<!--所需权限--> <uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/> <uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/> <uses-permission android:name="android.permission.READ_PHONE_STATE"/> <uses-permission android:name="android.permission.INTERNET"/> <meta-data android:name="UMENG_APPKEY" android:value="" /> <meta-data android:name="UMENG_CHANNEL" android:value="${UMENG_CHANNEL_VALUE}" /> 这个地方注意 android:value="${UMENG_CHANNEL_VALUE}" 值的配置
要与build.gradle文件中配置保持一致
productFlavors.all { flavor -> flavor.manifestPlaceholders = [UMENG_CHANNEL_VALUE: name] } 2、在build.gradle中添加所需要的渠道
productFlavors { oppo {} vivo {} _360 {} meizu {} baidu {} xiaomi {} yinyou {} huawei {} anzhi {} le {} pp {} muma {} shaxin {} shixi {} jb {} } 这个时候你Sync Now 应该会出现一个错误
Attribute meta-data#UMENG_CHANNEL@value at AndroidManifest.xml:189:13-51 requires a placeholder substitution but no value for <UMENG_CHANNEL_VALUE> is provided. app main manifest (this file), line 188 Error: Validation failed, exiting app main manifest (this file)
大概意思是:属性元数据#UMENG_CHANNEL@value在AndroidManifest。需要一个占位符替换,但是没有提供的值。app主清单(此文件),验证失败,退出app主清单(此文件)
查看AndroidManifest.xml文件 点击Merged Manifest 查看具体的错误信息,但是这个问题本身是友盟渠道的问题。
<meta-data android:name="UMENG_APPKEY" android:value="5d6e127a570df312af00012f" /> <meta-data android:name="UMENG_CHANNEL" android:value="${UMENG_CHANNEL_VALUE}" /> 但是在主清单,build.gradle 添加
productFlavors.all { flavor -> flavor.manifestPlaceholders = [UMENG_CHANNEL_VALUE: name] } 注意Manifest 中的 UMENG_CHANNEL 中的value 和主清单中的flavor.manifestPlaceholders值保持一致。
问题就在于没有配置主清单文件。
相关阅读:
友盟多渠道获取渠道名,后台显示市场标识
书到用时方恨少,纸上得来终觉浅。共勉
sql表 班级表class 学生表student 成绩表scores 1:查询没有参加考试(没有成绩表)的学生 SELECT s.sid,s.sname,s.sex,c.cname,sc.languages,sc.math FROM student as s LEFT JOIN class as c on s.cid = c.cid LEFT JOIN scores as sc on s.sid = sc.sid WHERE sc.languages is null and sc.math is null ; 2:查询学生的成绩档 SELECT s.sid,s.sname,s.sex,c.cname, (CASE WHEN sc.languages >= 80 THEN '优秀' WHEN sc.languages >= 60 THEN '及格' WHEN sc.languages >= 0 THEN '不及格' ELSE '未参加考试' END ) as languages, (CASE WHEN sc.math >= 80 THEN '优秀' WHEN sc.
在学习vue的时候遇到这个问题
<el-carousel-item v-for="(item) in imagesList" :key="item"> 改为:
<el-carousel-item v-for="(item,index) in imagesList" :key="index"> 或者改为:
<el-carousel-item v-for="(item) in imagesList" :key="iitem.index"> 问题解决。
CUBEMX STM32F105RB U盘读写详细教程
abin 42817001
打开cubemx软件, 2.选择单片机型号,本文选stm32f105rb
3.设置RCC,
4.设置时钟
1 根据开发板选外部晶振,一般是8Mhz。
2 选通外部晶振通道,由于ubs要使用48Mhz频率,内部频率无法提供
3工具单片机选择主频,
1 2 3步骤无先后顺序,
5.选择调试端口,这里使用UART2,可以根据需要选择其他的uart
6.配置USB顺序
检查usb时钟是否是48Mhz,一般软件会自动设置好。
Host 设置 见usbh_conf.h 65-90行
7.设置PC9脚输出
由于本开发板的usb通过PC9低电平导通三极管给usb供电,所以要另外设置PC9脚, 如与本板不同可忽略本步骤。
8.管脚布局查看
9.PROJECT配置
10.点击软件界面的右上角的 产生代码,可能会出现一个警告窗口,不必理会,点YES 软件会自动生成KEIL需要的相关工程文件,点打开工程,然后就自动打开KEIL,
11.Keil 操作
12.Cubemx生成的main.c还不能直接使用,要定义变量 回调函数 USB操作函数等
代码要保存在cubemx设定好的用户代码区域,如果硬件变动生成新代码,用户自定义的代码就会保留。
13.下面是main.c修改后的文件,红色部分是增加的内容,其他文件不需修改
/* USER CODE BEGIN Header */
/**
******************************************************************************
* @file : main.c
* @brief : Main program body
******************************************************************************
* @attention
*
* <h2><center>© Copyright (c) 2019 STMicroelectronics.
* All rights reserved.